
XProtect – система защиты активной HTML-информации
Пехотин Е.В.
Источник: Работа приняла участие и стала победителем конкурса «Завтра.UA»-2009
Введение
Задача защиты информации довольно стара и на сегодняшний день остро стоит в информатике. Как известно, сегодня практически для любой программы легко достать так называемый кряк, т.е. в общем случае некоторый набор данных, предоставляющих к программе нелегальный, но полноценный доступ.
Сегодня не существует универсальных алгоритмов решения данной проблемы, и даже ранее с успехом работавший метод грубой силы (чем больше, тем лучше) дает осечку по причине существования инструментов, автоматизирующих процесс анализа и взлома. Побеждает не тот, кто сильнее, а тот, кто хитрее, кто может сделать неожиданный ход, ввести противника в заблуждение или выбить у него опору из-под ног. Лучшим решением будет комплексное применение защитных приемов, однако с нестандартным подходом к ним.
Данная работа направлена на разработку и реализацию необходимого барьера на пути изучения, взлома и доступа к некоторым DHTML-данным в нескольких направлениях: защита от возможности использовать хранящиеся данные не иначе, как только методом снятия скриншота и привязка самого защитного комплекса к поставляемому с ним носителю.
Для написания и компиляции созданных алгоритмов был выбран язык Ассемблера и применялся редактор и компилятор FlatAssembler for Windows. Это было сделано с целью применения более хитрых трюков при написании защиты, а также из-за хорошей лицензии fasm’а (да и автор уже более 10 лет программирует на ассемблере и знает его лучше, чем даже C).
1 Постановка задачи и общий обзор решения
1.1 Постановка задачи
Постановка задачи: имеется программа P, у которой имеются некоторые данные, представленные множеством каталогов и файлов D. Необходимо:
- Преобразовать множество D так, чтобы было невозможно или достаточно затруднительно извлечь из него файлы и каталоги в исходном виде – проблема создания защищенного формата данных;
- Преобразовать программу P так, чтобы она запускалась только при наличии ее собственного носителя (CD-диска) в приводе;
- Как можно сильнее усложнить взлом программы P для извлечения алгоритмов решения задачи 1 и правки алгоритмов решения задачи 2.
Дополнительным пожеланием является исключение методов ring0-защиты.
Анализ проблемы 1 приводит к мысли спрятать все множество D в единый файл со сложным форматом, для разбора которого могут быть потрачены дни, анализ проблемы 2 приводит к мысли создать комплексную многоуровневую защиту.
1.2 Общий обзор ситуации в сфере защиты данных на сегодняшний день
На сегодняшний день имеет место «гонка вооружений»: вначале побеждают создатели защиты и должно пройти некоторое время, чтобы последняя была взломана, однако так или иначе защита все равно будет взломана. Существует единственное правило: стоимость защиты должна быть больше или равной стоимости защищаемой программы. Только в этом случае можно гарантировать, что взломщики не возьмутся ломать ее за деньги.
2 Общий концепт защиты программы
2.1 Общие приемы защиты
- Физически разбить весь монолитный комплекс на несколько блоков кода, причем так, чтобы самостоятельно любой блок, кроме первого, не мог быть подгружен и использован отдельно от программы, блоки являют собою кусок защиты следующего уровня; их необходимо разбросать по всему диску защиты, включая недоступные стандартным средствам области [3];
- Активно использовать классы и технологию COM, т.к.: 1) нет имен; 2) легко поменять и подменить на каждом этапе загрузки; 3) одна из самых высоких сложностей анализа среди всех технологий (т.к. статический дизассемблер уже не может проанализировать такие программы); 4) сокрытие настоящий целей использования функций из OLE-библиотек;
- Активно использовать потоки (threads) и нити (fibers) в защитных механизмах – последние особенно хороши при ручном поочередном управлении из различных процессов таким образом, что под отладчиком будет неявно сбиваться их синхронизация; на потоках можно реализовать систему самоконтроля во времени (антипатчинг);
- Перевести критические участки кода на виртуальную машину и исполнять в ней (сложность анализа логики и опкодов виртуальной машины);
- Использовать множественный неявный самоконтроль [1];
- Как можно больше привязок к именам, адресам, смещениям и т.д.
2.2 Концепт защиты программы от использования без оригинального CD
- Проверять тип носителя и метку; эта защита будет первой на пути взлома и поэтому ею необходимо усыпить бдительность;
- При наличии на носителе UID’а, использовать его для проверки на «правильный» диск; данную защиту необходимо хорошо скрыть и выполнять неявно;
- Сделать неправильный TOC – оставляя диск читаемым для стандартного драйвера CDFS, создать пустые области для собственных данных, обнаружить которые можно только посредством прямого покластерного чтения диска; также в качестве скрытых областей использовать не до конца заполненные файлами и резервные кластеры [2];
- В скрытые области диска помещать критические данные и код программы, например, некоторая контрольная сумма диска может лежать в трех местах: самой программе, файле данных и скрытой области, причем в последней желательно хранить видоизмененную контрольную сумму;
- Возможна еще двухсессионная запись, когда в первой сессии записываются настоящие файлы с данными, а во второй файлы перезаписываются всякими не очень важными данными и мусором;
- Самое сложное – применение собственной ФС для носителя, скажем, во втором треке, тогда запускать программу (с первого трека) можно будет без труда, но прочесть содержимое второго трека – только с помощью программы;
- Делать попытку самостирания для защиты от копирования на HDD;
- Для защиты от эмуляции необходимо делать проверку скорости чтения данных с диска;
- Использование невидимых сессионных файлов (физически существующих в данной сессии, но в ее TOC’е отсутствует информация о них, хотя они и учитываются в размере сессии) и межсессионных блоков данных;
- Примерная последовательность проверки диска: метка – эмуляция – наличие защищенных областей – UID – проверка данных в защищенных областях – их загрузка и использование.
2.3 Концепт защищенного хранилища файлов
- Необходимо преобразовывать имена всех хранимых файлов невосстановимым образом (защита от визуального поиска имен);
- Все данные в файле–контейнере необходимо как можно сильнее преобразовывать в псевдомусор (защита от визуального поиска текстовых данных и стандартных файловых сигнатур);
- Необходимо разбить каждый защищаемый файл на фрагменты и каждый фрагмент обрабатывать отдельно (защита от ручного извлечения файлов из контейнера);
- Многостадийная обработка каждого фрагмента каждого файла;
- Возможность интеграции API защищенного хранилища с использующим его приложением на уровне алгоритмов (т.е. приложение предоставляет свои алгоритмы для каждой операции).
2.4 Концепт основного комплекса защиты – защищенного браузера
- По сути – браузер, использующий сторонний HTML–движок (в данном случае – MSHTML);
- Тесная интеграция с кодом обработки защищенного хранилища используемых файлов и защиты от копирования с CD;
- Часть защиты вынесена в браузер, часть – разбросана в остальных файлах и блоках данных диска;
- Реализация собственного протокола для загрузки файлов (сердцем является собственная реализация интерфейса IInternetProtocol).
3 Разработка формата защищенного хранилища
3.1 Общая идея формата XPFC
Первой идеей, пришедшей в голову автору по проблеме защиты данных, была идея хранить их все вместе в едином файле, формат которого был назван (x) Protected Files Container (Защищенный Файловый Контейнер). Алгоритмически формат представлен двумя сущностями – программой создания XPFC-контейнера XPFCCreator и API доступа к нему, на данный момент реализованного в виде DLL (планируется переделать в бинарный дамп).
Сразу стоит отметить, что x-контейнер можно физически разбить на блоки, первым блоком является заголовок контейнера.
При разработке данного формата основной целью было затруднить извлечение из него данных, для этого была введена концепция файлоблоков – блоки постоянной длины в области данных, в которых размещается содержимое всех защищаемых файлов, изюминкой является то, что для каждого файлоблока можно указать собственные алгоритмы криптования (защита от автоматического анализа на сигнатуры, энтропию и шум), упаковки (защита от визуального и автоматического анализа на шум + уменьшение объема контейнера) и зашумливания (защита от визуального анализа и извлечения, возможно двухуровневое зашумливание), также существует (сразу после заголовка) блок общеиспользуемых алгоритмов – таких, которые применяются в большинстве файлоблоках, описаны в этом блоке, а ссылки на них из файлоблоков осуществляются по ID’у. Структуры описания алгоритмов спроектированы так, что позволяют указывать параметры каждому алгоритму.
Далее, как известно, любой взлом начинается с запуска взламываемого приложения на предмет его реакции и почти всегда проходит через фазу поиска «нехороших» текстовых строк, типа «Unregistered version», «Unlicensed» и тому подобных. В процессе размышления автор приходит к выводу, что попытки взломать неизвестный файловый формат вероятнее всего будут начаты с поиска текстовых строк в экземпляре этого формата, и если будут найдены строки типа «index.htm», или «data\protected_picture.gif», то часть изучения можно будет свести к анализу нескольких следующих или предыдущих байтов или байтов, адресующих на данные строки. Поэтому, в целях безопасности было решено полностью отказаться от таблиц описания файлов в формате и использовать для этого единую хеш-таблицу, ключи которой получаются из алиасов файлов (которые могут быть и частью имени, что и реализовано в XPFCCreator’е) посредством некоторой невосстановимой хеш функции: hkey = hash_func(alias).
Теперь никто не может сказать ничего конкретного об именах сохраненных файлов и структуре каталогов, из которой они были получены. Через некоторое время автор вспомнил, что такой подход уже применяется в mpq-архивах, как видим, идея не нова. Главное, что достигается при этом – невозможно (имеющимся API формата) доступиться к файлу в x-контейнере, не зная алиаса, под которым он прописан. Единственная проблема на сегодняшний день – не изобретено еще, как хранить хеш–таблицу так, чтобы нигде явно не было указано ее размера, т.е. количества элементов в ней (а лучше, чтобы это было невозможно даже рассчитать), т.е. пока что можно определить количество имеющихся в x-контейнере файлов, и, забегая наперед, узнать начало блока Run-List’ов. Однако, эта проблема частично разрешима: необходимо брать таблицу, большую, чем необходимо и свободное место заполнять мусором с одновременным созданием фантомных Run-List-цепочек, пересекающихся с реальными.
Как уже отмечено выше, физически x-контейнер можно разделить на несколько блоков, вначале идет блок заголовка, далее – блок описания общеиспользуемых алгоритмов, следом за ним – блок хеш–таблицы, а потом – блок Run-List’ов.
Run-List – это упрощенная концепция из NTFS, в каждом RunList’е идет цепочка записей, каждая из которых содержит номер первого файлоблока данной непрерывной цепочки файлоблоков и их количество в цепочке, а также заголовок данного RunList’а, содержащий флаги, общее количество файлоблоков и еще несколько важных полей.
Последний и самый главный блок x-контейнера – блок файлоблоков, содержащий в себе файлоблоки – это блоки данных одинакового размера, имеющих заголовки. Каждый файл в x-контейнере представлен набором файлоблоков и, самое главное, каждый файлоблок может, как отмечено выше, описывать собственные алгоритмы, так что теоретически, не только каждый защищаемый файл, а даже каждый файлоблок последнего можно защищать своими собственными алгоритмами. Размер файлоблоков является числом, равным 2^N: от 512 байт до 512Mb включительно (в этой версии).
Относительно алгоритмов стоит сказать, что на данный момент имеется пять типов алгоритмов: неизвестный (для внутреннего обмена между XPFC API и приложением), шифрования, сжатия, расчета хеша, расчета хеш-входа и алгоритм шума и зашумливания данных. Последние два – это один и тот же тип, различается только тем, что алгоритм шума применяется ко всему файлоблоку, и этот алгоритм описывается, как «по умолчанию», а алгоритм зашумливания данных – только к области данных и при условии явного его указания в файлоблоке, иначе не будет применено ничего. В состав стандартного API на текущий момент входят: 1 алгоритм расчета хеша по алиасу, 1 алгоритм расчета хеш-входа и 1 алгоритм шума.
Самым главным достоинством XPFC-формата является то, что в каждом типе алгоритмов область ID’ов алгоритмов разделена на две: область стандартных алгоритмов и область пользовательских алгоритмов, причем функция извлечения просто передает этот ID пользовательской callback-функции, которая возвращает указатель на функцию обработки данного алгоритма, что позволяет при необходимости полностью отказаться от использования собственных стандартных алгоритмов XPFC, заменив их своими собственными защищенными алгоритмами работы с данными; это дает возможность использовать API XPFC только лишь как интерфейс для инкапсуляции низкоуровневых структур x-контейнера.
3.2 Описание XPFCCreator’а – программы для создания XPFC-контейнера
XPFCCreator – это программа, позволяющая создавать XPFC-файлы из множества файлов, хранящихся в выбранной папке. Главное окно программы приведено на рисунке 1. Следует отметить, что программа находится в стадии alpha, но ее уже можно использовать для сборки файлов в один x-контейнер, хотя она и не осуществляет шифрование и сжатие данных, но уже имеет реализованный алгоритм зашумливания.
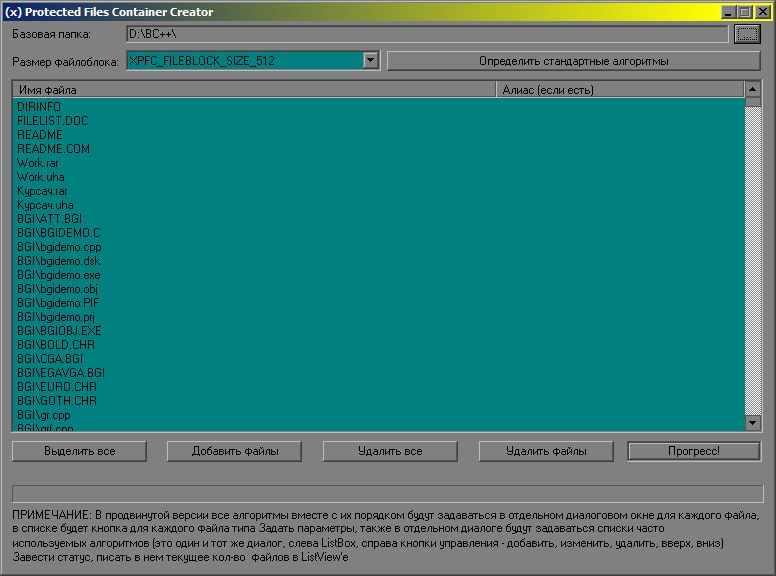
Рисунок 1 – Главное окно программы XPFCCreator
Основные ограничения данной версии:
- Используется фиксированная цепочка стандартных алгоритмов;
- Отсутствуют алгоритмы сжатия, криптования и зашумливания;
- В качестве алиасов – только относительные имена файлов;
- На диске, содержащим временную папку пользователя, должно быть достаточно места для tmp-файла файлоблоков.
3.3 Описание XProtectedBrowser’а – защищенного браузер-движка
XProtectedBrowser (Защищенный Браузер, рисунок 2) являет собой собственно защитный механизм и целевое приложение данной работы. Первым полюсом защиты является внутренний протокол передачи данных в HTML-движок MSHTML (для обработки и отображения защищаемых DHTML-страниц используется именно он). Протокол реализован в виде набора интерфейсов и классов, центральной является реализация интерфейса IInternetProtocol – CXPFCProtocol, посредством которого MSHTML запрашивает и получает данные. Второй полюс – защита от извлечения визуальной информации любым методом, кроме снятии скриншота – также реализован в виде нескольких интерфейсов, используемых MSHTML для получения информации о визуализации сайта; центральным является интерфейс IDocHostUIHandler.
CXPFCProtocol осуществляет доступ к файлам сайта из защищенного контейнера посредством API в XPFC.dll, однако, планируется сделать ее, как бинарную подгружаемую секцию.

Рисунок 2 – Главное окно XProtectedBrowser
Выводы
В данной работе для решения задачи защиты содержимого DHTML-сайта было предложено и реализовано следующее:
- Новый файловый формат сокрытия и защищенного хранения данных, использование которого приводит к одновременной легкости доступа к данным на уровне защиты, простоте их хранения и трудности анализа формата такого файла; для повышения надежности имена файлов заменяются их хеш-значениями, что приводит к значительному осложнению визуального анализа экземпляра формата;
- На основании стороннего HTML-движка использовать собственные интерфейсы работы с файлами, данными и их выводом, что приводит к возможности усилить защиту передаваемых и отображаемых на экране данных.
Перечень ссылок
- Крис Касперски aka Мыщьх. Неявный самоконтроль как средство создания неломаемых защит // wasm.ru
- Крис Касперски aka Мыщьх. Техника защиты лазерных дисков от копирования. Статья // www.kpnc.opennet.ru
- Cпецвыпуск журнала Хакер #57, август 2005 г. // www.wisesoft.ru/content1984.htm