PARALLEL
PROCESSING WITH CUDA
Nvidia’s
High-Performance Computing Platform Uses Massive Multithreading
By
Tom R. Halfhill {01/28/08-01}
Источник: http://www.nvidia.com/docs/IO/55972/220401_Reprint.pdf
Introduction
Parallel processing on multicore
processors is the industry’s biggest software challenge, but the real problem is
there are too many solutions — and all require more effort than setting a
compiler flag. The dream of push-button serial programming was never fully
realized, so it’s no surprise that push-button parallel programming is proving
even more elusive.
In recent years, Microprocessor Report has been
analyzing various approaches to parallel processing. Among other technologies,
we’ve examined RapidMind’s Multicore
Development Platform (see MPR 11/26/07-01, “Parallel Processing for the x86”), PeakStream’s math libraries for graphics processors (see
MPR 10/2/06-01, “Number Crunching With GPUs”),
Fujitsu’s remote procedure calls (see MPR 8/13/07-01, “Fujitsu Calls
Asynchronously”), Ambric’s development-driven CPU
architecture (see MPR 10/10/06-01, “Ambric’s New Parallel
Processor”), and Tilera’s tiled mesh network (see MPR
11/5/07-01, “Tilera’s Cores Communicate Better”).
Now it is Nvidia’s turn for
examination. Nvidia’s Compute Unified Device
Architecture (CUDA) is a software platform for massively parallel high-performance
computing on the company’s powerful GPUs. Formally
introduced in 2006, after a year-long gestation in beta, CUDA is steadily
winning customers in scientific and engineering fields. At the same time, Nvidia is redesigning and repositioning its GPUs as versatile devices suitable for much more than
electronic games and 3D graphics. Nvidia’s Tesla
brand denotes products intended for high-performance computing; the Quadro brand is for professional graphics workstations, and
the GeForce brand is for Nvidia’s
traditional consumer graphics market.
For Nvidia, high-performance computing is both an opportunity to sell more chips and insurance against an uncertain future for discrete GPUs. Although Nvidia’s GPUs and graphics cards have long been prized by gamers, the graphics market is hanging. When AMD acquired ATI in 2006, Nvidia was left standing as the largest independent GPU vendor. Indeed, for all practical purposes, Nvidia is the only independent GPU vendor, because other competitors have fallen away over the years. Nvidia’s sole-survivor status would be enviable—should the market for discrete GPUs remain stable. However, both AMD and Intel plan to integrate graphics cores in future PC processors. If these integrated processors shrink the consumer market for discrete GPUs, it could hurt Nvidia. On the other hand, many PCs (especially those sold to businesses) already integrate a graphics processor at the system level, so integrating those graphics into the CPU won’t come at Nvidia’s expense. And serious gamers will crave the higher performance of discrete graphics for some time to come. Nevertheless, Nvidia is wise to diversify.
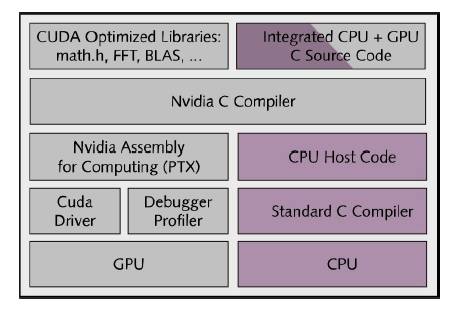
Figure 1. Nvidia’s CUDA platform for
parallel processing on Nvidia GPUs. Key elements are
common C/C++ source code with different compiler forks for CPUs and GPUs; function libraries that
simplify programming; and a hardware-abstraction mechanism that hides the
details of the GPU architecture from programmers.
Hence, CUDA. A few years ago,
pioneering programmers discovered that GPUs could be reharnessed for tasks other than graphics. However, their
improvised programming model was clumsy, and the programmable pixel shaders on the chips weren’t the ideal engines for general
purpose computing. Nvidia has seized upon this
opportunity to create a better programming model and to improve the shaders. In fact, for the high-performance computing
market, Nvidia now prefers to call the shaders “stream processors” or “thread processors.” It’s
not just marketing hype. Each thread processor in an Nvidia
GeForce 8-series GPU can manage 96 concurrent
threads, and these processors have their own FPUs,
registers, and shared local memory.
As Figure 1 shows, CUDA includes C/C++ software
development tools, function libraries, and a hardware abstraction mechanism
that hides the GPU hardware from developers. Although CUDA requires programmers
to write special code for parallel processing, it doesn’t require them to
explicitly manage threads in the conventional sense, which greatly simplifies
the programming model. CUDA development tools work alongside a conventional
C/C++ compiler, so programmers can mix GPU code with general-purpose code for
the host CPU. For now, CUDA aims at data-intensive applications that need
single-precision floating-point math (mostly scientific, engineering, and
high-performance computing, as well as consumer photo and video editing).
Double-precision floating point is on Nvidia’s
roadmap for a new GPU later this year.
Hiding the Processors
In one respect, Nvidia
starts with an advantage that makes other aspirants to parallel processing
envious. Nvidia has always hidden the architectures
of its GPUs beneath an application programming
interface (API). As a result, application programmers never write directly to
the metal. Instead, they call predefined graphics functions in the API.
Hardware abstraction has two benefits. First, it
simplifies the high-level programming model, insulating programmers (outside Nvidia) from the complex details of the GPU hardware.
Second, hardware abstraction allows Nvidia to change
the GPU architecture as often and as radically as desired. As Figure 2 shows, Nvidia’s latest GeForce 8
architecture has 128 thread processors, each capable of managing up to 96
concurrent threads, for a maximum of 12,288 threads. Nvidia
can completely redesign this architecture in the next generation of GPUs without making the API obsolescent or breaking
anyone’s application software.
In contrast, most microprocessor architectures are
practically carved in stone. They can be extended from one generation to the
next, as Intel has done with MMX and SSE in the x86. But removing even one
instruction or altering a programmer-visible register will break someone’s
software. The rigidity of general-purpose CPUs forced companies like RapidMind and PeakStream to
create their own abstraction layers for parallel processing on Intel’s x86 and
IBM’s Cell Broadband Engine. (PeakStream was acquired
and absorbed by Google last year.) RapidMind has gone
even further by porting its virtual platform to ATI and Nvidia
GPUs instead of using those vendors’ own platforms
for high-performance computing.
In the consumer graphics market, Nvidia’s
virtual platform relies on install-time compilation. When PC users install
application software that uses the graphics card, the installer queries the GPU’s identity and automatically compiles the APIs for the
target architecture. Users never see this compiler (actually, an assembler),
except in the form of the installer’s progress bar. Install-time translation
eliminates the performance penalty suffered by run-time interpreted or
just-in-time compiled platforms like Java, yet it allows API calls to execute
transparently on any Nvidia GPU. As we’ll explain
shortly, application code written for the professional graphics and
high-performance computing markets is statically compiled by developers, not by
the software installer—but the principle of insulating programmers from the GPU
architecture is the same.
Although Nvidia designed
this technology years ago to make life easier for graphics programmers and for
its own GPU architects, hardware abstraction is ideally suited for the new age
of parallel processing. Nvidia is free to design
processors with any number of cores, any number of threads, any number of
registers, and any instruction set. C/C++ source
code written today for an Nvidia GPU with 128 thread
processors can run without modification on future Nvidia
GPUs with additional thread processors, or on Nvidia GPUs with completely
different architectures. (However, modifications may be necessary to optimize
performance.)
Hardware abstraction is an advantage for software
development on parallel processors. In the past,