
Figure 1. Fragment handling to set accessibility and definedness
In this paper we describe the implementation of memory checking functionality based on instrumentation using valgrind. The combination of valgrind based checking functions within the MPI-implementation offers superior debugging functionality, for errors that otherwise are not possible to detect with comparable MPI-debugging tools. The functionality is integrated into Open MPI as the so-called memchecker-framework. This allows other memory debuggers that offer a similar API to be integrated. The tight control of the user’s memory passed to Open MPI, allows not only to find application errors, but also helps track bugs within Open MPI itself.
We describe the actual checks, classes of errors being found, how memory buffers internally are being handled, show errors actually found in user’s code and the performance implications of this instrumentation.
Parallel programming with the distributed memory paradigm using the Message Passing Interface MPI1 is often considered as an error-prone process. Great effort has been put into parallelizing libraries and applications using MPI. However when it comes to maintaining the software, optimizing for new hardware or even porting the code to other platforms and other MPI implementations, the developers face additional difficulties2. They may experience errors due to implementation-defined behavior, hard-to-track timing-critical bugs or deadlocks due to communication characteristics of the MPI-implementation or even hardware dependent behavior. One class of bugs, that are hard-to-track are memory errors, specifically in non-blocking communication.
This paper introduces a debugging feature based on instrumentation functionality offered by valgrind3, that is being employed within the Open MPI-library. The user’s parameters, as well as other non-conforming MPI-usage and hard-to-track errors, such as accessing buffers of active non-blocking operations are being checked and reported. This kind of functionality would otherwise not be possible within traditional MPI-debuggers based on the PMPI-interface.
This paper is structured as follows: Section 2 gives an introduction into the design and implementation, sec. 3 shows the performance implications, sec. 4 shows the errors, that are being detected. Finally, sec. 5 gives a comparison of other available tools and concludes the paper with an outlook.
The tool suite valgrind3 may be employed on static and dynamic binary executables on x86/x86 64/amd64- and PowerPC32/64-compatible architectures. It operates by intercepting the execution of the application on the binary level and interprets and instruments the instructions. Using this instrumentation, the tools within the valgrind-suite then may deduce information, e. g. on the allocation of memory being accessed or the definedness of the content being read from memory. Thereby, the memcheck-tool may detect errors such as buffer-overruns, faulty stack-access or allocation-errors such as dangling pointers or double frees by tracking calls to malloc, new or free. Briefly, the tool valgrind shadows each byte in memory: information is kept whether the byte has been allocated (so-called A-Bits) and for each bit of each byte, whether it contains a defined value (so-called V-Bits).
As has been described on the web-page4 for MPIch since version 1.1, valgrind can be used to check MPI-parallel applications. For MPIch-15 valgrind has to be declared as debugger, while for Open MPI, one only prepends the application with valgrind and any valgrind-parameters, e. g. mpirun -np 8 valgrind --num callers=20 ./my app inputfile.
As described, this may detect memory access bugs, such as buffer overruns and more, but also by knowledge of the semantics of calls like strncpy. However, valgrind does not have any knowledge of the semantics of MPI-calls. Also, due to the way, how valgrind is working, errors due to undefined data may be reported late, way down in the call stack. The original source of error in the application therefore may not be obvious. In order to find MPI-related hard-to-track bugs in the application (and within Open MPI for that matter), we have taken advantage of an instrumentation-API offered by memcheck. To allow other kinds of memory-debuggers, such as bcheck or Totalview’s memory debugging features6, we have implemented the functionality as a module into Open MPI’s Modular Component Architecture7. The module is therefore called memchecker and may be enabled with the configure-option --enable-memchecker.
The instrumentation for the valgrind-parser uses processor instructions that do not
otherwise change the semantics of the application. By this special instruction preamble,
valgrind detects commands to steer the instrumentation. On the x86-architecture, the
right-rotation instruction ror is used to rotate the 32-bit register edi, by 3, 13, 29 and
19, aka 64-Bits, leaving the same value in edi; the actual command to be executed is then
encoded with an register-exchange instruction (xchgl) that replaces a register with itself
(in this case ebx):
#define __SPECIAL_INSTRUCTION_PREAMBLE \
"roll $3, %%edi ; roll $13, %%edi\n\t" \
"roll $29, %%edi ; roll $19, %%edi\n\t" \
"xchgl %%ebx, %%ebx\n\t"
In Open MPI objects such as communicators, types and requests are declared as pointers to structures. These objects when passed to MPI-calls are being immediately checked for definedness and together with MPI Status are checked upon exita. Memory being passed to Send-operations is being checked for accessibility and definedness, while pointers in Recv-operations are checked for accessibility, only.
Reading or writing to buffers of active, non-blocking Recv-operations and writing to buffers of active, non-blocking Send-operations are obvious bugs. Buffers being passed to non-blocking operations (after the above checking) is being set to undefined within the MPI-layer of Open MPI until the corresponding completion operation is issued. This setting of the visibility is being set independent of non-blocking MPI Isend or MPI Irecv function. When the application touches the corresponding part in memory before the completion with MPI Wait, MPI Test or multiple completion calls, an error message will be issued. In order to allow the lower-level MPI-functionality to send the user-buffer as fragment, the so-called lower layer Byte Transfer Layer (BTLs) are adapted to set the fragment in question to accessible and defined, as may be seen in Fig. 1. Care has been taken to handle derived datatypes and it’s implications.
Figure 1. Fragment handling to set accessibility and definedness
For Send-operations, the MPI-1 standard also defines, that the application may not access the send-buffer at all (see1, p. 30). Many applications do not obey this strict policy, domain-decomposition based applications that communicate ghost-cells, still read from the send-buffer. To the authors’ knowledge, no existing implementation requires this policy, therefore the setting to undefined on the Send-side is only done with strict-checking enabled (see Undefined* in Fig. 1).
Adding instrumentation to the code does induce a slight performance hit due to the assembler instructions as explained above, even when the application is not run under valgrind. Tests have been done using the Intel MPI Benchmark (IMB), formerly known as Pallas MPI Benchmark (PMB) and the BT-Benchmark of the NAS parallel benchmark suite (NPB) all on the dgrid-cluster at HLRS. This machine consists of dual-processor Intel Woodcrest, using Infiniband-DDR network with the OpenFabrics stack.
For IMB, two nodes were used to test the following cases: with&without --enable-memchecker compilation and with --enable-memchecker but without MPI-object checking (see Fig. 2) and with&without valgrind was run (see Fig. 3). We include the performance results on two nodes using the PingPong test. In Fig. 2 the measured latencies (left) and bandwidth (right) using Infiniband (not running with valgrind) shows the costs incurred by the additional instrumentation, ranging from 18 to 25% when the MPI-object checking is enabled as well, and 3-6% when memchecker is enabled, but no MPI-object checking is performed. As one may note, while latency is sensitive to the instrumentation added, for larger packet-sizes, it is hardly noticeable anymore (less than 1% overhead). Figure 3 shows the cost when additionally running with valgrind, again without further instrumentation compared with our additional instrumentation applied, here using TCP connections employing the IPoverIB-interface.

Figure 2. Latencies and bandwidth with&without memchecker-instrumentation over Infiniband, running without
valgrind.
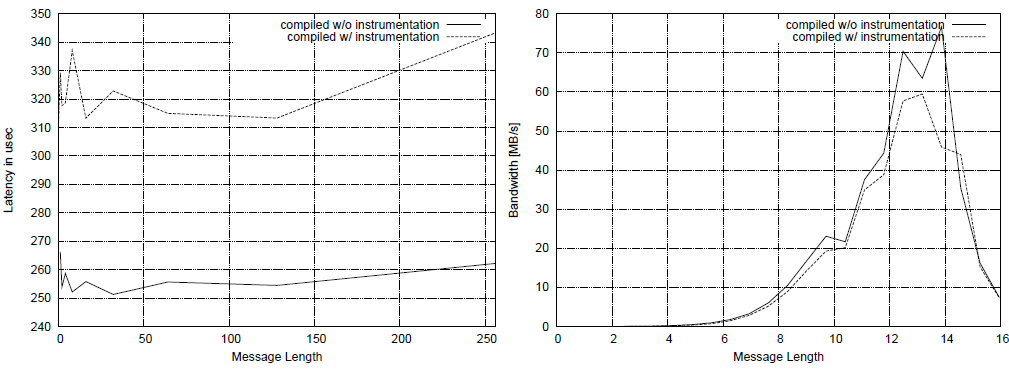
Figure 3. Latencies and bandwidth with&without memchecker-instrumentation using IPoverIB, running with
valgrind.
The large slowdown of the MPI-object checking is due to the tests of every argument and its components, i. e. the internal data structures of an MPI Comm consist of checking the definedness of 58 components, checking an MPI Request involves 24 components, while checking MPI Datatype depends on the number of the base types. The BT-Benchmark has several classes, which have different complexity, and data size. The algorithm of BT-Benchmark solves three sets of uncoupled systems of equations, first in the x, then in the y, and finally in the z direction. The tests are done with sizes Class A and Class B. Figure 4 shows the time in seconds for the BT Benchmark. The Class A (size of 64x64x64) and Class B (size of 102x102x102) test was run with the standard parameters (200 iterations, time-step dt of 0.0008).
Again, we tested Open MPI in the following three cases: Open MPI without memchecker component, running under valgrind with the memchecker component disabled and finally with --enable-memchecker.
As may be seen and is expected this benchmark does not show any performance implications whether the instrumentation is added or not. Of course due to the large memory requirements, the execution shows the expected slow-down when running under valgrind, as every memory access is being checked.
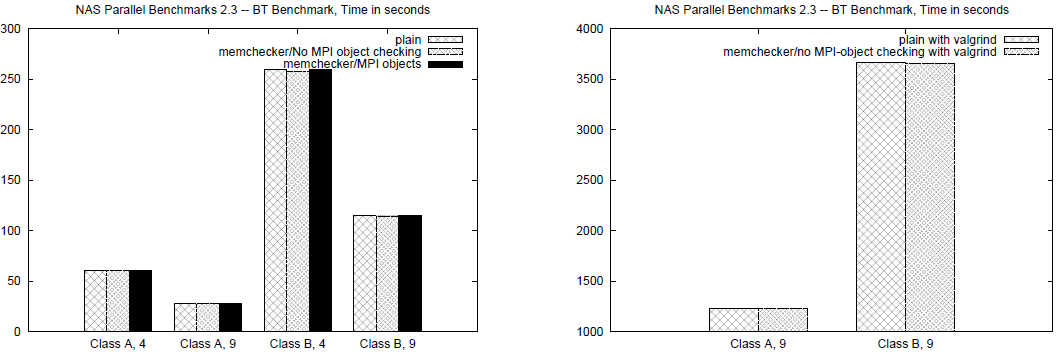
Figure 4. Time of the NPB/BT benchmark for different classes running without (left) and with (right)
valgrind.
The kind of errors, detectable with a memory debugging tool such as valgrind in conjunction with instrumentation of the MPI-implementation are:
During the course of development, several software packages have been tested with the memchecker functionality. Among them problems showed up in Open MPI itself (failed in initialization of fields of the status copied to user-space), an MPI testsuite8, where tests for the MPI ERROR triggered an error. In order to reduce the number of false positives Infiniband-networks, the ibverbs-library of the OFED-stack9 was extended with instrumentation for buffer passed back from kernel-space.
We have presented an implementation of memory debugging features into Open MPI, using the instrumentation of the valgrind-suite. This allows detection of hard-to-find bugs in MPI-parallel applications, libraries and Open MPI itself2. This is new work, up to now, no other debugger is able to find these kind of errors.
With regard to related work, debuggers such as Umpire10, Marmot11 or the Intel Trace Analyzer and Collector2, actually any other debugger based on the Profiling Interface of MPI, may detect bugs regarding non-standard access to buffers used in active, non-blocking communication without hiding false positives of the MPI-library itself.
In the future, we would like to extend the checking for other MPI-objects, extend for MPI-2 features, such as one-sided communication, non-blocking Parallel-IO access and possibly other error-classes.