ВВЕДЕНИЕ В АРХИТЕКТУРУ КЛИЕНТ-СЕРВЕРНЫХ СИСТЕМ
Автор: Крамек Э.
Перевод с английского: Чернобай Ю. А.
Источник: Источник: http://weblogs.foxite.com/andykramek/archive/2008/09/29/6935.aspx
Развитие клиент-серверных систем
Архитектура компьютерной системы развилась наряду со способностями аппаратных средств использовать запускаемые приложения. Самой простой (и самой ранней) из всех была «Mainframe Architecture», в которой все операции и функционирование производятся в пределах серверного (или "host") компьютера. Пользователи взаимодействовали с сервером через «dumb» терминалы, которые передали инструкции, захватив нажатие клавиши, серверу и показали результаты выполнения инструкций для пользователя. Такие приложения носили типичный характер и, несмотря на относительно большую вычислительную мощность серверных компьютеров, были в основном относительно медленными неудобными в использовании, из-за необходимости передавать каждое нажатие клавиши серверу.
Введение и широкое распространение PC, с его собственной вычислительной мощностью и графическим пользовательским интерфейсом позволяли приложениям стать более сложными, и расширение сетевых систем привело к второму главному типу архитектуры системы, "Файловому разделению". В этой архитектуре PC (или "рабочая станция") загружает файлы от специализированного "файл сервера" и затем управляет приложением (включая данные) локально. Это работает хорошо, когда невелико использование общих данных, обновление данных, и объем данных, которые будут переданы. Однако скоро стало ясно, что разделение файла все больше засоряло сеть, и приложения становились более сложными и требовали, чтобы все большее количество данных было передано в обоих направлениях.
Проблемы, связанные с обработкой приложениями данных через файл, разделенный по сети, привели к развитию архитектуры клиент-сервер в начале 1980-ых. В этом подходе файл сервер заменен сервером баз данных, который, вместо того, чтобы просто передать и сохранить файлы подключенным рабочим станциям (клиентам), получает и фактически выполняет запросы о данных, возвращая только результат, запрашиваемый клиентом. Передавая только данные, запрашиваемые клиентом, а не весь файл, эта архитектура значительно уменьшает нагрузку на сеть. Это позволило создать систему, в которой множество пользователей могли обновлять данные через GUI интерфейсы, связанные с единственной разделенной базой данных.
Обычно для обмена данными между клиентом и сервером используется либо Structured Query Language (SQL) либо Remote Procedure Call (RPCs). Ниже описаны несколько основных вариантов организации архитектуры клиент-сервер.
Двухуровневая архитектура
В двухуровневой архитектуре нагрузка распределяется между сервером (в котором находится база данных) и клиентом (в котором находится пользовательский интерфейс). Как правило, они расположены на разных физических машинах, но это является не обязательным требованием. При условии, что уровни логически отделены, они могут быть размещены (например, для разработки и тестировании) на одном компьютере (рис. 1).
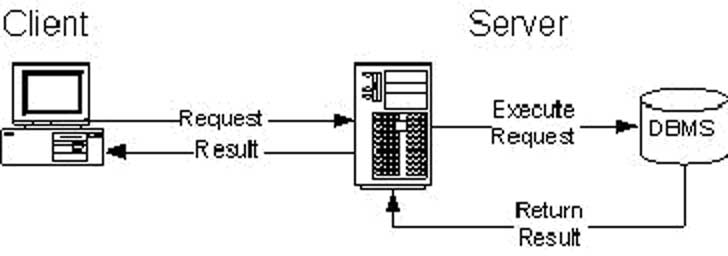
Рисунок 1: Двухуровневая архитектура
Распределение логики приложения и обработки данных в этой модели был и остается проблематичным. Если клиент «smart» и проводит основную обработку данных то появляются проблемы, связанные с распространением, установкой и обслуживании приложения, поскольку каждый клиент нуждается в собственной локальной копии программного обеспечения. Если клиент «dumb» применение логики и обработки должны быть реализованы в базе данных, а, следовательно, он становится полностью зависимым от конкретной используемой СУБД. В любом случае, каждый клиент должен пройти регистрацию и в зависимости от полученных им прав доступа выполнять определенные функции. Тем не менее, двухуровневая архитектура клиент-сервер была хорошим решением, когда количество пользователей было относительно небольшим (примерно до 100 одновременно работающих пользователей), но с ростом пользователей появился ряд ограничений на использование этой архитектуры.
• Производительность: Так как количество пользователей растет, производительность начинает ухудшаться. Ухудшение производительности прямопропорциональна количеству пользователей, каждый из которых имеет собственное подключение к серверу, что означает, что сервер должен поддерживать все эти соединения (с использованием "Keep-Alive" сообщения), даже когда работа с базой не ведется.
• Безопасность: Каждый пользователь должен иметь собственный индивидуальный доступ к базе данных, и обладать правами, предоставленными для эксплуатирования приложения. Для этого необходимо хранить права доступа для каждого пользователя в базе данных. Когда нужно добавить функциональности приложению и нужно обновить пользовательские права.
• Функциональность: Независимо от того, какой тип клиента используется, большая часть обработки данных должна находиться в базе данных, это означает, что она полностью зависит от возможностей предусмотренных в базе данных производителем. Это может серьезно ограничить функциональность приложения, поскольку различные базы данных поддерживают различные функции, используют различные языки программирования и даже реализуют такие основные средства, как триггеры по-разному.
• Мобильность: Двухуровневая архитектура настолько зависит от конкретной реализации базы данных, что перенос существующих приложений для различных СУБД, становится серьезной проблемой. Это особенно очевидно в случае приложений на вертикальных рынках, где выбор СУБД не определен поставщиком.
Но, несмотря на это, двухуровневая архитектура нашли новую жизнь в эпоху интернета. Она может хорошо работать в разъединенной окружающей среде, где UI является «dumb» (например браузер). Однако, во многих отношениях это реализация представляет собой возврат к первоначальной архитектуре мэйнфреймов.
Трехуровневая архитектура
В стремлении преодолеть ограничения двухуровневой архитектуры, описанных общих чертах выше, был введен дополнительный уровень. Такая архитектура является стандартной моделью клиент-сервер с трехуровневой архитектурой. Цель дополнительного уровня (обычно его называют «middle» или «rules» уровень) - управлять прикладным выполнением и управлением базой данных. Как и с двухуровневой моделью, уровни могут располагаться или на различных компьютерах (рисунок 2), или на одном компьютере в тестовом режиме.

Рисунок 2: Трехуровневая архитектура
Введя средний ряд, ограничения двухуровневой архитектуры в значительной степени были устранены, в результате получилась намного более гибкая, и масштабируемая, система. Так как теперь клиенты соединяются только с прикладным сервером, а не непосредственно к серверу данных, нагрузка на сохранение соединений удаляется, как и необходимость осуществить прикладную логику в пределах базы данных. База данных теперь может выполнять только функции хранения и поиска данных, а задачу приема и обработки заявок могут выполняет средний уровень трехуровневой архитектуры. Развитие операционных систем, включающее такие элементы, как пул соединений, очереди и обработки распределенных транзакций укрепил (и упростил) развитие среднего уровня.
Обратите внимание на это, в этой модели, прикладной сервер не управляет интерфейсом пользователя, и при этом пользователь фактически не обращается с запросами непосредственно к базе данных. Вместо этого это позволяет многочисленным клиентам разделять деловую логику, вычисления, и доступ к поисковой системе данных. Главное преимущество состоит в том, что клиент требует меньше программного обеспечения и ему больше не нужен прямое подключение к базе данных, что повышает безопасность. Следовательно приложение более масштабируемо, затраты на поддержку и установку на один сервер значительно меньшие, чем для поддержания приложений прямо на компьютере клиента или даже на двухуровневую архитектуру.
Есть много вариантов основных трехуровневых моделей, предназначенных для выполнения различных функций. К ним относятся обработка распределенных транзакций (когда несколько СУБД обновляются в одном протоколе), приложения, базирующиеся на сообщениях (где приложения не общаются в режиме реального времени) и кросс-платформенной совместимости (Object Request Broker или «ORB» приложения).
Многоуровневая архитектура или N-уровневая архитектура
С развитием интернет приложений на фоне общего повышения количества пользователей основная трехуровневая клиент-серверная модель была расширена путем введения дополнительных уровней. Такие архитектуры называют «"многоуровневые», обычно они состоят из четырех уровней (рисунок 3), где в сети сервер отвечает за обработку соединение между клиентом браузером и сервером приложений. Выгода заключается в том, что несколько веб-серверов могут подключаться к одному серверу приложений, тем самым, увеличивая обработку большего числа одновременно подключенных пользователей.
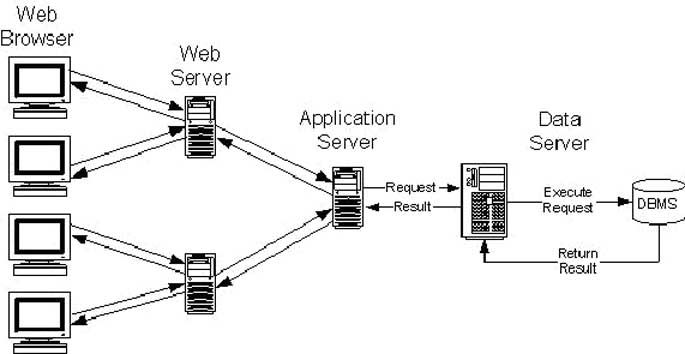
Рисунок 3: N-уровневая архитектура
Уровни против слоев
Эти термины (к сожалению) часто путают. Однако между ними большая разница и имеют определенный смысл. Основное отличие заключается в том, что уровни находятся физическом уровне, а слои на логическом. Иными словами уровень, теоретически, может быть развернут независимо на отдельном компьютере, а слой логическое разделение внутри уровня (рисунок. 4). Типичная трехуровневая модель, описанная выше, как правило, содержит, по меньшей мере семь слоев, разделенных на всех трех уровнях.
Главное, что нужно помнить о многоуровневой архитектуре является то, что запросы и ответы каждого потока в одном направлении проходят по всем слоям, и что слои никогда не может быть пропущены. Таким образом, в модели, показанной на рисунке 4, единственный слой, который может обратиться к слою "E" (слой доступа к данным) является слой "D" (слой правил). Аналогичным образом слой "C" (прикладной слой ратификации) может только отвечать на запросы из слоя "B" (слоя обработка ошибок).

Рисунок 4: Ряды разделены на логические слои