Трассировка в реальном времени с применением NVIDIA CUDA GPGPU и Intel Quad-Core
Eric Rollins
Перевод с английского: Иванова Е.В.
Источник:http://eric_rollins.home.mindspring.com/ray/cuda.html

Введение
Эта статья является продолжением предыдущей работы, Real-Time Ray Tracing on the Playstation 3 Cell Processor.
Применяю тот же тест для анализа трассировки лучей. Код был изменен, чтобы использовать NVIDIA GPU, и многоядерные POSIX потоки.
NVIDIA CUDA GPGPU
В четырехмерной-сетке для ускорения GPGPU я уже экспериментировал с GPGPU (Graphics Processing Units).
Такое программирование было трудно, поскольку речь идет по сути про «обман» OpenGL шейдеров для выполнения
каких-либо неграфических вычислений. Все программирование было сделано посредством графики OpenGL на платформе API.
CUDA NVIDIA предоставила неграфических API для выполнения программирования общего назначения на графических процессорах 8 серии.
Она поддерживается в Windows XP и Linux; драйверов и SDK можно просмотреть тут.
Хотя мой пример графический, будет использоваться из свего GPU только буфер кадра SDL.
Все получаемые объекты создаются моим CUDA-кодом, исполнимом на GPU — видеокарта не знает, что это графические вычисления.
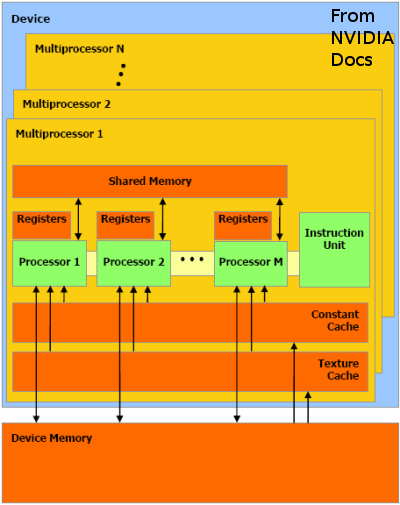
NVIDIA GPU имеет несколько многопроцессоров: 12 на GeForce 8800 GTS (я тестировал). Каждый мультипроцессор
имеет 8 процессоров, каждый из которых может поддерживать одновременно до 768 потоков.
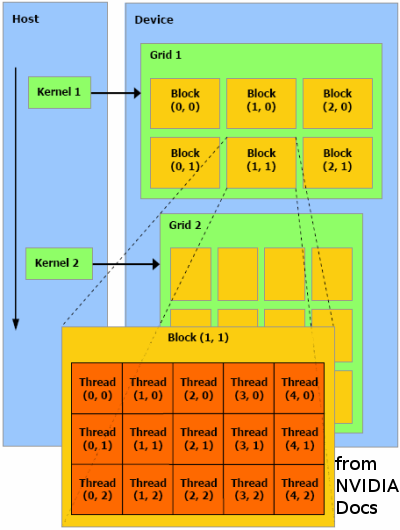
В CUDA программист пишет ядро, являющееся кодом исполнимым в одном потоке.
Потоки сгруппированы в 2 или 3-мерном пространства, называемые блоками, и блоки, в свою очередь находятся в
2-мерной группе называемой сеткой. Во время выполнения система объединяет блоки и сетки для применения их
в качестве ресурсов. Общий смысл вычислительной модели SIMD: одна инструкция ядра выполняется на всех потоках.
"C компилятор" NVIDIA поддерживает стандартную работу C с циклами, ветвлениями, и т.п., но не рекурсии.
Как SPUs на PS3 процессора Cell, память GPU ограничена и доступ к host-памяти происходит медленно.
Данные явно перемещаются от хоста(host) к устройству(device) через программу хоста.
В данном случае данные находятся в устройстве глобальной памяти (global memory — общая для всех мультипроцессоров), которая по-прежнему довольно медленная.
Потоки ядра могут скопировать данные из глобальной памяти в общую память (shared memory — общую для процессоров,
расположенных в одном мультипроцессоре), к тому же объем общей памяти ограничен 16K на мультипроцессор.
Моя программа на CUDA
Ранее мы код для трассировки лучей был разбили на хост и потоки ядра устройства.
Каждое устройство связано и выполняет инструкции только своих потоков. Потоки разбиты на блоки 16x16,
каждый из которых в свою очередь образуют сетку 64x35. Каждый поток обрабатывает один пиксель 1024x564 дисплея.
В начале каждого кадра, текущее состояние устройства копируется хоятом в глобальную память устройства.
0,0 поток в каждом блоке, в свою очередь копирует эту структуру в общую память, чтобы обеспечить более
быстрый доступ всех потоков в свои блоки. Обратите внимание! общая память доступна потоку только для
чтения «точки зрения» — они никогда не обновляют ее. После окончания чтения потоками программ устройства,
главная программа записывает вычисленный результат (цвет одного пикселей) в глобальный массив другого устройства.
Когда все потоки завершили чтения состояния хоста из глобального массива устройства , происходит запись
вычисленного состояния его в буфер кадра SDL.
В данной конструкции CUDA не является практическим способом реализации алгоритма трассировки лучей.
16K разделяемой памяти делает нецелесообразным создавать реалистичные модели мира.
Создается впечатление, что количество потоков, которые могут быть запущены одновременно ограничивается
размером глобальной структуры:
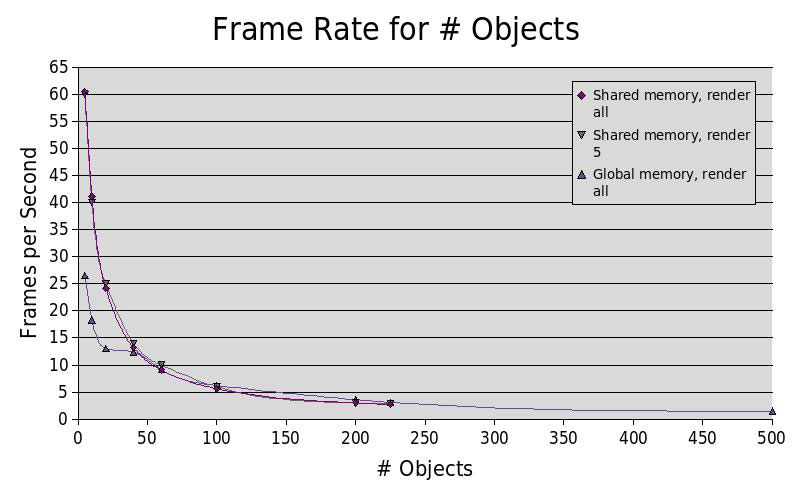
Здесь мы видим, что при небольшом количестве объектов в мире программа работает быстрее, с общей памятью.
При большом количестве объектов в мире это гораздо быстрее, без разделяемой памяти (в разделяемой памяти не
может поместиться более 225 объектов). Ускорение получаемое от общей памяти не зависит от того, все ли объекты
фактически показаны. Узким местом программы является не только массив объектов, но и в скорость доступа
к данным объекту и количество потоков, которые могут быть одновременно запущены.
Pthreads на Intel Quad-Core
Первоначальный код для трассировки-лучей был модифицирован для использования Pthreads.
В начале каждого кадра создаются 4 потока и получают первоначальное значение строки кадра.
Как PS3 трассировщик лучей сетки, первый поток будет отображать 1,5,9 и т.д. строки, а второй поток отобразит
2, 6, 10 и др. Основные программа соединяет все данные из потоков в единое изображение.
Программа линейно не масштабируется с увеличением числа процессоров, получается, что он может быть узкое место
при записи результатов в основную память. Программа может работать быстрее, если запись производить пакетным способом, как в версии PS3.
Результаты
Новый код доступен здесь
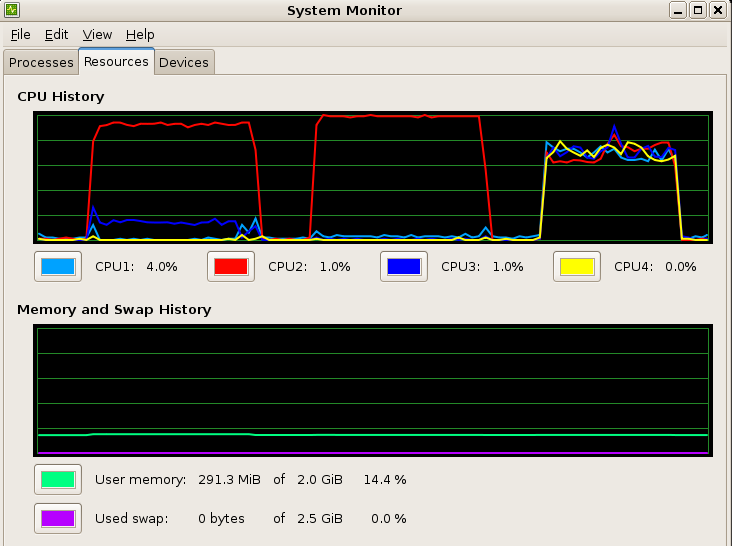
 Ниже показан процессор и использование памяти при испытании NVIDIA CUDA GPGPU, для 1 Pthreads потока,
и 4 Pthreads. В тесте для CUDA моя программа трассировки лучей используется 92% возможностей центрального процессора и
X-сервер Xorg использовал 12% другого процессора.
Ниже показан процессор и использование памяти при испытании NVIDIA CUDA GPGPU, для 1 Pthreads потока,
и 4 Pthreads. В тесте для CUDA моя программа трассировки лучей используется 92% возможностей центрального процессора и
X-сервер Xorg использовал 12% другого процессора.
Обновление (7 / 2007)
Я получил оценку для Intel C + + Compiler 10.0, Professional Edition под Linux . Мне было интересно попробовать
свою SSE-векторизацию кода автомобиля. С 4 потоками было на 21% быстрее, чем GCC.
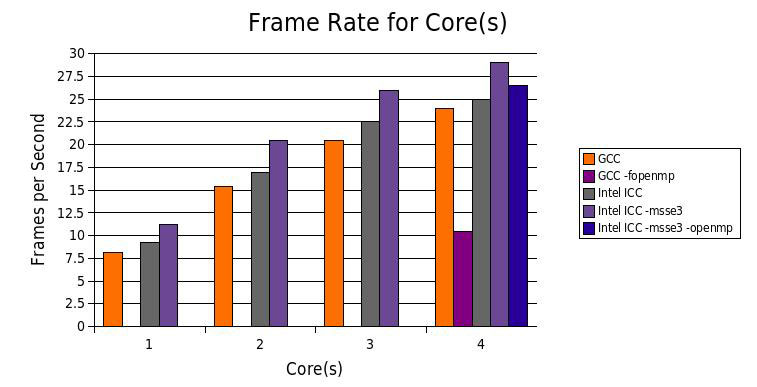
Обновление (12/2007)
Intel C + + поддерживает OpenMP , стандартный API для совместного использования в многопроцессорных C++.
Добавив простой #pragma циклы могут быть разделины на автоматический запуск параллельно на нескольких ядрах.
Я добавил простое изменение на экране для генерации цикличного луча трассировки:
int screenX;
#ifdef USE_OMP
#pragma omp parallel for firstprivate(portPoint)
#endif
for (screenX = 0; screenX < SCREEN_WIDTH; screenX++)
{ ... }
В результате этого изменения каждый пиксель обрабатывает отдельный поток,
с максимальным числом одновременно работающих ядер = 4. Такое использовани потоков является альтернативой
применения Pthreads обработки, испытанной выше, где в отдельном потоке, используется строка на экране.
В этом случае OpenMP проще, чем явных потоков, хотя и дает несколько меньшую производительность.
GCC 4.2 поддерживает OpenMP, но ее эффективность намного хуже, чем Intel.
Обновление (1/2009)
Я перенес классическую трассировку лучей и трассировку лучей на CUDA на Mac OS X работающей
на ноутбуке MacBook Pro. Он имеет 2,4 ГГц Intel Core 2 Duo процессор и NVIDIA GeForce 9600M GT графический
процессор. Производительность для 1 и 2 программных потоков можно сравнить с более ранними исследованиями
под Linux, и CUDA находится на третьем месте среди написанных видеокарт.
потоков кадров в секунду
1 8.5
2 17.4
GPU 16.7
© Магистр ДонНТУ Иванова Екатерина Владимировна, 2010
Eric Rollins
Перевод с английского: Иванова Е.В.
Источник:http://eric_rollins.home.mindspring.com/ray/cuda.html
Введение
Эта статья является продолжением предыдущей работы, Real-Time Ray Tracing on the Playstation 3 Cell Processor. Применяю тот же тест для анализа трассировки лучей. Код был изменен, чтобы использовать NVIDIA GPU, и многоядерные POSIX потоки.
NVIDIA CUDA GPGPU
В четырехмерной-сетке для ускорения GPGPU я уже экспериментировал с GPGPU (Graphics Processing Units). Такое программирование было трудно, поскольку речь идет по сути про «обман» OpenGL шейдеров для выполнения каких-либо неграфических вычислений. Все программирование было сделано посредством графики OpenGL на платформе API. CUDA NVIDIA предоставила неграфических API для выполнения программирования общего назначения на графических процессорах 8 серии. Она поддерживается в Windows XP и Linux; драйверов и SDK можно просмотреть тут.
Хотя мой пример графический, будет использоваться из свего GPU только буфер кадра SDL. Все получаемые объекты создаются моим CUDA-кодом, исполнимом на GPU — видеокарта не знает, что это графические вычисления.
NVIDIA GPU имеет несколько многопроцессоров: 12 на GeForce 8800 GTS (я тестировал). Каждый мультипроцессор имеет 8 процессоров, каждый из которых может поддерживать одновременно до 768 потоков.
В CUDA программист пишет ядро, являющееся кодом исполнимым в одном потоке. Потоки сгруппированы в 2 или 3-мерном пространства, называемые блоками, и блоки, в свою очередь находятся в 2-мерной группе называемой сеткой. Во время выполнения система объединяет блоки и сетки для применения их в качестве ресурсов. Общий смысл вычислительной модели SIMD: одна инструкция ядра выполняется на всех потоках. "C компилятор" NVIDIA поддерживает стандартную работу C с циклами, ветвлениями, и т.п., но не рекурсии.
Как SPUs на PS3 процессора Cell, память GPU ограничена и доступ к host-памяти происходит медленно. Данные явно перемещаются от хоста(host) к устройству(device) через программу хоста. В данном случае данные находятся в устройстве глобальной памяти (global memory — общая для всех мультипроцессоров), которая по-прежнему довольно медленная. Потоки ядра могут скопировать данные из глобальной памяти в общую память (shared memory — общую для процессоров, расположенных в одном мультипроцессоре), к тому же объем общей памяти ограничен 16K на мультипроцессор.
Моя программа на CUDA
Ранее мы код для трассировки лучей был разбили на хост и потоки ядра устройства. Каждое устройство связано и выполняет инструкции только своих потоков. Потоки разбиты на блоки 16x16, каждый из которых в свою очередь образуют сетку 64x35. Каждый поток обрабатывает один пиксель 1024x564 дисплея. В начале каждого кадра, текущее состояние устройства копируется хоятом в глобальную память устройства. 0,0 поток в каждом блоке, в свою очередь копирует эту структуру в общую память, чтобы обеспечить более быстрый доступ всех потоков в свои блоки. Обратите внимание! общая память доступна потоку только для чтения «точки зрения» — они никогда не обновляют ее. После окончания чтения потоками программ устройства, главная программа записывает вычисленный результат (цвет одного пикселей) в глобальный массив другого устройства. Когда все потоки завершили чтения состояния хоста из глобального массива устройства , происходит запись вычисленного состояния его в буфер кадра SDL.
В данной конструкции CUDA не является практическим способом реализации алгоритма трассировки лучей. 16K разделяемой памяти делает нецелесообразным создавать реалистичные модели мира. Создается впечатление, что количество потоков, которые могут быть запущены одновременно ограничивается размером глобальной структуры:
Здесь мы видим, что при небольшом количестве объектов в мире программа работает быстрее, с общей памятью. При большом количестве объектов в мире это гораздо быстрее, без разделяемой памяти (в разделяемой памяти не может поместиться более 225 объектов). Ускорение получаемое от общей памяти не зависит от того, все ли объекты фактически показаны. Узким местом программы является не только массив объектов, но и в скорость доступа к данным объекту и количество потоков, которые могут быть одновременно запущены.
Pthreads на Intel Quad-Core
Первоначальный код для трассировки-лучей был модифицирован для использования Pthreads. В начале каждого кадра создаются 4 потока и получают первоначальное значение строки кадра. Как PS3 трассировщик лучей сетки, первый поток будет отображать 1,5,9 и т.д. строки, а второй поток отобразит 2, 6, 10 и др. Основные программа соединяет все данные из потоков в единое изображение. Программа линейно не масштабируется с увеличением числа процессоров, получается, что он может быть узкое место при записи результатов в основную память. Программа может работать быстрее, если запись производить пакетным способом, как в версии PS3.
Результаты
Новый код доступен здесь
Ниже показан процессор и использование памяти при испытании NVIDIA CUDA GPGPU, для 1 Pthreads потока,
и 4 Pthreads. В тесте для CUDA моя программа трассировки лучей используется 92% возможностей центрального процессора и
X-сервер Xorg использовал 12% другого процессора.
Обновление (7 / 2007)
Я получил оценку для Intel C + + Compiler 10.0, Professional Edition под Linux . Мне было интересно попробовать свою SSE-векторизацию кода автомобиля. С 4 потоками было на 21% быстрее, чем GCC.
Обновление (12/2007)
Intel C + + поддерживает OpenMP , стандартный API для совместного использования в многопроцессорных C++.
Добавив простой #pragma циклы могут быть разделины на автоматический запуск параллельно на нескольких ядрах.
Я добавил простое изменение на экране для генерации цикличного луча трассировки:
int screenX;
#ifdef USE_OMP
#pragma omp parallel for firstprivate(portPoint)
#endif
for (screenX = 0; screenX < SCREEN_WIDTH; screenX++)
{ ... }
В результате этого изменения каждый пиксель обрабатывает отдельный поток, с максимальным числом одновременно работающих ядер = 4. Такое использовани потоков является альтернативой применения Pthreads обработки, испытанной выше, где в отдельном потоке, используется строка на экране. В этом случае OpenMP проще, чем явных потоков, хотя и дает несколько меньшую производительность.
GCC 4.2 поддерживает OpenMP, но ее эффективность намного хуже, чем Intel.
Обновление (1/2009)
Я перенес классическую трассировку лучей и трассировку лучей на CUDA на Mac OS X работающей на ноутбуке MacBook Pro. Он имеет 2,4 ГГц Intel Core 2 Duo процессор и NVIDIA GeForce 9600M GT графический процессор. Производительность для 1 и 2 программных потоков можно сравнить с более ранними исследованиями под Linux, и CUDA находится на третьем месте среди написанных видеокарт.
| потоков | кадров в секунду |
| 1 | 8.5 |
| 2 | 17.4 |
| GPU | 16.7 |