Интеллектуализация пользовательских интерфейсов информационных систем
Попов Ф.А., Ануфриева Н.Ю.
Алтайский государственный технический университета
Попов Ф.А., Ануфриева Н.Ю. Интеллектуализация пользовательских интерфейсов информационных систем // Вестник Томского государственного университета. - 2007.- №300(1).- с.130-133.
Исследования в области создания и развития средств поддержки диалога в автоматизированных системах различного назначения, таких как САПР, АСУП, АСНИ и др., выполнялись с 1970-х гг. А.П. Ершовым, А.М. Довгялло, В.И. Дракиным, Э.В. Поповым, О.Ф. Цуриным, Р. Коутсом, О.Л. Перевозчиковой [1–6], а также авторами в процессе создания различных диалоговых систем [7–19]. Рассмотрим коротко структуру пользовательского интерфейса, явившуюся одним из основных результатов отмеченных выше исследований. Взаимодействие пользователя с информационной системой (ИС) в его интерфейсе описывается средствами сценария, в котором фиксируется форма диалога, регламентирующая последовательность транзакций, и вид обмена сообщениями между компьютером и пользователем. В зависимости от используемых средств сценарий может быть представлен в виде графа переходов конечного автомата либо в виде совокупности фреймов [6, 20]. Совокупность сценариев диалога (как статических, так и динамических) хранится в соответствующих библиотеках и представляет собой модель общения, реализуемую пользовательским интерфейсом информационной системы.
По сценарию и текущему состоянию диалога диалоговый монитор формирует или определяет форму общения, а также тип задания, выполняемого системой на текущем шаге (типы заданий — генерация вопроса, понимание ответа, генерация ответа и т.п.). Важное место в структуре диалогового монитора занимает предложенный автором в работе [7] механизм динамического задания таблиц эквивалентностей подпрограмм (процедур), обеспечивающий использование в процессе диалога без изменения его сценария различных по со- держанию и результатам выполнения, но эквивалентных по типу выполняемых действий процедур.
Одна из главных особенностей современных ИС — это общение с пользователями на языках, близких к естественному, являющихся его подмножествами. При этом естественность данных языков состоит, в первую очередь, в том, чтобы они позволяли вести взаимодействие с компьютером при минимальной подготовке пользователя, без необходимости предварительного обращения к инструкциям и запоминания различных правил построения высказываний [21].
Одно из основных звеньев интеллектуальных интерфейсов — лингвистические процессоры, переводящие естественно-языковые высказывания пользователей на язык внутреннего представления, вид которого определяется прикладными программами, выполняющими дальнейшую обработку данных (входные языки информационно-поисковых систем, языки манипулирования данными СУБД, языки программирования). При этом в процессе перевода выполняется выделение описаний сущностей, упомянутых в высказывании,выявление свойств и отношений этих сущностей, а также отображение текущего высказывания на знания системы о проблемной области, хранящиеся в составе комплекса словарей.
Последний компонент интерфейса — библиотека процедур, используемых диалоговым монитором для выполнения действий, соответствующих функционалным операторам языка описания диалогов, таким как выполнение различных операций, формирование таблиц при табличной форме общения и т.п.
Знания интерфейса о диалоге, языке и проблемной области разделяют на проблемно-независимые и проблемно-ориентированные, причем первые представляются в основном процедурно, вторые — декларативно. При этом механизм интерпретации декларативных знаний не зависит от их конкретного содержания, что позволяет выполнять настройку систем общения на проблемную область, рассматривая ее как процесс ввода или корректировки декларативно представленных проблемно-ориентированных знаний. Рассмотренные компоненты пользовательских интерфейсов постоянно уточняются и совершенствуются в различных аспектах, в первую очередь – в направлении создания средств, позволяющих пользователю эффективно взаимодействовать с ИС на стадиях их разработки, использования и развития. При этом весь комплекс возможностей, предоставляемых данными средствами, характеризуется тем, что взаимодействие осуществляется в соответствии с гибкой диалоговой структурой, на привычном для пользователя языке, на различных стадиях разработки и эксплуатации системы, с настройкой средств общения на изменения как проблемной области, так и информационных потребностей пользователя.
Одно из основных назначений рассматриваемого интерфейса — удовлетворение информационных потребностей пользователя на основе применения методов фактографического и (или) документального поиска [22]. Уровень интеллектуализации пользовательских интерфейсов в обеих случаях определяется возможностью задавать условия поиска на естественном языке, не задумываясь об особенностях внутреннего представления значений атрибутов данных и об операциях, которые должны быть выполнены для выражения условий поиска. При этом наиболее сложными для реализации, но и достаточно мощными для выражения информационной потребности пользователя являются текстовые языки общения, предоставляющие человеку в процессе взаимодействия с ИС неограниченный выбор функций. В целях упрощения реализации интерфейсов с текстовыми языками часто используются два подхода: ограничение проблемной области и языка общения. Примером второго подхода может служить текстовый язык общения, разработанный автором в рамках информационно-поисковой системы САПР, обеспечивающей возможности как фактографического, так и документального поиска, в котором задание на поиск формулируется в виде последовательности предложений русского языка, описывающих операции (поиск, сохранение, вывод и др.), необходимые для его выполнения [7, 13].
Возможности современной вычислительной техники и информационных технологий позволяют реализовать текстовые языки без упомянутых выше ограничений. При этом общение осуществляется на привычном для пользователя естественном языке, в котором допускаются ошибки, в целом не требуется строгого соблюдения синтаксиса языка. В настоящее время данный тип языков чаще всего используется в так называемых системах искусственного интеллекта, основанных на знаниях. Не выходя за пределы своей предметной области, пользователь может общаться с ЭВМ непосредственно при помощи информационно-поисковых, расчетно-логических и экспертных систем. В этом плане революционную роль сыграло создание и развитие Web-технологии, ставшей одним из главных факторов, обеспечивших бурное развитие и популярность Internet как глобальной информационной системы. В целом в рамках Web был сконструирован и реализован универсальный способ построения сетевых информационных систем, не зависящих от платформ, использование же браузеров в качестве элемента пользовательских интерфейсов позволило унифицировать и упростить доступ к данным. При этом на современном этапе развития информатики основное внимание в области интеллектуализации пользовательских интерфейсов ИС все в большей степени сосредоточивается на применении для этих целей именно Web-технологий [16–19]. Вместе с тем проблема эффективной организации взаимодействия пользователя с ИС стала еще более насущной и актуальной, обретя новые черты, обусловленные распределенной обработкой информации, необходимостью оптимального распределения функций по обработке данных между серверной и клиентской частями ИС, разнообразием устройств ввода и отображения информации, другими особенностями Web.
Рассмотрим подробнее особенности Wеb, отметив, что гипермедиа-структуры, лежащие в основе построения Web, являются обобщением гипертекстов и имеют одинаковую с ними природу, в соответствии с чем при дальнейшем изложении материала мы будем пользоваться термином гипертекст. Главной частью гипертекста является его тезаурус, представленный совокупностью тезаурусных статей, который служит для систематизации и поиска сведений. Каждая из них отражает сведения о классе объектов, описание которого содержится в информационной статье гипертекста, а также ссылается на родственные тезаурусные статьи с указанием типа родства. Формируется тезаурусная статья на основе индексирования сведений, вводимых в гипертекст.
Тезаурус гипертекста повышает полноту информационного поиска по сравнению с традиционными дескрипторными системами благодаря тому, что в нем могут быть отражены связи между словосочетаниями любой сложности [24].
Графически тезаурус гипертекста можно представить в виде конечного ориентированного графа, вершины которого содержат текстовые описания объектов, а дуги указывают на существование связи между объектами и позволяют определить тип связи.
Для автоматизации процедуры поиска семантических сведений в гипертекстовом массиве могут применяться модели поиска ближайшей по составу и содержанию информационной статьи, а также поиска информационных статей с наиболее желательными свойствами, при этом могут быть применены зарекомендовавшие себя в традиционных информационно-поисковых системах модели, основанные на использовании статистических методов, логических полиномов и весовых критериев [22].
Для пояснения проблем, сопутствующих созданию Web-ресурсов и, соответственно, Web-интерфейсов, укажем на те задачи, которые должен решать их разработчик: выбор информационного содержания; проектирование структуры; проектирование графического представления; разработка компонентов; сборка и верификация структуры (проверка соответствия ограничениям целостности) ресурса; обеспечение идентификации ресурса; обеспечение адаптируемости Web-интерфейса к уровню подготовки и разрешенным видам доступа к информации пользователей. При этом создание новой разработки может начинаться с нуля или с реструктуризации уже имеющихся систем, выполняющих в этом случае роль прототипов. При отсутствии соответствующих инструментов и подходов решение перечисленных задач крайне затруднительно, требует значительных затрат времени, не позволяет вести согласованные работы коллективам специалистов и фактически исключает возможность эффективной оперативной разработки и модернизации Web-ресурсов. Все задачи взаимоувязаны и могут быть решены с применением концепций баз данных к WWW, а также с помощью построения и исследований моделей Web, основанных на использовании для этих целей конечных ориентированных графов, узлы которых соответствуют информационным страницам, а дуги — связям между страницами Web. Эти страницы могут находиться на единственном или множестве сайтов, что отражается в графовой модели. Это может быть осуществлено с помощью меток на дугах графа, содержащих набор данных, определяющих особенности перехода: ссылка, ее местоположение, тип ссылки (на документ, на графи-ческий образ) и другие необходимые сведения (в том числе и семантические).
Данные модели могут быть построены в автоматизированном режиме в процессе тестирования структур разработанных сайтов и в процессе их проектирования для автоматизации процедур последующей сборки. При этом обеспечивается решение таких задач, как определение особых ситуаций (неопределенных ссылок и др.), кратчайших путей по ссылкам между документами сайта. Расширение графовых моделей до уровня фреймовых сетей позволяет создавать средства настройки Web-систем на особенности пользователей, обеспечивая как возможность адаптации к уровню их профессиональной подготовки, так и предоставляя администратору системы дополнительные средства ограничения доступа к информации, что важно для корпоративных информационных систем.
Особые ситуации, которые могут иметь место в структуре Web-интерфейса, отражены на рис. 1: отсутствие концевой вершины на пути (S4, P), невозможность возврата к вершине S1 из вершин S2, S3, S4, S6, S7.
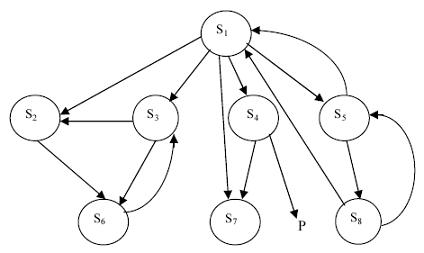
Рисунок 1 — Особые ситуации в структуре Web-интерфейса
При этом все особые ситуации исключаются автоматически, если соответствующий ориентированный граф будет сильно связным, т.е. любая пара его вершин соединена путем. В то же время следовать этому правилу при построении сайта затруднительно, поскольку связи в данном случае имеют семантический смысл и отражают его логико-лингвистическую структуру. Использование наряду с семантическими связями возвратных, обеспечивающих для каждого пути (Si,Sj) также путь (Sj,Si), а для каждой вершины Sk, k∈[2,…,l], где l – количество вершин графа, путь (Sk,S1) (на рис. 1 пути (S5,S1), (S8,S5), (S8,S1)), позволяет разрешить проблему достаточно эффективно.
Перечисленные проблемы, проблемы использования естественных языков при формулировке запросов на поиск информации в InterNet/IntraNet, оценка результатов поиска связаны с задачами интеллектуализации пользовательских интерфейсов и требуют разрешения [18, 19]. Сконструированный и осуществленный в рамках Web способ построения сетевых ИС по своим возможностям в значительной мере приближается к современным экспертным системам: имеет место база знаний, реализуемая в виде гипертекста; присутствует развитый интерфейс с пользователем, позволяющий общаться с системой на языке, близком к естественному (браузер — в качестве диалогового монитора, сценарии диалога — на уровне HTML-документов); возможно наличие средств автоматизированного пополнения и модификации гипертекстовых структур.
Гипертекст как один из вариантов логиколингвистических моделей, широко используемых в экспертных системах, предназначен для систематизации, хранения, накопления и модификации семантической информации, обрабатываемой с использованием вычислительной техники. Главная составляющая гипертекста — тезаурус — обеспечивает взаимосвязь понятий, определяющих предметную сферу, информация о которой заносится в базу знаний. Тезаурусная статья является фактически моделью объекта, которую можно считать некоторой аналогией фрейма, тезаурус же в целом может быть интерпретирован как совокупность взаимосвязанных типовых фреймов [24].
Единственное несоответствие гипертекстовых систем — это то, что экспертным носителем правил вывода является специалист, работающий с информацией. Но это действительно при непосредственном общении пользователя с сайтом. На другом уровне общения — посредством информационно-поисковых систем, при котором указанное несоответствие может быть исключено, список перечисленных задач может быть конкретизирован задачей построения экспертных систем InterNet/IntraNet.
В настоящее время наряду с развитием возможностей языка разметки гипертекстов HTML [25], используемого в основном при создании Web-сайтов, интенсивно развиваются технологии, основанные на Extensible Markup Language (XML) [26], языке, спецификации которого недавно приобрели статус стандарта W3C (World Wide Web Consortium). Нужно отметить, что использование XML-технологий открывает радикально новые перспективы в части интеллектуализации Web-интерфейсов, что связано с возможностью не только предоставлять, но и хранить информацию в структурированном виде. Декларации Document Type Definition (DTD) в языке XML позволяют описывать структурные свойства XML-документов. При этом структура документа определяется как последовательность элементов и/или иерархий элементов определяемых в документе типов. Более развитые средства описания структуры и других свойств XML-документов обеспечивают разрабатываемые W3C спецификации языка определения схемы для XML-документов.
С использованием этих метаданных легко контролировать целостность структуры XML-документов, отображать ее в одну из существующих моделей данных (реляционная, объектная), работать со слабоструктурированной информацией с применением методов баз данных.
При создании сайта в среде XML для формирования его структуры могут использоваться структурообразующие средства самого языка XML (спецификации DTD), а также гиперссылки и указатели, связывающие между собой XML-документы и/или фрагменты документов. Для декларации гиперссылок и указателей предусматривается использование языков XLink и XPointer.
В заключение необходимо отметить, что одним из основных направлений в области интеллектуализации пользовательских интерфейсов в настоящее время является применение для этих целей Web-технологий, расширенных средствами автоматизированной разработки Web-сайтов. Исследования в данном направлении, выполненные авторами при создании ряда информационных систем в Бийском технологическом институте АлтГТУ [16–19], обеспечили создание ком- плекса унифицированных средств построения таких интерфейсов, сокращение сроков их создания за счет применения автоматизированных методов, упрощение взаимодействия с ИС для различных категорий поль- зователей.
Список литературы
- Цурин О.Ф., Зайченко Л.Е., Салова Е.В. Автоматизация проектирования одного класса диалоговых систем // УсиМ. 1979. № 5.
- Ершов А.П. К методологии построения диалоговых систем: феномен деловой прозы // Вопросы кибернетики. Общение с ЭВМ на естествен- ном языке / Науч. совет по комплексной проблеме «Кибернетика» АН СССР. М., 1982.
- Диалоговые системы. Современное состояние и перспективы развития / А.М. Довгялло, В.И. Брановицкий, К.П. Вершинин и др. Киев: Нау- кова думка, 1987.
- Перевозчикова О.Л. Модели общения при решении задач на ЭВМ // УсиМ. 1987. № 5.
- Общение конечных пользователей с системами обработки данных / В.И. Дракин, Э.В. Попов, А.Б. Преображенский. М.: Радио и связь, 1988.
- Коутс Р., Влейминк И. Интерфейс «человек-компьютер». М.: Мир, 1990.
- Попов Ф.А., Груздев Г.П., Галигузов С.Н. Информационно-поисковая система в автоматизированной системе проектирования // Эксплуата- ция вычислительной машины БЭСМ-6: Матер. VI конф. Тбилиси: ТГУ, 1977.
- Попов Ф.А., Карлов А.А. ДИАЛЭМ – диалоговая система для разработки математического обеспечения ЭВМ в режиме эмуляции // Матер. 3-й Всесоюз. конф. «ДИАЛОГ ЧЕЛОВЕК – ЭВМ». Серпухов: ИФВЭ, 1984.
- Попов Ф.А. и др. Математическое обеспечение терминальной станции на базе мини-ЭВМ типа СМ-3, СМ-4 // Матер. 3-й Всесоюз. конф. «ДИАЛОГ ЧЕЛОВЕК – ЭВМ». Серпухов: ИФВЭ, I984.
- Попов Ф.А. и др. Распределенная система машинной графики на основе БЭСМ-6 и комплексов АРМ-М (АРМ-Р) // Тез. докл. Всесоюз. конф. по проблемам машинной графики и цифровой обработки изображений. Владивосток: ИАиПУ ДВНЦ АН СССР, 1985.
- Попов Ф.А. и др. Математическое обеспечение автоматизированного рабочего места программиста задач АСУТП на базе микроЭВМ: Ма- тер. школы-семинара ИВЕРСИ-85. Системные и прикладные аспекты диалога на персональных ЭВМ. Тбилиси: ТГУ, 1985.
- Попов Ф.А. и др. Диалоговая система для разработки математического обеспечения микропроцессорных программируемых управляющих устройств // Тез. докл. 4-й Всесоюз. конф. «ДИАЛОГ ЧЕЛОВЕК – ЭВМ». Киев: ИК АН УССР, 1985. Ч. 1.
- Попов Ф.А. и др. Интегрированная система СИГМА. Архитектура и основные возможности // Тез. докл. IV Всесоюз. конф. по проблемам машинной графики. Серпухов: ИФВЭ, 1987.
- Попов Ф.А. и др. Программное обеспечение интеллектуальных терминалов на основе ПЭВМ ДВК-3 // Тез. докл. V Всесоюз. конф. по ма- шинной графике. Новосибирск: ВЦ СО АН CCCP, 1989.
- Попов Ф.А. и др. Интеллектуальные терминалы на основе IBM РС // Тез. докл. Всесоюз. школы-семинара «Машинная графика и автомати- зация проектирования в радиоэлектронике». Челябинск: ЧПИ, 1990.
- Попов Ф.А., Овечкин Б.П., Максимов А.В. Проблемы и принципы построения пользовательских интерфейсов информационных систем // Известия АГУ. 2000. № 1.
- Жарков А.С., Попов Ф.А., Ануфриева Н.Ю. Пользовательские интерфейсы информационных систем // Наука. Культура. Образование. 2000. № 4/5.
- Попов Ф.А., Максимов А.В., Ануфриева Н.Ю. Проблемы разработки WEB-ресурсов и пути их разрешения // Известия АГУ. Сер. Математи- ка. Информатика. Физика. 2001. № 1 (19).
- Попов Ф.А. Проблемы интеллектуализации пользовательских интерфейсов информационных систем // Ползуновский вестник. 2004. № 3. С. 99–103.
- Минский М. Фреймы для представления знаний. М.: Энергия, 1978.
- Marthin J. Application Development without Programmers. Savant Institute, 1981.