Источник: ACM FCRC, San Diego, CA, June 2007.
http://www.cs.rochester.edu/u/cli/research/switch.htm
АННОТАЦИЯ
Измерение накладных затрат при переключении контекста вызываемых
задач. В этой статье, мы показываем наши результаты экспериментального
определения количества накладных расходов при переключении контекста, используя
искусственную рабочую нагрузку. В особенности, мы измеряем воздействие большого
шага размера и доступа данных программы на затратах переключения контекста. Мы
также демонстрируем потенциальное воздействие обработки перерываний ОС на
точности измерений. Такое воздействие может быть облегчено при использовании
мультипроцессорной системы, на которой один процессор используется для
измерения переключения контекста в то время как фоновые задачи ОС выполняются
на другом.
Категории и Предметные описатели
D.4.8 [Операционные Системы]: Производительность –
Измерения;
C.4 [Организация компьютерных систем]: Производительность
систем – методы измерения систем.
Ключевые слова
Переключение контекста, кэш интерфейс
1. ВВЕДЕНИЕ
Для мультизадачных систем, переключение контекста ведет
к переключению центрального процессора от одного процесса или нити к другому. Переключение
контекста делает мультизадачность возможной. В то же самое время, это вызывает
неизбежную системную нагрузку. Возникновение накладных расходов может произойти
по нескольким причинам. Регистры процессора должны быть сохранены и
восстановлены, код ядра операционной системы (планировщик) должен был выполнен,
записи TLB должны быть перезагружены, и конвеер процессора должен сбросится[2]. Эти
накладные расходы непосредственно связаны с почти каждым переключением
контекста в системе мультизадачности. Мы называем их прямыми затратами. Кроме
того, переключение контекста приводит к разделению кэша между многими
процессами, что может привести к ухудшению производительности. Эта стоимость
изменяется для различных рабочих нагрузок с различными моделями доступа памяти
и для различных архитектуры. Мы называем это задержкой интерфейса кэша или накладными
затратами переключение контекста. Доклад теперь продолжает описывать подход и
результат нашего измерения на прямой и косвенной стоимости переключения
контекста.
2. ПОДХОД ИЗМЕРЕНИЯ
В предыдущей работе, Ousterhout измерил прямую стоимость выключателя
контекста, используя критерий с двумя процессами, общающимися через два канала[6].
McVoy и др.
измерил стоимость переключение контекста между множеством процессов, используя lmbench [4]. Основываясь на этих
традиционных методах, мы также использовали коммуникацию канала, чтобы
осуществить частые переключения контекста между двумя процессами. Мы сначала
измеряем прямое время переключение
контекста (c1), используя метода Ousterhout, где процессы не делают никакого
доступа к данным. Тогда мы измеряем полное время переключения контекста (c2),
когда каждый процесс размещает и получает доступ к множеству чисел с плавающей
запятой. Следует отметить, что общее время (c2) включает накладные расходы на
восстановление состояния кеша. Накладные расходы рассчитываются как c2 - c1.
2.1 Прямые затраты на переключение контекста (c1)
Следуя методу Ousterhout, мы имеем два процесса, неоднократно
посылающие однобайтовые сообщения друг другу через два канала. В течение
каждого цикла обмена между процессами, есть два переключение контекста, плюс
одно чтение и одна запись системного вызова в каждом процессе. Мы измеряем время
10 000 обменов (t1). Мы используем единственный процесс, моделирующий
коммуникацию двух процессов, посылая однобайтовое сообщение себе через
один канал. Каждый обмен моделируемой коммуникации
включает только одно чтение и запись системного процесса. Поэтому, процесс
моделирования делает половину работы, которую выполняют два обменивающихся
процесса за исключением переключением контекста. Мы измеряем затраты времени 10
000 моделируемых коммуникаций (t2), которые не включают никакой переключения контекста.
Мы получаем прямое время переключение контекста как
c1 = t1/20000 - t2/10000.
2.2 Общая стоимость переключения контекста (c2)
Управляющий поток этой тестовой программы подобен той
из секции 2.1. Однако, после того, как каждый процесс становится runnable, он получит доступ к множеству чисел
с плавающей запятой прежде, чем он напишет сообщение другому процессу а затем
заблокирует на следующую операцию чтения.
Мы также имеем единственный процесс, моделирующий
поведение этих двух процессов за исключением переключения контекста. Процесс
моделирования сделает то же самое количество доступов к массиву как каждый из
двух общающихся процессов. Учитывая выполнение 10 000 обменов между двумя тестовыми
процессами - (s1) и время выполнения 10 000 моделируемых обменов (s2), мы
получим полное время переключения контекста как c2 = s1/20000 - s2/10000. Мы
изменяем следующие два параметра в течение других запусков нашего теста:
• Размер массива: данные, к которым получает доступ
каждый процесс.
• Шаг доступа: размер шагов доступа.
2.3 Избежание потенциального вмешательства
Чтобы избегать потенциального вмешательства от
второстепенной обработки прерываний ОС или от других процессов в системе, мы
используем механизм двойного процессора для нашего эксперимента. Так как
большинство обработчиков прерываний ОС привязаны на один процессор по
умолчанию, мы назначаем обменивающиеся процессы и процесс моделирования в нашем
эксперименте на другой процессор. Мы также устанавливаем нашим тестовым
процессам политику реального времени FIFO SCHED и даем им максимальный приоритет.
По-видимому, большинство стандартных задач ОС и внезапные обработки событий не
будут сталкиваться с нашим измерением. И никакой другой процесс не может
выгрузить ни один из наших тестовых процессов пока наш процесс - runnable. Система Linux вызывает sched seta_nity (), и sched setscheduler () используются к e_ect проекту.
2.4 Измерение времени
Таймер, который мы используем, - с высокой разрешающей
способностью таймер, который использует регистр подсчета в центральном
процессоре. Он измеряет время, считая число циклов, которые центральный
процессор прошел начиная с запуска. Когда длина времени измеряемого события
чрезвычайно коротка, накладные расходы самого таймера могут вызвать некоторую
ошибку. Поэтому, мы измеряем стоимость большого количества (20 000) переключений
контекста и затем сообщаем о среднем времени.
3. ЭКСПЕРИМЕНТАЛЬНЫЕ РЕЗУЛЬТАТЫ
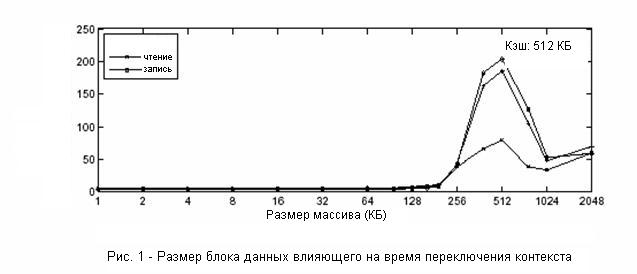
Машина, которую мы используем, - IBM eServer с двухядерным 2.0 ГГц Intel Pentium Xeon CPU. Каждый процессор имеет 512 КБ L2
кэш и размер линии кэша – 128Б. Операционная система - Linux 2.6.17 Redhat 9. Компилятор - gcc 3.2.2. Мы не используем никаких
опций оптимизации для компиляции. Наш исходный текст может быть найден в <http://www.cs.rochester.edu/u/cli/research/switch.htm>.
Средняя прямая (c1) стоимость переключения контекста в нашей системе - 3.8
микросекунды. Результаты, показанные ниже - об общих затратах на переключение контекста
(c2). Вообще, c2 располагается от нескольких микросекунд до больше чем одной
тысячи микросекунд. Накладные затраты переключения контекста могут быть оценены
как c2 - c1. В следующих подразделах, мы сначала обсуждаем эффекты большего
шага и размера данных на стоимости переключения контекста. Потом мы обсудим
влияние экспериментальной среды на точность измерения.
…
6. Список использованной литературы
[1] Anant Agarwal,
John L. Hennessy, and Mark Horowitz.Cache performance of operating system and
multiprogramming workloads. ACM Trans. Comput. Syst., 6(4):393–431, 1988.
[2] R. Fromm and N.
Treuhaft. Revisiting the cache interference costs of context switching.
http://citeseer.ist.psu.edu/252861.html.
[3] R. Jain. The
Art of Computer Systems Performance Analysis: Techniques for Experimental
Design, Measurement, Simulation and Modeling. John Wiley & Sons, 2001.
[4] L. McVoy and C.
Staelin. lmbench: Portable Tools for Performance Analysis. In In Proc. of the
USENIX Annual Technical Conference, pages 279–294, San Diego, CA, January 1996.
[5] J. C. Mogul and
A. Borg. The E_ect of Context Switches on Cache Performance. In In Proc. of the
Fourth International Conference on Architectural Support for Programming
Languages and Operating Systems, pages 75–84, Santa Clara, CA, April 1991.
[6] J. K.
Ousterhout. Why Aren’t Operating Systems Getting Faster As Fast As Hardware ?
In In Proc. Of the USENIX Summer Conference, pages 247–256, Anaheim, CA, June
1990.
[7] G. Edward Suh,
Srinivas Devadas, and Larry Rudolph. Analytical cache models with applications
to cache partitioning. In Proceedings of the International Conference on
Supercomputing, pages 1–12, 2001.