
Verenich Ivan
Theme of master's degree dissertation: Analysis of methods of construction of the systems of speech recognition using of hybrid of the hidden markovskoy model and network
Leader of work: Ph.D. Oleg Fedyaev
RUS
Last years with multiplying the productivity of calculable machines an actual task is become by development of new, more simple, clear and friendly interfaces of the programs with users. In particular is a synthesis and human speech recognition. Such interface will help a man, to not having skills of work with a computer, quick than him to master, and also will save time from simplification of serve of commands. Also technology of speech recognition will be irreplaceable and for men-invalids with violations of the oporno-dvigatel'noy system. So a man can execute some work, remaining in place.
The process of recognition of voice passes in a few stages. On each of the stages for the vocal signal processing a number of different methods is used. The process of recognition of voice can be broken up on three stages:
- receipt of vocal signal and preliminary treatment of speech;
- recognition of phonemes and words;
- understanding of speech.
Recognition of phonemes and words. For recognition of phonemes, groups of phonemes and words such methods, as hidden markovskaya model or NMM (hidden Markov modelling), artificial networks of neurons or their combinations, are used.
Understanding of speech. To Ģunderstandģ speech it most difficult. On this stage of sequence of words (suggestions) must be regenerate in the pictures of tom, that wanted to say talking. It is well known that understanding of speech leans against the enormous volume of linguistic and cultural knowledges. Greater part of the systems of recognition of voice takes into account knowledges about a human language and concrete circumstances here. A task, related to recognition of voice, is recognition talking, I.e. Ģwho talksģ the process of automatic determination on the basis of incoming in a vocal signal individual information. Thus the question can is about authentication or about verifikatsii of talking. Authentication is finding in the known great number of phrases of controls of copy, proper the manner of this announcer to talk. Verifikation of announcer is determination of identity of talking: tot is it a man? Technology of recognition of announcer allows to use voice for providing of access control; for example, telephone access to bank services, to the databases, to the systems of electronic commerce or vocal mail, and also access to the secret equipment. Both technologies require, that an user was Ģadded to the systemģ, I.e. he must leave the standard of speech, on which the system can build a template. Attempts to develop hardware representation of the systems of recognition of voice were undertaken. Some products provide both golosonezavisimoe and golosozavisimoe speech recognition on one chip. A chip is supported by golosozavisimoe recognition on the base of dictionary, kept in permanent data storages of chip (ROM, read only memory). The dictionaries of the golosozavisimykh systems are kept out of chip and can be loaded during work of the system.
In work, the followings decide 3 tasks: Primary sound signal processing, application to the got signal of vehicle of the hidden markovskikh models, application of neyroseti for a receipt out signal

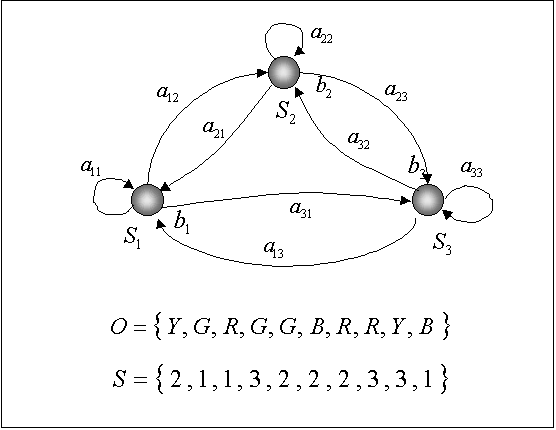
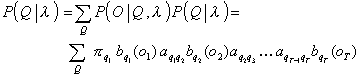


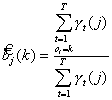
Three basic barriers cost speech recognition on the way of development of the systems:
- large volumes of dictionaries;
- templates of continuous speech;
- different accents and pronunciations.
Not decided finally and problem of separation of vocal signal ot a noise background. Presently the users of the systems of recognition of voice are forced either to work in the conditions of minimum noise background or carry send with a microphone at a mouth. In addition, users have to Ģinformģ a computer that they speak to him. For this purpose it is usually necessary to push the button or do something like that. Certainly, it is the best not variant of user interface. Working out these problems began, and much-promising results are already got. One of long-awaited developments in area of recognition of voice are the cheloveko-mashinnye interactive systems; engaged in such systems in many university laboratories of researches. The systems are Ģableģ to work with a continuous vocal stream and with unknown announcers, to understand the values of fragments of speech (in narrow areas) and undertake the actions of returns. These systems work in real time and able to execute five functions by phone:
- recognition of speech is transformation of speech to the text, consisting of separate words;
- understanding is a grammatical analysis of suggestions and recognition of semantic value;
- renewal of information is a receipt of information from operative sources on the basis of the got semantic value;
- a generation of linguistic information is a construction of suggestions, presenting findings, in language chosen an user;
- a synthesis of speech is transformation of suggestions to the speech synthesized a computer.
References:
-
L. Rabiner, B.-H. Juang. Fundamentals of Speech Recognition. Prentice Hall, 1995, 507 p.
- X. D. Huang, Y. Ariki, M. A.
Jack. Hidden Markov Models for Speech Recognition. Edinburgh University
Press, 1990, 275 p.
- C. D. Manning, H. Schutze.
Foundations of Statistical Natural Language Processing. MIT Press, 1999,
680 p.