Веренич И.В. Перевод части тезисов Dr. Casimir Kulikowski, Dr. James Flanagan Robust speech recognition using neural networks and hidden markov models.
Автоматическое распознавание речи, используя скрытые Марковские модели
Так как скорость компьютеров становится быстрее, и размер разговорных массивов становится большим, больше вычислительно интенсивные статистические алгоритмы распознаваний образов, которые требуют большое количество данных для обучения, становятся популярными для автоматического распознавания речи. Скрытая Марковская модель (HMM) [81] - стохастический метод, в котором некоторая временная информация может быть объединена. В этой главе, основные принципы алгоритмов распознаваний речи, которые используют СММ, описаны. Рисунок 2.1 показывает блок-схему типичной системы распознавания речи. Для начала, векторы свойств извлекаются из речевой звуковой волны.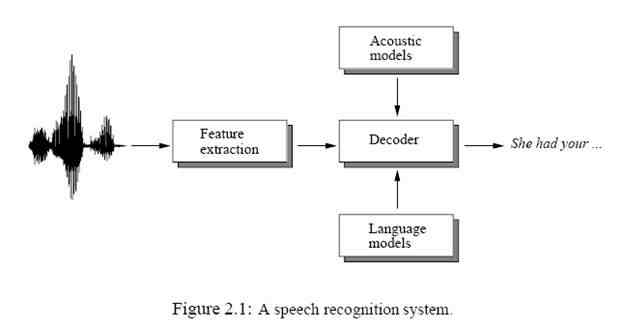
2.1 Выделение Признаков
Так как воздух выходит из легких, напряжение голосовых связок заставляет вибрировать воздушный поток. Эти квази-периодические импульсы затем фильтруются, проходя через голосовой тракт и носовой трактат, создавая озвученные звуки [20]. Различные позиции артикуляционных органов, как например челюсть, язык, губы, и мягкое небо, производят различные звуки. Когда голосовые связки расслаблены, воздушный поток проходит через сокращение в голосовом тракте, или создает давление сзади пункта прекращения и давление внезапно ослабевает, порождая глухие звуки [20]. Позиции сокращения или прекращения создают различные звуки. Речь это просто последовательность озвученных и не озвученных звуков, которые изменяют медленно (5..100 ms) поскольку конфигурация органов артикуляции изменяется медленно. Рисунок 2 показывает пример звуковой формы волны предложения, “У нее есть ваш темный костюм”, который произносит мужчина диктор. Для автоматического распознавания речи компьютерами, характеристические векторы извлекаются из звуковой формы волны. Характеристический вектор обычно считается от окна разговорных сигналов (20..30 ms) в каждом коротком интервале времени (около 10 ms). Произнесение представлено как последовательность этих характеристических векторов особенностей. Cepstrum [14][76] - широко используемая особенность вектор для распознавания речи. Cepstrum определен, как обратное преобразование логарифмического спектра короткого времени. Низшие порядковые cepstral коэффициенты представляют голосовой ответ импульса тракта. В усилии взять слуховые характеристики во внимание, взвешенные средние величины спектральных значений на логарифмическом частотном масштабе используются вместо спектра величины, производя mel-частотные cepstral коэффициенты (MFCC) [17]. Производные MFCC обычно присоединены для захватывания динамики речи. Посмотрите секцию 5.2.1 для детального рассмотрения процедуры выделения признаков. Рисунок 2.2 (b) и (c) - спектрограмма и MFCC, извлеченный от примера произнесения предложения выше. 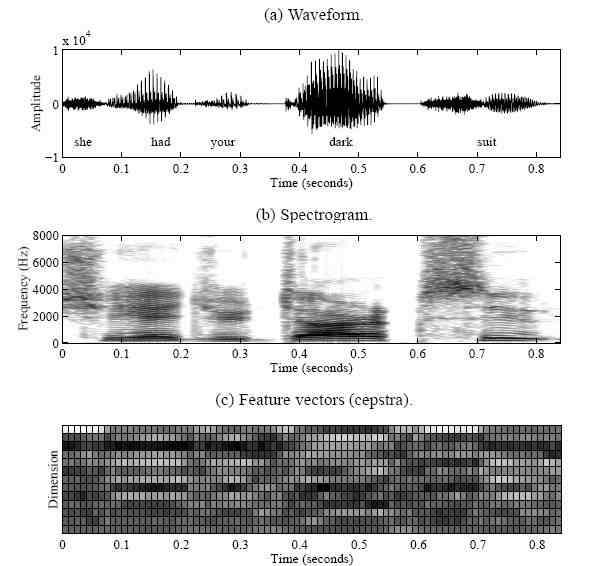
Рисунок 2.2: пример звуковой формы волны, спектрограммы, и характеристических векторов.
Одна популярная техника для устойчивого распознавания речи, которая применяется к cepstral коэффициентая - нормализация cepstral средины (CMN) [2][25]. С тех пор, как искажения такие, как например отражение и различные микрофоны становятся аддитивными ответвлениями после логарифмирования, вычитание шумового компонента из искаженной речи будет обеспечивать чистый речевой компонент. Однако, оценивая шум искаженной речи это нелегкая задача. CMN приближает шумовой компонент со средним cepstra, предполагая, что средняя величина линейной речи спектра равен 1, который очевидно не верен. Средний вектор каждого произнесения вычисляется и вычитается от речевых векторов. Велись наблюдения, что CMN представляет устойчивые характеристики для шума (посмотрите Секцию 5.3.3). Несмотря на то, что CMN прост и быстр, его эффективность ограничена шумом, потому что это перемещает спектральное наклонное положение, вызванное шумом. Также, оценивание среднего вектора не надежно, когда произнесение слишком коротко.2.2 Скрытые Марковские Модели
Распознавание речи может рассматриваться, как проблема распознавания образов. Если распределение разговорных данных известно, Байесовский классификатор, 
2.2.1 Акустическое моделирование
Одна из отличительных характеристик речи является ее динамичность. Даже в пределах маленького сегмента, как например фонема, звуки изменяются постепенно. Начало фонемы зависит от предыдущих фонем, средняя часть фонемы есть в общем стабильна, и на конец воздействуют следующие фонемы. Временная информация о характеристических векторах играет важную роль в процессе распознавания. Для того, чтобы захватить динамичные характеристики речи в рамках классификатора Байеса, нужно наложить определенные временные ограничения. обычно используется ориентированная слева-направо СММ, состоящая из 3 состояний, чтобы представить фонему. Рисунок 2.3 показывает пример такой СММ, где Aij представляет вероятность изменения состояний от состояния i к состоянию j, и bi(х) - вероятность наблюдения характеристического вектора Х, полученного в состоянии i. Каждое состояние в СММ 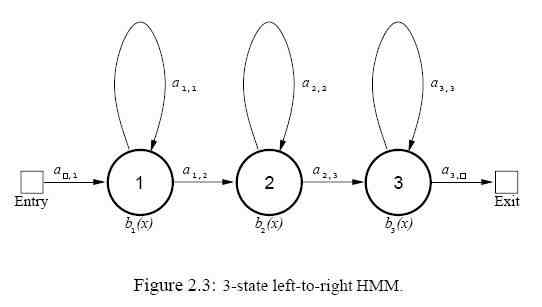
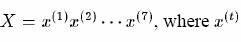

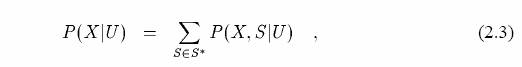
2.2.2 Моделирование под-слова
В большом словаре распознавания (LVCSR) речи, трудно надежно оценить параметры всех слов СММ в словаре, потому что большинство из слов не были проработтаны достаточно часто в учебных данных. К тому же, некоторые из слов словарей могут быть совсем не рассмотрены в учебных данных, которые ухудшают точность распознавания [52]. С другой стороны, число единиц под-слов, как например фонемы обычно намного меньше, чем число слов. Большинство языков имеют около 50 фонем. Есть больше данных на модель фонемы, чем на модель слова, и все фонемы происходят справедливо часто в разумном размере в учебных данныех[55]. Монофонемные СMM моделирует одну фонему. Это – контекстно-независимая единица в смысле, что это не отличает его от соседнего фонетического контекста. В спокойно произнесенной речи, однако, на фонему сильно воздействуют его граничащие фонемы, производя различные звуки в зависимости от фонетического контекста. Это названо коартикуляционным эффектом. Он есть благодаря факту, что артикуляционные органы не могут двигаться мгновенно от одной позиции к другой. Для того, чтобы управлять коартикуляционным эффектом более эффективно, могут использоваться контекстно-зависимые единицы [4][55][92], как например бифоны или трифоны. Бифонемная СММ моделирует фонему со своим левым или правым контекстом. Трифонемная СММ представляет фонему со своим левым и правым контекстом. Например, предложение “У нее есть ваш темный костюм” может быть представлено, как