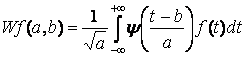
Источник: http://www.ict.nsc.ru/ws/YM2004/8532/Leonovich_Title.htm
Одним из основных подходов, используемых при построении речевых распознавателей, является подход, основанный на обработке акустических сигналов, который опирается на следующее положение: поскольку речевой сигнал является особой формой сигнала (или вектором чисел), то к нему применимы общие методы обработки сигналов (например, анализ частотного спектра Фурье, анализ основных составляющих, процедуры статистических решений и другие математические методы). Эти методы используются для того, чтобы установить идентичность входного сигнала одному из шаблонов.
Многие методы математической обработки сигналов (кепстральный анализ, скрытое марковское моделирование) для получения описательных признаков речи используют в основе частотный анализ Фурье. Однако, преобразование Фурье обладает рядом существенных недостатков:
Речевой сигнал является примером нестационарного процесса, в котором информативным является сам факт изменения его частотно-временных характеристик.
Для выполнения анализа таких процессов требуются базисные функции, обладающие способностью выявлять в анализируемом сигнале как частотные, так и его временные характеристики. Другими словами, сами функции должны обладать свойствами частотно-временной локализации.
Исходя из этих соображений уместно применить такой математический метод, как вейвлет-преобразование. Вейвлет-преобразование сигналов является обобщением спектрального анализа. Применяемые для этой цели базисы были названы вейвлетами – функциями двух аргументов – масштаба и сдвига. В отличие от традиционного преобразования Фурье, вейвлет-преобразование обеспечивает двумерное представление исследуемого сигнала в частотной области в плоскости частота-положение. Аналогом частоты при этом является масштаб аргумента базисной функции (чаще всего – времени), а положение характеризуется ее сдвигом. Это позволяет разделять крупные и мелкие особенности сигналов, одновременно локализуя их на временной шкале. Иными словами, вейвлет-анализ можно охарактеризовать как спектральный анализ локальных возмущений [1].
Главными направлениями данного метода являются непрерывный и дискретный вейвлет-анализ.
Результатом непрерывного вейвлет-анализа некоторого сигнала, заданного функцией f(t), будет функция Wf(a,b), которая зависит уже от двух переменных – от координаты b и от масштаба a.
Строгое определение выглядит так:
|
|
(1) |
Распределение значений коэффициентов Wf(a,b) в пространстве (a,b) дает информацию об эволюции относительного вклада компонент во времени и называется спектром коэффициентов вейвлет-преобразования, (частотно-) масштабно-временным спектром или вейвлет-спектром.
Способы визуализации этой информации могут быть различными. Спектр Wf(a,b) часто представляют в виде проекции на плоскость (a,b) с изолиниями или изоуровнями, позволяющими проследить изменения интенсивности амплитуд вейвлет-преобразования на разных масштабах и во времени, а также картины линий локальных экстремумов этих поверхностей (так называемый «skeleton»), четко выявляющие структуру анализируемого процесса (рис. 1).
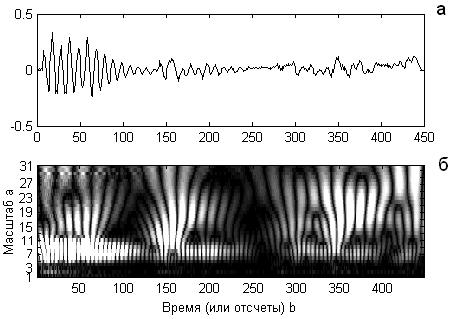
На рисунке 1б светлые области соответствуют положительным, а темные – отрицательным значениям Wf(a,b), оттенками серого цвета в каждой из областей выделены диапазоны значений Wf(a,b). Ясно, что значение амплитуды вейвлет-преобразования в точке (a0,b0) тем больше (по абсолютной величине), чем сильнее корреляция между вейвлетом данного масштаба и поведением сигнала в окрестности t=b0. Картина коэффициентов демонстрирует, что процесс составляют компоненты разных масштабов: экстремумы Wf(a,b) наблюдаются на разных масштабах, интенсивность их меняется и со временем, и с масштабом.
Многие авторы полагают, что скелетон не только четко и без лишних деталей визуализирует структуру анализируемого процесса, но фактически содержит всю информацию о нем. Исходя из этого, было принято решение для описания речевого сигнала использовать скелетон сигнала в координатном представлении.
На основе этого была построена система распознавания речи [2]. Исходный речевой сигнал сегментировался на фонемы и для каждого сегмента находился скелетон со значением масштаба a=32 при помощи вейвлета Морле. Полученные признаки сохранялись в базу данных эталонов. Сравнение с эталоном производилось при помощи алгоритма динамического программирования, с одновременным временным выравниванием. Совпадение считалось по порогу pвыбранному экспериментально.
В результате получены следующие показатели: средний коэффициент распознавания составил 63%. Это означает, что из 100 введенных фонем, верно распознаны 63, остальные либо не распознаны, либо распознаны неверно.
Другая ветвь вейвлет-анализа – это дискретный вейвлет-анализ. Рассмотрено одно из его направлений многомасштабный (кратномасштабный) вейвлет-анализ, идея которого состоит в представлении сигнала последовательностью образов с разной степенью детализации, что позволяет выявлять локальные особенности сигнала и классифицировать их по интенсивности.
Многомасштабный вейвлет-анализосновывается на разложении сигнала по функциям, образующим ортонормированный базис [3]. Любую функцию можно разложить на некотором заданном уровне разрешения (масштабе) jn в ряд вида:
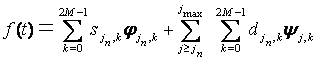 |
(2) |
Масштабирование и смещение функцийи
- масштабированные и смещенные версии скейлинг-функции (масштабной функции)
и «материнского вейвлета»
;
sj,k - коэффициенты аппроксимации;
dj,k - детализирующие коэффициенты.
|
|
(3) |
|
|
(4) |
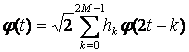 |
(5) |
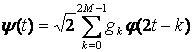 |
(6) |
|
|
(7) |
Таким образом, многомасштабный вейвлет-анализ сводится к нахождению коэффициентов аппроксимации sj,k и детализирующих коэффициентов dj,k в разложении сигнала f(t) по формуле (2) ортогональным вейвлет-преобразованием.
Первая сумма в (2) содержит средние значения f(t) по диадным интервалам. Второй член содержит все флуктуации f(t) на данном интервале. Эти флуктуации проистекают из всех меньших интервалов, заключенных внутри данного и соответствующих большим значениям параметра масштабирования j. Можно сказать, что этот член «фокусирует» внимание на все более тонких деталях изучаемого сигнала.
При построении системы распознавания на основе многомасштабного вейвлет-анализа в качестве характеристических признаков речевого сигнала были выбраны коэффициенты детализации ортогонального вейвлет – преобразования.
Создана аналогичная система распознавания, где для каждого сегмента речевого сигнала находились детализирующие коэффициенты с использованием ортогонального вейвлета Добеши 4.
Эксперименты проводились на тех же фонемах, что и в случае с непрерывным вейвлет-анализом. Результат: средний коэффициент распознавания составил 82%.
Полученные результаты дают основание полагать, что ортогональный вейвлет-анализ наиболее предпочтителен для обработки речевых сигналов, однако, в данном случае эксперименты носили предварительный характер. В частности, не проводилась работа по оптимизации признаков, полученных на основе вейвлетов. В настоящий момент в этих направлениях проводятся исследования.