Проектирование клиент-серверных экономических информационных систем (КЭИС)
Первоисточник:http://pcica.hut2.ru/6.htm
Архитектура современных КЭИС базируется на принципах клиент-серверного взаимодействия программных компонентов ИС.
В вычислительных сетях под сервером понимается специализированная ЭВМ, управляющая использованием разделяемых между терминалами сети дорогостоящих ресурсов системы, например, баз данных, средств связи, принтеров и т.д. По признаку характера разделяемых ресурсов различают файловые серверы и серверы приложений.
В различных компонентах архитектуры сети может осуществляться поиск или обновление в базе данных, и тогда сервер называется сервером базы данных; если выполняется некоторая процедура обработки данных, тогда сервер называется сервером приложения.
Клиентом является приложение, посылающее запрос на обслуживание сервером. Задачей клиента являются инициирование связи с сервером, определение вида запроса на обслуживание, получение от сервера результата обслуживания, подтверждение окончания обслуживания.
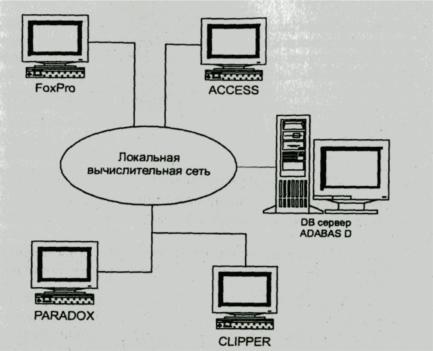
Рис. 6.1. Структура локальной вычислительной сети
Клиент-серверная архитектура реализует многопользовательский режим работы и является распределенной, когда клиенты и серверы располагаются на разных узлах локальной или глобальной вычислительной сети. Пример локальной сети с одним сервером представлен на рис. 6.1.
Преимущество локальной сети перед централизованной вычислительной системой заключается в открытом подключении и использовании вычислительных ресурсов с помощью единой передающей среды без пересмотра принципов взаимодействия ранее установленного вычислительного оборудования, то есть, простой масштабируемости КЭИС. В общем случае схема клиент-серверной архитектуры включает три уровня представления: уровень представления (презентации) данных пользователем; уровень обработки данных приложением и уровень взаимодействия с базой данных.
По этой схеме пользователь (клиент) в одном случае вводит данные, которые после контроля и преобразования некоторым приложением попадают в базу данных, а в другом случае запрашивает обработку данных приложением, которое обращается за необходимыми данными к базе данных. Получив необходимые данные, сервер их обрабатывает, а результаты или помещает в базу данных, или выдает пользователю (клиенту) в удобном для него виде, например в виде текстового документа, электронной таблицы, графика, или делает то и другое вместе.
Клиент-серверная архитектура в вычислительной сети может быть реализована по-разному. Выбор конкретной схемы определяется различными вариантами территориального распределения удаленных подразделений предприятия, требованиями эксплуатационной надежности, быстродействием, простотой обслуживания.
Рассмотрим различные схемы клиент-серверной архитектуры (рис. 6.2).
Файл-серверная архитектура представляет наиболее простой случай распределенной обработки данных, согласно которой на сервере располагаются только файлы данных, а на клиентской части находятся приложения пользователей вместе с СУБД. Файл-сервер представляет собой достаточно мощную по производительности и оперативной памяти ПЭВМ, являющуюся центральным узлом локальной сети. Файл-сервер в среде сетевой операционной системы организует доступ к файлам, полностью эквивалентным файлам операционной системы и расположенным во внешней памяти файл-сервера.
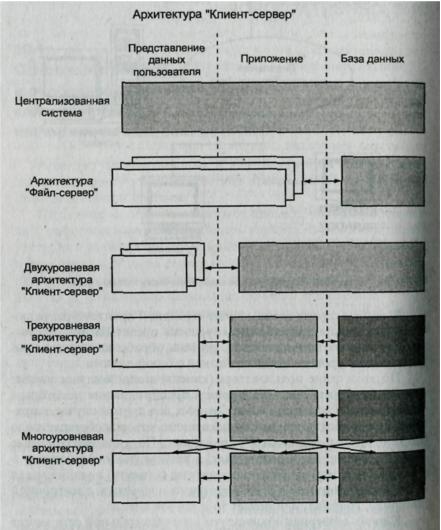
Рис. 6.2. Варианты клиент-серверной архитектуры КЭИС
При данном подходе программы СУБД располагаются в оперативной памяти рабочих станций локальной сети, а файлы базы данных - на магнитных дисках файл-сервера. Специальный интерфейсный модуль распознает, где находятся файлы, к которым осуществляется обращение. В связи с этим данная СУБД может работать как с локальными базами данных, так и с центральной базой данных. Синхронизация совместного использования базы данных файл-сервера возлагается на систему управления базами данных, которая должна обеспечивать блокирование записей на время их корректировки, чтобы сделать их недоступными с других рабочих станций.
Использование файл-серверов предполагает, что вся обработка данных выполняется на рабочей станции, а файл-сервер лишь выполняет функции накопителя данных и средств доступа.
Двухуровневая клиент-серверная архитектура основана на использовании только сервера базы данных (DB-сервера), когда клиентская часть содержит уровень представления данных, а на сервере находится база данных вместе с СУБД и прикладными программами,
DB-сервер отличается от файл-сервера тем, что в его оперативной памяти, помимо сетевой операционной системы, функционирует централизованная СУБД, которая обеспечивает совместное использование рабочими станциями базы данных, размещенной во внешней памяти этого DB-сервера.
DB-сервер дает возможность отказаться от пересылки по сети файлов данных целиком и передавать только ту выборку из базы данных, которая удовлетворяет запросу пользователя. При этом возможно разделение пользовательского приложения на две части: одна часть выполняется на сервере и связана с выборкой и агрегированием данных из базы данных, а вторая часть по представлению данных для анализа и принятия решения выполняется на клиентской машине. Таким образом, увеличивается общая производительность информационной системы в результате объединения вычислительных ресурсов сервера и клиентской рабочей станции.
Обращение к базе данных осуществляется на языке SQL, который фактически стал стандартом для реляционных баз данных, Отсюда сервер баз данных часто называют SQL-сервером, который поддерживается всеми реляционными СУБД: Огасle, Informix, MS SQL, ADABAS D, InterBase, SyBase и др. Клиентское приложение может быть реализовано на языке настольных СУБД (MS Access, FoxPro, Paradox, Clipper и др.). При этом взаимодействие клиентского приложения с SQL-сервером осуществляется через ODBC-драйвер (Open Data Base Connectivity), который обеспечивает возможность пересылки и преобразования данных из глобальной базы данных в структуру базы данных клиентского приложения. Применение этой технологии позволило разработчикам не заботиться о специфике работы с той иной СУБД и делать свои системы переносимыми между баз данных. За время своего существования ODBC стал стандартом де-факто на алгоритм доступа к разнородным базам данных, и на сегодняшний день насчитывается более 160 прикладных систем, которые работают с источниками информации через драйверы ODBC.
Трехуровневая клиент-серверная архитектура позволяет помещать прикладные программы на отдельные серверы приложений, с которыми через API-интерфейс (Application Program Interface) устанавливается связь клиентских рабочих станций. Работа клиентской части приложения сводится к вызову необходимых функций сервера приложения, которые называются «сервисами». Прикладные программы в свою очередь обращаются к серверу базы данных с помощью SQL запросов. Такая организация позволяет еще более повысить производительность и эффективность КЭИС за счет:
• многократности повторного использования общих функций обработки данных во множестве клиентских приложений при существенной экономии системных ресурсов;
• параллельности в работе сервера приложений и сервера базы данных, причем сервер приложений может быть менее мощным по сравнению с сервером базы данных;
• оптимизации доступа к базе данных через сервер приложений
из клиентских мест путем диспетчеризации выполнения запросов в вычислительной сети;
• повышения скорости и надежности обработки данных в результате дублирования программного обеспечения на нескольких
серверах приложений, которые могут заменять друг друга в сети в случае перегрузки или выхода из строя одного из них;
• переноса функций администрирования системы по проверке полномочий доступа пользователей с сервера базы данных на сервер приложений.
Многоуровневая архитектура «Клиент-сервер» создается для территориально-распределенных предприятий. Для нее в общем случае характерны отношения «многие ко многим» между клиентскими рабочими станциями и серверами приложений, между серверами приложений и серверами баз данных. Такая организация позволяет более рационально организовать информационные потоки между структурными подразделениями в процессе выполнения общих деловых процессов. Так, каждый сервер приложений, как правило, обслуживает потребности какой-либо одной функциональной подсистемы и сосредоточивается в головном для подсистемы структурном подразделении, например, сервер приложения по управлению сбытом - в отделе сбыта, сервер приложения по управлению снабжением - в отделе закупок и т.д. Естественно, что локальная сеть каждого из подразделений обеспечивает более быструю реакцию на запросы основного контингента пользователей из соответствующего подразделения. Интегрированная база данных находится на отдельном сервере, на котором обеспечиваются централизованное ведение и администрирование общих данных для всех приложений.
Выделение нескольких серверов баз данных особенно актуально для предприятий с филиальной структурой, когда в центральном офисе используется общая база данных, содержащая общую нормативно-справочную, планово-бюджетную информацию и консолидированную отчетность, а в территориально-удаленных филиалах поддерживается оперативная информация о деловых процессах. При обработке данных в филиалах для контроля используется плановая и нормативно-справочная информация из центральной: базы данных, а в центральном офисе получение консолидированной отчетности сопряжено с обработкой оперативной информации филиалов.
Для сокращения объема передачи данных по каналам связи в распределенной информационной системе предлагается репликация данных, то есть, тиражирование данных на взаимодействующих серверах баз данных с автоматическим поддержанием соответствия копий данных.
При этом возможны следующие режимы репликации:
• синхронный режим, когда тиражируемые данные обновляются по мере возникновения необходимости одновременно на серверах баз данных во всех копиях. Требуемое быстродействие каналов для синхронного режима - единицы Мбит в секунду;
• асинхронный режим, когда тиражирование данных выполняется в строго определенные моменты времени, например, каждый час работы информационной системы. Требуемое быстродействие каналов для асинхронного режима - единицы Кбит в секунду. Асинхронный режим может вызывать откладывание выполнения транзакций до момента обновления данных.
Направление тиражирования между серверами баз данных может быть:
• равноправным, т.е. в обоих направлениях;
• сверху-вниз типа «ведущий/ведомый», когда на серверах филиалов содержатся только некоторые подмножества данных центральной базы данных;
• снизу-вверх по консолидирующей схеме, когда при обновлении данных в филиалах в определенные моменты времени обновляется центральная база данных.
Рассмотрим технологическую сеть техно-рабочего проектирования трехуровневой клиент-серверной КЭИС, включающую шесть операций (рис. 6.3).
I. Разработка общей структуры корпоративной информационной системы (П1)
Эта операция выполняется на основе описания предметной области D1 и технического задания D4, а также универсумов сетевых операционных систем и технических платформ (U1), серверов БД (U2), программных средств разработки КЭИС (U3). Выходом данной технологической операции служат описание выбранной конфигурации технических средств и сетевой операционной системы D3, описание выбранного сервера БД - D2, описание выбранных программных средств разработки КЭИС - D5, описание функциональной структуры КЭИС - D6.
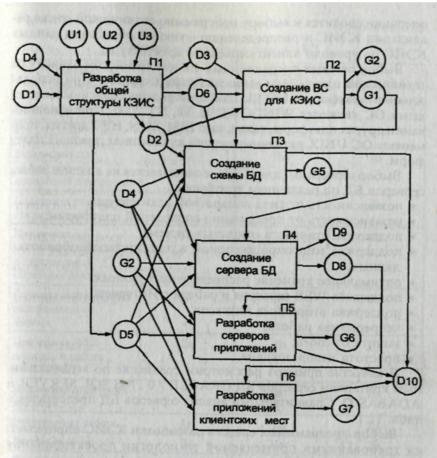
Рис. 6.3. Технологическая сеть техно-рабочего проектирования
трехуровневой клиент-серверной КЭИС:
D1 - описание предметной области; D2 - описание выбранного сервера БД;
D3 - описание выбранной конфигурации технических средств и сетевой операционной системы: D4 - техническое задание; D5 - описание выбранных
программных средств разработки КЭИС; D6 - описание функциональной структуры КЭИС; D8 - права доступа различным категориям пользователей КЭИС; D9 - журнал заполнения областей БД; D10– сопровождающая документация; U1 - универсум сетевых операционных систем и технических платформ; U2 - универсум серверов БД;
U3 - универсум программных средств разработки КЭИС; G1 - вычислительная ость;
G2 - СУБД; GS - SQL-описание БД с управляющими элементами; G6 - программное
обеспечение сервера; G7 - приложения клиентских мест
Сущность операции сводится к выбору программно-технической среды реализации КЭИС и распределению функций обработки данных КЭИС по уровням клиент-серверной архитектуры.
Выбор сетевых операционных систем во многом зависит технической платформы вычислительных средств. При использовании платформы INTEL наиболее распространенными сетевыми ОС являются WINDOWS 98, NT 2000. При использовании других платформ, таких, как: IBM; SUN; HP и других, применяют ОС UNIX различных версий для соответствующих: форм.
Выбор сервера БД для КЭИС основывается на анализе рынка серверов БД по различным критериям:
· независимость от типа аппаратной архитектуры;
· независимость от программно-аппаратной платформы;
· поддержка стандарта открытых систем;
· поддержка многопроцессорной и параллельной обработки данных;
· оптимальное хранение распределенных данных;
· поддержка WEB-серверов и работа с Интернет;
· непрерывная работа;
· защита от сбоев;
· простота использования.
В качестве примера рассмотрим сравнение по вышеназванным критериям серверов БД ORACLE 7.0, MS SQL SERVER и ADABAS D. Сравнительный анализ серверов БД представлен в табл. 6.1.
Выбор программных средств разработки КЭИС определяется требованиями применяемой технологии проектирования КЭИС.
Разработка общей функциональной структуры корпоративной информационной системы на основе функционально-ориентированной или объектно-ориентированной модели проблемной области заключается в определении:
• функций сервера БД;
• функций серверов приложений;
• функций клиентских мест;
• информации, которая необходима для выполнения этих операций;
• распределения серверов и клиентских мест по узлам вычислительной сети;
• прав доступа пользователей к КЭИС.
Таблица 6.1
Сравнительный анализ серверов БД

Основными правами доступа являются следующие:
• права на доступ к вычислительным ресурсам. Такие права задаются администратором вычислительной сети с помощью инструментов сетевой операционной системы. Процесс задания прав заключается в назначении различным категориям пользователей прав доступа к ресурсам сети и возможности выполнения над ними функций чтения, редактирования, записи. Например, пользователю с именем manager 1 доступны ресурсы, представленные в табл. 6.2.
• права на доступ к объектам схемы базы данных КЭИС. Такие права задаются администратором сервера БД с помощью инструментов серверной СУБД. Процесс задания прав заключается в назначении различным категориям пользователей возможности выполнения над объектами схемы БД функций чтения, редактирования, записи. Например, пользователю с именем manager l доступны объекты, представленные в табл. 6.3.
Таблица 6.2
Задание прав доступа
Имя пользователя |
Системный ресурс (диски, папки, файлы) |
Разрешенные функции |
| manager 1 | D:\zapasy\ostatok 1.dbf D:\zapasy \ostatok.dbf C:\price |
Только чтение Чтение, редактирование Только запись |
Основными правами доступа являются следующие:
• права на доступ к вычислительным ресурсам. Такие права задаются администратором вычислительной сети с помощью инструментов сетевой операционной системы. Процесс задания прав заключается в назначении различным категориям пользователей прав доступа к ресурсам сети и возможности выполнения над ними функций чтения, редактирования, записи. Например, пользователю с именем manager 1 доступны ресурсы, представленные в табл. 6.2.
• права на доступ к объектам схемы базы данных КЭИС. Такие права задаются администратором сервера БД с помощью инструментов серверной СУБД. Процесс задания прав заключается в назначении различным категориям пользователей возможности выполнения над объектами схемы БД функций чтения, редактирования, записи. Например, пользователю с именем manager l доступны объекты, представленные в табл. 6.3.
Таблица 6.2
Задание прав доступа
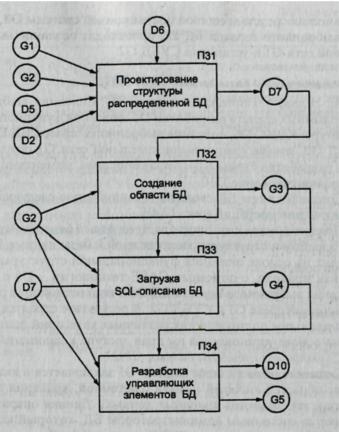
Рис. 6.4. Технологическая есть проектирования базы данных в клиент-серверной среде:
D2 - описание выбранного сервера БД; D5 - описание выбранных программных
средств разработки КЭИС; D6 - описание функциональной структуры КЭИС;
D7 - структура базы данных; D10 - сопровождающая документация;
G1 - вычислительная сеть; G 2 - СУБД; G3 - область базы данных;
G4 - SQL-описание БД; G5 - SQL-описание БД с управляющими элементами
Хранимая процедура представляет собой вариант программного наполнения базы данных, основная функция которой - функциональное расширение схемы БД, Хранимая процедура выполняет то или иное логическое действие. Например, администратор банковской системы создает хранимую процедуру, которая реализует функцию «занести на счет номер X сумму Y».
Разработчик приложения пользуется этой процедурой, но не знает, как именно она работает. Это дает следующие преимущества:
• когда меняется алгоритм данного действия, то администратор меняет только эту хранимую процедуру и все приложения сразу начинают работать по-новому;
• независимо от типа рабочего места, использующего хранимую процедуру, одно и то же действие выполняется одинаково, что повышает надежность разработанной системы;
• хранимая процедура пишется одним человеком, а используется многими, следовательно, повышаются темпы разработки КЭИС;
• повышается скорость обработки запросов пользователей за счет того, что действия по анализу хранимой процедуры выполняются единожды при определении этой процедуры.
Триггер БД - это механизм «событие - действие», который автоматически выполняет некоторый набор SQL-операторов, когда происходит некоторое событие. Событиями, на которые можно установить триггер, являются модификации данных. Причем триггер связан с конкретной таблицей БД. Триггер хранится как объект в базе данных. Создание триггеров позволяет установить правила обеспечения ссылочной целостности сервера БД.
4. Создание сервера БД КЭИС (П4)
На основании разработанной схемы БД с управляющими элементами G5, описания выбранного сервера БД D2 и его СУБД G2 осуществляется создание сервера БД, то есть физическое наполнение БД и настройка программ доступа СУБД. Выходом данной операции служат физическое установление прав доступа различным категориям пользователей КЭИС D8, журнал заполнения областей БД D9.
5. Разработка серверов приложений (П5)
Исходя из информационных потребностей пользователей D4 и их прав D8, используя программные средства разработки D5, разрабатывается сервер приложения G5 и сопровождающая документация D10.
В состав сервера приложений входят набор сервисов (функций обработки данных) и монитор транзакций, осуществляющий Управление выполнением сервисов по обслуживанию клиентских потребностей.
6. Разработка клиентских приложений на рабочих станциях (П6)
На основе информационных потребностей пользователей D4 и их прав D8, используя программные средства разработки D5, создаются приложения клиентских мест G7, а также сопровождающая документация D10. В частности, осуществляется проектирование пользовательского интерфейса клиентских частей приложений.
Проектирование систем оперативной обработки транзакций
Клиент-серверная архитектура КЭИС упрощает взаимодействие пользователей с информационной системой и между собой в процессе выполнения деловых процессов или длинных транзакций. Под длинной транзакцией будем понимать совокупность операций делового процесса, требующих обращения к КЭИС, каждая из которых не имеет ценности без выполнения всей совокупности. Под короткой транзакцией или просто транзакцией будем понимать отдельное обращение к одному из компонентов КЭИС или обращение клиента к серверу. С помощью обработки длинных транзакций КЭИС позволяет управлять достаточно сложными цепочками операций делового процесса как единым целым. Такие информационные системы называют системами оперативной обработки транзакций (OLTP – On-Line Transaction Processing).
Основой современных систем оперативной обработки транзакций является управление рабочими потоками (workflow), в которых пользователи-клиенты взаимодействуют между собой и с множеством программных приложений через специальную управляющую программу. Системы оперативной обработки транзакций могут распространяться и на межорганизационное взаимодействие предприятий с помощью специально разработанных Интернет-приложений в глобальной вычислительной сети.
Использование систем управления рабочими потоками
Под рабочим потоком будем понимать совокупность информационного и материального потоков в цепочке операций делового процесса.
Система управления рабочими потоками (СУРП) - это программный комплекс, который оперативно связывает персонал из различных подразделений предприятия и программные приложения в общий деловой процесс, позволяя его автоматизировать и управлять им как единым целым. СУРП интегрирует по управлению все взаимодействующие элементы рабочего потока, переключает потоки между приложениями, управляет выбором исполнителей операций (как персонала, так и программ). С позиции проектирования ЭИС СУРП обеспечивает выстраивание цепочек автоматизированных рабочих мест, которые обмениваются между собой информацией по вычислительной сети через распределенную базу данных. С позиции многоуровневой клиент-серверной архитектуры СУРП - это управляющая (супервизорная) программа, которая регулирует множественное взаимодействие клиентов и серверов приложений и баз данных в длинных транзакциях (рис. 6.5). Таким образом, клиент обращается не напрямую к серверу приложений, а через СУРП, которая выбирает необходимое приложение в зависимости от конкретных событий в деловом процессе.

Рис. 6.5. Многоуровневая клиент-серверная архитектура на основе использования СУРП
СУРП создаются на основе использования специального программного обеспечения для организации коллективной (групповой - workgroup) работы в локальных вычислительных сетях. В эту систему входят средства электронного обмена сообщениями и маршрутизации, которые позволяют организовывать непосредственный обмен результатами работы между участниками делового процесса, мониторинг выполнения делового процесса со стороны руководства предприятия, а также инициировать работу исполнителей по завершении выполнения автоматических процедур. Система управления рабочим потоком может быть реализована на основе специализированного программного обеспечения, например Staffware, Workroute, или встроена в контур интегрированной ЭИС, как в системах комплексной автоматизации R/3 и BAAN IV.
Основными особенностями системы управления рабочими потоками являются:
· наличие программы-менеджера рабочего потока, управляющей переходами между шагами задания и документирующей исполняемые процессы;
· поддержка маршрутной карты предприятия, определяющей схему прохождения работ в деловом процессе;
· обеспечение выбора исполнителей процессов по модели организационной структуры предприятия;
· обработка событий: временных (deadline) и завершения операций, условий (триггеров) подключения процессов; наличие средств электронной почты для обмена сообщениями между исполнителями и передача списка заданий от руководителей;
· автоматический контроль исполнения работ и информирование руководителей;
· обращение к интегрированной базе данных, через которую осуществляется обмен результатами работ исполнителей;
· открытые интерфейсы с внутренними и внешними приложениями, подключение транзакций по Интернету;
· сбор статистики о выполнении деловых процессов;
· подключение стандартных процедур и шаблонов оформления документов.
Центральным компонентом СУРП является менеджер рабочих потоков, который выполняет следующие функции:
• создание шагов задания;
• оценку условий выполнения шага заданий;
• обработку возникающих событий и принятие решений по сообщениям;
• контроль сроков выполнения шагов заданий (события по таймеру);
• передачу управления между приложениями;
• синхронизацию несколько одновременно выполняющихся процессов;
• распределение результатов выполнения шага задания по получателям;
• ведение журнала операций.
Менеджер рабочих потоков в процессе обработки возникающих событий обрабатывает маршрутную карту делового процесса. В основе маршрутной карты лежит организационная структура, на которой распределяются списки заданий в рамках какого-либо делового процесса. СУРП использует модель организационной структуры предприятия для создания списка заданий с учетом наличных ресурсов (поступления и выбытия работников и оборудования). Таким образом, СУРП поддерживает модель организационной структуры предприятия, внося по мере необходимости изменения в структуру взаимосвязей организационных единиц.
В работе менеджера рабочих потоков используются различные методы маршрутизации, основанные на определенных правилах. Так, в зависимости от предопределенности порядка выполнения процедур различают правила:
• жесткой маршрутизации;
• свободной маршрутизации;
• гибридной маршрутизации.
Жесткая маршрутизация возможна в том случае, если порядок выполнения операций делового процесса известен заранее и не зависит от результата выполнения предыдущей операции. Такая маршрутизация закладывается при проектировании модели делового процесса. При ее реализации завершение одной операции приводит к автоматическому запуску одной или нескольких последующих операций. В случае необходимости, например при изменении порядка выполнения делового процесса, правила жесткой маршрутизации, заложенные в маршрутной карте, могут быть изменены.
Свободная маршрутизация означает, что последовательность операций делового процесса не известна заранее и определяется только в ходе его выполнения. В этом случае решение о запуске определенной операции предоставляется участнику делового процесса, наделенному соответствующими правами.
Гибридная маршрутизация предполагает возможность принятия решения менеджером рабочего потока на основе правил перехода, обрабатывающих возникающие события.
В зависимости от порядка следования активизируемых операций может выполняться последовательная, параллельная или смешанная маршрутизация.
Последовательная маршрутизация подразумевает выполнение деловых операций одна за другой. Очередная операция инициируется только после завершения предыдущей операции. Таким образом, при последовательной маршрутизации в определенный момент времени может быть инициирована только одна операция.
Параллельная маршрутизация приводит к одновременной активизации нескольких деловых операций. Это возможно в том случае, если активизируемые операции независимы друг от друга и выполнение одной из них не требует результатов, получаемых после завершения другой. Параллельная маршрутизация значительно сокращает время реализации делового процесса.
Смешанная маршрутизация допускает сочетание последовательной и параллельной маршрутизации.
Использование Интернет-приложений
Многоуровневая клиент-серверная архитектура распространяется на Интернет-приложения, связывающие множество участников делового процесса, территориально удаленных друг от друга в рамках как одного, так и нескольких предприятий на основе применения сетевого протокола TCP/IP. Эти приложения разрабатываются для таких предметных областей, как управление финансами, логистикой, персоналом, учет и отчетность и др. Достоинство распределенных приложений заключается в устранении промежуточных звеньев делового процесса, когда пользователь, минуя обращения к тому или иному подразделению предприятия, напрямую обращается к информационной системе для выполнения требуемой функции. Причем обращение может быть выполнено из любого места, в любой день и в любое время суток в удобной для пользователя форме, используя обычную программу навигации (браузер) и мультимедийное представление информации в Интернете.
Типичными Интернет-приложениями являются:
• «клиент - предприятие», осуществление торговли по электронным каталогам, проведение электронного обслуживания клиентов (банковские, страховые, таможенные операции и т.д.). В этом случае клиент оформляет заказ или заявку на обслуживание путем просмотра списка услуг обслуживающего предприятия, информационная система автоматически регистрирует поступивший заказ и планирует его выполнение. Все необходимые документы (счета, накладные, платежные поручения) оформляются автоматически. Пользователю высылается уведомление о выполнении операции или отказе;
• «предприятие - предприятие», осуществление сделок закупки-продажи товаров, выполнение совместных проектов. В первом случае между предприятиями осуществляется обмен документов: договоров, заказов, счетов, накладных, платежных поручений. Причем в отличие от традиционного электронного обмена данными (EDI - Electronic Data Interchange) возможна такая синхронизация транзакций, что два деловых процесса закупки и продажи по сути сливаются в один общий процесс.
В случае осуществления проектов взаимная деятельность предприятий расширяется до проектирования изделий и планирования производства и образования совместных виртуальных предприятий. При этом обычно используется международный стандарт для обмена данными по моделям продукции STEP (Standard for the Exchange of Product model data);
• «работник (подразделение) - работник (подразделение)», приложения Интранета предполагают применение технологии Интернета для связи между сотрудниками одного предприятия. При этом используются описанные выше системы управления рабочими потоками.
В корпоративной информационной системе R/3 (SAP) для реализации распределенных деловых процессов с помощью Интернет-приложений разработан специальный механизм Application Link Enabling (ALE), с помощью которого свободно связываются друг с другом программные компоненты, относящиеся к различным информационным системам. В частности, для взаимодействия программных компонентов предлагается использовать стандартные интерфейсы BAPI (Business Application Programming Interface). В системе R/3 в настоящее время разработано более 25 Интернет-приложений и более 100 BAPI интерфейсов к ним.
На рис. 6.6 представлена многоуровневая клиент-серверная архитектура для реализации Интернет-приложений в системе R/3. В этой архитектуре добавляется дополнительный уровень, обеспечивающий обработку транзакций в Интернете. В частности, SAP-сервер транзакций Интернета обеспечивает надежный доступ из Интернета/Интранета ко всем транзакциям R/3. Получив обращение из Интернета, SAP-сервер вызывает соответствующее Интернет-приложение, которое через BAPI-интерфейс осуществляет доступ к приложению R/3, в свою очередь обращающемуся к серверу базы данных.

Рис. 6.6. Многоуровневая клиент-серверная архитектура для Интернет- приложений в системе R/3