

Optical Character Recognition System Using BP Algorithm
Author: Sang Sung Park, Won Gyo Jung, Young Geun Shin, Dong-Sik Jang
Source: http://paper.ijcsns.org/07_book/200812/20081218.pdf
1. Introduction
Recently, most government agencies and companies have kept proof data and documentations which are passed certain period of time and exchanged electronic forms by the regulation of an office management. The method that saving relevant documents by scanning or entering manually on computer was used for document's digitalization. So that the government agencies and companies are trying to reduce these inconvenience nowadays. They use OCR (OCR : Optical Character Recognition) technique which is that saving relevant documents to DB after extracting text by using OCR. However, there is inconvenience in general OCR. That is, text should be entered to DB after classifying segments one by one in realized whole document after doing character recognition through OCR. In this paper, in order to solve this problem, we constructed OCR system that saves abstracted characters to DB automatically after extracting only equivalent and necessary characters from a large amount of documents by using BP algorithm that is one of Artificial neural network.
This paper is consisted as following. Describing problems of an existing study and this study’s necessity in Paragraph 1. Introducing a related study about character recognition in Paragraph 2. Explaining a composition of proposed system in Paragraph 3. Describing the method to embody about proposed system in Paragraph 4. Explaining a sequence of constructed system in paragraph 5. And lastly, the paper is concluded with making reference to an effect of manufactured system and hereafter study direction in Paragraph 6.
2. Related study
2.1 The method for character recognition
The character recognition method is divided into roughly two branches including a deterministic method and a syntax method. A deterministic method is comparingan input pattern and a standard pattern by analyzing a literal pattern which is in document image. Then, recognizing their patterns by estimating the similarity of each other. On the other hands, a syntax method is following a given syntax rule which is introducing similarity with syntax of language and pattern structure, and then identify the structure of patterns according to a given syntax rule [2] [3].
In this paper, We used deterministic method that compares input pattern and standard pattern. The character recognition is able to classify into Template matching method, Statistical method, Structural analysis method and etc according to a classification process. The Template matching method is that finding the most similar form by comparing with Template pattern , and it classifies a literal pattern according to a arrangement form. This method which is mainly using the character of one fixed form used a lot in the beginning. however frequency of use is less in the present due to the problems. Statistical character recognition method is that recognizing character by extracting a characteristic vector in indicator target .In this method , find the characters of statistical probability distribution of characteristic vector through the learning step, and separate the space of characteristic vector with an each class by using it. This classification model was defined well mathematically and in this method pattern of express, it is a very important issue that how define well of input pattern’s character and how extract the character. The structure analytic character recognition method is extracting the base element of composed character such as stokes in a Chinese character and its correlation based on a literal composition principle .This method has gotten a fine theoretical array and simple method, but there is a shortcoming that it takes long realization time because the regulation of characteristic character is very various according to the fonts.
In order to recognize the character pattern, the study that using Neural Networks Model which is one of artificial intelligence system is getting into the spotlight. Neural networks model is modeling human's structure of brain, and it presupposed that displays good performance through connection of simple calculation element with neuron that is standard unit for composing a brain. Therefore, neural networks model is a suitable model in the problems that require lots of computational complexities and parallelism such as analysis voice, character, image and etc[7].
2. Artificial neural networks algorithm
Artificial Neural Network(ANN) used Back Propagation(BP) algorithm which is efficient learning of Multi-Layer Perceptron(MLP).[8].BP is consist of three layer forward structure that has hidden layer between input layer and output layer. Fig. 1 shows BP's structure. BP's learning method passes through a learning process that exchange early connection weight value to suitable value for data. The forward step presents input pattern of neural net and produce output by using a input function and activation function to an each node. All value can contain only binary value (0 or 1).
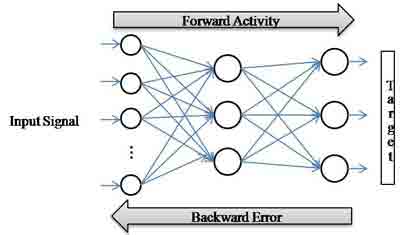
Fig. 1 The structure of BP algorithm
Activation function which is used in calculation of connection weight value used sigmoid function same as equation (1).
logstg(x) = 1/(1+exp^(-x)) (1)
Output value of hidden layer and output value of output layer which are according to activation function formula can express equation (2)and (3).
h = logstg(Sum(Wij*Xi)) (2)
y = logstg(Sum(Wik*Xj)) (3)
Backward is a step for renewal a connection weight value which is important element in learning process. In this step, measuring an error through the formula by calculating difference of desire value and output value . And then resetting a connection weight between layer and layer for making a minimize error value in order of input layer and output layer. Resetting the final connection weight value which has an minimize error value via forward and backward steps.
e = Sum((y-i)^2)/2 (4)
3. System composition
Component of optical character recognition system that proposed in this paper is divided at character learning part,document style setting part, image register part, character realization part and data saving part. System schematic diagram is same as Fig. 2.
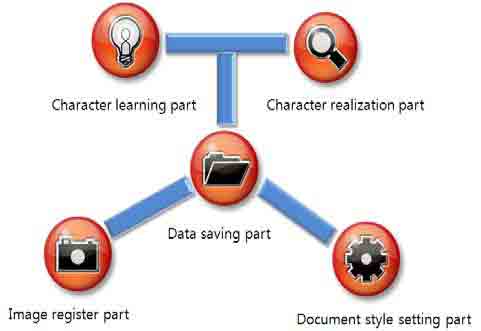
Fig. 2 System schematic diagram
3.1 Character learning part
Character learning part creates resetting connection weight that inputs character image and extracts information of pixel value about relevant image by using BP algorithm. Created connection weight becomes standard value for comparing and stored in data saving part during the recognition step. That is, it learns various fonts of character image and stores in data saving part in order to create literal standard value.
3.2 Document style setting part
Document style setting part sets recognition area that wish to achieve the character recognition and distinguish thedocument form. That is, it presets the document which has fixed form (ex) patent specification, financial products contract, etc) and necessary recognition area before doing character recognition.
3.3 Image register part
Image register part inputs document image to perform character recognition. Image register part involves thedevices such as a scanner that converts document to an imaging.
3.4 Character realization part
Character realization department recognizes the character which is compared with the standard value that comes outthe learning character step within a setting area for recognition, and the character should be corresponded to the document image that is matching a setting document style in the document style setting part. That is, when any document image was inputted through image register part, it realize the style of document image automatically. And if there is a conformable document style which is set in document style setting part, it realize the character.
3.5 Data saving part
Data saving part saves data that generated in document style setting part, image register part and characterrealization part. That is, it saves that document style data which occurs from document style setting part , any document image data which includes the character for recognition process in image register part and completely recognized character realization data and etc.
In these composition, inputted any document is applicable to the document style that is set in the realization part , thesystem is able to recognize only necessary segment so that mass document can be analyzed fast and enables character recognition.
4. System embodiment method
4.1 Character learning step
Fig. 3 is a flowchart that display character learning step which is preprocess phase of character recognition step.
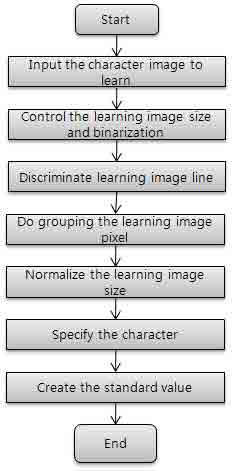
Fig. 3 Character learning step
In the character learning step, Input a character image to study for creating a literal standard value which is used at priority character recognition. Next, control whole size of inputted image and binarize whole pixel of image. The whole image size can be controlled, and it will adjust according to the specific size that is already preset. If the image is bigger than preset size, reduce an image size for reducing the data, and if not it doesn’t need any control. After controlling the size of image, divide and binarize the whole pixels as 0 for white and 1 for black.
0 means background and 1 means character and thereby divide character and background definitely . Next, in order recognize the character efficiently discriminate the line in the binarized image as Fig. 4.

Fig. 4 Discriminate line
Discriminate line means that connect pixels which are located in the lowest position among characters that realized as 1 and recognize by line (1 a) , so it doesn’t mean creating the line. At this time, measure the similarity of pixels which are located on adjacent 8 directions to lowest position pixel such as top-left, topmid, top-right, left, right, bottom-left, mid-left, bottomleft., and then it can find the last point at the any line’s end.
After discriminating the line, grouping the adjacent pixels which mean character and have 1 of pixel value by the line [9][10]. In this occasion, measure the similarity of pixels as well as a line discrimination step, and the grouping method through measurement of similarity is same Fig. 5.
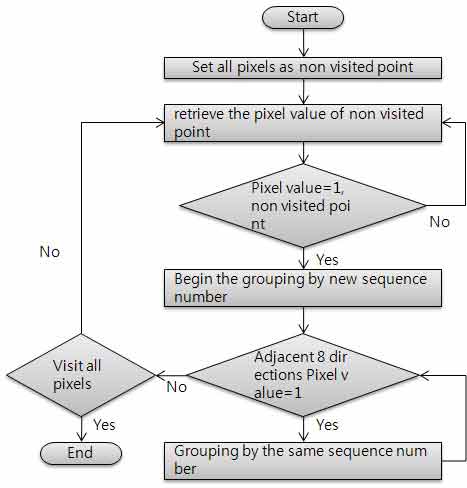
Fig. 5 Character grouping algorithm
Conclusion
In this paper, in order to recognize the character efficiently which is in mass document constructed the Optical Character Recognition System, and the section that needs for recognizing standardized document style and characters are predesignated. Optical Character Recognition System that is constructed by using artificial neural net work algorithm expects to be efficient in character recognition of mass standardized document. An experiment that measure accuracy and efficiency of developed system in paper has to be achieved by using various document more than hereafter.
