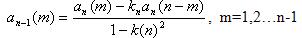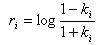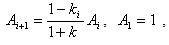|
|||||||||||
|
|||||||||||
|
РЕФЕРАТ кваліфікаційної роботи магістра «Розробка комп'ютеризованої системи контролю доступу з використанням аутентифікації по голосу» ВСТУП ВВЕДЕНИЕ
СПИСОК ЛІТЕРАТУРИ ВСТУП Інформація у наш час – найдорожчий та найпотрібніший товар. Вона дає владу над людськими масами або дозволяє обігнати конкурентів. На захист інформації мобілізовані найвищі технології. Найперше їхнє завдання – не допустити до неї сторонньої людини, тобто надійно розпізнати, хто «свій», а хто ні. Та, якщо карту доступу можна елементарно вкрасти, а PIN-коди не особливо зручні, їх доводиться запам'ятовувати і кожного разу вводити. Очевидний вихід – використовувати для ідентифікації саме людське тіло, його параметри, по-науковому звані біометричними. Серед різних біометричних систем голосова аутентифікація має наступні переваги:
1 АКТУАЛЬНІСТЬ ТЕМИ РОБОТИ Перед будь-яким підприємством у сучасному світі гостро стоїть проблема захисту від несанкціонованого доступу до своїх матеріальних (приміщення, будівлі) і віртуальних (комп'ютерні бази даних) ресурсів. Біометричне рішення цієї проблеми – найбільш надійна і комплексна технологія, з існуючих у світі технологій, в галузі розробки рішень по аутентифікації користувачів. Згідно міжнародної конференції, присвяченої «голосовій біометрії», яка щорічно проводиться в США, аутентифікація по голосу стрімко розвивається і з кожним роком користується все більшим попитом [1]. Проте до сих пір невирішеним питанням залишається вибір оптимального набору ознак, які б мінімізували помилки першого і другого роду. 2 МЕТА І ЗАДАЧІ Метою магістерської роботи є мінімізація помилок 1-го і 2-го роду і збільшення швидкості аутентифікації в комп'ютеризованій системі контролю доступу з використанням аутентифікації по голосу. Для досягнення мети магістерської роботи необхідно вирішити наступні задачі:
3 ПЛАНОВАНА НАУКОВА НОВИЗНА Планована наукова новизна магістерської роботи: мінімізація помилок 1-го і 2-го роду за рахунок вибору ефективної комбінації методів виділення унікальних ознак та їх класифікаторів. 4 ОГЛЯД ДОСЛІДЖЕНЬ І РОЗРОБОК ЗА ТЕМОЮ 4.1 На національному рівні У нашій країні, на відміну від країн зарубіжжя, практично відсутні дослідження і розробки по даній темі. В Україні даною темою займаються в Інституті проблем штучного інтелекту [2], Харківському національному університеті радіоелектроніки [3], Національному технічному університеті України «Київському політехнічному інституті» [4]. 4.2 На глобальному рівні Розглянемо наступні закордонні системи:
Voice Key Service – система голосової біометричної аутентифікації, розроблена російською компанією «Центр мовних технологій» (ЦМТ) [5]. Технологія Voice Key використовує унікальні характеристики фізіологічної будови мовного тракту кожної людини. В її основі лежить запатентований компанією ЦМТ алгоритм, що використовує спектрально-формантний метод виділення і порівняння біометричних ознак. Переваги:
Недоліки:
SPIRIT SV-система – система аутентифікації, розроблена російською компанією SPIRIT Corp [6]. Ця система здатна працювати у різних умовах: від аутентифікації диктора для локальних систем безпеки до віддаленої аутентифікації по телефону, що може бути застосовано, наприклад, для банківських служб та електронної комерції. Конкретне рішення може бути зроблено SPIRIT Corp., включаючи портінг системи на задану платформу та забезпечення телекомунікаційної підтримки. Введений диктором мовний сигнал (після запиту системи) зазнає наступної обробки: попередня фільтрація; еквалайзінг для компенсації лінійних спотворень в мікрофоні і телефонної лінії; виключення ділянок сигналу, що не містять мови; інтелектуальне детектування найменш зашумленних ділянок мовного сигналу; виділення інформативних ознак із зазначених ділянок мовного сигналу (як правило, це спектральні ознаки, зокрема, кепстральних коефіцієнти або їх модифікації). Інформативні ознаки містять інформацію про текст парольної фрази та особливості її вимови конкретним диктором. Потім відбувається класифікація мовного зразку. При аутентифікації здійснюється оцінка близькості зразка до еталону (моделі цього диктора) і робиться порівняння цієї оцінки з порогом. Прийняття рішення відбувається по мінімуму відстані між пропонованим зразком і найближчою моделлю з набору моделей голосів дикторів, що входять в задану групу. Відбір на предмет приналежності до групи здійснюється шляхом порівняння зазначеної відстані з порогом. Система виконана на платформі WINTEL з наступними мінімальними вимогами: платформа Win32 (Windows 98SE/2000), процесор Intel Pentium MMX 200 MHz або вище, ОЗУ 32 Мб, звукова карта, мікрофон, навушники, середа MS Visual C + + 6.0. Переваги:
Недоліки:
Speech Secure – система ідентифікації голосу, розроблена американською компанією Nuance Technology [7]. Спочатку в процесі реєстрації, система за спеціальними алгоритмами, створює модель голосу, використовуючи унікальні характеристики голосу того, хто телефонує. Система зберігає моделі голосу (опис структури голосу і особливостей голосового тракту) як частину профілю абонента. Під час аутентифікації (ідентифікації) ці моделі використовуються для визначення рівня відповідності голосу того, хто телефонує голосам записаних раніше людей. На основі цієї інформації система приймає рішення щодо проведення операції. Система доступна через веб-інтерфейс. Повна версія включає:
Переваги:
Недоліки:
5 ОПИС ОБ'ЄКТА КОМП’ЮТЕРИЗАЦІЇ Об'єктом комп'ютеризації у даній роботі є система контролю доступу з використанням аутентифікації по голосу. Аутентифікація диктора – спосіб перевірки автентичності, який дозволяє достовірно переконатися в тому, що суб'єкт дійсно є тим, за кого він себе видає, на підставі порівняння голосу з еталоном. Під голосовою аутентифікацією полягає наступна ситуація [8]. Диктор вимовляє фразу, а комп'ютеризована система розпізнавання індивідуальних характеристик голосу повинна підтвердити або спростувати індивідуальність того, хто говорить. Взагалі вимовити фразу може як істинний користувач, так і зловмисник. Задаючись вартістю витрат у випадку можливого несанкціонованого доступу зловмисника, можна (для даної системи) розрахувати ймовірність, з якою система не повинна пропускати чужого. Завданням початкового етапу аутентифікації диктора за тембром голосу є перетворення в мовний сигнал звуків, що генеруються речовою системою людини [9]. Звук, як відомо, являє собою механічні коливання, що поширюються в навколишньому середовищі (середовищем розповсюдження служить повітря). Тиск звукової хвилі сприймається мікрофоном і перетворюється їм в електричний аналоговий сигнал. Для подальшої обробки необхідно провести перетворення інформаційного образу мови з аналогового сигналу в дискретний. Це завдання вирішує аналого-цифровий перетворювач. АЦП здійснює дискретизацію і квантування мовного сигналу. Дискретизація полягає в розбитті безперервного сигналу на ряд дискретних відліків, кожен з яких представляє значення аналогового сигналу у відповідний момент часу. Дискретизація дозволяє скоротити кількість інформації, що підлягає подальшій обробці, до необхідного мінімуму. Однак частота дискретизації, тобто число відліків у секунду, повинна бути достатньо великою, інакше можуть бути пропущені важливі зміни сигналу, присутні у його аналогової формі. Згідно теоремі Котельникова частота дискретизації F0 повинна бути, як мінімум, у два рази вище максимальної частоти даного сигналу Fmах. При меншій частоті дискретизації починає губитися інформація, яка активно використовується при розпізнаванні. Особливо це важливо для розпізнавання в умовах шумів. Але сильно збільшувати частоту дискретизації немає сенсу: при незначному збільшенні корисної інформації починає збільшуватися кількість непотрібної інформації (шумів). На практиці частоту дискретизації треба обирати навіть дещо більше, ніж рекомендує теорема Котельникова, так як в теоремі розглядається ідеалізований випадок. Частотний діапазон мови знаходиться в діапазоні 100-4000 Гц. Оскільки максимальна частота мови Fmах=4 кГц, то F0 має бути дещо більше, ніж 3*Fmах=12 кГц. У нашому випадку ми використовуємо частоту дискретизації F0 =22050 Гц. Квантування полягає в округленні заміряного аналогового сигналу з точністю до молодшого розряду АЦП. Таким чином, квантований сигнал може приймати тільки фіксовані значення з кроком, рівним ціні молодшого розряду, в той час, як вихідний сигнал був безперервним і міг приймати будь-яке значення. Необхідна кількість розрядів АЦП n можна визначити з виразу:
де D - необхідний динамічний діапазон в дБ. Інтенсивність звуку під час промови змінюється приблизно від 20 дБ (шепіт) до 70 дБ (голосна розмова), таким чином динамічний діапазон може досягати 50 дБ. Виходячи з цього кількість розрядів АЦП має бути не менше 8. У нашому випадку ми використовуємо розрядність 16 біт. Найважливішим параметром систем аутентифікації є коефіцієнт надійності – ймовірність помилок 1-го і 2-го роду. Помилки виникають в результаті того, що при порівнянні реального ідентифікатора та ідентифікатора в базі даних існує складність досягнення ідеальної відповідності (100% збігу). Тому вводиться поріг, який однозначно повинен визначити відсоток відповідності, при якому ідентифікатор буде визнаний відповідним. Запровадження такого порогу може призвести до помилок:
Кожна дана система може перебудовуватися таким чином, що помилки одного роду можуть бути зменшені за рахунок збільшення помилок іншого роду (навіть при збереженні всіх інших факторів, що впливають на ймовірність помилки: тривалість і характер мовного повідомлення, перешкоди і т.п.). Зміна співвідношення помилок першого і другого роду досягається за рахунок зміни порогу прийняття рішення та вибору набору ознак. 6 АНАЛІЗ УНІКАЛЬНИХ ІНДИВІДУАЛЬНИХ ОЗНАК, ЩО ХАРАКТЕРИЗУЮТЬ ОСОБУ ДИКТОРА Найважливішим елементом успішного розпізнавання дикторів є вибір інформативних ознак (мовних параметрів), здатних ефективно представляти інформацію про особливості мови конкретного диктора. До них пред'являються наступні вимоги:
У якості унікального вектора ознак можна використовувати одномірний частотний вектор кепстральних коефіцієнтів, а також вектор складений з його похідних [10]. Кепстральні коефіцієнти визначаються відповідно до схеми, представленої на рис. 6.1:
Рисунок 6.1 – Загальна схема кепстрального аналізу сигналу (FFT – блок швидкого перетворення Фур'є сигналу, LOG – блок логарифмування спектру, IFFT – блок зворотного швидкого перетворення Фур'є) Лінійне передбачення є одним з найбільш ефективних методів при оцінці основних параметрів мовного сигналу, таких як, наприклад, період основного тону, функція площі мовного тракту і т.п. Важливість методу обумовлена високою точністю одержаних оцінок і відносною простотою обчислень. Основний принцип методу лінійного передбачення полягає в тому, що поточний відлік мовного сигналу можна апроксимувати лінійною комбінацією попередніх відліків. Коефіцієнти передбачення при цьому визначаються однозначно мінімізацією середнього квадрата різниці між відліками мовного сигналу і їх передбаченими значеннями (на кінцевому інтервалі) [11]. Ще в якості вектора ознак можна використовувати коефіцієнти відбиття. Фізичний сенс коефіцієнтів відбиття полягає у визначенні величини хвилі, відбитої на кордоні двох акустичних труб. Коефіцієнти відбиття розраховуються шляхом перетворення вектора коефіцієнтів фільтра передбачення a в коефіцієнти відбиття відповідної решітчастої структури по наступному рекурсивному алгоритму:
Дані формули базуються на рекурсивному алгоритмі Левінсона. Для його реалізації у циклі перебираються елементи вектора a, починаючи з останнього і закінчуючи другим. Іноді використовуються також функції від коефіцієнтів відбиття – логарифмічні співвідношення площ (Log-Area Ratio – LAR) [12]:
де ki – коефіцієнти відбиття. Ще однією ознакою є площі поперечних перерізів акустичних труб. Голосовий тракт можна представити у вигляді послідовності р акустичних труб однакової довжини і різних діаметрів, які мають площі поперечних перерізів Ai [13]. Площі поперечних перерізів Ai акустичних труб обчислюється через коефіцієнти віддзеркалення:
де р – порядок лінійного передбачення, ki – коефіцієнти відбиття. (A2 ,..., Ap+1) – вектор ознак, що базується на площах акустичної труби. Зауважимо, що коефіцієнти відбиття визначають співвідношення площ сусідніх секцій. Таким чином, площі поперечного перерізу не визначаються абсолютно точно, але все ж таки ці площі часто бувають подібними з конфігурацією голосового тракту, який використовується людиною при мовотворення. 7 ВИБІР СТРУКТУРИ КОМП’ЮТЕРИЗОВАНОЇ СИСТЕМИ КОНТРОЛЮ ДОСТУПУ З ВИКОРИСТАННЯМ АУТЕНТИФІКАЦІЇ ПО ГОЛОСУ Структура комп'ютеризованої системи контролю доступу з використанням аутентифікації по голосу представлена на рис. 7.1.
Рисунок 7.1 – Структура комп'ютеризованої системи контролю доступу з використанням аутентифікації по голосу (анімація: об'єм – 50 756 байт; розмір – 779х459; складається з 4 кадрів; затримка між останнім і першим кадрами – 1 500 мс; затримка між кадрами – 800 мс; цикл повторення – безперервний) Ця система складається з двох основних підсистем: підсистеми введення мовного сигналу і підсистеми аутентифікації. Перша розташована на стороні клієнта і забезпечує введення мовного повідомлення користувача через мікрофон, який записується у файл .wav з форматом аудіо PCM, 22050 кГц, 16 біт, моно. Сформований сигнал з цієї підсистеми направляється на серверну підсистему аутентифікації, яка складається з бази даних, блоку параметризації, навчання, кластеризації та прийняття рішень. У блоці параметризації відбувається виділення ознак, що характеризують особу диктора. Блок кластеризації використовує дані блоку навчання і поточний параметризований сигнал. На основі даних класифікації та порогового значення блок прийняття рішення формує рішення: диктор свій чи чужий. Сформований результат надходить (в залежності від конкретних задач) або на виконавчий пристрій, або у підсистему авторизації. 8 ЗАПЛАНОВАНІ ПРАКТИЧНІ РЕЗУЛЬТАТИ Після аналізу унікальних індивідуальних ознак, що характеризують особу диктора, а також методів класифікації дикторів, на підставі практичних результатів досліджень виберемо ті ознаки (у поєднанні з певним ефективним класифікатором), які будуть мати найкращі показники, тобто найменші помилки першого і другого роду. При цьому швидкість аутентифікації повинна бути не більше 30 сек. Далі планується розробка забезпечувальної частини даної комп'ютеризованої системи з використанням найбільш ефективної ознаки або їх комбінації та обраного методу класифікації. Потім буде проведено тестування системи і необхідне налаштування. ВИСНОВКИ У ході виконання науково-дослідницької роботи були проаналізовані існуючі комп'ютеризовані системи контролю доступу з використанням аутентифікації по голосу та виявлено їх недоліки. Після аналізу унікальних індивідуальних ознак, що характеризують особу диктора, вибрали ті ознаки, які прості у вимірюванні та дають уявлення про особливості мови конкретного диктора. Також запропонована структура комп'ютеризованої системи контролю доступу з використанням аутентифікації по голосу. СПИСОК ЛІТЕРАТУРИ
При написанні даного автореферату магістерська робота ще не завершена. Остаточне завершення: грудень 2010 р. Повний текст роботи й матеріали по темі можуть бути отримані в автора або його керівника після зазначеної дати. © ДонНТУ 2010, Кулібаба О.В. |
|||||||||||

|
ДонНТУ >>
Портал магістрів ДонНТУ Автобіографія| Реферат |
||||||||||