Платформы параллельных вычислений
Автор: Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar
Перевод: Кучереносова о.В.
Источник: http://www-users.cs.umn.edu/~karypis/parbook/Lectures/AG/chap2_slides.pdf
Неявный параллелизм: Тенденции в архитектурах микропроцессоров
Область видимости параллелизма
- Обычная архитектура грубо включает процессор, систему памяти, и информационный канал.
- Каждый из этих компонентов представляет существенные узкие места производительности.
- Параллелизм обращается к каждому из этих компонентов существенными способами.
- Различные приложения используют различные аспекты параллелизма – например, данные itensive приложения используют высокую составную пропускную способность, приложения – серверы используют высокую составную сетевую полосу пропускания, и научные приложения типично используют высоко обработку и производительность системы памяти.
- Важно понять каждое из этих узких мест производительности
Неявный Параллелизм: Тенденции в Архитектуре Микропроцессора
- Тактовые частоты микропроцессора зарегистрировали внушительный прирост за последние два десятилетия (два - три порядка величины).
- Более высокие уровни интеграции устройства сделали доступным большое количество транзисторов.
- Вопрос, как лучше всего использовать эти ресурсы остается важным.
- Текущие процессоры используют эти ресурсы во множественных функциональных модулях и выполняют множественные команды в том же самом цикле.
- Точный способ, которым эти команды выбраны и выполнены, обеспечивает внушительное разнообразие в архитектуре.
Сцепление и Суперскалярное Выполнение
- Сцепление накладывается на различные стадии выполнения машинной команды, чтобы достигнуть производительности.
- На высоком уровне абстракции, машинная команда может быть выполнена, в то время как следующий декодируется, и следующий выбирается.
- Это является похоже на сборочную линию для изготовления автомобилей.
- У сцепления, однако, есть несколько ограничений
- Скорость конвейера в конечном счете ограничена самой медленной стадией.
- Поэтому обычные процессоры полагаются на очень глубокие конвейеры (20 конвейерных состояний в современных процессорах Pentium).
- Однако, в типичных следах программы, каждая 56-ая машинная команда – условный переход! Это требует очень точного предсказания ветвлений.
- Штраф за неудачное предсказание растет с глубиной конвейера, так как большее число команд должно будет быть сброшено на диск.
- Один простой способ облегчить эти узкие места состоит в том, чтобы использовать множественные конвейеры.
- Вопрос тогда становится относительно выбора этих команд.
Суперскалярное выполнение: Пример
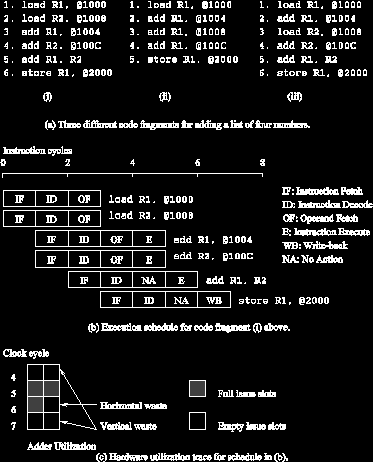
Пример двухстороннего суперскалярного выполнения команд.
- В вышеупомянутом примере есть некоторый расход ресурсов из-за зависимостей в данных.
- Пример также иллюстрирует то что различные смеси команд с идентичной семантикой могут занять совершенно различное время выполнения.
Суперскалярное выполнение
Планирование команд определено многими коэффициентами:
- Истинная Зависимость по данным: результат одной операции – переход к следующей.
- Зависимость Ресурса: две операции требуют того же самого ресурса.
- Зависимость Перехода: команды планируются через операторов условного перехода не могут быть сделаны учеты промахов предсказания априорно.
- Планировщик, часть аппаратных средств рассматривает большее количество команд в очереди машинной команды и выбирает соответствующее число команд, чтобы выполниться одновременно основанный на этих коэффициентах.
- Сложность этих аппаратных средств – важное ограничение на суперскалярные процессоры.
Суперскалярное выполнение: Механизмы Проблемы
- В более простой модели команды могут быть выпущены только в запросе, в котором с ними сталкиваются. Таким образом, если вторая машинная команда не может быть выпущена, потому что у нее есть зависимость по данным с первой, только одна машинная команда выпущена в цикле. Это называют проблемой порядка.
- В более агрессивной модели команды могут быть выпущены не в порядке. В этом случае, если у второй машинной команды будут зависимости по данным с первой, но третья машинная команда не делает, то первые и третьи команды могут быть cо-намечены. Это также называют динамической проблемой.
- Производительность того, чтобы проблема вообще ограничена.
Суперскалярное выполнение: Рассмотрение Эффективности
- Не все функциональные модули могут быть заставлены напряженно трудиться всегда.
- Если во время цикла, никакие функциональные модули не используются, это упоминается как вертикальная затрата.
- Если во время цикла, только некоторые из функциональных модулей используются, это упоминается как горизонтальная затрата.
- Из-за ограниченного параллелизма в типичных следствиях машинной команды, зависимостях, или неспособности планировщика извлечь параллелизм, в конечном счете ограничивает производительность суперскалярных процессоров.
- Обычные микропроцессоры обычно поддерживают четырехканальное суперскалярное выполнение.
Очень длинная машинная команда (VLIW). Процессоры
- Аппаратная стоимость и сложность суперскалярного планировщика – главное что рассматривается в проектировании процессоров.
- Чтобы найти выход, процессоры VLIW полагаются на анализ времени компиляции, чтобы идентифицировать и упаковать вместе команды, которые могут быть выполнены одновременно.
- Эти команды упаковываются и послаются вместе, и таким образом назваются очень длинной машинной командой.
- Это понятие использовалось с некоторым коммерческим успехом в машине Следа Мультипотока (приблизительно 1984).
- Варианты этого понятия используются в Intel процессоры IA64.
Очень длинная машинная команда (VLIW). Процессоры: Обзор
- Аппаратные проблемы реализации более просты.
- У компилятора есть большой контекст, чтобы выбрать запланированные команды.
- У компиляторов, однако, нет во время выполнения информации, такой как неудачные обращения в кэш. Планирование, поэтому, неотъемлемо консервативно.
- Предсказание перехода и памяти является более трудным.
- Производительность VLIW очень зависит от компилятора. Много методик, таких как развертывание цикла, интеллектуальное выполнение, предсказание ветвлений важно.
- Типичные процессоры VLIW ограничены с 4 и 8 степенями параллельности
Ограничения производительности систем памяти.
- Система памяти, а не скорость процессора, часто является узким местом для многих приложений.
- Производительность системы памяти в значительной степени зафиксирована двумя параметрами, временем ожидания и полосой пропускания.
- Время ожидания – время затраченное от запроса к памяти и до момента, когда данные доступны в процессоре.
- Полоса пропускания – норма, по которой данные могут качаться на процессор системой памяти.
Производительность Системы Памяти: Полоса пропускания и Время ожидания
- Очень важно понять различие между временем ожидания и полосой пропускания.
- Рассмотрите пример пожарного шланга. Если вода выходит из шланга спустя две секунды после того, как гидрант включен, время ожидания системы составляет две секунды.
- Когда вода уже подается, если гидрант поставляет воду со скоростью 5 галлонов/сек, полоса пропускания системы составляет 5 галлонов/сек.
- Если Вы желаете непосредственно ответ от гидранта, важно уменьшить время ожидания.
- Если Вы хотите бороться с большим огнем, Вы хотите высокую полосу пропускания.
Время ожидания Памяти: Пример
- Рассмотрите процессор, работающий в 1 ГГц (такт 1 нс) подключенный с DRAM со временем ожидания 100 нс (без кэша). Предположим, что процессор имеет два модуля умножения-сложения модули, и способен выполнять четыре команды в каждом цикле 1 нс. То отсюда следует:
– Пиковая оценка процессора – 4 GFLOPS.
– Так как время ожидания памяти равно 100 циклам, и размер блока – одно слово, каждый раз, когда поступает запрос к памяти, процессор должен ждать 100 циклов прежде, чем он сможет обработать данные. - На вышеупомянутой архитектуре, рассмотрите проблему вычисления поэлементного перемножения двух векторов.
Поэлементное вычисление произведения выполняет одна операцию умножения-сложения для каждой пары векторных элементов, то есть, каждый элемент с плавающей запятой, требует одну операцию выборки данных.
Из этого следует, что пиковая скорость данного вычисления ограничена одной операцией выборки элемента с плавающей запятой каждые 100 нс, или скоростью 10 MFLOPS, что является очень маленьким значением пиковой оценки процессора!
Увеличение эффективности памяти за счет времени ожидания используя кэши
- Кэши – элементы маленькой и быстродействующей памяти между процессором и динамической оперативной памятью.
- Эта память действует как память высокой полосы пропускания с более низким временем ожидания.
- Если часть данных неоднократно используется, эффективное время ожидания этой системы памяти может быть уменьшено кэшем.
- Фракцию справочной информации данных, удовлетворенной кэшем, называют отношением удачного обращения в кэш вычисления на системе.
- Отношение удачного обращения в кэш, достигнутое кодом на системе памяти часто, определяет свою производительность.
Применение Кэшей: Пример
Рассмотрим архитектуру из предыдущего примера. В этом случае, мы зададим кэш размера 32 Кбайта со временем ожидания 1 нс или одним циклом. Мы используем эту установку, чтобы умножить две матрицы A и B размерностью 32 × 32. Мы тщательно выбрали эти числа так, чтобы кэш был достаточно большим, чтобы сохранить матрицы A и B, так же как матрицу-результат C.
Следующие наблюдения могут быть сделаны о задаче:
- Выборка этих двух матриц в кэш соответствует выборке слов 2 КБ, которая займет приблизительно 200 мс.
- Умножение двух матриц n × n занимает 2n3 операции. Для нашей задачи это соответствует 64 тыс. операций, которые могут быть выполнены в 16 тыс. итераций в цикле (или 16 мс) в четырех командах за цикл.
- Полное время для вычисления приблизительно сумма времени для операций загрузки\сохранения и времени для непосредственно вычисления, то есть, 200 + 16 мs.
- Это соответствует пиковой норме вычисления 64K/216 или 303 MFLOPS.
Применение кэшей
- Повторная справочная информация на тот же самый элемент данных соответствует временному местоположению.
- В нашем примере у нас был O (n2) доступа к данным и O (n3) вычисление. Это асимптотическое различие делает вышеупомянутый пример иллюстрирует желательное применение кэша.
- Многократное использование данных важно для производительности кэша.
Полоса пропускания памяти
- Полоса пропускания памяти определяется полосой пропускания шины памяти так же как и количеством модулей памяти.
- Полоса пропускания памяти может быть улучшена, увеличивая размер блоков памяти.
- Основная система берет l единиц времени (где l – время ожидания системы), чтобы доставить b единиц данных (где b – размер блока).
Полоса пропускания памяти: Пример
Рассмотрим ту же самую конфигурацию как прежде, кроме того в этом случае, размер блока – 4 слова вместо 1 слова. Мы повторяем вычисление поэлементного произведения в этом сценарии:
- Предположим, что векторы размещены линейно в памяти, восемь FLOPs (четыре операции умножения-сложения), может быть выполнены в 200 циклах.
- Однако, потому что однократный доступ к памяти возращает четыре последовательных слова в вектор.
- Поэтому, двойной доступ к памяти может выбрать четыре элемента каждого из векторов. Это соответствует ФЛОПУ каждые 25 нс для пиковой скорости 40 MFLOPS.
Полоса пропускания памяти
- Важно отметить, что увеличение размера блока не изменяет время ожидания системы.
- Физически, сценарий, проиллюстрированный здесь, может быть рассмотрен как широкая шина данных (4 слова или 128 битов) связанный с многократными банками памяти.
- На практике, такие широкие шины сложны для реализации.
- В более практической системе последовательные слова посылают на шину памяти на последующих циклах шины после того, как первое слово восстановлено.
- Вышеупомянутый пример ясно иллюстрируют, как увеличенная полоса пропускания приводит к более высоким пиковым нормам вычисления.
- Расположения данных, как предполагалось, были таковы, что последовательные слова данных в памяти использовались последовательными инструкциями (пространственное местоположение ссылки).
- Если мы берем расположение данных центральное представление, вычисления должны быть переупорядочены, чтобы увеличить пространственное местоположение ссылки.
Полоса пропускания памяти: Пример
Рассмотрим следующий фрагмент кода:
for (i = 0; i < 1000; i++) column_sum[i] = 0.0; for (j = 0; j < 1000; j++) column_sum[i] += b[j][i];
Фрагмент кода суммирует колонки матрицы b в вектор column_sum.
Вектор column_sum является маленьким и легко помещается в кеш.
Матрица b получена в порядке следования столбцов
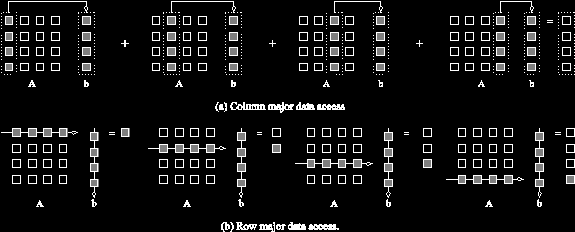
Умножение матрицы на вектор:
(a) умножается колонка на колонку, сохраняя текущую сумму;
(b) вычисляя каждый элемент результата как поэлементное произведение строки матрицы на вектор.
Мы можем исправить вышеупомянутый код следующим образом:
for (i = 0; i < 1000; i++) column_sum[i] = 0.0; for (j = 0; j < 1000; j++) for (i = 0; i < 1000; i++) column_sum[i] += b[j][i];
В этом случае, матрица транспанирована в порядке следования строк, и выполнение, как можно ожидать, будет значительно эффективней.
Производительность системы памяти: Резюме
Ряды примеров, представленных в этом разделе, иллюстрируют следующие понятия:
- Эксплуатация пространственного и временного местоположения в приложениях важна для того, чтобы амортизировать время ожидания памяти и увеличить эффективную полосу пропускания памяти.
- Отношение числа операций к числу доступов памяти – хороший индикатор ожидаемого допуска к полосе пропускания памяти.
- Схемы размещения памяти и вычисление организации соответственно могут сделать существенное влияние на пространственное и временное местоположение.