|
Введение
Биометрические устройства аутентификации существуют уже около двадцати лет. За это время они из шпионских фильмов переместились на рабочие столы и существенно подешевели. На рынке имеется множество систем биоидентификации стоимостью от нескольких десятков до нескольких миллионов долларов. С их помощью можно защитить и отдельно стоящий ПК, и большую корпоративную сеть.
Но в них нуждаются не только корпорации. Для таких сфер жизни общества, как пограничный контроль, обслуживание и регистрация пассажиров, электронные идентификационные документы и карты, предупреждение и раскрытие преступлений, вопросы безопасности приоритетны, и в их решении существенную помощь могут оказать автоматизированные системы, основанные на биометрических методах.
К повсеместному внедрению этих систем готовится и Microsoft, объявившая о планах встраивания в Windows механизмов защиты на основе биометрических технологий: персональный компьютер будет узнавать своего хозяина по отпечаткам пальцев, голосу, радужной оболочке глаза.
В ходе выполнения магистерской работы, я планирую создать специализированную компьютерную систему аутентификации пользователей локальных вычислительных сетей по тембру голоса.
В основной части автореферата я рассматриваю уже существующие наработки в данной области , а также методы необходимые для достижения поставленной цели.
 Актуальность Актуальность 
Анализ тенденций развития речевых технологий дает основания полагать, что системы распознавания речи и идентификации довольно быстро могут пройти стадию автоматизированных программно-аппаратных комплексов и перейти на уровень микроустройств — чипов, встраиваемых в различные речевые терминалы: телефоны, персональные компьютеры, банкоматы, системы документирования и системы безопасности. Вполне возможно, что средства речевого управления, системы диктовки, средства идентификации по голосу, синтезаторы речи станут такими же обычными атрибутами деловой жизни, как факс и компьютер.
Целью данной работы является исследование, посвященное проблеме обеспечения безопасности внутрисетевых информационных ресурсов путем ограничения доступа к ним по биометрической характеристике: тембру голоса.
Обзор на национальном уровне
Теоретическим аналогом разрабатываемой СКС в нашем территориальном районе является система разрабатываемая студентами Донецкого
государственного института искусственного интеллекта. Задача отдела в широком плане – обучение компьютера работе с устной русской и украинской речью. Созданы системы, распознающие отдельно произносимые слова наперед заданного словаря
как целое. Такие системы требуют предварительного обучения - создания для каждого слова голосового эталона. На их основе разработан ряд прикладных программ, в их числе голосовое управление мобильным роботом, программа голосового набора
математических формул. В настоящее время разрабатываются системы пофонемного распознавания, требующие от диктора обучения лишь небольшого числа фонем путем предварительного произнесения нескольких десятков специально подобранных слов.
В основном решена проблема сегментации (выделение в речевом сигнале участков, отвечающих отдельным фонемам).
Методы распознавания голоса
Процесс распознавания голоса можно разбить на следующие этапы:
1. Получение голосового сигнала, предварительная обработка речи. Получение голосового сигнала или дискретизация голоса определяется как процесс получения и преобразования акустического сигнала. Голос представляется как колебания акустического давления в микрофоне.
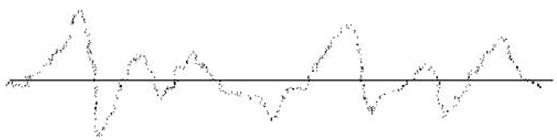
Рисунок 1. Представление сигнала
Есть два типа звуков: звонкие и глухие. Звонкие порождаются вибрацией голосовых связок при прохождении воздуха. Этот акустический сигнал модулируется напряжением голосовых связок. Вибрации резонируют в речевом канале (это нос, горло и полость рта). Поток воздуха, создающий звук, называется "волной, образованной в голосовой щели". Этот сигнал квазипериодический, а его период называется периодом основного тона
2. Распознавание фонем (слов) Для распознавания фонем, групп фонем и слов используются такие методы, как скрытая марковская модель, нейронные сети или их комбинации. Наиболее часто и успешно при распознавании фонем и слов используется скрытая марковская модель, она определяется как множество состояний и переходов из одного состояния в другое. Если происходит переход, то с определенной вероятностью будут наблюдаться некие выходные данные. Кроме того, с каждым переходом связана вероятность, представляющая собой вероятность перехода из некоторого состояния в следующее состояние. Существует множество начальных и множество конечных состояний. Любая последовательность наблюдений является результатом перехода из одного из начальных состояний в одно из конечных. Эта модель обеспечивает довольно естественное представление речи.
3. Понимание речи. "Понять" речь - это самое трудное. На этом этапе последовательности слов (предложения) должны быть преобразованы в представления о том, что хотел сказать говоривший. Задача, связанная с распознаванием голоса - распознавание говорящего, т. е. процесс автоматического определения "кто говорит" на основе входящей в речевой сигнал индивидуальной информации. При этом речь может идти об идентификации или о верификации говорящего. Идентификация - это нахождение в известном множестве контрольных фраз экземпляра, соответствующего манере данного диктора говорить. Верификация диктора - это определение идентичности говорящего: тот ли это человек? Технология распознавания диктора позволяет использовать голос для обеспечения контроля доступа; например, телефонный доступ к банковским услугам, к базам данных, к системам электронной коммерции или голосовой почте, а также доступ к секретному оборудованию.
Основные методы, которые будут использованы при написанни программы распознования пользователя по тембру голоса: быстрое преобразование Фурье и Адаптивное преобразование Эрмита.

Рисунок 2. Концептуальная блок-схема разрабатываемой СКС.
Параметры анимации: количество циклов - 10, число кадров - 8, создана в Easy Gif Animator, размер - 60 Кб
Адаптивное преобразование Эрмита
Представление звукового сигнала, ориентированное непосредственно на квазипериодическую структуру речи основано на адаптивном преобразовании Эрмита.
Функции Эрмита образуют полную ортонормированную систему функций и определяются как:
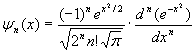
Они также могут быть определены следующими рекуррентными формулами:
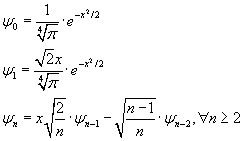
Кроме того, функции Эрмита являются собственными функциями преобразования Фурье
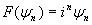
где F обозначает оператор преобразования Фурье.
Графики функций Эрмита выглядят следующим образом:
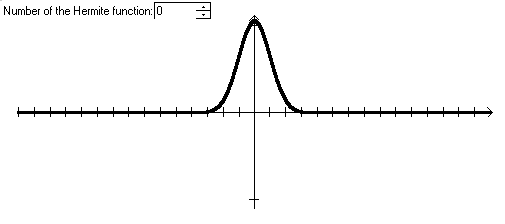
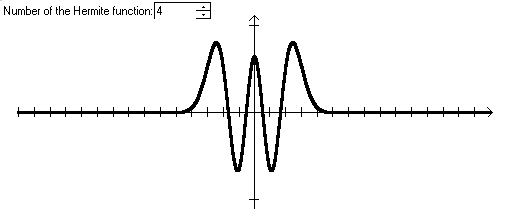
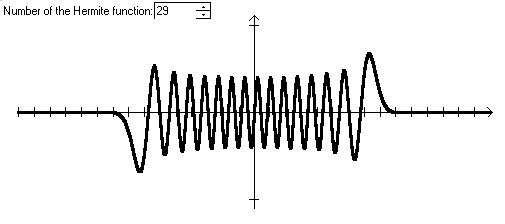
Рисунок 3. Графики функций Эрмита.
Для преобразования Эрмита мы должны определить отрезок интегрирования. Если мы посмотрим на структуру речевого сигнала, то увидим, что многие участки речи зачастую имеют квазипериодическую структуру (следует подчеркнуть, что длина соседних квазипериодов, а также форма волны в соседних квазипериодах могут немного различаться):
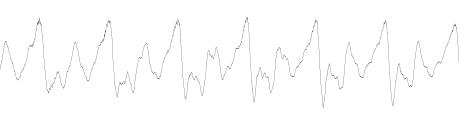
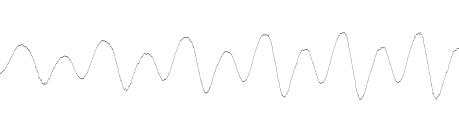
Рисунок 4. Вид волны в соседних квазипериодах.
В качестве исходного отрезка будем брать поочередно каждый из таких квазипериодов. Границы будем проводить таким образом, чтобы экстремум сигнала достигался приблизительно на середине квазипериода, а значения на границах были близкими к нулю. Далее мы растягиваем наш отрезок аппроксимации [-A0, A0] до отрезка [-A1, A1], определенного по следующему критерию:
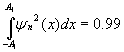
где n - число функций Эрмита, используемых для аппроксимации.
Затем мы раскладываем исходный сигнал в ряд Фурье по функциям Эрмита:
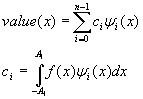
Так как функции Эрмита являются собственными функциями преобразования Фурье, то мы получаем и преобразование Фурье для данного сигнала.
Наряду с линейным кодированием можно использовать иерархическое кодирование, которое, с одной стороны, показывает более стабильные результаты, а, с другой стороны, позволяет провести аналогию между коэффициентами Эрмита и формантами. Суть его состоит в том, что сначала квазипериод приближается одной функцией, далее находится разность, которая растягивается до нужного для аппроксимации 2 функциями отрезка и приближается уже двумя функциями и т.д.
Следует подчеркнуть, что хоть такое представление и избыточно, но оно позволяет проводить полный анализ как в частотном диапазоне, так и во временном, что сказывается на возможности более тонкого анализа индивидуальных особенностей каждого человека.
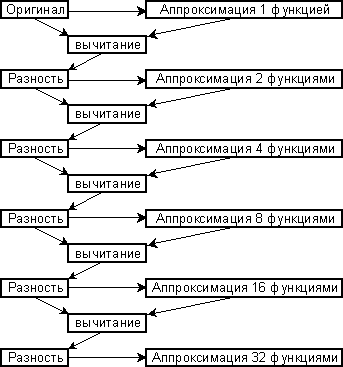
Рисунок 5. Блок-схема иерархического кодирования.
Практическая ценность
Можно выделить следующие области применения систем распознавания голоса:
1. Интерфейс между человеком и компьютером: очевидно, что многие люди испытывают трудности в общении с машиной, необходим новый способ общения с компьютером - простой, быстрый, интуитивный. Системы распознавания голоса заставляют машину приспосабливаться к человеку, а не наоборот. Огромное преимущество систем распознавания голоса в том, что они намного быстрее любых других типов интерфейсов. Голосовая программа электронной почты позволяет включить компьютер, продиктовать и послать сообщения не прикасаясь к мыши и клавиатуре. Также люди с физическими недостатками получат более эффективный способ взаимодействия с компьютером.
2. Информационные услуги. Речь - это идеальный инструмент для получения информации. И речь позволяет наладить взаимодействие с компьютером. При помощи систем разговорного языка пользователь и машина могут вступить в непосредственный диалог, постепенно, шаг за шагом, приближаясь к искомой информации. Например, разработаны системы распознавания голоса для обеспечения доступа к базам данных, содержащим оцифрованные клипы новостей телерадиовещания, систем заказа авиабилетов.
3. Другие человеко-машинные интерфейсы - системы распознавания лиц и сенсорные экраны, способствуют ускорению внедрения систем речевого общения - наблюдается тенденция к созданию комбинированных систем. Технологии распознавания лиц и голоса проникли и в банковский мир - вместе с банкоматами. За последнее десятилетие области применения систем распознавания речи значительно расширились и будут продолжать расширяться.
Решаемые вопросы
Что такое голосовая биометрия?
Идентификация по голосу происходит по следующей схеме: система сравнивает образец голоса, представленного в цифровой форме, с так называемым "голосовым отпечатком", хранящимся в базе данных. Голос является уникальной биометрической характеристикой человека и может использоваться для подтверждения его личности.
Что такое "голосовой отпечаток"?
"Голосовым отпечатком" называется цифровое изображение уникальных характеристик голоса. Голоса различаются, и эти различия обусловлены физиологическими характеристиками, такими как голосовые связки, трахеи, носовой проход; тем, как язык двигается во рту, и тем, как извлекаются звуки, и так далее. Комбинация этих характеристик анализируется и представляется уникальной для каждого человека.
Чем отличается верификация говорящего от распознавания речи?
Распознавание речи связано с тем, что было сказано, что и является главным отличием от верификации, связанной с тем, кто именно говорит. Системы голосовой идентификации не зависят от какого-либо языка или словаря. Человек может сказать что угодно и на каком угодно языке, что делает эти системы очень "дружелюбными" и идеальными для международного использования.
Как осуществляется занесение в базу данных?
Весь процесс занесения данных занимает несколько минут. Система предлагает ответить на несколько простых вопросов, например, ваше имя, отчество, фамилия или дата рождения. Ответы становятся идентификационными фразами, которые позднее будут использоваться для идентификации человека. Запомните, неважно, что
Вы скажете, главное, как
Вы это скажете; вопросы могут быть самыми разными, главное, чтобы ответ был хорошо знаком человеку, и он бы смог воспроизвести его в любую минуту. Для каждого вопроса пользователь произносит четыре раза свой ответ. Ответ должен состоять как минимум из трех слогов и длиться больше секунды для того, чтобы создать "голосовой отпечаток". Записанные ответы накладывают друг на друга, убирают посторонний шум и через несколько секунд "голосовой отпечаток" готов. Затем система таким же образом поступает с другими вопросами и ответами (системы безопасности предлагают делать несколько таких "голосовых отпечатков"). Через несколько минут создаются "голосовые отпечатки", которые будут применяться каждый раз, когда человек будет проходить через службу безопасности.
Как происходит верификация говорящего?
Пользователь произносит определенные фразы, и система сравнивает произнесенное с ранее сохраненным "голосовым отпечатком". Человек произносит две или три идентификационные фразы. Если две произнесенные фразы проходят биометрический тест, личность человека идентифицируется. Если одна из этих фраз не принимается, система обращается к третьей произнесенной фразе, и если она принимается системой, то личность пользователя также идентифицируется. Если система не уверена в правильности идентификации пользователя после трех произнесенных идентификационных фраз, она отказывает пользователю в доступе и отправляет к оператору, или связь просто прерывается.
Что значит "нормальный голос"?
Также как и с другими применениями биометрических технологий, успех голосовой идентификации зависит от неизменного, устойчивого образца. Если сравнивать данную технологию с идентификацией по отпечаткам пальцев, которая предполагает отсутствие порезов или грязи, то для голосовой идентификации неизменный, устойчивый образец - это значит говорить нормально, спокойно, то есть в обычной манере. Также пользователи должны понимать, что жевательная резинка, одышка, а также алкоголь негативно отражаются на голосе.
Если человек простужен, то будет ли идентифицирован его голос?
Не все характеристики вашего голоса пострадают, если вы простужены. Система голосовой идентификации все равно сможет узнать вас в случае обычной простуды. При серьезных заболеваниях горла, таких как ларингит, конечно, потребуются дополнительные средства идентификации.
Каковы границы распознавания?
В процессе голосовой идентификации (сравнение произнесенной фразы с ранее записанной) выдается список, который показывает насколько близко совпадает произнесенная идентификационная фраза с занесенной в базу данных. Система выдает цифры от -10,000 до +10,000. В теории, цифра 0 или меньше нуля показывает "вероятно обманщик"; цифра больше нуля показывает "вероятно правильный пользователь". Для того, чтобы быть уверенным в высоком уровне безопасности, сохраняя дружественность системы, для каждого порога установлен свой минимум. Также надо сказать, что установленные пороги распространяются как на оценку ложного доступа(false acceptance rate FAR), так и на оценку ошибочного отказа (false reject rate FRR).
FAR и FRR. Что это обозначает?
Уровень, по которому система будет пропускать пользователей, определяется каждой организацией. Часто администрация заявляет, что тех, кого система расценивает, как обманщика, вообще не пропускать (false acceptance rate FAR), и то, что не более х% правильных, действительных пользователей могут быть не узнаны системой (false reject rate FRR). В реальности надо признать, что ни одна система не может гарантировать 100% точность. FAR и FRR будут изменяться соответственно. Также многое зависит от характеристик окружающей обстановки, а также от уровня квалификации персонала.
Действительно ли голосовая идентификация обеспечивает 100% гарантию безопасности?
Нет такого решения, включая и биометрию, которое могло бы гарантировать 100% безопасность.
Правда ли, что для сохранения голосового отпечатка нужно много места?
В зависимости от длины устойчивого образца, системе понадобится от 20 до 40 Кб для голосового отпечатка. Ожидается, что в ближайшем будущем размеры будут уменьшены до 10-15 Кб.
Заключение
Применения систем голосовой идентификации уже можно встретить по всему миру. Компании радио и телевещания используют системы голосовой идентификации для обеспечения безопасности данных, передаваемых на большие расстояния. Правительственные агентства используют такие системы для защиты жизненно важной и секретной информации.
Разработка программного продукта посвященного данной проблеме на момент написания автореферата (май 2008) не является законченной. Планируемое время окончания работы - ноябрь 2008.
Литература
1.Винцюк Т.К. "Анализ, распознавание и интерпретация речевых сигналов." -Киев: Наук. думка, 1987. -262 с.
2. Кофман А. "Введение в теорию нечетких множеств" - М.:Радио и связь, 1982. -432с
3. Секунов Н. Обработка звука на PC. - СПб.:БХВ-Петербург, 2001-1248с.;
4. http://speech-soft.ru - сайт посвященный речевым технологиям и распознаванию речи
5. http://www.osp.ru - анализ рынка биометрических систем аутентификации, прогноз развития к 2009 году.
6. http://www.keldysh.ru - нейросетевой анализ и сопоставление частотно-временных векторов
на основе краткосрочного спектрального представления и адаптивного преобразования Эрмита
7. "Наукоемкие технологии и интеллектуальные системы в XXI столетии". - Сборник научных работ. Москва. 16-17 марта 2000 г. С.126-130.
 |

 ДонНТУ - >Портал магистров ДонНТУ
ДонНТУ - >Портал магистров ДонНТУ

 Кравченко
Дмитрий Александрович
Кравченко
Дмитрий Александрович