Измерения производительности многоядерных систем с поддержкой технологии HT
Желтов Сергей
Братанов Станислав
Source of information: http://www.intel.com/cd/corporate/europe/EMEA/RUS/update/272446.htm
Обзор: оценка производительности многопоточного кода
С точки зрения аппаратного обеспечения, многоядерные процессоры – это просто отдельные процессоры, расположенные на одном кристалле и заключенные в общий физический комплекс. Они обеспечивают вычислительные возможности, подобные традиционным симметричным многопроцессорным системам (symmetric multiprocessing, SMP), и неминуемо наследуют большинство проблем мониторинга производительности, характерных для работы с симметричными многопроцессорными системами.
В этой статье мы рассмотрим такие проблемы оценки производительности и покажем преимущества подхода к мониторингу производительности, основанного на потоках, как эффективного метода при работе с многопоточным кодом. Мы также рассмотрим этот подход как основу для решения частной задачи – мониторинга производительности многоядерных систем с поддержкой технологии Hyper-Threading (HT).
В этой статье обсуждаются некоторые методы и предлагаются решения проблем, которые нельзя решить, не принимая во внимание фактическое распределение потоков, их активность и взаимодействие.
Проблема мониторинга использования ресурсов, разделяемых между несколькими ядрами или процессорами, обсуждается на примере измерения уровня использования системной шины. Предлагается решение, основанное на мониторинге потоков, и сравнивается с подходами на основе выборок.
Также мы подробно обсудим метод, позволяющий избежать некоторых ограничений мониторинга производительности процессоров с поддержкой технологии HT, а также метод повышения точности измерений производительности технологии Hyper-Threading. Также мы сделаем обзор необходимых условий и преимуществ мониторинга потоков.
Известные методы мониторинга производительности
Основные проблемы мониторинга производительности являются общими как для однопоточных, так и многопоточных приложений, т. к. все современные операционные системы поддерживают многозадачную работу. Методы и проблемы, обсуждаемые здесь, полностью применимы ко всем многозадачным вычислительным средам и могут рассматриваться вне зависимости от того, сколько процессоров поддерживает конкретная вычислительная система.

Рисунок 1. Распределение выполнения потоков.
Обычно процесс выполнения задач под управлением многозадачной ОС выглядит так, как показано на Рисунке 1. Обработка потоков на процессоре периодически прерывается и приостанавливается, исходя из внутренних правил выбираются и планируются для выполнения другие потоки и так далее. Такой режим работы диктует правило мониторинга производительности в многопоточных средах: чтобы измерить количество прошедших событий (например, тактов процессора), система мониторинга должна обеспечить подсчет только тех событий, которые относятся к определенному потоку и к процессору, на котором он выполняется в настоящий момент. В противном случае результаты измерения будут зависеть от количества процессов и потоков, выполняющихся в текущий момент, а также от состояния системы, которое обычно непредсказуемо.
Существуют различные методы, позволяющие обеспечить соблюдение вышеуказанного условия.
Прямое измерение
Во-первых, если известен минимальный временной квант выполнения процессов в ОС, максимальное оцениваемое время выполнения тестируемого фрагмента кода не должно превышать длительность этого кванта, и начало измерения должно быть согласовано с началом выполнения. В таком случае ожидается, что полученные результаты измерения будут правильными. Но поскольку этот метод предполагает столько допущений и ограничений, его нельзя считать надежным.
Дискретная выборка
Второй способ фильтрации событий, относящихся к другим потокам, – использование метода дискретной выборки, основанной на времени или на событиях (Рисунок 2). В этом случае измерения выполняются через постоянные, переменные или настраиваемые интервалы времени, когда исследуемый поток (процесс) находится в активном состоянии. В результате будут собраны данные мониторинга производительности всей системы в целом, и с помощью дальнейшего анализа можно определить, сколько времени заняло выполнение каждого потока и сколько событий при этом произошло.
Этот метод достаточно надежен, хотя его точность обратно пропорциональна длительности интервала дискретизации. В то же время короткие интервалы дискретизации могут не только замедлить выполнение потока, но также вызвать частую очистку конвейера и другие изменения внутреннего состояния процессора. Это, в свою очередь, приведет к получению таких результатов измерения производительности, которые не составят представительной выборки, поэтому они будут неправильными.
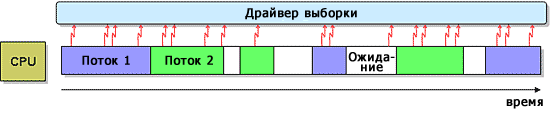
Рисунок 2. Пример процесса дискретной выборки.Обработка переключений контекста
Для третьего метода требуется прямое управление выполнением потока или, по крайней мере, наличие уведомлений о переключениях контекста (Рисунок 3). Если поток выбран для выполнения или приостановлен, система мониторинга производительности может проверить, необходим ли мониторинг именно этого потока, что повышает точность измерений.

Рисунок 3. Обработка переключений контекста.
По сравнению с двумя предыдущими методами этот метод обеспечивает более высокую точность, которая в первую очередь зависит от механизма оповещения о переключениях контекста. Этот метод не оказывает существенного влияния на выполнение потоков, т. к. все служебные вычисления, выполняемые системой мониторинга, производятся во время «естественных» окон между переключениями контекста, а в эти периоды так или иначе происходит изменение состояния процессора.
Сочетание метода дискретной выборки и метода обработки переключений потоков может принести интересные результаты: можно независимо выполнять мониторинг каждого потока, легко рассчитать время выполнения, а выборка на основе событий, выполняемая в течение кванта активности потока, может помочь определить реальное распределение времени между событиями и выполнением кода, как показано на Рисунке 4.
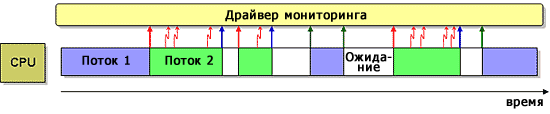
Рисунок 4. Выборка на основе переключений потоков.
Для завершения картины стоит упомянуть, что все результаты мониторинга производительности обычно объединяются в записи о производительности (информация о временах задержки, количестве событий и адресах), которые затем сохраняются для последующего анализа или обрабатываются в реальном времени, чтобы предоставить пользователю окончательные результаты.
Мониторинг симметричных многопроцессорных систем
Для мониторинга симметричных многопроцессорных систем (независимо от конкретного используемого метода) система мониторинга должна установить контроль над каждым процессором, чтобы избежать неполной регистрации, когда поток или процесс распределяется для выполнения на процессоре, мониторинг которого в настоящий момент не выполняется. Для установления вышеупомянутого контроля необходима или процедура мониторинга (или выборки), которая непрерывно работает на каждом процессоре, или, при наличии возможности обработки переключений контекста потоков, переключение на определенный процессор, на котором активизируется исследуемый поток.
После того как установлен контроль процессоров, могут возникнуть дополнительные ограничения, если необходимо выполнять мониторинг события, которое показывает использование разделяемых аппаратных ресурсов. Например, если необходимо измерить степень использования шины контроллера, связывающей процессор и память, независимые измерения активности системной шины каждого процессора недостаточны.
Проблема измерения использования общих ресурсов
В этом разделе мы рассмотрим упрощенный пример измерения степени использования шины памяти в качестве примера измерения использования общих ресурсов несколькими процессорами. В данном случае наше основное допущение – равномерное распределение времени между процессорами для доступа к памяти. Рассмотрим следующую формулу:
Здесь B – степень использования шины, k – отношение частот процессора и шины, Tbdr – время (количество тактов процессора) активности сигнала для системной шины процессора. И, наконец, T – средний интервал времени использования шины при передаче данных.
Эта формула описывает степень использования шины в случае одного процессора, а для симметричных многопроцессорных систем она рассчитывается для каждого процессора и показывает только степень использования системной шины каждым процессором. Мы не можем получить информацию о пропускной способности памяти (или внешней кэш-памяти) контроллера шины для системы в целом.
Чтобы получить такую информацию, запишем следующую формулу:
Здесь Bn – средняя степень использования шины для n-го процессора, N – количество процессоров в системе, Bseq соответствует средней степени использования шины для системы в целом, а Bpar показывает среднюю степень использования шины в случае параллельного доступа.
Параллельный доступ означает, что все процессоры имеют доступ к шине во время одного и того же временного интервала T, который служит для вычисления средней степени использования.
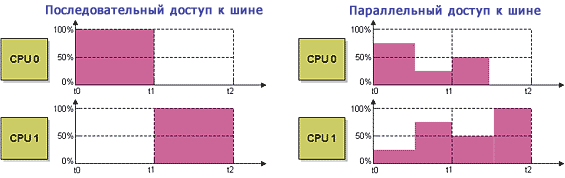
Рисунок 5. График использования шины.
Таким образом, в соответствии с Рисунком 5, степень использования шины Bn усредняется по равным интервалам времени [T0, T1] и [T1, T2]. Предполагается, что доступ к шине последовательный, если в течение интервала времени, необходимого для усреднения использования шины, активен только один процессор. В противном случае, если в течение интервала усреднения имеется несколько активных процессоров, доступ будет параллельным.
В примере, представленном на Рисунке 5, мы можем рассчитать степень использования шины следующими способами:
- Для случая последовательного доступа суммарное время использования шины в течение обоих интервалов делится на число процессоров ((100% + 100%) / 2 = 100%).
- Для случая параллельного доступа время использования шины в каждом интервале суммируется (25% + 75%) и (50% + 50%), и мы получаем 100% использования шины.
Определение интервалов с параллельным доступом
Рассуждения, приведенные выше, показывают, что для определения степени использования шины многопоточным приложением в многопроцессорной системе система мониторинга должна иметь возможность определять, какие части (потоки) приложения выполняются одновременно на разных процессорах, какие потоки работают последовательно, а какие приостановлены.
Системы, основанные на выборке, которые выполняют измерения на основе внешней временной шкалы, достаточно хороши для получения усредненных результатов при проведении приблизительного анализа сложных приложений, выполнение которых занимает значительное время (до нескольких минут). Но проблемы точности измерений, которые обсуждались в предыдущих разделах, все еще встают в случае симметричных многопроцессорных систем, и, что еще хуже, точность может упасть из-за невозможности точного определения момента времени, когда начинается параллельное выполнение потока 0 и потока 1 (как показано в примере на Рисунке 6), если такое определение основано на асинхронных прерываниях для выборки.

Рисунок 6. Определение участков параллельного выполнения потоков, основанное на выборке.
Как следует из Рисунка 7, для корректного вычисления степени использования разделяемых ресурсов в симметричных многопроцессорных системах информация о переключении контекста безусловно необходима. Более того, возможность «отслеживать» переключение потоков с процессора на процессор и сбор информации об ID процессора, назначенного для выполнения, во время переключения контекста позволяет определить наличие параллельных вычислений, чтобы получить правильные результаты расчетов.
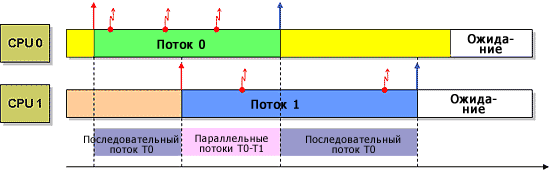
Рисунок 7. Определение участков параллельного выполнения потоков, основанное на отслеживании переключений контекста.Мониторинг симметричных многопоточных систем
Симметричные многопоточные системы (Symmetric Multithreading, SMT) с точки зрения ПО не сильно отличаются от симметричных многопроцессорных систем, за исключением того, что в них имеются внутренние ресурсы, совместно используемые логическими процессорами в одном физическом процессорном корпусе. В этом разделе мы расскажем о симметричных многопоточных системах с архитектурой Intel® на базе технологии HT.
В текущих реализациях технологии HT существует несколько параметров производительности, которые могут измеряться как для системы в целом, так и для подмножества логических процессоров, но с одним ограничением: выбор подмножества влияет на все логические процессоры, т. е. когда один логический процессор переходит из одного подмножества в другое, это влияет на измерение производительности остальных.
Борьба с ограничениями
Методы, основанные на дискретных выборках, не обеспечивают точного способа определения периодов параллельного выполнения потоков. Реализации систем мониторинга производительности страдают или чрезмерным количеством отсчетов (если мониторинг каждого логического процессора выполняется независимо), или применимы только к физическим процессорам, что абсолютно не подходит для симметричных многопоточных систем.

Рисунок 8. Мониторинг производительности симметричных многопоточных систем.
Однако, при наличии уведомлений о переключении потоков система мониторинга может эффективно контролировать распределение разделяемых физических ресурсов между логическими процессорами. Один из возможных вариантов показан на Рисунке 8. Первый поток, назначенный на выполнение на одном из логических процессоров, завладел ресурсом мониторинга производительности, и начался подсчет. Другие потоки, запланированные на выполнение на том же самом физическом процессоре, должны проверить, могут ли они получить доступ к этому ресурсу. Если нет, они могут добавить свои идентификаторы в список ожидания или в подмножество выбранных логических процессоров (см. выше) и продолжать выполнение. Когда поток, владеющий ресурсом, приостанавливается или переключается на другой процессор, система мониторинга выбирает из списка ожидания другой поток и передает владение ресурсом этому потоку.
Такая схема позволяет правильно подсчитывать события, но точность оценки распределения событий между потоками продолжает зависеть от модели распределения.
Чтобы доказать пригодность предлагаемого метода мониторинга симметричных многопоточных систем, желательно оценить его точность и сравнить его с другими методами. Результаты сравнения приведены на Рисунке 9.
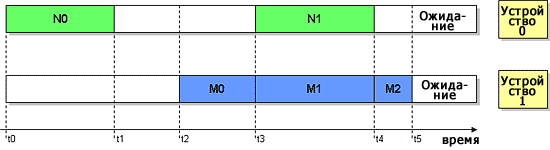
Рисунок 9. Примерное использование ресурсов симметричной многопоточной системы во времени.
В соответствии с методом, не предназначенным для симметричных многопоточных систем, первое устройство, запросившее выполнение, или предопределенное устройство (например, устройство 0), собирает все данные о производительности, относящиеся ко всем устройствам. В этом случае все события мониторинга производительности, которые произошли в интервале времени [t0, t5], будут приписаны устройству 0. Предположим, что устройство 0 фактически выполнило N=N0+N1 событий, а устройство 1 насчитало M=M0+M1+M2 событий. Сумма N и M будет присвоена устройству 0 (или 1). Это может привести к тому, что точность будет изменяться от 0 до 100% в зависимости от фактических значений N и M (если N стремится к нулю, точность тоже будет стремиться к нулю из-за того, что сумма будет присвоена почти неактивному устройству).
В соответствии с методом, предложенным выше, последнее устройство, отправившее запрос на мониторинг производительности, посылает сигнал о своем активном состоянии устройству, которое уже собирает данные о производительности, и в тот момент, когда устройство, собирающее данные, становится неактивным, оно посылает сигнал другому устройству о необходимости продолжать сбор данных о производительности. Например, количество событий, которые произошли в интервале времени [t0, t1] (назовем его N0), будет присвоено устройству 0, а сумма (M и N1) событий, которые произошли в интервале времени [t2, t5], будет присвоена устройству 1. Точность измерений при таком подходе также может варьироваться от 0 до 100%, как и при подходе, рассмотренном выше, но этот метод гарантирован от чрезмерного количества отсчетов.
Повышение точности
Лучших результатов можно достичь, если события, которые произошли в интервале времени [t3, t4], будут распределены между устройствами как средняя величина или взвешенное произведение общего количества событий в интервале времени и вероятности, присвоенной каждому устройству. Для этого необходимо или запоминать информацию об активности устройств для дальнейшего анализа, или использовать адаптивный метод мониторинга производительности, описанный ниже.
Суть адаптивного метода заключается в программировании устройства мониторинга производительности (Performance Monitoring Unit, PMU) для сбора информации о производительности для выбранного устройства (а также для других устройств, которые могли послать запрос на выполнение этой операции раньше) и генерировании сигнала (или прерывания) процессора, когда подсчитано определенное количество событий (что во многом подобно методу выборки на основе событий). Количество событий может быть установлено заранее или настраиваться в процессе измерений, чтобы приспособить систему мониторинга к разным интервалам активности. Для некоторых случаев взаимодействия потоков чем меньше это значение, тем больше данные о производительности приближаются к средним, однако задание очень маленького значения может повысить издержки из-за слишком частых прерываний.
При наступлении заданного количества событий происходит асинхронное прерывание исполняющего устройства, которое владеет PMU, и начинается выполнение следующих действий: может быть считано текущее значение, подсчитанное в PMU, и присвоено текущему активному исполняющему устройству (execution unit, EU). Затем может быть выполнена проверка наличия ожидающих запросов. В случае если нет запросов, находящихся в состоянии ожидания, PMU снова может быть запрограммировано для подсчета предопределенного или предварительно оцененного количества событий для текущего EU.
Если имеются другие запросы на обслуживание, выполняется выбор нового запроса (и соответствующего EU), и PMU подобным же образом программируется для другого EU.
Чтобы лучше понять, как этот метод влияет на точность мониторинга производительности, вернемся к Рисунку 9. Теперь события, которые произошли в интервале времени [t0, t1], будут присвоены устройству 0, события, которые произошли в интервалах времени [t2, t3] и [t4, t5], будут присвоены устройству 1, а события, которые произошли в интервале времени [t3, t4], будут распределены поровну (или в соответствии с используемой моделью) между всеми EU.
Таким образом, система, основанная на этом методе, может показать точность измерений не меньше 50% (в случае равномерной загрузки устройств выполнения), динамически приспосабливаться к изменению интервалов активности EU и выполнять квазинезависимый мониторинг производительности на основе потоков.
Применимость
Этот метод разделения ресурсов может быть очень эффективным, когда программа (или исполняющий поток/устройство), для которой выполняется мониторинг, посылает сигнал или сообщает о том типе своей активности, для которого необходимо выполнять мониторинг. Таким образом, система мониторинга может решить, ресурсы какого конкретного процессора необходимо разделять, т. е. нужно ли перепрограммировать аппаратуру процессора для подсчета событий другого потока (исполняющего устройства) при получении очередного сигнала переполнения.
Предлагаемый метод также может применяться для несимметричных систем в том случае, если исполняющие устройства (или процессоры) в таких системах могут получать сигналы от PMU и имеют хотя бы один совместно используемый ресурс, позволяющий обмениваться служебными данными о производительности.
Заключение
Как было показано в этой статье, бывают случаи, когда точных результатов нельзя достичь без представления о фактической активности потоков во времени, определения интервалов параллельного выполнения и совместного использования ресурсов мониторинга производительности на основе потоков.
Имеется необходимость отслеживания переключений контекста выполнения, и системы мониторинга производительности необходимо разрабатывать таким образом, чтобы обеспечить сбор данных о производительности независимо для каждого исполняющего потока.
Программные системы мониторинга, соответствующие этим условиям, могут уменьшить налагаемые ограничения и сократить сложность аппаратного обеспечения для мониторинга производительности. Например, если нет технической возможности оснастить каждый логический процессор в симметричной многопроцессорной или многопоточной системе отдельным устройством мониторинга производительности, можно получить адекватные результаты, применяя метод совместного использования ресурсов для мониторинга производительности на основе потоков, описанный в этой статье.
Для оценки загрузки разделяемого ресурса в симметричной многопроцессорной системе нет необходимости подключать устройство мониторинга к самому ресурсу (например, к шине, памяти, контроллерам ввода/вывода). Достаточно дать возможность каждому агенту, имеющему доступ к этому ресурсу, собирать данные о собственной активности при выполнении на основе потоков. Это позволит системе мониторинга находить участки повышенного или пониженного использования ресурса (по времени и по выполняемому коду) и в то же время относить полученные данные к конкретному потоку, представляющему интерес.
Преимущества получения фактической информации об активности потоков по сравнению с усредненной информацией о производительности системы:
- Усредненная информация отражает фактические данные, которые получит конечный пользователь в ответ на свои запросы о приложении (части целой вычислительной системы).
- Такая усредненная информация может сильно меняться и даже давать непредсказуемые результаты, если она основана на конкретных условиях запуска приложений.
- Необходима точная информация, связанная с приложениями, которая позволит разработчику увидеть разницу между событиями, вызванными системой, и некорректным или неоптимальным поведением приложения, чтобы получить ответ на вопрос, можно ли улучшить приложение и какие методы следует для этого применять.