Л. Левкович-Маслюк, А. Переберин. Введение в вейвлет-анализ
Ссылка: http://algolist.manual.ru/compress/image/leo_lev/lecture1/wav1_1.php
Ортогональные вейвлеты и многомасштабный анализ
Введение
Вейвлет-преобразование естественно возникает в контексте многомасштабного анализа (multiresolution analysis), МА. МА – это математическая конструкция, синтезирующая две идеи обработки сигналов. Первая идея – разложение сигнала по поддиапазонам (subband decomposition) при помощи квадратурных зеркальных фильтров (quadrature mirror filters) – появилась в задаче сжатия речи. Вторая идея – пирамидное представление (pyramid representation) – в задаче сжатия изображений. Обе идеи связаны с применением к сигналу фильтров специального вида. В первом случае теория строилась в терминах Фурье-преобразования сигнала, во втором – в терминах исходного сигнала.
Рассмотрим сигнал – последовательность чисел x=![]() .
Для сглаживания сигнала, подавления шума и других целей часто используют
фильтры – преобразования свертки вида:
.
Для сглаживания сигнала, подавления шума и других целей часто используют
фильтры – преобразования свертки вида:
Сигнал y=![]() получается “локальным усреднением” сигнала x с помощью набора “весов” h={hk}:
получается “локальным усреднением” сигнала x с помощью набора “весов” h={hk}:
В дальнейшем нам понадобятся следующие понятия.
-
Дискретное преобразование Фурье (ДПФ) сигнала:
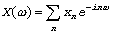 (формальная сумма).
(формальная сумма).
-
z-преобразование сигнала:
 (формальная
сумма).
(формальная
сумма).
-
Преобразование Фурье функции x(t) имеет вид
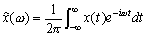 .
.
или
(если сигнал конечен, его обычно доопределяют периодическим образом
для всех целых значений индекса).
-
Транспонированный фильтр h* состоит
из тех же коэффициентов, что и фильтр h,
переставленных в обратном порядке. В Фурье-области транспонированный фильтр
имеет вид
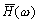 .
Коэффициенты всех сигналов и фильтров будут предполагаться вещественными.
.
Коэффициенты всех сигналов и фильтров будут предполагаться вещественными.
Разложение по поддиапазонам
Мы хотим найти два фильтра, h (подавляющий высокие частоты) и g (подавляющий низкие частоты), которые позволяли бы разложить сигнал на две компоненты, XH(z) и XG(z), вдвое их проредить (половина значений становится лишней – ведь частотный диапазон сократился вдвое!), а затем, с помощью транспонированных фильтров, точно восстановить по этим данным исходный сигнал (эту операцию можно применять рекурсивно). Условия на искомые фильтры удобно записать в терминах z-преобразования.
Пусть Y(z) – z-преобразование одной из компонент. Перед кодированием она прореживается вдвое, а перед восстановлением исходного сигнала доводится до исходной длины вставкой нулей между соседними значениями. При этом z-преобразование из Y(z) превращается в (Y(z)+Y(-z))/2. Подставим сюда (1.1’) для каждого из фильтров, и получим z-преобразования компонент перед восстановлением
z-преобразования транспонированных фильтров имеют вид H(z-1)и G(z-1). Сигнал восстановится с их помощью точно, если:
Получаем условия точного восстановления (perfect reconstruction, PR):
В матричной форме они записываются так:
где
Подставив ![]() , получим
условия на ДПФ искомых фильтров:
, получим
условия на ДПФ искомых фильтров:
-
 (1.2)
(1.2) -
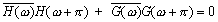
Допустим, что мы нашли h такой, что ()
Тогда, положив
мы видим, что (1.2) выполняется. Задача свелась к нахождению тригонометрического
многочлена ![]() ,
удовлетворяющего (1.2’). На методах построения таких многочленов мы остановимся
в следующей лекции. Фильтры h и g, удовлетворяющие (1.2),
называются квадратурными зеркальными фильтрами (quadrature mirror filters,
QMF).
,
удовлетворяющего (1.2’). На методах построения таких многочленов мы остановимся
в следующей лекции. Фильтры h и g, удовлетворяющие (1.2),
называются квадратурными зеркальными фильтрами (quadrature mirror filters,
QMF).
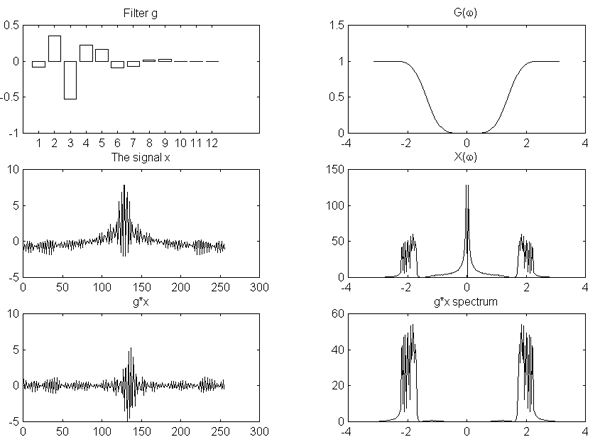
На рис.1, (a) и (b), показаны ДПФ такой пары фильтров h и g, а также исходный сигнал до и после фильтрации (без прореживания).

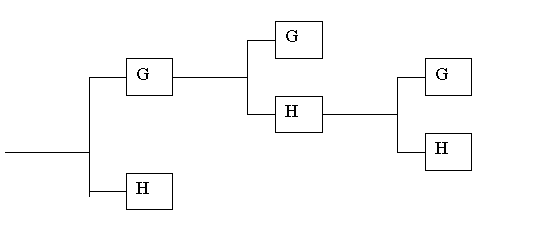
Точно такую же операцию можно применить к одной или обеим из полученных компонент, и т.д., добиваясь нужной локализации по частоте. Это позволяет адаптироваться к особенностям сигнала за счет выбора подходящего “дерева разложения”. Оно может выглядеть, например, так:
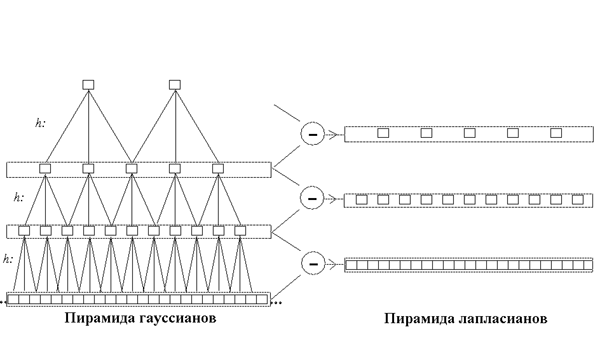
На рисунке 3 схематически изображено пирамидное представление одномерного сигнала. Сигналу ставятся в соответствие две пирамиды: пирамида гауссианов (ПГ) и пирамида лапласианов (ПЛ). Эти названия отражают аналогию с популярными в графике операциями сглаживания (свертки с колоколообразным фильтром) и выделения перепадов (вычисления “дискретного оператора Лапласа”). Можно считать эту конструкцию упрощенным вариантом предыдущей.
В основании ПГ находится исходный сигнал. Следующий этаж ПГ – исходный сигнал, профильтрованный низкочастотным фильтром h и прореженный после этого вдвое – предполагается, что фильтр h “убивает” верхнюю половину частотного диапазона, поэтому густоту выборки можно соответственно уменьшить. К этому этажу применяется та же операция, и так далее. В случае конечных сигналов каждый следующий этаж вдвое короче предыдущего.
Этажи ПЛ – разности между последовательными этажами ПГ. Они вычисляются так. Пусть, например, g1 и g2 – первый и второй этажи ПГ, d1 – первый этаж ПЛ, который мы хотим вычислить. Для этого сначала выравниваются длины этажей:
![]()
а затем выполняется фильтрация сопряженным фильтром h*
(его коэффициенты – переставленные в обратном порядке коэффициенты h,
в Фурье-области это равнозначно переходу к ![]() ).
В результате возникает вектор
).
В результате возникает вектор ![]() . По определению,
. По определению,
Теперь вместо исходного сигнала (g1) достаточно запомнить пару (g2,d1). Исходный сигнал можно точно восстановить по формуле:
Сигнал d1 вдвое короче исходного, а сигнал d1, как правило, почти целиком состоит из очень малых величин. Многие из этих величин можно без заметного ущерба для точности восстановления заменить нулями, а остальные закодировать более короткими словами, чем компоненты исходного сигнала. За счет этого общая длина записи будет существенно меньше длины записи исходного сигнала. Это сокращение станет еще больше, если вычислить несколько этажей ПЛ, и запоминать вместо исходного сигнала несколько этажей ПЛ и последний этаж ПГ.
Степень сжатия информации этим методом зависит от выбора фильтра h.
При экспериментах с пирамидными представлениями было сделано наблюдение:
“качество” фильтра удобно выражать в терминах эквивалентной весовой
функции. Эта функция возникает так. Нетрудно вычислить коэффициенты
фильтров, свертка сигнала с которыми дает сразу второй этаж ПГ, третий
этаж, и т.д. Оказывается, что при соответствующей нормировке векторы этих
коэффициентов сходятся к некоей предельной “форме” – графику функции ![]() ,
которая должна удовлетворять функциональному уравнению:
,
которая должна удовлетворять функциональному уравнению:
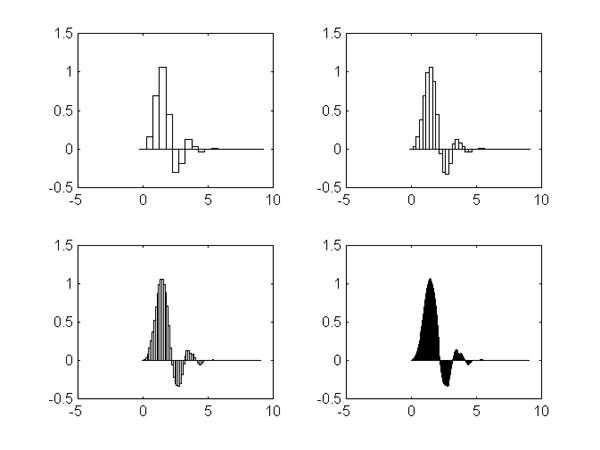
Процесс получения![]() изображен на рис. 4.
изображен на рис. 4.
- I. Daubechies. Ten Lectures on Wavelets. SIAM, 1992.
- C.K.Chui. Wavelets: a tutorial in theory and applications, Academic Press, 1992.
- IEEE Trans. on Information Theory, Vol. 38, No. 2, March 1992 (специальный номер по вейвлетам)
- P.Burt, E.Adelson. The Laplacian pyramid as a compact image code, IEEE Trans. Comm., 31, pp. 482-540.
- Mark Smith, Thomas Barnwell. Exact Reconstruction Techniques for Tree-Structured Subband Coders, IEEE Trans. on ASSP, v. ASSP-34, No.3, June 1986.