Представление нейросетей
Данная работа посвящена
разработке алгоритмов в концепции построения нейронных сетей с самостоятельной
адаптацией (самоадаптирующихся нейросетей), предложенных в работах [[1],[2]], позволяющей значительно расширить
возможности нейросетевых методов управления и обработки информации.
Пусть функционирование
нейрона нейросети описывается уравнением
![]() , (
1 )
, (
1 )
где Ai - внешние входные сигналы; aj - входные сигналы от других нейронов; xij - веса межнейронных
связей.
В работе [[3]] показано, что можно получить сколь
угодно точное приближение любой непрерывной функции многих переменных,
используя операции сложения и умножения на число, суперпозицию функций,
линейные функции, а также одну произвольную непрерывную нелинейную функцию
одного переменного. Для нейросетей это означает, что для получения указанного
результата от функции активации нейрона требуется только нелинейность.
Адаптивные возможности предлагаемых алгоритмов с ускоренным стохастическим
поиском позволяют в полной мере реализовать потенциальные возможности нейросетей.
Целевая функция с помощью
которой оценивается успешность обучения (адаптации) может быть задана, например,
следующим образом:
![]() , ( 2
)
, ( 2
)
где ai* - требуемые значения ai. Однако существуют и другие возможности [1,2].
В работе [1] приведен метод
случайного поиска с целью адаптации нейросети, построенный на флюктуациях весов
межнейронных связей. Обладая всеми необходимыми качествами для создания самоадаптирующихся
нейросетей, этот метод требует изменения N2
параметров на каждом пробном шаге, где N
- число формальных нейронов полносвязной нейросети. Метод адаптации, предложенный
в работе [2] дает
возможность сократить число изменяемых параметров поиска с N2 до N за
счет варьирования величинами ri вместо xij, что обеспечивает ускорение обучающих алгоритмов.
Дальнейшее ускорение осуществляется прогнозированием последующего направления
поиска с использованием предыдущего опыта адаптации. Комбинация этих методов
позволяет существенно ускорить процедуру случайного поиска, приближая ее
быстродействие к детерминированным алгоритмам и сохраняя ее преимущества перед
другими методами при построении самоадаптирующихся нейросетей.
Алгоритм самоадаптации нейросетей
В процессе адаптации
(обучения) нейросети происходит подстройка весовых коэффициентов xi до тех пор, пока не будет
получен набор xij,
удовлетворяющих условию H£m, где m максимально допустимая
величина ошибки.
В работе предложенного в
публикации [2]
алгоритма можно выделить три повторяющихся этапа:
1. Сохранение
текущих значений ri0 для каждого нейрона и H0 для сети в целом.
2. Подбор
методом случайного поиска величин ri таким образом, чтобы
выполнялось условие H<H0.
При этом ошибка в уровне активности каждого нейрона сети может быть получена
как
![]() .
.
3. Подстройка
весовых коэффициентов осуществляется с помощью преобразования
![]() ,
,
аналогичного обобщенному
правилу [[4],[5]] Уидроу-Хоффа [[6]]
(дельта-правилу), а коэффициент y
пропорционален скорости изменения xij.
Изменение xij ведет к уменьшению Dri, приближающему величины ri и, следовательно, ai = f(ri) к желаемым. При этом H стремится к минимально возможным
значениям. То, что наилучшее приближение для ri существует следует, из
теоремы, приведенной в работе [[7]].
Для упрощения доказательства теоремы заменим ri -Ai на U.
Для U Î R
добиться наилучшего приближения можно линейной комбинацией ![]() линейно независимых элементов
линейно независимых элементов
![]() . То есть можно найти такой элемент
. То есть можно найти такой элемент ![]() , что
, что
![]() .
.
Теорема: Элемент наилучшего приближения существует.
Доказательство: Исследуем соотношение (неравенство треугольника)
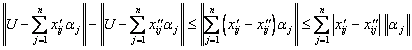 .
.
Из него следует, что функция
![]()
является непрерывной
функцией аргументов ![]() при " UÎR. Пусть
при " UÎR. Пусть ![]() -евклидова норма вектора
-евклидова норма вектора ![]() . Функция
. Функция ![]() непрерывна на
единичной сфере
непрерывна на
единичной сфере ![]() и, следовательно, в
некоторой точке
и, следовательно, в
некоторой точке ![]() достигает своей нижней
грани
достигает своей нижней
грани ![]() по сфере, причем
по сфере, причем ![]() , так как равенство
, так как равенство ![]() противоречит линейной
независимости элементов
противоречит линейной
независимости элементов ![]() . Для любого
. Для любого ![]() справедлива оценка
справедлива оценка
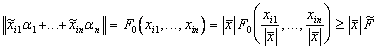 .
.
Пусть ![]() . Функция
. Функция ![]() непрерывна в шаре
непрерывна в шаре ![]() ; следовательно в некоторой точке шара
; следовательно в некоторой точке шара ![]() она достигает своей
нижней грани
она достигает своей
нижней грани ![]() по шару. Имеем
по шару. Имеем ![]() . Вне этого шара выполняется соотношение
. Вне этого шара выполняется соотношение
![]() .
.
Таким образом
![]()
при всех возможных ![]() , что и требовалось
доказать.
, что и требовалось
доказать.
Отметим, что элементов
наилучшего приближения может быть множество.
Адаптивная
процедура
Для выполнения процедуры
случайного поиска может быть использовано множество алгоритмов.
Одним из простейших является
алгоритм с возвратом на неудачном шаге [[8]]. Он сводится к
построению последовательности {rik}
по правилу:
![]() ,
,
где g k - некоторая положительная величина; ![]() - какая-либо
реализация n - мерной случайной
величины
- какая-либо
реализация n - мерной случайной
величины ![]() с известным законом
распределения. Например, координаты xh случайного вектора
с известным законом
распределения. Например, координаты xh случайного вектора ![]() могут представлять
независимые случайные величины, равномерно распределенные на отрезке [-1,1].
могут представлять
независимые случайные величины, равномерно распределенные на отрезке [-1,1].
Пусть k-е приближение уже известно. Функция H(a(ri)) в уравнении (2) достигает
минимума на некотором множестве QÎ En, rikÎ Q (k³ 0).
Алгоритм действует следующим
образом. С помощью датчика случайных чисел получают некоторую реализацию
случайного вектора ![]() и в пространстве En определяют точку rik=rik+gx, g =const>0. Если rikÎ Q и H(a(rik))< H(a(rik)),
тогда rik+1=rik. Если rikÎ Q но H(a(rik))³ H(a(rik)),
или rikÏ Q, то сделанный шаг считается неудачным и полагается rik+1=rik.
и в пространстве En определяют точку rik=rik+gx, g =const>0. Если rikÎ Q и H(a(rik))< H(a(rik)),
тогда rik+1=rik. Если rikÎ Q но H(a(rik))³ H(a(rik)),
или rikÏ Q, то сделанный шаг считается неудачным и полагается rik+1=rik.
В ситуации, когда требуемая
точность достигнута - H£m, или rik=rik+1=rik+2...=rik+N, если N
достаточно велико, точка rik принимается в качестве искомой точки минимума.
Ускорение адаптивной процедуры
На этапе функционирования
описываемые нейросети совпадают по быстродействию с нейросетями, обученными по
детерминированным алгоритмам, но при обучении даже с учетом предложенных
усовершенствований[1], случайный поиск остается процессом достаточно
медленным. Для его ускорения в работе [2]
предложено использовать прогнозирование последующего направления поиска с
использованием предыдущего опыта адаптации. Набор численных методов, пригодных
для прогноза наилучшего изменения величин ri (а для алгоритма,
описанного в [1],
величин xij), достаточно широк.
Приведем один из подходов,
позволяющих осуществить подобную процедуру. Он представляет собой простую самонастраиваемую
модель, основанную на вычислении так называемой экспоненциальной средней [[9]].
Поиск с вычислением экспоненциальной средней. В процессе случайного
поиска возникает последовательность значений {ri},
которые удовлетворяют условию улучшения функции оценки. Это временной ряд rt, поведение которого прогнозируется (rt - значение ri в некоторый момент
времени). Пусть временной ряд, генерируемый некоторой моделью, можно
представить в виде можно представить в виде двух компонент
![]() ,
,
где величина et генерируется
случайным неавтокореллированным процессом с нулевым математическим ожиданием и
конечной дисперсией, а величина dt может быть сгенерирована
либо детерминированной функцией, либо случайным процессом, либо какой-нибудь их
комбинацией.
Вычисление и анализ
тенденции динамического ряда можно осуществить с помощью его экспоненциального
сглаживания. В его основе лежит расчет экспоненциальных средних.
Экспоненциальное сглаживание описывается рекуррентной формулой
![]() ,
,
где St - значение экспоненциальной средней в момент t; n -параметр сглаживания, n =const, 0<n <1; b=1-n. Или через значения временного ряда rt
![]() ,
,
где N - количество членов ряда; S0
- некоторая величина, характеризующая начальные условия для первого применения
формулы при t=1.
Так как b<1,
то при N®¥ bN®0, а
![]() .
.
Тогда
![]() .
.
Таким образом, величина St является взвешенной суммой
всех членов ряда.
Пусть ряд генерируется
моделью
![]() ,
,
где a1=const; et - случайное неавтокоррелированное отклонение, или
шум, со средним значением 0 и дисперсией s2.
Применим к нему процедуру
экспоненциального сглаживания. Тогда
![]() .
.
Найдем математическое
ожидание
![]()
и дисперсию
![]() .
.
Так как 0<n <1, D(St)< D(rt)=s2.
Таким образом,
экспоненциальная средняя St
имеет то же математическое ожидание, что и ряд r, но меньшую дисперсию. При
высоком значении n дисперсия экспоненциальной средней незначительно
отличается от дисперсии ряда r.
Чтобы использовать
экспоненциальную среднюю для краткосрочного прогнозирования используем ряд,
который генерируется моделью
![]() ,
,
где a1,t - варьируемый во времени средний уровень ряда; et - случайное
неавтокоррелированное отклонение с нулевым математическим ожиданием и
дисперсией s 2.
Прогнозная модель имеет вид
![]() ,
,
где ![]() - прогноз, сделанный в
момент t на t единиц времени (шагов) вперед;
- прогноз, сделанный в
момент t на t единиц времени (шагов) вперед;
![]() - оценка a1,t. Экспоненциальная
средняя St служит оценкой
для единственного параметра модели a1,t
- оценка a1,t. Экспоненциальная
средняя St служит оценкой
для единственного параметра модели a1,t
![]() .
.
Все свойства
экспоненциальной средней являются одновременно свойствами прогнозной модели.
Если St-1 - прогноз на 1 шаг вперед, то величина (rt - St-1)
является погрешностью этого прогноза, а новый прогноз St получается в репогрешностью этого прогноза, а новый
прогноз St получается в результате
корректировки предыдущего прогноза с учетом ошибки.
[1]. Ланкин Ю.П.
Самоадаптирующиеся нейронные сети./ Препринт ТО №3 Института биофизики СО РАН, Теоротдел.- Красноярск,
1997.- 21 с.
[2]. Ланкин Ю.П. Адаптивные
сети с самостоятельной адаптацией./ Препринт ТО №4 Института биофизики СО РАН,
Теоротдел.- Красноярск, 1998.- 17 с.
[3]. Горбань А.Н. Обобщенная
аппроксимационная теорема и вычислительные возможности нейронных сетей.// Сибирский
журнал вычислительной математики.- Новосибирск: РАН. Сиб. отделение, 1998.- 1, №1.-
С.11-24.
[4]. Rumelhart D.E., Hinton G.E. & Williams R.J.
Learning representations by back-propogating errors.// Nature.- 1986.- 323.- P.533-536.
[5]. Барцев С.И., Охонин В.А.
Адаптивные сети обработки информации./ Препринт №59Б Института биофизики СО АН СССР.- Красноярск, 1986.- 19
стр.
[6]. Widrow B., Hoff M.B. Adaptive Switching Circuits.// IRE WESCOW Conv. Record.-
1960.- Pt.- 4.- P.96-104.
[7]. Бахвалов Н.С., Жидков
Н.П., Кобельков Г.М. Численные методы.- М.: Наука. Гл. ред. физ. мат. лит,
1987.- 600 с.
[8]. Васильев Ф.П. Численные
методы решения экстремальных задач.- М.: Наука. Гл. ред. физ. мат. лит, 1988.-
552 с.
[9]. Лукашин Ю.П. Адаптивные
методы краткосрочного прогнозирования.- М.: Статистика, 1979.- 252 с.