| <<Показать меню | |
Об архитектурных различиях ADO.NET и ADO сказано уже немало, однако, также интересно было бы сравнить их скоростные характеристики. В конце концов, именно скорость (точнее, недостаточная скорость) выполнения программы часто раздражает пользователя.
Также показалось любопытным, есть ли отличия в работе с ADO.NET через COM+ и NetRemoting? Стоит ли по-прежнему использовать COM+ в качестве сервера приложений? Возможно, NetRemoting работает значительно быстрее, чем COM+, или при использовании COM+ с .NET возникают какие-то непреодолимые проблемы?
Конечно же, мы не обошли вниманием и собственный продукт – ascDB, постаравшись максимально беспристрастно оценить его на фоне ADO и ADO.NET. Кто оказался быстрее и в каких случаях?
Ответам на эти и смежные с ними вопросы посвящена данная статья.
Тестировались три средства доступа к данным: ADO.NET (C#), ADO (VB6) и ascDB (VB6). Использовался MS SQL Server 2000.
В качестве тестовых таблиц использовались копии таблицы Orders из базы Northwind стандартной поставки MS SQL Server 2000. Таблицы содержат 14 колонок со следующими типами данных: int (3 колонки), money (одна колонка), datetime (3 колонки), строки с длиной от 5 до 60 символов (7 колонок). Таблицы создавались в отдельной базе данных и не связаны с другими таблицами или между собой.
Для каждого случая выполнялись 5 тестов. Каждый тест выполнялся в «in-process режиме», в «локальном режиме через COM+» и в «удаленном режиме через COM+». Отдельно для ADO.NET тесты запускались дополнительно в «локальном режиме через NET Remoting» и «удаленном режиме через NET Remoting».
В качестве тестовой машины в «in-process режиме» и «локальном режиме через COM+», а также в качестве сервера в удаленных режимах, использовался компьютер со следующими параметрами:
В качестве клиентской машины в удаленных режимах использовался компьютер со следующими параметрами:
В удаленных режимах использовалась локальная сеть Ethernet 10BaseT (10 Мегабит/с).
В «in-process режиме» (без использования COM+) весь исполняемый код находился в клиентском exe-приложении, то есть приложение напрямую работало с базой данных, минуя промежуточное копирование данных и передачу их между процессами.
Этот режим является типичным для работы web-приложений.
Во всех остальных режимах работа велась через отдельный промежуточный (middleware) COM-объект, создаваемый в другом процессе («локальный режим через COM+») или на удаленном компьютере («удаленный режим через COM+» и «удаленный режим через NET Remoting»). В этом объекте происходило получение result-set’a, данные из которого затем возвращались клиентскому приложению. Для передачи данных между процессами использовались объекты ascCachedCursor (ascDB), Recordset (ADO) и DataSet (ADO.NET) (они возвращались клиентскому приложению методами промежуточного объекта).
Аналог «локального режима через COM+», за исключением того, что вместо COM+ использовалась технология NET Remoting. В этом режиме тестировался только ADO.NET.
Аналог «локального режима через COM+», за исключением того, что на клиентской машине был установлен COM+ proxy, и передача данных осуществлялась не между процессами на одной машине, а по сети.
Аналог «локального режима через NET Remoting» за исключением того, что передача данных осуществлялась не между процессами на одной машине, а по сети. Этот режим тестировался только для ADO.NET.
Выполнялись следующие тесты:
В этом тесте мы пытались работать с очень большой таблицей в forward-only режиме. Основной особенностью такой работы является быстрое получение на клиента первой (маленькой) части записей с возможностью последующего дочитывания данных.
Такой метод зачастую применялся раньше в случаях, когда результирующая выборка может потенциально иметь большой объем, но пользователю требуется постраничная прокрутка. При этом все время жизни клиентской сессии должна сохраняться связь с БД. Иногда применялся прием, при котором связь с БД разрывалась, но при запросе следующей страницы производилась прокрутка до нужной страницы и считывание нужного блока. Особенности forward-only-курсора позволяют быстро получить первые записи выборки (так как SQL Server, по сути, использует алгоритм выборки и хранит позицию, а физическая выборка осуществляется в момент пролистывания курсора на клиенте). Эти особенности позволяют очень быстро осуществлять пропускание ненужных записей. Однако оказалось, что сейчас не все средства доступа к БД поддерживают этот режим работы. Так, оказалось, что ADO.NET предназначено исключительно для отключенного режима работы и, как следствие, показывает плохие результаты, если производится неполное считывание данных, возвращаемых запросом. Но об этом немного позже.
Во всех режимах тестирования, кроме in-process, на серверной стороне выполнялся запрос «select * from Orders1000000» (в таблице 1 млн. записей). Затем первый блок данных (100 строк) передавался на клиентскую сторону, где по ним выполнялся перебор (fetch) с копированием данных в переменные класса (переменные класса использовались во избежание потенциальной оптимизации компилятором).
В in-process режиме запрос выполнялся на клиентской стороне без отключения от БД. В связи с этим в ADO.NET в этом режиме использовался SqlDataReader, а не SqlDataAdapter.
Затем выполнялось переоткрытие курсора. Использовались forwardonly-курсоры или их аналоги (SqlDataReader в ADO.NET). В тестах ADO.NET для всех режимов, кроме in-process, forwardonly-курсор имитировался поблочным копированием данных в промежуточные объекты DataSet, которые затем пересылались в клиентское приложение (подробности см. ниже, в описании этого теста для ADO.NET). Выполнялось 10 повторов.
Вообще хочется отметить, что первый запуск любого из тестов на ADO.NET заметно тормозит. Причем не только первый, но и второй, и третий запуски могут выполняться значительно медленнее, чем последующие. На рисунке 1 приведен типичный пример выполнения теста ADO.NET.
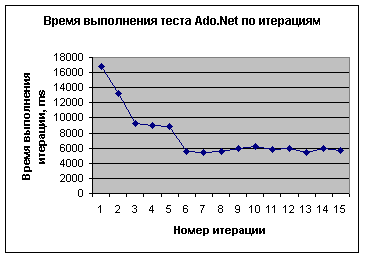
Рисунок 1
Как видно из графика на рисунке 1, время выполнения теста в первый раз примерно втрое превосходит «устоявшееся» значение (получаемое начиная с 6-й итерации). Время выполнения итераций с 1-й по 6-ю постепенно уменьшается и не может быть использовано для анализа «средней скорости» выполнения теста, поскольку не является «типичным». Как будет показано ниже, ADO.NET пытается кэшировать содержимое всего resultset’a. Это приводит не только к тому, что все данные копируются на клиента, но и к тому, что SQL-сервер вынужден обращаться ко всем данным большой таблицы. Особенности SQL-сервера таковы, что он выходит на оптимальный режим работы (производит полное кэширование таблицы и оптимизирует план выборки) только к какой-то N-й итерации. Увеличение объема оперативной памяти должно уменьшить количество итераций до выхода на оптимальный режим.
Однако это не имеет существенного значения для серверных приложений. Уже после первого десятка запусков ситуация нормализуется и ADO.NET выйден на оптимальный (по скорости) режим работы.
В тестах других продуктов (ADO, ascDB) все запуски, кроме первого, как правило, имели разброс значений не более 10%.
В качестве аналога forward-only курсора в ADO.NET был использован SqlDataReader. Выполнялось пересоздание объекта SqlDataReader и считывание первых 100 записей из него методом Read. Основной код теста выглядит так:
// Переменные для хранения считанных данных int m_iOrderID = 0; string m_sCustomerID = ""; int m_iEmployeeID = 0; DateTime m_dtOrderDate = DateTime.Now; DateTime m_dtRequiredDate = DateTime.Now; DateTime m_dtShippedDate= DateTime.Now; int m_iShipVia = 0; decimal m_decFreight = 0; string m_sShipName = null; string m_sShipAddress = null; string m_sShipCity = null; string m_sShipRegion = null; string m_sShipPostalCode = null; string m_sShipCountry = null; // Позволяет получить все данные из строки SqlDataReader'a protected void RowDataLoadFromReader(SqlDataReader sdr) { // Заполнить переменные m_iOrderID = sdr.GetInt32(0); m_sCustomerID = sdr.GetString(1); m_iEmployeeID = sdr.GetInt32(2); m_dtOrderDate = sdr.GetDateTime(3); m_dtRequiredDate = sdr.GetDateTime(4); m_dtShippedDate= sdr.GetDateTime(5); m_iShipVia = sdr.GetInt32(6); m_decFreight = sdr.GetDecimal(7); m_sShipName = sdr.GetString(8); m_sShipAddress = sdr.GetString(9); m_sShipCity = sdr.GetString(10); m_sShipRegion = sdr.GetString(11); m_sShipPostalCode = sdr.GetString(12); m_sShipCountry = sdr.GetString(13); } // Фрагмент кода метода, в котором выполняется создание // и открытие объекта SqlDataReader с последующим // переходом по записям и чтением данных protected const string csConnectionString = "Integrated Security=SSPI;Persist Security Info=False; " + "Initial Catalog=ascCursorTest"; using(cnnConnection = new SqlConnection(csConnectionString)) using(SqlCommand cmdCommand = cnnConnection.CreateCommand()) { cnnConnection.Open(); cmdCommand.CommandText = sSqlSelect; sdrReader = cmd.ExecuteReader(); for(int j = 0; j < iFetchNexCount; ++j) { // Переходить на след. запись с чтением данных sdrReader.Read(); RowDataLoadFromReader(sdrReader); } } |
В процессе отладки оказалось, что даже если вызывать только метод SqlDataReader.Read (без вызова методов SqlDataReader.GetXXX), разницы во времени практически нет – очевидно, что при вызове метода Read объект SqlDataReader честно считывает из курсора БД все данные, относящиеся к новой строке. Однако: «порядок есть порядок» (с) народная немецкая поговорка.
В результате переноса кода работы с БД в middleware-объект, объект SqlDataReader оказался «отрезанным» от клиента. Поскольку кэширование миллиона записей для передачи их в клиентское приложение не выглядит разумным, было решено сделать «довесочек» к ADO.Net в виде ручного пролистывания курсора.
На первый взгляд задача, выполняемая в этом тесте, может показаться «высосанной из пальца», однако это не так. Поблочное чтение информации используется, например, при пролистывании большой таблицы (скажем, по 100 записей за раз).
Казалось бы, для реализации поблочного чтения данных лучше всего подходит SqlDataAdapter. Все, что надо сделать для заполнения блока с использованием объекта SqlDataAdapter, так это вызвать его метод Fill, в параметры которого передать начальный номер записи и количество записей в блоке.
Это и было сделано. Чтение данных из объекта SqlDataAdapter выполнялось поблочно (по 100 записей), эти блоки в виде объектов DataSet отправлялись клиенту. На клиенте блоки принимались и копировались в конец основного объекта DataSet. Таким образом имитировался forwardonly-курсор на ADO.NET (см. код примера ниже).
И действительно, пока тестировалось получение только первого блока (первые 100 записей), время выполнения теста выглядело терпимо и почти не отличалось от «in-process режима», где использовался SqlDataReader (примерно 5.5 секунд).
Однако увеличение количества блоков до пяти (500 записей) привело в возрастанию затрат времени на их получение почти до полуминуты, а считывание 25-ти блоков заняло, соответственно, 2.5 минуты.
Очевидно, что объект SqlDataAdapter каждый раз для получения нового блока данных внутри себя переоткрывает SqlDataReader и копирует данные из него в DataSet.
Но даже результат, достигнутый с использованием SqlDataReader (5.5 секунды), совершенно неприемлем для выборки первых 100 записей. С чем же это связано, спросите вы. Эксперименты показали, что, вероятнее всего, это происходит из-за слишком большого предварительного кэширования внутри объекта DataReader при обращении к большой таблице. Хотя нами выбирались всего 100 первых записей, было отчетливо заметно, что Reader кэшировал сотни тысяч записей. Такое предположение было сделано на основании двух экспериментов. В первом мы физически ограничили запрос 100 записями (добавив «top 100» в SQL-запрос), а во втором мы попытались пролистать несколько сот тысяч записей. В первом случае запрос начал выполняться молниеносно, а во втором на каждые 100 тыс. записей уходило примерно по 1.2 секунды. Скорее всего, это время затрачивается Reader на считывание данных из кэша. Более подробно результаты работы SqlDataReader представлены в таблице 2. Отсюда можно заключить, что, работая с ADO.NET, а особенно с SQL-провайдером, нужно избегать запросов, потенциально способных вернуть большое количество строк. Для этого можно принудительно ограничивать количество записей непосредственно в запросе оператором «top xxx». Второй вывод – ADO.NET может оказаться идеальным средством для скачивания очень больших объемов данных, т.к. вышеописанное поведение приводит к повышению скорости считывания больших объемов данных. Как видно из той же таблицы, разница между считыванием одной и 800 тыс. записей составила 3 раза, тогда как другие средства доступа к БД дают одну запись практически мгновенно, а считывание всего resultset’a производят медленнее.
Любопытство заставило собрать аналогичный тест с использованием объекта SqlDataReader вместо объекта SqlDataAdapter. К сожалению, чтение из объекта SqlDataReader возможно только по одной записи, поэтому пришлось выполнить некоторое количество промежуточных действий по созданию и заполнению DataSet’а (см. код примера ниже).
Несмотря на промежуточные действия по копированию данных, на больших объемах использование объекта SqlDataReader оказалось предпочтительнее. Результаты сравнения представлены в таблице 1.
| Прокрутка на N записей (в скобках количество блоков), одна итерация: | SqlDataReader | SqlDataAdapter |
|---|---|---|
| 1 (1 блок) | 5.598 | 5.508 |
| 100 (1 блок) | 5.899 | 5.508 |
| 500 (5 блоков) | 6.88 | 28.301 |
| 2500 (25 блоков) | 7.661 | 142.945 |
Время выполнения операций по чтению первых 100 записей в обоих случаях оказалось почти одинаковым. Отдельным тестом было установлено, что почти не имеет значения, с какой позиции начинать чтение. Почти все время тратится на повторное открытие SqlDataReader (при использовании SqlDataAdapter объект SqlDataReader переоткрывается неявно при каждом вызове метода Fill). Считывание 100 тыс. записей занимает примерно 1.2 секунды. Любопытно, что объект SqlDataReader не имеет метода, аналогичного методу Skip в ADODb.Recordset. Однако, как показали наши эксперименты, вызов в цикле метода SqlDataReader.Read выполняется очень быстро, и его вызов в цикле может служить заменой методу Skip (что, кстати, и делает SqlDataAdapter). Но не надо забывать, что такая высокая скорость пролистывания SqlDataReader связана с тем, что все данные запроса уже кэшированы, и Read реально почти ничего не делает.
Из вышесказанного следует вывод, что для чтения первого небольшого блока данных можно использовать SqlDataAdapter и не мучиться с объектом SqlDataReader. Однако вообще считывание части resultset’а в ADO.NET крайне неэффективно.
Когда количество блоков доходит до трех-пяти (размер блока 100 записей), то работа через SqlDataReader становится предпочтительнее (не забывайте, что мы производим докачку, и при считывании каждого блока SqlDataAdapter переоткрывает SqlDataReader). Из таблицы 1 видно, что время, затрачиваемое объектом SqlDataAdapter на чтение новых блоков данных, возрастает почти прямо пропорционально количеству блоков (1 блок – 5 секунд, 5 блоков – 28 секунд, 25 блоков – 143 секунды). Тогда как объект SqlDataReader справляется с возрастанием количества считываемых блоков без особого напряжения (1 блок - 6 секунд, 25 блоков – 8 секунд).
Единственная серьезная проблема при работе с объектом SqlDataReader заключается в том, что на одном SqlConnection может быть открыт только один SqlDataReader.
В тесте «Forward» для реализации подобия forward-only курсора на ADO.NET были опробованы оба варианта. Тест с объектом SqlDataReader выполнялся быстрее, поэтому здесь приводятся приводятся именно его результаты (см. ниже таблицы с результатами теста «Forward» в режимах тестирования через COM+ и NET Remoting).
Примеры основного кода поблочного чтения для клиента (клиентское приложение) и сервера (middleware-объект, зарегистрированный в COM+-приложении) приведены ниже. Для серверной стороны даны два варианта реализации функции Orders1000000Fetch: через SqlDataReader и через SqlDataAdapter.
// КЛИЕНТ // Код получения следующего блока данных с сервера (клиент) protected bool CursorFetchNextServer(int iFetchCount, bool bReopen) { bool bRet = false; DataSet dsDataSetFetched = null; try { // m_mwoIntf – ссылка на интерфейс middleware-объекта // Метод Orders1000000Fetch возвращает следующий блок данных bRet = m_mwoIntf.Orders1000000Fetch(iFetchCount, out dsDataSetFetched, bReopen); if(null == m_dsDataSet) m_dsDataSet = new DataSet("DefaultName"); // Если основной DataSet не имеет таблицы, копируем ее описание // из таблицы объекта DataSet, полученного с сервера if(m_dsDataSet.Tables.Count <= 0) m_dsDataSet.Tables.Add(dsDataSetFetched.Tables[0].Clone()); for(int i = 0; i < dsDataSetFetched.Tables[0].Rows.Count; ++i) { // Добавить новую строку в основной DataSet, копируя в нее данные // из DataSet с блоком данных, полученных с сервера m_dsDataSet.Tables[0].Rows.Add( dsDataSetFetched.Tables[0].Rows[i].ItemArray); } } finally { if(dsDataSetFetched != null) dsDataSetFetched.Dispose(); } return bRet; } // Код прокрутки курсора на iFetchNexCount записей (клиент) const int ciFetchBufSize = 100; int iFetchBufCounter = 0; for(int j = 0; j < iFetchNexCount; ++j) { ++iFetchBufCounter; if(iFetchBufCounter > ciFetchBufSize) { CursorFetchNextServer(ciFetchBufSize); iFetchBufCounter = 0; } } // СЕРВЕР // Sql-запрос для имитации forward-only курсора protected const string csSqlOrders1000000SelectAll = "select * from Orders1000000"; // Эти переменные используются для имитации forward-only курсора. // Поэтому они объявлены как переменные класса, а не создаются // локально в "using" #if CompileWithSqlClient protected SqlConnection m_cnnLarge; protected SqlDataAdapter m_sdaLarge; protected SqlDataReader m_sdrLarge; #else protected OleDbConnection m_cnnLarge; protected OleDbDataAdapter m_sdaLarge; protected OleDbDataReader m_sdrLarge; #endif // Переменная m_iOrders1000000FetchAdapterCount определяет, // на сколько записей уже прокрутили адаптер protected int m_iOrders1000000FetchAdapterCount = 0; // Позволяет закрыть SqlDataReader и обнулить счетчик // считанных записей для объекта SqlDataAdapter public void Orders1000000Close() { if(m_sdrLarge != null && !m_sdrLarge.IsClosed) { m_sdrLarge.Close(); m_sdrLarge = null; } if(m_sdaLarge != null) { m_sdaLarge.Dispose(); m_sdaLarge = null; } if(m_cnnLarge != null) { m_cnnLarge.Dispose(); m_cnnLarge = null; } m_iOrders1000000FetchAdapterCount = 0; } // Позволяет открыть SqlConnection // При использовании объекта SqlDataReader нельзя закрывать // SqlConnection, так что для дочитки данных приходится хранить // соединение в поле m_cnnLarge объекта. protected void Orders1000000ConnectionOpen() { if(null == m_cnnLarge) #if CompileWithSqlClient m_cnnLarge = new SqlConnection(csConnectionString); #else m_cnnLarge = new OleDbConnection(csConnectionString); #endif if(0 == m_cnnLarge.State) m_cnnLarge.Open(); } // *************************** // *** Получение блока через SqlDataAdapter // Код получения следующего блока данных через SqlDataAdapter (сервер) protected bool Orders1000000FetchAdapter( int iFetchCount, out DataSet dsDataSetFetched, bool bReopen) { dsDataSetFetched = null; if(bReopen) Orders1000000Close(); // Просят переоткрыть // Создать Adapter, если его нет Orders1000000ConnectionOpen(); if(null == m_sdaLarge) #if CompileWithSqlClient m_sdaLarge = new SqlDataAdapter(csSqlOrders1000000SelectAll, m_cnnLarge); #else m_sdaLarge = new OleDbDataAdapter(csSqlOrders1000000SelectAll, m_cnnLarge); #endif dsDataSetFetched = new DataSet(); m_sdaLarge.Fill(dsDataSetFetched, m_iOrders1000000FetchAdapterCount, iFetchCount, "Orders1000000"); return (null != dsDataSetFetched.Tables[0] && dsDataSetFetched.Tables[0].Rows.Count == iFetchCount); } // *************************** // *** Получение блока через SqlDataReader // Проинициализировать колонки таблицы объекта DataSet protected void InitColumnInfo(DataRow drRow, DataColumn dcColumn) { dcColumn.ColumnName = (string)drRow["ColumnName"]; dcColumn.MaxLength = (int)drRow["ColumnSize"]; dcColumn.Unique = (bool)drRow["IsUnique"]; dcColumn.DataType = (Type)drRow["DataType"]; dcColumn.AllowDBNull = (bool) drRow["AllowDBNull"]; dcColumn.AutoIncrement = (bool) drRow["IsAutoIncrement"]; dcColumn.ReADOnly = (bool)drRow["IsReADOnly"]; } // Код получения следующего блока данных через SqlDataReader (сервер) protected bool Orders1000000FetchReader( int iFetchCount, out DataSet dsDataSetFetched, bool bReopen) { dsDataSetFetched = null; if(bReopen) Orders1000000Close(); // Просят переоткрыть // Создать SqlReader, если его нет if(null == m_sdrLarge || m_sdrLarge.IsClosed) { Orders1000000ConnectionOpen(); #if CompileWithSqlClient using(SqlCommand cmd = m_cnnLarge.CreateCommand()) #else using(OleDbCommand cmd = m_cnnLarge.CreateCommand()) #endif { cmd.CommandText = csSqlOrders1000000SelectAll; if(0 == m_cnnLarge.State) m_cnnLarge.Open(); m_sdrLarge = cmd.ExecuteReader(); } } // Создать и заполнить SqlDataSet с данными по прокрученным строкам object[] ItemArray = new object[m_sdrLarge.FieldCount]; dsDataSetFetched = new DataSet("DefaultName"); using(DataTable dtSchemaTable = m_sdrLarge.GetSchemaTable()) { dsDataSetFetched.Tables.Add("Orders1000000"); // добавить колонки for (int i = 0; i < dtSchemaTable.Rows.Count; i++) { using(DataColumn dcColumn = new DataColumn()) { // Создать колонку, проинициализировать ее // и добавить в коллекцию колонок InitColumnInfo(dtSchemaTable.Rows[i], dcColumn); dsDataSetFetched.Tables[0].Columns.Add(dcColumn); } } } // Добавить значения for(int i = 0; i < iFetchCount; ++i) { if(!m_sdrLarge.Read()) return false; m_sdrLarge.GetValues(ItemArray); dsDataSetFetched.Tables[0].Rows.Add(ItemArray); } return true; } |
Чтобы middleware-объект успешно регистрировался и работал через COM+, его нужно реализовать как COM-объект. Для этого в подразделе Build раздела настроек конфигурации (Configuration Properties) в настройках проекта (Project Properties) значение настройки “Register for COM interop” было установлено в true.
Класс MWO1 (middleware-объект) наследовался от System.EnterpriseServices.ServicedComponent и интерфейса ITest, описанного в той же библиотеке, что и объект MWO1 (файл «MWO1.cs»). Вот основной код описаний из этого файла:
using System; using System.Data; using System.Data.SqlClient; using System.EnterpriseServices; using System.Runtime.InteropServices; namespace SpeedTest_ADONet_server { [GuidAttribute("AA712B8A-2170-4818-B220-DA38A21D808E")] [InterfaceType(ComInterfaceType.InterfaceIsDual)] public interface ITest { // Описание методов интерфейса //… // Метод Orders1000000Fetch приведен для примера [DispId(12)] bool ITest.Orders1000000Fetch(int iFetchCount, out DataSet dsDataSetFetched, bool bReopen) //… } /// <summary> /// Класс реализует middleware-объект для теста ADO.NET /// </summary> [GuidAttribute("F68D09A4-940E-48ba-8397-ABE2C20D36F7")] [ClassInterface(ClassInterfaceType.None)] public class MWO1 : System.EnterpriseServices.ServicedComponent, ITest { // Реализация методов интерфейса ITest //… // Метод Orders1000000Fetch приведен для примера bool ITest.Orders1000000Fetch(int iFetchCount, out DataSet dsDataSetFetched, bool bReopen) { dsDataSetFetched = null; // Если объявлено TestForwardWithReader, // то работать через SqlDataReader, // иначе через SqlDataAdapter #if TestForwardWithReader return Orders1000000FetchReader(iFetchCount, out dsDataSetFetched, bReopen); #else return Orders1000000FetchAdapter(iFetchCount, out dsDataSetFetched, bReopen); #endif } //... } } |
Некоторые изменения были внесены и в файл «AssemblyInfo.cs» (в проекте middleware-объекта). Ниже приведено содержание этого файла:
using System.Reflection; using System.Runtime.CompilerServices; using System.EnterpriseServices; using System.Runtime.InteropServices; // Эти атрибуты добавлены для COM+ [assembly: ApplicationName("SpeedTest_ADONet_server")] [assembly: ApplicationID("433647B6-98C0-4a43-BA17-60FBF574F2D3")] [assembly: ApplicationActivation(ActivationOption.Server)] [assembly: Guid("747800AE-3337-44d1-B5A5-7862963BFA9B")] // Эти атрибуты были в файле изначально [assembly: AssemblyTitle("")] [assembly: AssemblyDescription("")] [assembly: AssemblyConfiguration("")] [assembly: AssemblyCompany("")] [assembly: AssemblyProduct("")] [assembly: AssemblyCopyright("")] [assembly: AssemblyTrademark("")] [assembly: AssemblyCulture("")] // Версия библиотеки указана жестко как "1.0.0", а не "1.0.*", // поскольку иначе при удаленном режиме работе через COM+ // сбивается совместимость с exe-файлом клиентского приложения // при каждой перекомпиляции серверного проекта. [assembly: AssemblyVersion("1.0.0")] // В атрибуте AssemblyKeyFile указан путь до файла с уникальным // ключом, который будет использован для генерации StrongName. // StrongName необходимо для работы в удаленном режиме. // Сгенерировать snk-файл можно утилитой sn.exe // (например, запустив ее с командной строки: "sn.exe -k XXX.snk", // где XXX.snk – имя выходного файла, содержащего StrongName). // Эта утилита находится в подкаталоге FrameworkSDK\Bin корневого // каталога Visual Studio.NET. [assembly: AssemblyDelaySign(false)] [assembly: AssemblyKeyFile("..\\..\\SpeedTest_ADONet_server.snk")] [assembly: AssemblyKeyName("")] |
После компиляции библиотеки она была зарегистрирована в GAC (global assembly cache) утилитой gacutil.exe. Эта утилита может быть найдена в подкаталоге FrameworkSDK\Bin корневого каталога Visual Studio NET. Командные строки регистрации приведены ниже:
gacutil /u SpeedTest_ADONet_server gacutil /i SpeedTest_ADONet_server.dll |
При регистрации в GAC библиотека копируется в отдельный каталог (кэшируется). Поэтому после ее перекомпиляции нужно отрегистрировать старую версию (при этом она удаляется из кэша) и только затем зарегистрировать новую, иначе изменения «не будут замечены» (будет загружаться старый объект из кэшированной библиотеки).
Помимо регистрации в GAC объекты из библиотеки SpeedTest_ADONet_server.dll были зарегистрированы в COM+ через утилиту regsvcs, которая может быть найдена в подкаталоге Microsoft.NET\Framework\v1.0.3705 системного каталога (разумеется, номер версии не обязательно будет 1.0.3705). Командная строка регистрации приведена ниже:
regsvcs /tlb:SpeedTest_ADONet_server.tlb SpeedTest_ADONet_server.dll |
Для регистрации на удаленном компьютере (клиенте) средствами COM+ (system32\Com\comexp.msc) был создан proxy. Этот proxy был установлен на клиентской машине. Туда же было скопировано клиентское приложение и библиотека SpeedTest_ADONet_server.dll.
Для работы через COM+ в коде приложения было реализовано создание удаленного middleware-объекта MWO1. Ниже приведен пример кода создания этого объекта:
// Получить тип Type type = Type.GetTypeFromCLSID( new Guid("F68D09A4-940E-48ba-8397-ABE2C20D36F7"), sServerName); // Создать экземпляр объекта m_mwoComPlus = (MWO1)Activator.CreateInstance(type); // Протестировать вызов. Именно в этот момент объект будет реально создан. m_mwoComPlus.TestCall(); |
Принцип имитации forward-only-курсора (получения и передачи данных) тот же, что и в «локальном режиме через COM+», т.е. создается промежуточный (middleware) объект, работающий с БД, и клиентское приложение, обращающееся к нему. В этом случае данные копируются «через процесс» (выполняется маршалинг). Однако механизм взаимодействия изменился – используется NET Remoting вместо COM+. В чем проявляются отличия?
Во-первых, вместо регистрации в COM+, middlerware-объект создавался в процессе серверного exe-приложения (Console Application в понятиях NET), которое предварительно запускалось на серверной машине. Во-вторых для передачи данных между процессами использовался протокол TCP (данные паковались в бинарный формат: formatter ref="binary" />).
Пример кода серверного приложения представлен ниже:
using System; using System.Runtime.Remoting; namespace SpeedTest_ADONet_RemotingServer { class ServerConsolApp { [STAThread] static void Main(string[] args) { RemotingConfiguration.Configure( "SpeedTest_ADONet_RemotingServer.exe.config"); Console.WriteLine("Running..."); Console.ReadLine(); } } } |
Конфигурация сервера из файла SpeedTest_ADONet_RemotingServer.exe.config приведена ниже:
<configuration>
<system.runtime.remoting>
<application name="SpeedTest_ADONet_RemotingServer">
<service>
<wellknown mode="Singleton"
type="SpeedTest_ADONet_RemotingServer.Server,
SpeedTest_ADONet_RemotingServer" objectUri="Server.rem" />
</service>
<channels>
<channel ref="tcp" port="8008">
<serverProviders>
<formatter ref="binary" />
</serverProviders>
</channel>
</channels>
</application>
</system.runtime.remoting>
</configuration>
|
В этой же области видимости (namespace) был реализован объект Server, в котором и была реализована вся функциональность работы с базой данных. Ниже приведен его код:
using System; using System.Data; using System.Data.SqlClient; using SpeedTest_ADONet_server; // Только для интерфейса ITest namespace SpeedTest_ADONet_RemotingServer { public class Server: MarshalByRefObject, ITest { // Этот класс во всем подобен классу MWO1 // из библиотеки SpeedTest_ADONet_Server // (см. выше, в тесте COM+), однако унаследован // не от ServicedComponent, а от MarshalByRefObject //… } } |
Принцип имитации forwardonly-курсора (получения и передачи данных) тот же, что и в «локальном режиме через COM+» теста «Forward». На клиентской машине устанавливается proxy серверного COM+-приложения.
Принцип имитации forwardonly курсора (получения и передачи данных) тот же, что и в «локальном режиме через NET Remoting» теста «Forward».
В качестве forward-only курсора использовался объект Recordset с установкой значений свойств: CursorType в ADOpenForwardOnly, LockType в adLockReADOnly и CursorLocation в adUseServer. Размер кэша устанавливался равным 100 записям (свойство CacheSize). Переход по записям осуществлялся с помощью вызова метода MoveNext.
Основной код теста приведен ниже:
' Импорт системной функции GetTickCount для подсчета времени ' выполнения тестов Private Declare Function GetTickCount Lib "Kernel32" () As Long ' Переменные для считывания данных Dim m_iOrderID As Long Dim m_sCustomerID As String Dim m_iEmployeeID As Long Dim m_dtOrderDate As Date Dim m_dtRequiredDate As Date Dim m_dtShippedDate As Date Dim m_iShipVia As Long Dim m_decFreight As Currency Dim m_sShipName As String Dim m_sShipAddress As String Dim m_sShipCity As String Dim m_sShipRegion As String Dim m_sShipPostalCode As String Dim m_sShipCountry As String ' Считывает все данные из строки таблицы DataSet'a Private Sub RowDataLoad(ByRef ars As Recordset) If ars.EOF Or ars.BOF Then Exit Sub ' Заполнить переменные m_iOrderID = ars(0).Value m_sCustomerID = ars(1).Value m_iEmployeeID = ars(2).Value m_dtOrderDate = ars(3).Value m_dtRequiredDate = ars(4).Value m_dtShippedDate = ars(5).Value m_iShipVia = ars(6).Value m_decFreight = ars(7).Value m_sShipName = ars(8).Value m_sShipAddress = ars(9).Value m_sShipCity = ars(10).Value m_sShipRegion = ars(11).Value m_sShipPostalCode = ars(12).Value m_sShipCountry = ars(13).Value End Sub ' Позволяет перезаполнить Resultset Protected Sub CursorReopen() If adStateClosed <> m_rs.State Then m_rs.Close m_rs.Open End Sub ' Выполняется iIterationCount итераций ' В каждой итерации выполняется iFetchNexCount прокруток ' курсора (на входе он уже открыт). ' Затем выполняется переоткрытие курсора. ' Отдельно считается время выполнения всех прокруток ' и переоткрытий курсора For i = 0 To iIterationCount - 1 ' fetch iStartTimeTmp = GetTickCount m_rs.MoveFirst For j = 0 To iFetchNexCount - 1 If Not m_rs.EOF Then m_rs.MoveNext RowDataLoad ars End If Next iFetchSumTime = iFetchSumTime + GetTickCount - iStartTimeTmp ' reopen CursorReopen iStartTimeTmp = GetTickCount iReopenSumTime = iReopenSumTime + GetTickCount - iStartTimeTmp Next |
Поскольку в ADO отсутствует возможность получения отключенного однонаправленного курсора, обеспечение передачи данных в forward-only режиме между процессами или по сети оказалось затруднительным. Конечно, можно было бы немножко попрограммировать, и посылать на клиента порции данных, запакованные в отдельные отключенные объекты Recordset, собирая их по прибытии в один большой Recordset. Однако в качестве примера это уже было сделано в тесте ADO.NET – повторение не представляет особого интереса (принцип ясен).
Копирование же всего курсора между процессами или по сети представляется нецелесообразным (в таблице – миллион записей). Однако, для чистоты эксперимента, такой опыт все же был проведен.
Этот тест выполнялся единожды (то есть время замерено только по одной итерации). Общее время по десяти итерациям, представленное в таблице, получено умножением на десять.
В коде клиентской стороны произошло единственное изменение: для переоткрытия курсора вместо последовательного вызова методов Close и Open от объекта m_rs (см. код примера теста «Forward» в «in-process режиме») стал вызываться метод Orders1000000SelectAll middleware-объекта. Код middleware-объекта приведен ниже (код инициализации и метод GetDisconnectedCursor применялся и в остальных тестах ADO, поэтому в дальнейшем тексте будут ссылки сюда):
' Инициализация middleware-объекта Dim m_cnn As Connection Const csConnectionString As String = _ "Provider=sqloledb;Initial Catalog=ascCursorTest;Integrated Security=SSPI" Private Sub Class_Initialize() Set m_cnn = New Connection m_cnn.Open csConnectionString End Sub ' Метод, позволяющий получить отключенный Recordset Private Sub GetDisconnectedCursor(ByRef Cursor As ADODB.Recordset, ByVal sSql As String ) Set Cursor = New ADODB.Recordset With Cursor Set .ActiveConnection = m_cnn .CursorLocation = adUseClient .CursorType = ADOpenStatic .LockType = adLockBatchOptimistic .Source = sSql .CacheSize = 100 .Open .ActiveConnection = Nothing ' Отключиться от базы данных End With End Sub ' Метод, который вызывается с клиента Public Sub Orders1000000SelectAll(ByRef Cursor As Recordset) GetDisconnectedCursor Cursor, "select * from Orders1000000" End Sub |
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+» теста «Forward». На клиентской машине устанавливается proxy серверного COM+-приложения.
Значение времени выполнения этого теста получено не вполне корректно, поскольку где-то к его середине система сообщила пренеприятнейшее известие: ”low virtual memory”. Очевидно, что если бы не это ужасное событие, то тест выполнился бы быстрее.
Этот тест выполнялся единожды (то есть время замерено только по одной итерации). Общее время по десяти итерациям, представленное в таблице, получено умножением на десять.
В качестве forward-only курсора использовался объект ascVisualCursor с установкой значений свойств rsDBCursorType равным actForward. Размер кэша устанавливался равным 100 записям (свойство rsFetchBufferSize). Переход по записям осуществлялся с помощью вызова метода FetchNext.
Вся работа с SQL-сервером уже на этом этапе вынесена в промежуточный объект, но библиотека с этим объектом зарегистрирована локально (не через COM+), то есть загружается в процессе клиентского приложения (in-process). Для получения курсора клиентское приложение вызывает метод middleware-объекта, в котором загружается и выполняется предварительно настроенная «хранимая команда» ascDB. Хранимая команда ascDB – это команда, хранимая на диске в виде файла. Она может быть создана и записана с помощью дизайнера команд. Результатом выполнения команды является курсор (объект ascCachedCursor). Этот объект передается в клиентское приложение в качестве возвращаемого параметра вызванного метода middleware-объекта и может подключаться к визуальному курсору.
Вызов метода middleware-объекта и подключение кэширующего курсора (ascCachedCursor) к визуальному курсору автоматизирован и настраивается на странице свойств визуального курсора, поэтому соответствующий код отсутствует в статье. Однако вместо визуального курсора в ascDB можно воспользоваться кэширующим курсором. В этом случае для получения данных (передаваемых в объекте ascCachedCursor) нужно явно (из кода программы) вызывать методы middleware-объекта. Затем, также программно, нужно подключать полученный полученный ascCachedCursor к визуальному курсору, который связан с элементами управления, отображающими данные (ascDataGrid и ascDataField).
В ascDB существует также возможность работы напрямую с базой данных – минуя middleware-объект и обходясь без команд. Для этого надо непосредственно в коде клиентского приложения реализовать работу через объект ascServer. Пример такого кода можно увидеть в тестах «Top10» и «Top100» ascDB.
Однако наилучшим образом проиллюстрировать многоуровневую архитектуру ascDB позволяет именно использование middleware-объекта и хранимых команд. Кроме того, такой подход позволяет практически всю работу выполнить визуально и является типичным для ascDB.
Ниже приведен основной код теста (через объект scVisualCursor):
' *** Код приложения ' Считывает все данные из строки визуального курсора Private Sub RowDataLoad(ByRef avc As ascVisualCursor) If avc.IsEOF Then Exit Sub ' Заполнить переменные If (avc(1).Value.IsNull) Then m_iOrderID = 0 Else m_iOrderID = avc(1).Value.AsLong End If m_sCustomerID = avc(2).Value.AsLong m_iEmployeeID = avc(3).Value.AsLong m_dtOrderDate = avc(4).Value.AsDateTime m_dtRequiredDate = avc(5).Value.AsDateTime m_dtShippedDate = avc(6).Value.AsDateTime m_iShipVia = avc(7).Value.AsLong m_decFreight = avc(8).Value.AsMoney m_sShipName = avc(9).Value.AsString m_sShipAddress = avc(10).Value.AsString m_sShipCity = avc(11).Value.AsString m_sShipRegion = avc(12).Value.AsString m_sShipPostalCode = avc(13).Value.AsString m_sShipCountry = avc(14).Value.AsString End Sub ' Выполняется iIterationCount итераций. ' В каждой итерации выполняется iFetchNexCount прокруток ' курсора (на входе он уже открыт). ' Затем выполняется переоткрытие курсора. ' Отдельно считается время выполнения всех прокруток ' и переоткрытий курсора. For i = 0 To iIterationCount - 1 ' fetch iStartTimeTmp = GetTickCount For j = 0 To iFetchNexCount - 1 avc.FetchNext RowDataLoad ars Next iFetchSumTime = iFetchSumTime + GetTickCount - iStartTimeTmp ' reopen iStartTimeTmp = GetTickCount avcOrders1000000.Reopen iReopenSumTime = iReopenSumTime + GetTickCount - iStartTimeTmp Next ' *** Код middleware-объекта ' Инициализация. Создается ascServer и открывается ascSession. Dim m_srv As ascServer Dim m_sn As ascSession Const csCommandPath As String = "Tests\ascCursorTest\" Private Sub Class_Initialize() Set m_srv = New ascServer Set m_sn = m_srv("ascCursorTest").GetDefaultSession End Sub ' Метод middleware-объекта, который загружает и исполняет хранимую ' команду Orders1000000SelectAll. ' В команде Orders1000000SelectAll выполняется следующий sql-запрос: ' «select * from Orders1000000» Public Sub Orders1000000SelectAll(ByRef Cursor As ascCachedCursor) Dim cmd As ascCommand ' Загрузить хранимую команду "Orders1000000SelectAll" из каталога csCommandPath1 Set cmd = m_srv.LoadCommand(csCommandPath + "Orders1000000SelectAll") ' Выполнить команду и вернуть курсор cmd.Execute Cursor End Sub |
Принцип получения и передачи данных остался тем же, что и в in-process режиме: для передачи данных между процессами использовался объект ascCachedCursor, в котором содержались (кэшировались) все данные, полученные в результате запроса к SQL-серверу.
Короче говоря, все полностью так же, как и в «in-process режиме», но библиотека с промежуточным объектом зарегистрирована в COM+-приложении.
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+» теста «Forward». На клиентской машине устанавливается proxy серверного COM+-приложения.
| Test Forward (10 итераций) | InProcessClient | COM+ Client | NET Remoting Client | COM+ Server | NET Remoting Server |
|---|---|---|---|---|---|
| ADO.NET | 51.77 | 54.238 (ручная реализация поблочного копирования данных) | 54.390 (ручная реализация поблочного копирования данных) | 57.89 (ручная реализация поблочного копирования данных) | 56.281 (ручная реализация поблочного копирования данных) |
| ADO | 0.052 (приведено к 10 итерациям, получено по 1000) | 330.76 (1 итерация) | не тестировалось | 439.39 (1 итерация) | не тестировалось |
| ascDB | 0.17 | 0.231 | не тестировалось | 1.632 | не тестировалось |
Пусть вас не удивляет малая разница во времени выполнения теста ADO.NET между разными режимами, поскольку это время в основном определяется временем переоткрытия объекта SqlDataReader на серверной стороне. Столь большое время переоткрытия объекта DataReader связано с кэшированием им всей таблицы (объяснения этому см. выше). По сравнению с этим событием передача по сети блока из 100 записей (не забывайте, что мы реализовали вручную поблочное копирование) практически не занимает времени. Разницы между in-process, клиентскими и серверными режимами в тестах ADO.NET практически нет.
Однако имитация forwardonly-курсора через копирование объектов DataSet с порционной выдачей resultset’a по 100 строк (код см. выше) позволила хоть как-то работать с такими объемами данных по сети, хотя отставание ADO.NET от ascDB и в этом случае впечатляет. Даже в in-process режиме ADO.NET работает в тестируемом режиме неприемлемо медленно.
Никто и не сомневался, что в отключенном от БД режиме получить на клиента миллион записей будет трудно. Однако, пусть в невероятный срок, но ADO все-таки справилось с этой нелегкой задачей! А если серьезно, то, разумеется, работа в отключенном режиме (а для ADO.NET это идеологически единственный режим) с такими объемами данных невозможна. Да и в реальности вряд ли кому-то придется иметь дело с таблицей на миллион или даже 100 тыс. записей – такие условия скорее являются исключением, нежели правилом.
Приходится констатировать, что на ADO.NET невозможно организовать эффективную докачку данных, тогда как на ADO это сделать можно, а ascDB делает это автоматически. Наш совет пользователям ADO.NET: старайтесь выбирать столько данных, сколько будет обработано (ограничивая запрос средствами SQL), или выбирайте все данные resultset’a, потому как все равно все данные вашего resultset’a будут выбраны в кэш.
Выполнялся запрос на выборку всех записей из таблицы, содержащей 100000 записей, с последующим чтением записей из разных позиций (перемещение методом FetchRandom или его аналогом в позиции 10, 75, 30, 50 процентов от количества записей, а затем в конец и на начало списка). Использовались keyset-курсоры (static-курсоры в не-InProcess режимах ADO и SqlDataAdapter в ADO.NET). Каждый переход на новую строку сопровождался считыванием из нее данных, как это описано выше (в тесте «Forward»). Затем выполнялось переоткрытие курсора. Выполнялось 10 повторов.
Доступ к данным осуществлялся через SqlDataAdapter, данные из которого копировались в DataSet (с использованием метода SqlDataAdapter.Fill).
Основной код примера приведен ниже. Здесь выполняется переоткрытие объекта SqlDataAdapter с перезаполнением объекта DataSet. Хотя прокрутка массива данных в DataSet с их получением выполняется очень быстро (по сравнению с заполнением объекта DataSet), она была выполнена:
// Строка с текстом sql-запроса const string csOrders100000SelectAll = "select * from Orders100000"; // Считывает все данные из строки таблицы объекта DataSet protected void RowDataLoad(DataRow drRow) { // Заполнить переменные m_iOrderID = (int)drRow[0]; m_sCustomerID = (string)drRow[1]; m_iEmployeeID = (int)drRow[2]; m_dtOrderDate = (DateTime)drRow[3]; m_dtRequiredDate = (DateTime)drRow[4]; m_dtShippedDate= (DateTime)drRow[5]; m_iShipVia = (int)drRow[6]; m_decFreight = (decimal)drRow[7]; m_sShipName = (string)drRow[8]; m_sShipAddress = (string)drRow[9]; m_sShipCity = (string)drRow[10]; m_sShipRegion = (string)drRow[11]; m_sShipPostalCode = (string)drRow[12]; m_sShipCountry = (string)drRow[13]; } // Метод позволяет получить данные из строки объекта DataSet // для имитации прокрутки курсора. protected void CursorFetchRandom(int iIndexNew) { DataRowCollection drRows = m_dsDataSet.Tables[0].Rows; if(iIndexNew < 0 || iIndexNew >= drRows.Count) return; RowDataLoad(drRows[iIndexNew]); } // Выполнить SQL-запрос и заполнить DataSet protected void CursorReopenInternal(string sSelect, DataSet ds) { using(SqlConnection cnn = new SqlConnection (csConnectionString)) using(SqlDataAdapter sda = new SqlDataAdapter(sSelect, cnn)) sda.Fill(ds); } // Метод, выполняющий iIterationCount повторов тестов «LargeKeySet» protected void TestOrders100000(int iIterationCount) { OpenCursor(m_dsDataSet); int i; int iTimeStart; int iPosition10; int iPosition30; int iPosition50; int iPosition75; int iCount; iCount = (int)CursorRowCount(m_dsDataSet); iPosition10 = iCount / 10; iPosition30 = iPosition10 * 3; iPosition50 = iPosition10 * 5; iPosition75 = (int)(iPosition10 * 7.5); iTimeStart = Environment.TickCount; int iReopenSumTime; int iFetchSumTime; int iStartTimeTmp; iReopenSumTime = 0; iFetchSumTime = 0; for(i = 0; i < iIterationCount; ++i) { // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(iPosition10); CursorFetchRandom(iPosition75); CursorFetchRandom(iPosition30); CursorFetchRandom(iPosition50); CursorFetchRandom(iCount); CursorFetchRandom(1); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; // reopen iStartTimeTmp = Environment.TickCount; CursorReopenInternal(); iReopenSumTime = iReopenSumTime + Environment.TickCount - iStartTimeTmp; } int iFullTime = Environment.TickCount – iTimeStart; // Вывести информацию о времени выполнения операций и всего теста в целом //… } |
Объект DataSet, заполненный методом SqlDataAdapter.Fill, возвращался в клиентское приложение из промежуточного (middleware) объекта. Действие это оказалось небыстрым и очень неэкономичным в отношении оперативной памяти. Система перешла в состояние ”low virtual memory”, где и случился вылет с сообщением: «System.OutOfMemoryException: Exception of type System.OutOfMemoryException was thrown».
Клиентская часть этого теста отличается от вышеописанного теста in-process режима только реализацией метода CursorReopenInternal. Вместо открытия объекта SqlDataAdapter и заполнения объекта DataSet через него, вызывается метод middleware-объекта. Вот основной код этого теста:
// *** клиентское приложение // вызов метода middleware-объекта для заполнения объекта DataSet protected void CursorReopenInternal(string sSelect, DataSet ds) { m_dsDataSet = m_mwoIntf.Orders100000SelectAll(); } // *** middleware-объект // Метод позволяет получить отключенный resultset // для его возврата на клиентскую сторону. // Полностью кэширует данные из курсора! protected DataSet GetDisconnectedDataSet(string sSqlSelect) { #if CompileWithSqlClient using(SqlConnection cnn = new SqlConnection(csConnectionString)) using(SqlDataAdapter sda = new SqlDataAdapter(sSqlSelect, cnn)) #else using(OleDbConnection cnn = new OleDbConnection(csConnectionString)) using(OleDbDataAdapter sda = new OleDbDataAdapter(sSqlSelect, cnn)) #endif using(DataSet ds = new DataSet()) { sda.Fill(ds); return ds; } } // Метод интерфейса ITest, реализуемый middleware-объектом. // Основной код описания этого интерфейса и детали создания middleware-объекта // для работы через COM+ приведены выше в примере для теста «Forward». DataSet ITest.Orders10000SelectAll() { return GetDisconnectedDataSet(csSqlOrders10000SelectAll); } |
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+» теста «LargeKeySet». На клиентской машине устанавливается proxy серверного COM+-приложения.
Получена ошибка с сообщением о переполнении памяти («OutOfMemoryException was thrown»).
Принцип получения и передачи данных тот же, что и в «локальном режиме через NET Remoting» теста «LargeKeySet». На клиентской машине устанавливается proxy серверного COM+-приложения.
Получена ошибка с сообщением о переполнении памяти («OutOfMemoryException was thrown»).
В качестве keyset курсора использовался объект Recordset с установкой значений свойств CursorType равным ADOpenKeyset, LockType равным adLockReADOnly и CursorLocation равным adUseServer. Размер кэша устанавливался равным 100 записям (свойство CacheSize)..
Основной код теста мало отличается от аналога, реализованного для ADO.NET. По сути отличий три. Первое: реализация не на C#, а на VB6. Второе: переоткрытие курсора выполнялось вызовом метода CursorReopen, описанного в тесте «Forward» для «in-process режима». Третье: переход по записям осуществлялся с помощью вызова метода Move.
В связи с этим пример кода метода вызова теста приведен не будет. Код создания и открытия соединения приведен выше (в описании локального режима тестирования через COM+ для теста «Forward»).
Для передачи данных между процессами использовался объект Recordset, отключенный от SQL-сервера (disconnected). Для получения отключенного Recordset ему перед открытием устанавливались значения свойств CursorLocation равным adUseClient, CursorType равным ADOpenStatic, LockType равным adLockBatchOptimistic. Размер кэша устанавливался равным 100 записям (свойство CacheSize). После открытия курсора и заполнения объекта Recordset он (Recordset) отключался от SQL-сервера (значение свойства ActiveConnection устанавливалось равным Nothing) и возвращался в клиентское приложение.
Пример кода метода GetDisconnectedCursor приведен в описании теста «Forward» в «локальном режиме через COM+».
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+» теста «LargeKeySet». На клиентской машине устанавливается proxy серверного COM+-приложения.
В качестве keyset-курсора использовался объект ascVisualCursor с установкой значений свойства rsDBCursorType равным actKeyset. Размер кэша устанавливался равным 100 записям (свойство rsFetchBufferSize). Переход по записям осуществлялся с помощью вызова метода FetchRandom. В общем, принципы работы ничем не отличались от примененных в тесте «Forward». Реализация тестовых методов совпадает с аналогичными реализациями для теста ADO, за исключением того, что методы навигации по курсору в ascDB называются FetchXXX, а не MoveXXX.
Вся работа с сервером уже на этом этапе вынесена в промежуточный объект, но библиотека с этим объектом зарегистрирована локально (не через COM+).
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+» теста «LargeKeySet». Middleware-объект зарегистрирован в COM+.
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+». На клиентской машине устанавливается proxy серверного COM+-приложения.
| Test LargeKeyset (10 итераций) | InProcessClient | COM+ Client | NET Remoting Client | COM+ Server | NET Remoting Server |
| ADO.NET | 38.816 | Out of memory | Out of memory | Out of memory | Out of memory |
| ADO | 4.226 | 47.638 | не тестировалось | 226.065 | не тестировалось |
| ascDB | 7.921 | 8.012 | не тестировалось | 11.577 | не тестировалось |
Из результатов теста следует, что с работой по сети с большими объемами данных в keyset-режиме ADO.NET не справляется, тогда как ascDB показало себя неплохо. Это и не странно, т.к. ascDB – единственное из тестировавшихся средство работы с БД для многоуровневых приложений, полноценно реализующее эмуляцию keyset-курсора в удаленном режиме. В in-process режиме ADO оказалось в полтора раза быстрее ascDB. Для ascDB же не обнаружилось большой разницы, работать ли на клиенте или по сети – выполнение теста на удаленной машине оказалось медленнее клиентского теста менее чем в полтора раза.
Естественно, такие результаты ADO.NET невольно вызывают вопрос: что случилось? Как это может быть? Мы провели смелый научный эксперимент, в ходе которого выяснилось, что основная причина тормозов в ADO.NET связана с невероятно неоптимальной сериализацией данных. Мы создали простой тест, в котором сначала заполняли DataSet и измеряли скорость его работы. Естественно, что его время совпадало со временем работы теста in-process. Собственно, вот код этого теста:
public static DataSet test() { SqlDataAdapter sda = new SqlDataAdapter( "select * from Orders100000", "Integrated Security=SSPI;Persist Security Info=False;Initial Catalog=ascCursorTest" ); DataSet ds = new DataSet(); Console.WriteLine("DataSet ds = new DataSet();"); Console.WriteLine("Начинаем заполнять DataSet..."); sda.Fill(ds); Console.WriteLine("Приехали! :)"); return ds; } ... DataSet ds = test(); |
Затем мы дополнили тест ручным вызовом сериализации в бинарный формат (код приведен ниже):
BinaryFormatter bf = new BinaryFormatter(); MemoryStream ms = new MemoryStream(100000000); bf.Serialize(ms, ds); |
Каково же было наше удивление, когда в результате выполнения этого кода было занято несколько сотен мегабайт памяти, и машина погрузилась в глубокое раздумье. Тогда мы попытались скопировать данные в массив структур и сериализовать уже его. Объем занимаемой памяти несколько уменьшился, но время выполнения теста все равно оказалось совершенно неудовлетворительным. Тогда мы попытались сериализовать содержимое DataTable вручную (код приведен ниже):
protected DataSet DataSetFromByteArray(byte[] arr) { // *** Клиентское приложение // Получить описание колонок и создать таблицу DataSet ds = m_mwoIntf.Orders10000SelectTopCount(0); // Получить данные и заполнить таблицу using(MemoryStream ms = new MemoryStream(arr)) using(BinaryReader br = new BinaryReader(ms, System.Text.Encoding.GetEncoding(1251))) { object[] rowVals = new object[14]; while(br.BaseStream.Position < br.BaseStream.Length) { rowVals[0] = br.ReadInt32(); rowVals[1] = br.ReadString(); rowVals[2] = br.ReadInt32(); rowVals[3] = DateTime.FromOADate(br.ReadDouble()); rowVals[4] = DateTime.FromOADate(br.ReadDouble()); rowVals[5] = DateTime.FromOADate(br.ReadDouble()); rowVals[6] = br.ReadInt32(); rowVals[7] = br.ReadDecimal(); rowVals[8] = br.ReadString(); rowVals[9] = br.ReadString(); rowVals[10] = br.ReadString(); rowVals[11] = br.ReadString(); rowVals[12] = br.ReadString(); rowVals[13] = br.ReadString(); ds.Tables[0].Rows.Add(rowVals); } } return ds; } m_dsDataSet = DataSetFromByteArray(m_mwoIntf.Orders100000SelectAll2()); // *** Код middleware-объекта public byte[] Orders100000SelectAll2() { using(SqlConnection scn = new SqlConnection( "Integrated Security=SSPI;Persist Security Info=False;" + "Initial Catalog=ascCursorTest")) using(SqlCommand sc = new SqlCommand("select * from Orders100000", scn)) { scn.Open(); using(IDataReader dr = sc.ExecuteReader()) { MemoryStream ms = new MemoryStream(100000000); BinaryWriter br = new BinaryWriter(ms, System.Text.Encoding.GetEncoding(1251)); while(dr.Read()) { br.Write(dr.GetInt32(0)); br.Write(dr.GetString(1)); br.Write(dr.GetInt32(2)); br.Write(dr.GetDateTime(3).ToOADate()); br.Write(dr.GetDateTime(4).ToOADate()); br.Write(dr.GetDateTime(5).ToOADate()); br.Write(dr.GetInt32(6)); br.Write(dr.GetDecimal(7)); br.Write(dr.GetString(8)); br.Write(dr.GetString(9)); br.Write(dr.GetString(10)); br.Write(dr.GetString(11)); br.Write(dr.GetString(12)); br.Write(dr.GetString(13)); } return ms.ToArray(); } } } |
В результате ручной сериализации мы получали большой расход памяти, но скорость работы этого метода вплотную приблизилась к аналогичному тесту ADO, уступая последнему уже на проценты, а не на порядки.
Совершенно непонятно, почему для DataSet не сделали ручную сериализацию, и почему вообще так тормозит сериализация объектов в .NET. но с этим фактом придется мириться, по крайней мере, до выхода новой версии .NET. Сделать ручную сериализацию для объекта DataSet – не слишком сложная задача для программиста. А без этого, чем большие объемы данных копируются по сети, тем больше будет проигрыш ADO.NET перед другими средствами доступа к данным.
Выполнялся запрос на выборку всех записей из таблицы, содержащей 10 тыс. записей. После получения списка записей с ним выполнялись действия, имитирующие реальную работу (перебор, добавление, изменение, удаление записей, сохранение и переоткрытие курсора). Каждый переход на новую строку сопровождался считыванием из нее данных, как это описано выше (в тесте «Forward»). Использовались keyset-курсоры или их аналоги (SqlDataAdapter в ADO.NET). Выполнялось 10 повторов. После каждого повтора содержимое таблицы БД восстанавливалось.
| ПРЕДУПРЕЖДЕНИЕ К сожалению, при тестировании средств доступа к базам данных (ADO.Net, ADO, ascDB) в данном тесте было допущено несколько ошибок. См. поправки к статье. |
Доступ к данным осуществлялся через SqlDataAdapter, данные из которого копировались в DataSet (с использованием метода SqlDataAdapter.Fill). Выполнялись операции вставки, удаления и модификации данных в объекте DataSet с записью изменений в таблицу Orders10000.
Методы CursorFetchNext и CursorFetchPrev имитировались через CursorFetchRandom (последний описан выше, в «in-process режиме» теста «LargeKeySet» для ADO.NET).
Основной код теста «ChangeData» приведен ниже:
// Константы для заполнения полей const int ciOrderID = 0; const string csCustomerID = "1"; const int ciEmployeeID = 2; static DateTime cdtOrderDate = DateTime.Parse("01.01.2002"); static DateTime cdtRequiredDate = DateTime.Parse("02.02.2002"); static DateTime cdtShippedDate = DateTime.Parse("03.03.2002"); const int ciShipVia = 3; const decimal cdecFreight = 4; const string csShipName = "ShipName"; const string csShipAddress = "ShipAddress"; const string csShipCity = "ShipCity"; const string csShipRegion = "ShipRegion"; const string csShipPostalCode = "5"; const string csShipCountry = "ShipCountry"; // Заполняет все доступные для записи поля в строке таблицы объекта DataSet. // Объявление переменных описано выше в описании теста «Forward». protected void RowDataFill(DataRow drRow) { // Поле drRow[0] reADOnly drRow[1] = csCustomerID; drRow[2] = ciEmployeeID; drRow[3] = cdtOrderDate; drRow[4] = cdtRequiredDate; drRow[5] = cdtShippedDate; drRow[6] = ciShipVia; drRow[7] = cdecFreight; drRow[8] = csShipName; drRow[9] = csShipAddress; drRow[10] = csShipCity; drRow[11] = csShipRegion; drRow[12] = csShipPostalCode; drRow[13] = csShipCountry; } // Insert protected void CursorInsert(DataSet dsDataSet, int iRowIndex) { DataRow dr = dsDataSet.Tables[0].NewRow(); RowDataFill(dr); dsDataSet.Tables[0].Rows.Add(dr); } // Update protected void CursorUpdate(DataSet dsDataSet, int iRowIndex) { object[] ItemArray = new object[dsDataSet.Tables[0].Columns.Count]; for(int i = 0; i < dsDataSet.Tables[0].Columns.Count; ++i) { TypeCode tc = Type.GetTypeCode(dsDataSet.Tables[0].Columns[i].DataType); switch(tc) { case TypeCode.DateTime: ItemArray[i] = DateTime.Now; break; default: ItemArray[i] = i; break; } } dsDataSet.Tables[0].Rows[iRowIndex].ItemArray = ItemArray; } // Delete protected void CursorDelete(DataSet dsDataSet, int iRowIndex) { dsDataSet.Tables[0].Rows[iRowIndex].Delete(); } // Save protected void CursorSave(DataSet dsDataSet) { DataSet xDataSet; xDataSet = m_dsDataSet.GetChanges(); // Проверки на ошибки и т.п. //… m_sdaAdapter.Update(xDataSet); } // Тест на «случайную» прокрутку курсора. // Объект m_rnd класса Randomizer реализован // на C++ и находится в отдельной библиотеке. // Для достижения повторяемости результатов получения // «случайных» значений использован алгоритм, // реализованный в функции «rand» файла «rand.c» из // стандартной поставки MVC 6.0. protected void RandomFetchTest() { int iCount; int i; iCount = (int)CursorRowCount(m_dsDataSet); if(iCount <= 0) return; // Для повторяемости BaseValue должно совпадать m_rnd.BaseValue = 0; int iIndex = m_rnd.RandomInt(1, iCount); CursorFetchRandom(iIndex); for(i = 1; i < 10; ++i) CursorFetchNext(iIndex); for(i = 1; i < 20; ++i) CursorFetchPrev(iIndex); for(i = 1; i < 10; ++i) CursorFetchRandom(m_rnd.RandomInt(1, iCount)); } // Тест «ChangeData». Повторяется iIterationCount раз. protected void TestOrders10000(int iIterationCount) { // Сначала перезаполнить курсор, чтобы быть уверенным в идентичности. // Это время не учитывается. // … // Открыть курсор CursorOpen(); int i; int j; int iTimeStart; int iPosition10; int iPosition30; int iPosition50; int iPosition75; int iCount; iCount = (int)CursorRowCount(m_dsDataSet); iPosition10 = iCount / 10; iPosition30 = iPosition10 * 3; iPosition50 = iPosition10 * 5; iPosition75 = (int)(iPosition10 * 7.5); iTimeStart = Environment.TickCount; int iFetchSumTime = 0; int iReopenSumTime = 0; int iDeleteSumTime = 0; int iInsertSumTime = 0; int iUpdateSumTime = 0; int iSaveSumTime = 0; int iStartTimeTmp; for(i = 0; i < iIterationCount; ++i) { // fetch iStartTimeTmp = Environment.TickCount; RandomFetchTest(); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; CursorFetchRandom(iPosition10); // iStartTimeTmp = Environment.TickCount; for(j = 0; j < 10; ++j) { // insert iStartTimeTmp = Environment.TickCount; CursorInsert(m_dsDataSet, -1); iInsertSumTime = iInsertSumTime + Environment.TickCount - iStartTimeTmp; // update iStartTimeTmp = Environment.TickCount; CursorUpdate(m_dsDataSet, (int)CursorRowCount(m_dsDataSet) - 1); iUpdateSumTime = iUpdateSumTime + Environment.TickCount - iStartTimeTmp; } // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(iPosition75); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; // for(j = 0; j < 10; ++j) { // delete iStartTimeTmp = Environment.TickCount; CursorDelete(m_dsDataSet, iPosition75 + j); iDeleteSumTime = iDeleteSumTime + Environment.TickCount - iStartTimeTmp; // fetch iStartTimeTmp = Environment.TickCount; CursorFetchNext(iPosition75 + j); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; } // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(iPosition30); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; for(j = 0; j < 10; ++j) { // update iStartTimeTmp = Environment.TickCount; CursorUpdate(m_dsDataSet, iPosition30 + j); iUpdateSumTime = iUpdateSumTime + Environment.TickCount - iStartTimeTmp; // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(iPosition30); CursorFetchNext(iPosition30); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; } // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(iCount); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; // for(j = 0; j < 5; ++j) { // insert iStartTimeTmp = Environment.TickCount; CursorInsert(m_dsDataSet, -1); iInsertSumTime = iInsertSumTime + Environment.TickCount - iStartTimeTmp; // update iStartTimeTmp = Environment.TickCount; CursorUpdate(m_dsDataSet, (int)CursorRowCount(m_dsDataSet) - 1); iUpdateSumTime = iUpdateSumTime + Environment.TickCount - iStartTimeTmp; } // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(iPosition50); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; // for(j = 0; j < 100; ++j) { // delete iStartTimeTmp = Environment.TickCount; CursorDelete(m_dsDataSet, iPosition50 + j); iDeleteSumTime = iDeleteSumTime + Environment.TickCount - iStartTimeTmp; // fetch iStartTimeTmp = Environment.TickCount; CursorFetchNext(iPosition50 + j); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; } // fetch iStartTimeTmp = Environment.TickCount; CursorFetchRandom(1); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; // for(j = 0; j < 5; ++j) { // delete iStartTimeTmp = Environment.TickCount; CursorDelete(m_dsDataSet, 0); iDeleteSumTime = iDeleteSumTime + Environment.TickCount - iStartTimeTmp; // fetch iStartTimeTmp = Environment.TickCount; CursorFetchNext(1 + j); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; } for(j = 0; j < 100; ++j) { // insert iStartTimeTmp = Environment.TickCount; CursorInsert(m_dsDataSet, -1); iInsertSumTime = iInsertSumTime + Environment.TickCount - iStartTimeTmp; // update iStartTimeTmp = Environment.TickCount; CursorUpdate(m_dsDataSet, (int)CursorRowCount(m_dsDataSet) - 1); iUpdateSumTime = iUpdateSumTime + Environment.TickCount - iStartTimeTmp; } // fetch iStartTimeTmp = Environment.TickCount; RandomFetchTest(); iFetchSumTime = iFetchSumTime + Environment.TickCount - iStartTimeTmp; // Save iStartTimeTmp = Environment.TickCount; CursorSave(m_dsDataSet); iSaveSumTime = iSaveSumTime + Environment.TickCount - iStartTimeTmp; // Reopen iStartTimeTmp = Environment.TickCount; CursorReopenInternal(); iReopenSumTime = iReopenSumTime + Environment.TickCount - iStartTimeTmp; } // Вывод информации о времени выполнения всего теста и отдельных действий int iSum = Environment.TickCount – iTimeStart; //… GC.Collect(); // Очистить память от мусора } |
Объект DataSet после создания и заполнения возвращался в клиентское приложение. Изменения в данных, произведенные в клиентском приложении, копировались в другой объект DataSet (содержащий только изменения), который передавался в middleware-объект. Уже там изменения вносились в базу данных методом SqlDataAdapter.Update (пример кода приведен ниже):
// Метод клиентской стороны (клиентское приложение) protected void CursorSave(DataSet dsDataSet) { DataSet xDataSet; xDataSet = m_dsDataSet.GetChanges(); if(xDataSet.HasErrors) { // Обработка ошибок //... return; } if(0 == xDataSet.Tables[0].Rows.Count) return; // Изменений не было // Вызвать метод middleware-объекта m_mwoIntf.UpdateBatch(xDataSet); } // Метод middleware-объекта. // Вносит изменения в таблицы базы данных. // На вход приходит массив изменений. Получать его надо на клиенте! void ITest.UpdateBatch(DataSet dsDataSetChanges) { // Проверки входного параметра dsDataSetChanges // … // Внесение изменений в базу данных OpenConnection(); m_sdaAdapter.Update(dsDataSetChanges); } |
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM", но используется технология NET Remotimg.
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+». На клиентской машине устанавливается proxy серверного COM+-приложения.
Принцип получения и передачи данных тот же, что и в «локальном режиме через NET Remoting». Клиентское приложение запускается на локальной машине, серверная часть – на серверной.
В качестве keyset-курсора использовался объект Recordset (настройки аналогичны «in-process режиму» для теста ADO «LargeKeySet», см. выше). Алгоритм работы теста «ChangeData» полностью соответствует аналогичному тесту для ADO.NET, разница лишь в языке кодирования (тест ADO.NET писался на C#, а ADO – на VB6), поэтому код примера здесь не приводится.
Для передачи данных между процессами использовался объект Recordset, отключенный от SQL-сервера (настройки и принципы передачи данных те же, что и в вышеописанном «локальном режиме через COM+» теста «LargeKeySet»).
Для записи изменений в middleware-объект возвращался Recordset, содержащий строки с измененными данными. Cвойство MarshalOptions этого объекта устанавливалось равным adMarshalModifiedOnly, чтобы копировать (передавать между процессами или по сети) не все строки, а только измененные.
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+».
Принцип получения и передачи данных тот же, что и в «in-process режиме» теста «LargeKeySet». Код теста для краткости не приводится, так как он аналогичен коду текста для ADO за исключением того, что использовались объекты ascDB.
Принцип получения и передачи данных тот же, что и в «локальном режиме через COM+» теста «LargeKeySet».
Принцип получения и передачи данных тот же, что и в «удаленном режиме через COM+» теста «LargeKeySet».
| ChangeData (10 итераций) | InProcessClient | COM+ Client | NET Remoting Client | COM+ Server | NET Remoting Server |
|---|---|---|---|---|---|
| ADO.NET | 7.731 | 187.57 | 174.86 | 1251.2 | 1141.14 |
| ADO | 26.718 (2.574) | 5.178 | не тестировалось | 26.278 | не тестировалось |
| ascDB | 13.519 | 13.79 | не тестировалось | 36.933 | не тестировалось |
| ПРИМЕЧАНИЕ В таблице 3 с результатами для in-process теста ADO в скобках приведено значение, полученное при отключенном Recordset. |
Как видно по результатам тестирования, лучше всех с задачей в in-process режиме справляется ADO в отключенном режиме. Превосходство над «ближайшим преследователем» (ADO.NET) – в 3 раза. При этом то же ADO, но без отключения от БД, оказывается аутсайдером. Разница между подключенным к БД и отключенным режимами – 10 раз! Как оказалось, ADO безбожно тормозит на операции прокрутки курсора в in-process режиме (т.е. без отключения от БД, см. результаты в таблицах ниже).
ADO.NET в In-process режиме было примерно вдвое быстрее, чем ascDB. Столь нешустрая работа ascDB в in-process режиме связана в основном с большой длительностью записи изменений.
В целом очевидно превосходство ADO (в отключенном режиме) над ADO.NET и ascDB.
Ниже приведена детализация результатов этого теста по операциям:
| Test ChangeData | Insert | Update | Delete | Fetch | Save | Reopen | Всего |
|---|---|---|---|---|---|---|---|
| ADO.NET | 0.01 | 0.01 | 0.01 | 0.01 | 4.898 | 2.793 | 7.731 |
| ADO (connected) | 0.07 | 0.382 | 12.82 | 11.814 | 1.001 | 0.601 | 26.688 |
| ADO (disconnected) | 0.121 | 0.11 | 0.02 | 0.02 | 0.38 | 1.923 | 2.574 |
| ascDB | 0.14 | 0.232 | 0.01 | 1.082 | 11.074 | 0.931 | 13.469 |
| ПРИМЕЧАНИЕ В таблице 4 строка «ADO (connected)» содержит данные для DataSet, подключенного к БД. Строка «ADO (disconnected)» содержит данные для DataSet, отключенного от БД. |
Из таблицы 4 видно, что при отключении объекта DataSet от БД в тесте ADO заметно увеличивается время переоткрытия курсора, но зато резко снижаются затраты времени на операции удаления записей и прокрутки курсора. В результате общее время выполнения теста ADO снижается в 10 раз. Это связано с потерями времени на прокручивание подключенного курсора и удаление записей! Даже передача такого объекта по сети оказалась всего лишь вдвое медленнее, чем его прокрутка в «in-process режиме» (т.е. в подключенном к БД состоянии).
Также заметно, что в ascDB наибольшее время занимает операция записи изменений (это явная ошибка, с которой нам в ближайшее время придется побороться).
| Insert | Update | Delete | Fetch | Save | Reopen | Всего | |
|---|---|---|---|---|---|---|---|
| ADO.NET | 0.01 | 0.01 | 0.01 | 0.8 | 67.59 | 119.07 | 187.49 |
| ADO | 0.12 | 0.12 | 0 | 0.03 | 0.49 | 4.418 | 5.178 |
| ascDB | 0.21 | 0.28 | 0.03 | 1.241 | 11.021 | 0.978 | 13.76 |
За счет сериализации, а также копирования данных между процессами, на локальной машине резко (в 4.5 раза) возрастает время выполнения теста ADO.NET. Время выполнения ADO-теста возрастает вдвое (по отношению к тесту с отключением DataSet от базы в inprocess-режиме), но при этом ADO не теряет первого места. Время, затрачиваемое на тест ascDB, практически не изменяется, что свидетельствует о высокой скорости передачи данных между процессами, но, одновременно, об относительно низкой скорости записи изменений (если бы не запись, тест ascDB занимал бы 2.5 секунды вместо 14).
| TestOrders10000 | Insert | Update | Delete | Fetch | Save | Reopen | Всего |
|---|---|---|---|---|---|---|---|
| ADO.NET | 0.1 | 0.2 | 0.1 | 0.1 | 565.22 | 685.68 | 1251.4 |
| ADO | 0.06 | 0.38 | 0 | 0.04 | 2.583 | 23.914 | 26.977 |
| ascDB | 0.07 | 0.591 | 0.03 | 15.722 | 17.997 | 1.783 | 36.193 |
С переносом клиентского приложения на удаленную машину время выполнения теста ADO.NET возросло еще в 8 раз (по отношению к клиентскому режиму через COM+). Определенно, разработчики .NET занимают память не скупясь, и сериализуют данные талантливо! Время выполнения теста ADO возросло в 5 раз, но ADO и здесь оказалось лучшим.
Тест ascDB выполнился в 3 раза медленнее, чем клиентский вариант, но все-таки не догнал ADO, отстав от последнего в быстродействии примерно в 1.5 раза. Значительное возрастание времени на операции прокрутки (fetch) в удаленном тесте ascDB легко объяснимы – keyset-курсор выполняет докачку данных (то есть обращается к серверу по сети) именно на операциях прокрутки. Поскольку и ADO.NET, и ADO в удаленном тесте полностью копировали данные всего resultset’a, то основная нагрузка в этих тестах легла на операции переоткрытия и записи изменений (соответственно колонки Reopen и Save таблицы 6).
Проигрыш ascDB у ADO вновь объясняется потерями времени на сохранение изменений. Программисты, работающие на проектом ascDB, уже дали понять, что исправят эту ошибку в ближайшее время.
Выполнялся запрос на выборку и перебор 10 (или 100, соответственно) первых записей из таблицы. Размер resultset’а ограничивался в запросе (запрос вида «Select Top N From TableName»). Каждый переход на новую строку сопровождался считыванием из нее данных, как это описано выше (в тесте «Forward»). Затем выполнялось переоткрытие курсора. Использовались forward-only курсоры или их аналоги. Размер кэширующего буфера объектов ascCachedCursor (ascDB) и Recordset (ADO) устанавливался равным считываемому количеству строк (10 в тесте Top10 и 100 в тесте Top100). Выполнялось 100 повторов (в случае, когда время выполнения теста оказывалось слишком маленьким, тест повторялся с увеличением количества итераций, а результат получался делением).
Данный тест наилучшим образом подходит для disconnected-идеологии, а, следовательно, ADO.NET должен был показать себя с наилучшей стороны (т.к. ADO.NET спроектирован исключительно для disconnected-работы). Наши надежды не оправдались, но об этом чуть позже (в выводах из тестов).
Принципы получения и передачи данных соответствуют аналогичным режимам теста «ChangeData».
Примеры кода для теста «Top 10» приведен ниже (тест «Top 100» отличается только SQL-запросом):
// Перезаполнить DataSet в цикле iIterationCount раз. // Метод CursorFetchNext имитируется через CursorFetchRandom (описан выше). for(int i = 0; i < iIterationCount; ++i) { using(SqlDataAdapter sda = new SqlDataAdapter( "select top 10 * from Orders10000", m_cnnConnection)) { sda.Fill(dc); for(int j = 0; j < iRowCount; ++j) CursorFetchNext(ds, j); } } |
// Основной код из метода клиентской стороны (тестовое приложение). // Позволяет перезаполнить DataSet в цикле iIterationCount раз. iTimeStart = Environment.TickCount; for(int i = 0; i < iIterationCount; ++i) { DataSet ds = m_mwoIntf.Orders10000SelectTopCount(iRowCount); using(ds) { // На выходе из using объект ds будет освобожден // fetch iFetchStartTimeTmp = Environment.TickCount; for(int j = 0; j < iRowCount; ++j) CursorFetchNext(ds, j); iFetchSumTime = iFetchSumTime + Environment.TickCount - iFetchStartTimeTmp; } } int iFullTime = Environment.TickCount – iTimeStart; // Вывести отчет //... // Метод middleware-объекта public DataSet Orders10000SelectTopCount(int iTopCount) { string sSqlSelect = "select top " + iTopCount + " * from Orders10000"; DataSet ds = new DataSet(); using(SqlConnection cnn = new SqlConnection(csInitString)) using(SqlDataAdapter sda = new SqlDataAdapter(sSqlSelect, cnn)) sda.Fill(ds); return ds; } |
Принципы получения и передачи данных соответствуют аналогичным режимам теста «ChangeData».
Код этих тестов почти полностью аналогичен тесту ascDB (см. ниже), поэтому он здесь не приводится.
Принципы получения и передачи данных соответствуют аналогичным режимам теста «ChangeData».
Основной код тестов Top10 и Top100 находится в методе TestLoadCountInternal (приведен ниже):
Private Sub TestLoadCountInternal(ByVal iIterationCount As Long, ByVal iRowCount As Long, ByVal bServer As Boolean ) Dim sMode As String Dim srv As New ascServer, sn As ascSession, acc As ascCachedCursor If !bServer Then Set sn = srv("ascCursorTest").GetDefaultSession Dim iTimeStart As Long, i As Long, j As Long Dim iReopenSumTime As Long, iFetchSumTime As Long, iStartTimeTmp As Long iTimeStart = GetTickCount For i = 1 To iIterationCount ' reopen iStartTimeTmp = GetTickCount Set acc = New ascCachedCursor acc.rsFetchBufferSize = iRowCount If bServer Then m_mwo.Orders10000SelectTopCount acc, iRowCount Else sn.Execute acc, "select top " & iRowCount & " * from Orders10000" End If iReopenSumTime = iReopenSumTime + GetTickCount - iStartTimeTmp ' fetch iStartTimeTmp = GetTickCount acc.FetchFirst RowDataLoad acc For j = 1 To iRowCount acc.FetchNext RowDataLoad acc Next iFetchSumTime = iFetchSumTime + GetTickCount - iStartTimeTmp Next ' Далее выводится информация о времени выполнения теста ....' ... End Sub |
| top10 (100 итераций) | InProcessClient | COM+ Client | NET Remoting Client | COM+ Server | NET Remoting Server |
|---|---|---|---|---|---|
| ADO.NET | 0.11 | 1.732 | 1.382 | 14.891 | 2.984 |
| ADO | 0.24 (0.18) | 0.601 | не тестировалось | 0.86 | не тестировалось |
| ascDB | 0.231 | 0.6 | не тестировалось | 1.84 | не тестировалось |
| top100 (100 итераций) | InProcessClient | COM+ Client | NET Remoting Client | COM+ Server | NET Remoting Server |
|---|---|---|---|---|---|
| ADO.NET | 0.351 | 7.722 | 7.882 | 26.018 | 18.807 |
| ADO | 0.791 (0.601) | 1.192 | не тестировалось | 2.914 | не тестировалось |
| ascDB | 0.661 | 1.222 | не тестировалось | 8.172 | не тестировалось |
| ПРИМЕЧАНИЕ В результатах in-process тестов ADO (таблицы 7 и 8 ) в скобках приведены значения, полученные при отключенном Recordset. |
И сразу бальзам на сердца поклонников ADO.NET – ибо в in-process режиме на маленьких resultset’ах ADO.NET вдвое выигрывает по скорости и у ascDB и у ADO! Собственно, дело здесь даже не в размере resultset’а, а в inprocess-режиме и считывании всего содержимого выборки. Как уже говорилось ранее, это действительно оптимальный режим для ADO.NET. Стоит начаться копированию данных между процессами или по сети, то есть маршалингу и связанной с ним сериализации, и ADO.NET начинает проигрывать своим unmanaged-конкурентам.
Описываемый тест обнаружил разницу в скорости работы ADO.NET через COM+ и NetRemoting (последний был быстрее в 5 раз в тесте «Top 10» и 1.5 раза в тесте «Top 100»). Однако чем больше объем данных, тем менее заметным становится это различие.
Сравнение времени работы одинаковых тестов с прокруткой объекта DataSet на клиенте и без оной показало, что объект действительно полностью отключен от сервера и передается «по значению», а не по ссылке. Причем это одинаково справедливо как для NetRemoting, так и для COM+.
Что же касается ADO и ascDB, то они «шагают в ногу» в клиентских режимах (ascDB даже в 1.5 раза быстрее ADO в локальном режиме через COM+), однако в удаленном режиме ADO – вновь самый быстрый: 3 секунды против 8-ми секунд ascDB.
Итак, неутешительный вывод: ADO.NET оказывается не в выигрыше даже в том режиме, которому следовало бы быть для него оптимальным. Единственное, где можно смело рекомендовать использование ADO.NET (без переписывания сериализации) – это inprocess-режим в случае, когда надо считывать все данные запроса, т.е. в основном ASP.NET. Для эффективного использования ADO.NET в многоуровневых приложениях необходимо переписывать сериализацию объекта для объектов DataTable.
Мы не тестировали сериализацию в XML, поэтому не можем говорить об эффективности в этом случае.
В целом очевидно превосходство ADO в быстродействии при удаленной работе с малыми объемами данных. Получение в цикле десяти и ста записей из таблицы Orders10000 при использовании ADO в удаленном режиме заняло примерно вчетверо меньше времени, чем аналогичная операция в тестах с использованием ascDB (и в 8 раз меньше, чем ADO.NET).
ADO проиграло ascDB на больших объемах данных (более 10 тыс. записей).
ADO проиграло ADO.NET на очень малых объемах (10 записей) и в тесте «ChangeData» в «in-process режиме» без отключения от базы данных. Причиной медленной работы ADO в тесте ChangeData (без отключения от БД) являются аномально большие потери времени на прокручивание курсора и удаление записей. Эти операции в упомянутых условиях тестирования (10 повторов) заняли примерно по 12 секунд каждая, и это притом, что на запись и переоткрытие курсора было израсходовано всего лишь по 1.5 секунды! Однако при отключении от БД ADO оказалось первым в этом тесте. Отсюда следует вывод, что для ускорения работы ADO (если, конечно, нужно считать все данные resultset’а) очень желательно отключаться от БД.
Прокручивание подключенного к базе данных keyset-курсора в ADO работает настолько медленно, что тест «ChangeData» в in-process режиме (без использования COM+) выполнялся в 5 раз медленнее, чем при работе через COM+.
ADO показало наилучшую производительность там, где возможна disconnected-работа. Однако стоит отметить, что в ADO отсутствуют такие возможности ADO.NET, как использование отключенного DataSet в качестве эмуляции базы данных в памяти (с возможностью проводить запросы). Также ADO уступает ascDb при работе в keyset-режиме и с точки зрения простоты разработки приложений (например в ascDb 90% действий можно делать визуально, тогда как в ADO те же действия приводят к большому объему кодирования).
Итак, в целом ADO можно признать победителем нашего тестирования, хотя и не стопроцентным.
ADO.NET выигрывает в «in-process тесте» при очень малом объеме данных (10 записей). Здесь превосходство в скорости над ADO и ascDB примерно в два раза.
С увеличением количества записей (более 10 тыс. или при отключении от БД), ADO.NET начинает заметно тормозить, что, как выяснилось, объясняется плохой сериализацией и очень высокими требованиями к памяти. Попытки получить 100 тыс. записей во всех режимах, кроме «in-process», привели к вылету клиентского тестового приложения с сообщением о переполнении памяти (“OutOfMemoryException was thrown”). Однако сериализация, сделанная нами «вручную», легко справилась с поставленной задачей и показала время, ненамного худшее, чем ADO. Все это говорит о том, что проблемы ADO.NET можно излечить или путем изменения в столь хорошо разрекламированной, но столь же плохо реализованной системе сериализации .NET, или банальной ручной реализацией сериализации для объектов DataSet и DataTable. Судите сами, Recordset ADO без запинки позволял передавать recordset’ы со 100 тыс. строк, причем приложение отъедало незначительный объем памяти. ADO.NET не смог передать 100 тыс. записей ни на машине с 256 МБ оперативной памяти, ни на машине с 512 МБ RAM.
Второй проблемой ADO.NET является то, что программисты Microsoft в погоне за скоростью считывания данных из БД пришли к тому, что вся выборка кэшируется на стороне, выполняющей SQL-запрос, еще в момент создания DataReader’a. Нет никакой возможности повлиять ни на количество кэшируемых записей, ни на позицию, с которой необходимо считывать данные. ADO и ascDb таких проблем не имеют.
Существенные различия в скорости работы через COM+ и NetRemoting проявились только в тесте «Top 10» – здесь NetRemoting оказался существенно (в 3 раза) быстрее (!), чем COM+.
Отдельный тест показал, что с точки зрения скорости не имеет никакого значения, пересоздавать ли каждый раз объекты SqlConnection и SqlDataAdapter, или использовать единожды созданные. Время выполнения 1000 повторов запроса «select top 100 * from Orders1000000» оказалось близким для обоих случаев (в среднем 4.15 секунды). Таким образом, переоткрытие соединения не сказывается на времени выполнения теста.
Оказалось, что можно немного ускорить процесс перезаполнения, если не пересоздавать DataSet, а всего лишь удалять строки из его таблицы. В этом случае среднее время выполнения теста снижается до 4 секунд (т.е. примерно на 5%). Однако, если не удалять данные из таблицы, скорость падает на 20 %, т.к. в этом случае ADO.NET выполняет refresh.
Поскольку занятие памяти в .NET связано с Garbage Collection, было сделано резонное предположение, что сборка мусора между тестами может ускорить последовательное выполнение тестов, поэтому мы добавили вызов GC.Collect в конце теста (именно теста, а не итерации). Однако это не дало никаких результатов.
Пример кода сравниваемых вариантов (с пересозданием соединения и без пересоздания) приведен ниже:
#if CompileWithSqlClient const string csInitString = "Integrated Security=SSPI;" + "Persist Security Info=False;Initial Catalog=ascCursorTest"; #else const string csInitString = "Provider=SQLOLEDB;Integrated Security=SSPI;" + "Persist Security Info=False;Initial Catalog=ascCursorTest"; #endif const string csSelect = "select top 100 * from Orders100000"; private void pbRecreate_Click(object sender, System.EventArgs e) { int iCount = Convert.ToInt32(dfCount.Text, 10); int iTickCount = Environment.TickCount; for(int i = 0; i < iCount; ++i) { #if CompileWithSqlClient using(SqlConnection cnn = new SqlConnection(csInitString)) using(SqlDataAdapter sda = new SqlDataAdapter(csSelect, cnn)) #else using(OleDbConnection cnn = new OleDbConnection(csInitString)) using(OleDbDataAdapter sda = new OleDbDataAdapter(csSelect, cnn)) #endif using(DataSet ds = new DataSet()) sda.Fill(ds); } LogAppend((Environment.TickCount - iTickCount).ToString() + " ms"); GC.Collect(); } private void pbNoRecreate_Click(object sender, System.EventArgs e) { int iTickCount = Environment.TickCount; #if CompileWithSqlClient using(SqlConnection cnn = new SqlConnection(csInitString)) using(SqlDataAdapter sda = new SqlDataAdapter(csSelect, cnn)) #else using(OleDbConnection cnn = new OleDbConnection(csInitString)) using(OleDbDataAdapter sda = new OleDbDataAdapter(csSelect, cnn)) #endif //using(DataSet ds = new DataSet()) { int iCount = Convert.ToInt32(dfCount.Text, 10); DataSet ds = new DataSet(); for(int i = 0; i < iCount; ++i) { //using(DataSet ds = new DataSet()) sda.Fill(ds); //sda.Fill(ds); ds.Tables[0].Clear(); //ds.Tables.Clear(); } } LogAppend((Environment.TickCount - iTickCount).ToString() + " ms"); GC.Collect(); } |
Сравнение работы ADO.NET через SqlClient и OleDb показало, что в целом компоненты SqlClient работают несколько быстрее. Ниже приведена таблица с данными:
| In-process | Forward (10 итер) | LargeKeyset (10 итер) | ChangeData (10 итер) | Top10 (1000 итер) | Top100 (1000 итер) |
|---|---|---|---|---|---|
| ADO.NET (SqlClient) | 54.238 | 38.816 | 7.731 | 1.132 | 3.746 |
| ADO.NET (OleDb) | 45.625 | 43.142 | 8.012 | 2.293 | 5.468 |
По результатам сравнения (таблица 9) можно сделать вывод, что при чтении малых объемов данных (10-100 записей) с использованием объектов типа XXXDataReader лучше работать через SqlDataReader, т.к. он быстрее OleDbDataReader примерно вдвое. Когда же дело доходит до больших объемов данных, или же данные редактируются, становится все равно, что использовать – SqlClient или OleDb. Для сравнения, время записи изменений в тесте «ChangeData» для обоих случаев составило 4.8-4.9 секунды. Переоткрытие курсора с перезаполнением объекта DataSet заняло примерно 2.8 и 3.2 секунды для SqlClient и OleDb соответственно. Похоже, что при SqlClient выигрывает у OleDb именно на перечитывании данных. Изменения же вносятся примерно с одинаковой скоростью.
Но по сравнению со временем, затрачиваемым на сериализацию того же DataSet’а, разница между OleDb и SqlClient теряет значимость.
Код всех примеров для OleDb остается тем же, что и для SqlClient, только объекты SqlConnection, SqlDataAdapter, SqlDataReader, SqlCommand и SqlBuilder заменяются на соответствующие им объекты OleDbConnection, OleDbDataAdapter, OleDbDataReader, OleDbCommand и OleDbBuilder. В строке инициализации csConnectionString надо добавить указание на провайдер: «Provider=SQLOLEDB;» (остальной текст строки не меняется).
Выигрыш OleDb у SqlClient в тесте «Forward» объясняется вероятнее всего тем, что переоткрытие объекта OleDbReader (кэширование данных) происходит все-таки быстрее, чем объекта SqlDataReader, примерно на 10-20 процентов. Для определения разницы в выполнении операции Read этих объектов был создан отдельный тест. В нем создавался один объект Reader и выполнялось N-операций Read (т.е. аналог FetchNext) с получением значений из всех колонок в переменные класса (чтобы заведомо избежать оптимизации компилятором). Число считываемых строк показано в колонках таблицы 10, в ячейках таблицы – время выполнения теста:
| Прокручивание Reader'a, кол-во считанных записей | Первое создание | 0 | 100 | 1000 | 10 тыс. | 100 тыс. | 500 тыс. | 800 тыс. |
|---|---|---|---|---|---|---|---|---|
| ADO.NET (SqlClient), мс | 11.156 | 5.598 | 5.548 | 5.568 | 5.719 | 6.760 | 11.317 | 14.731 |
| ADO.NET (OleDb), мс | 6.800 | 4.546 | 4.536 | 4.547 | 4.687 | 6.109 | 12.428 | 17.174 |
Видно, что по большому счету нет разницы, каким из объектов пользоваться. На малом объеме данных чуть предпочтительнее OleDbReader, который создается быстрее. На большом объеме данных начинает выигрывать SqlDataReader, несколько быстрее читающий данные.
На малых объемах данных (10 и 100 записей) ascDB локальных режимах по скорости не уступает ADO, проигрывая только в удаленном режиме (примерно втрое). Обратная картина наблюдается при работе с большими объемами данных (более 10000 записей) – здесь ascDB начинает выигрывать, особенно на операциях чтения данных. Основные потери времени при работе через ascDB связаны с записью изменений в базу данных.
В то время, как для для ADO переоткрытие курсора на 100 тыс. записей выглядит почти смертельным в «удаленном режиме через СОМ+» (однократное выполнение этой операции занимает около 7 минут), для ascDB это действие не представляет никаких проблем – примерно 0.2 секунды за одну итерацию. Однако не следует забывать, что static-курсор в случае с ADO не имел связи с базой данных, то есть вся информация копировалась в отключенный от SQL-сервера объект Resultset. А в ascDB курсор от базы данных не отключается, и на клиентскую сторону данные копируются поблочно, и только по мере надобности (например, при прокручивании курсора). Собственно, это и есть особенность ascDB, спроектированного специально для работы в подобных режимах, т.е. когда нет необходимости контролировать количество данных в курсоре, а данные подгружаются автоматически по мере надобности.
ascDB отличалось значительно большим уровнем автоматизации. Так, большинство тестов ascDB были сделаны в визуальном режиме.
Понятно, что именно ADO.NET, несмотря на все тормоза, будет продвигаться в светлое будущее (ведь не зря же "специалисты из Microsoft жгли свое ночное масло"?!). Безусловно, ADO.NET имеет достаточное количество преимуществ над ADO (если не рассматривать скорость), которые, возможно, компенсируют неудобства от неумеренных аппетитов ADO.NET (и, вообще, всей «.NET») в отношении оперативной памяти.
Основным же неудобством при использовании как ADO, так и ADO.NET оказалась их неспособность самостоятельно (то есть без внешнего программирования) работать с большими объемами данных в отключенном от БД состоянии, а так же относительно большой объем кодирования, необходимый для их использования.
| <<Показать меню | |
