Источник:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.75.8188&rep=rep1&type=pdf
Современные параллельные вычислительные возможности FPGA и их способность к реконфигурированию делает их идеальной платформой для построения ускорителей для суперкомпьютерных систем. Недавно предложенный фирмой Cell Broadband EngineTM1 как многоядерный процессор предоставляет большие мощности. В этой статье мы познакомим с прототипом системы, которая комбинирует эти два типа вычислительных устройств в единый реконфигурируемый профиль, и опишем его архитектуру, подсистему памяти и богатый интерфейс.
Для реконфигурируемого профиля желательно, чтобы FPGA устройство имело возможности реконфигурирования в реальном времени. Эта статья представляет частично динамически реконфигурируемую технику (ДРТ) и дизайн потока для реконфигурируемого профиля. Также будут изложены экспериментальные результаты профиля, выполняющего частичную реконфигурацию. ДРТ позволяет перестраиваемому профилю быть мощным, изменяемым в реальном времени компьютерным двигателем. Простая программа, представленная далее, была запущенная на процессоре Cell и динамически загружена на FPGA.
Конфигурируемая система на кристалле (Configurable System-on-a-Chip - CSoC) содержит от одного и более микропроцессоров, встроенных в программируемые поля массивов вентилей (FPGA- field programmable gate array). Эти CSoC устройства с высокой плотностью транзисторов FPGA фабрик и встроенные микропроцессоры предоставляют возможности программируемой платформы ускорителей для суперкомпьютеров.
Недавно анонсированный ячеечный широкополосный двигатель (Cell Broadband Engine) может достигать 256Гфлопс пиковой производительности при 4Ггц (одинарная точность). Cell- это мульти-процессорное устройство 64-битного мощного процессорного ядра и нескольких синергетических процессорных ядер[2][3]. Система, которая объединяет оба Cell процессора и FPGA должна быть платформой, в которой эти два типа устройств служат дополнением друг для друга. В этой статье мы представляем реконфигурируемую систему, основанную на Cell - устройствах, которая содержит две микросхемы FPGA с возможностью динамического перепрограммирования.
Обычно процесс конфигурирования устройства сбрасывает ранее установленную конфигурацию, если она существовала, и записывает всю программу для устройства. В течение процесса конфигурирования система не работоспособна. Однако, под действием некоторых обстоятельств, желательно реконфигурирование части системы в реальном времени, не мешая работе остальных частей. Один из таких примеров показан на рисунке 1, в котором поток данных проходит сквозь конфигурируемую систему. Один из модулей ищет в потоке данных части строк. При необходимости строка поиска должна меняться, но поток данных должен оставаться тем же. Для такой реализации требуется динамическая частичная реконфигурация.
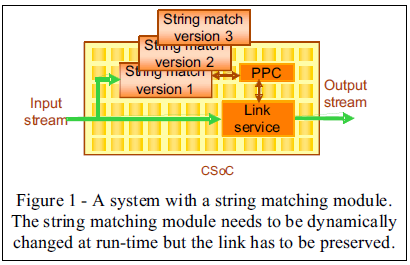
Обе архитектуры Xilinx Virtex и Virtex-4 поддерживают динамическое реконфигурирование. Xilinx Virtex, Virtex-2 и Virtex-2 Pro устройства могут быть перепрограммированы методом колонок [4]. Авторы [5] разработали «слияние динамической реконфигурации» техники в Virtex-4. В этой статье будет представлен подход к использованию динамического частичного реконфигурирования техники в реконфигурируемых профилях. Знакомство с реконфигурируемым профилем будет в главе 2. В главе 3 будет представлен подход к интегрированию динамических частично-реконфигурируемых систем с нашим реконфигурируемым профилем. В главе 4 приведены экспериментальные данные. Глава 5 – это заключение статьи.
Основное устройство реконфигурируемого профиля состоит из одного Cell-процессора и двух микросхем FPGA. Cell Broadband Engine состоит из одного 64-битного PowerPC (PowerTM Processor Element, или PPE) и 8 синергетических процессорных ядер (Synergistic Processing Elements (SPE)) [2][3]. PPE содержит 32Кбайт кеша первого уровня и 512Кбайт кеша второго уровня. Каждый SPE содержит 256Кбайт, являющихся ОЗУ, которое называется локальной базой(Local Store (LS)). PPE и SPE поддерживают режим SIMD. Рисунок 2 показывает схему системы реконфигурируемого профиля, в котором присутствует Virtex-4 LX160 FPGA(“FPGA #1”) и Virtex-4 FX100 FPGA (“FPGA #2”). XDR DRAM память присоединяется к Сell-процессору. XDRAM память обеспечивает высокую пропускную способность. FlexIO [6] интерфейс предоставляет соединения между Сell и FPGA #1. Rambus FlexIO интерфейс – это высокоскоростная шина, поддерживающая широкий спектр скоростей – от 400Мбит\с до 8Гбит\с. FlexIO интерфейс разработан для бюджетного использования.
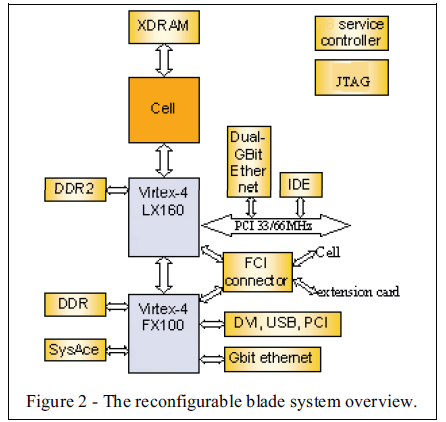
FlexPhase представляет собой новую технологию в классической схемотехнике. Она дает возможность с точностью до бита выравнивать данные и синхроимпульсы на чипе, избавляя пользователя от трассировки и программирования таймингов. Это приводит к логичной системе, способной поддерживать многочастотную передачу данных, более простой, более компактной и более дешевой. FlexIO интерфейс обеспечивает высокую пропускную способность между Cell - процессором и чипом FPGA.
Каждый FPGA имеет свое соединение с локальной памятью(DDR1, DDR2 или SDRAM). Мультинаправленная высокоскоростная SERDES шина формирует соединение между FPGA и может достигать скорости в 5Гбит\с двунаправленной передачи. Реконфигурируемый профиль обладает большим количеством интерфейсов, включающих в себя PCI-express, PCI, IDE, DVI, скоростной Ethernet, Xilinx SystemACE, флеш кардридер, USB и другие. Профиль в целом имеет 4606 компонент. Обе используемые микросхемы FPGA относятся к недавно-разработанным FPGA. Предыдущий комплект относился к высокопроизводительным приложениям, взамен которому пришел комплект приложений для встраиваемых систем. Эти две микросхемы подключены к одной и той же шине граничного сканирования(JTAG) так же как и SystemACE. Карта выбора(SelectMap) FPGA #1 подключена к FPGA #2.
В этой статье будет обсуждаться только ДТР в FPGA #2. Аналогичная техника может быть использована и в других FPGA.
На рисунке 3 изображена схема перестраиваемой системы реконфигурируемого профиля.
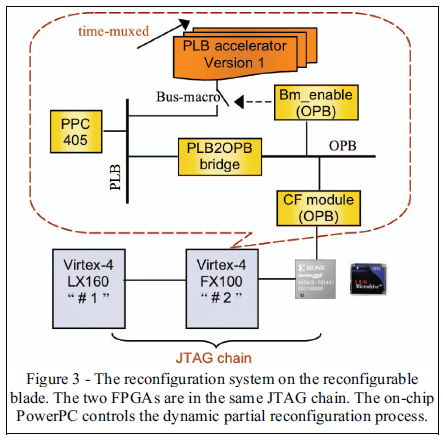
В FPGA #2 динамически реконфигурируемой частью является PLB ускоритель, который имеет несколько версий реализации, но установлена и работает в каждый момент времени только одна. PLB ускоритель подключен к одному из двух PowerPC 405 через PLB(processor local bus- локальная шина процессора). Необходимо заметить, что ускоритель взаимодействует с PLB через макрос-шину. Макрос-шина включается/выключается в Bm_enable, который находиться в OPB (on-chip peripheral bus – периферийная шина чипа). OPB SystemACE модуль, СF модуль, предоставляют интерфейс между PPC405 и микропроцессором в SystemACE устройстве.
На рисунке 4 изображена конструкция потока реконфигурируемого профиля с ДТР. Макрос-шина включена между ускорителем и статической частью для того, чтобы организовать закрытую маршрутизацию. Единственным исключением является сигнал синхронизации, который входит в динамическую модель напрямую, поскольку конфигурирование синхронизации отделено от конфигурирования логики и не меняет глобальные настройки синхромаршрутизации. На момент написания статьи, ПО фирмы Xilinx, обеспечивающее возможность частичной реконфигурации, требует, чтобы синхронизация была выполнена на кристалле высокого качества. Любая глобальная синхронизация, такая как DCM(digital clock manager – цифровой менеджер синхронизации), должна находиться на верхнем уровне конструкции. Еще одна проблема состоит в том, что постоянные сигналы(«0» или «1», находящиеся постоянно в сигналах шины) проходящие сквозь статико-динамическую границу не всегда могут быть распознаны как сигнал в ПО. Одно из решений – это вручную устанавливать константы сигналов Земля/питание(GND/Vcc) выше, чем сигналы в макрос-шине. Мы использовали Xilinx PlanAhead, чтобы выполнить планировку и управление частью потока, чтобы сгенерировать полный и части файла потока бит.

Оба FPGA сконфигурированы через JTAG, что показано на рисунке 3. Обычная флешкарта является хранилищем полной и частичных конфигураций. Конфигурации FPGA и выполняемые команды переформатированы в команды JTAG отдельно, после чего они соединяются вновь. Объединенные полные конфигурации JTAG конвертируются в ACE файл. При создании файла частичной конфигурации, мы устанавливаем опции, которые запрещают JTAG затирать настройку FPGA #1.
Подпрограмма работает в одном FPGA #2’s PowerPC405s, контролируя поток частичной конфигурации. В течение частичной реконфигурации, макрос-шина должна быть отключена от динамической и статической части. Иначе непредсказуемые сигналы при частичной реконфигурации могут перевести систему, в том числе и PowerPC405, в непредсказуемое состояние.
Мы использовали пример из рисунка 1 в качестве экспериментального приложения и сравним результаты системы с FPGA и симуляцию на Cell процессоре.
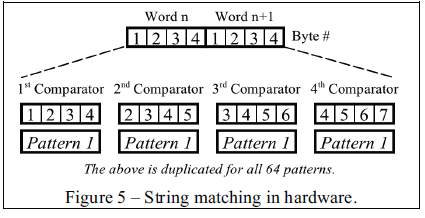
Система настроена так, как показано на рисунке 3 пунктиром. Входной поток данных поступает в динамический модуль ускорителя и состоит из двух 32-битных слов. Для каждого 32-битного слова ускоритель проверяет текущее слово, сдвинутое на 1, 2 или 3 байта с шаблонным словом. Обработка эквивалентна 4-ем 32-битным сравнениям. 64 32-битный части проверяются одновременно. Таким образом, для одного входного слова ускоритель выполняет 256(4*64 = 256) сравнения (рисунок 5). Для обоих 32-битных входных потоков общая сумма операций эквивалентна 512 32-битным сравнениям. У нас имеется две версии ускорителей, различающихся только шаблоном.
В FPGA #2, массив CLB(13*120) составляет динамический ускоритель. Общая стоимость системы равносильна 5,455 частей, в то время как ускоритель расходует 3,264 части. Пропускная способность ускорителя – 2 слова за цикл.

Размер сгенерированного ACE файла получится 435Кбайт (см табл. 1). Мы использовали таймер PPC405, чтобы быть уверенными, что количество циклов синхронизации PPC405 позволит ожидать процессы ДТР. PPC405 работает на 100Мгц, а ДТР процесс требует 290 мс для этого примера.

Таблица 2 показывает вычислительные возможности ускорителя. FPGA #2 работает на частое 100Мгц. Блок сравнения строк может достигать в пике 51,2 миллиард 32битный сравнений в секунду при текущей частоте синхронизации или 200 миллионов 64битных входных слов в секунду.
Мы запустили пример на Cell процессоре SPE, чтобы получить основу для сравнения относительной эффективности динамической архитектуры ускорителя. Мы использовали IBM Full-System Simulator известную как Mambo [1]. Mambo поддерживает циклы точных вычислений, когда работает на SPE, но не имеет возможности получить доступ за пределы локальной памяти SPE. Таким образом, мы ограничиваем сферу нашего анализа пропускной способности сравнения строк в предположении, что входной поток данных и модели уже присутствуют в локальной памяти. Это ограничение справедливо, поскольку возможности, обсуждаемые в 4.1, изолированы в аппаратуре.
Мы реализовали пример как С программу в Linux окружении симулятора. Код написан таким образом, чтобы в полной мере воспользоваться возможностями SPE SIMD. Так как SPE работает на 128битных данных, то он может обрабатывать 4 32-битных слова одновременно. Наша реализация включает цикл для итераций по 64 частям шаблонов сравнения. Мы повторили цикл 8 раз, чтобы минимизировать зависимость от частей.
После запуска примера в симуляторе и подачи потока данных, состоящего из 1024 4-словных элементов, симулятор доложил о времени работы в 1019960 циклов. При частоте в 3,2Ггц это соотносится с 317,7375 мс в сравнении на 4096 32битных элементов 64 частей. Этот показатель соответствует пиковой производительности согласования примерно 12851000 элементов в секунду в случае, когда используется один SPE или 102 806 000 элементов в секунду для 8 SPE, без учета доступа к памяти.
Увеличение плотности и кол-во процессоров на кристалле в устройствах CSoC делают их пригодными для использования в качестве ускорителей в суперкомпьютерах. Между тем, недавно представленный Cell Broadband EngineTM достигает 256Гфлопс пиковой производительности. Мы разработали реконфигурируемый профиль, объединяющий эти два типа устройств. В этой статье мы представили архитектуру и интерфейсы реконфигурируемого профиля.
Как вычислительная система, для некоторых приложений, реконфигурируемый профиль продолжает работать в тот момент, когда переконфигурируется одна из его FPGA. Желательно, чтобы FPGA поддерживали возможность динамической частичной реконфигурации в реальном времени. В этой статье представлены разработки потоков для достижения вышеописанной цели. Мы изложили экспериментальные результаты применения на примере одной из FPGA и результаты моделирования для процессора Cell.
Все же еще слишком рано, чтобы оценивать производительность процессоров Cell на реконфигурируемом профиле или общую производительность профиля. В наших будущих работах будет включено улучшение интерфейса в чипе и оценки системы.
Эта работа была спонсирована поддержана Semiconductor Research Corporation (2005-HJ-1331).
[1] IBM Full-System Simulator for the Cell Broadband EngineTM Processor. http://www.alphaworks.ibm.com/tech/cellsystemsim.
[2] Introduction to the Cell multiprocessor. http://researchweb.watson.ibm.com/journal/rd/494/kahle.html , 2006.
[3] D. Pham, S. Asano, M. Bolliger, M. N. Day, H. P. Hofstee, C. Johns, J. Kahle, A. Kameyama, J. Keaty, Y. Masubuchi, M. Riley, D. Shippy, D. Stasiak, M. Suzuoki, M. Wang, J. Warnock, S. Weitzel, D. Wendel, T. Yamazaki, K. Yazawa The Design and Implementation of a First-generation Cell Processor. In Procs. of the IEEE Int. Solid-State Circuits Symposium, February 2005.
[4] D. Lim and M. Peattie. Two flows for partial reconfiguration: module based or small bit manipulation, Application Note 290, Xilinx, 2002.
[5] P. Sedcole, B. Blodget, T. Becker, J. Anderson and P. Lysaght. Modular dynamic reconfiguration in Virtex FPGAs, IEE Proceedings of Computers and Digital Techniques, May 2006, Volume 153, Issue 3, p. 157-164.
[6] K. Chang, S. Pamarti, K. Kaviani,E. Alon, X. Shi, T.J. Chin, J. Shen, G. Yip, C. Madden, R. Schmitt, C. Yuan, F. Assaderaghi, M. Horowitz, Clocking and Circuit Design for a Parallel I/O on a First-generation CELL Processor, International Solid-State Circuit Conference 2005, pp 526- 527.