Источник: http://www.iamm.ac.donetsk.ua/upload/iblock/cbd/freiberg%202008%20final.pdf
Evolutionary distributed test generation methods for digital circuits
Источник: Donetsk National Technical University, Donetsk, Ukraine
Institute of Applied Mathematics and Mechanics of NAS of Ukraine, Donetsk, Ukraine.
Рассматривают генетические алгоритмы испытательного производства и моделирования ошибки для цифровых схем. Представлены главные способы генетического алгоритма parallelization для испытательного производства и моделирования - "рабочий-фермер", "островная модель". Обсуждено выполнение программы и компьютерные эксперименты предложенных методов.
Эволюционные вычисления - новое руководство в теории и практике искусственного интеллекта, который сильно исследован в настоящее время. Этот термин использован к родовому описанию поиска, оптимизируя или изучая алгоритмы, основанные на некоторых формальных принципах естественного эволюционного выбора. Среди этого может быть выбрано главные парадигмы:
-Генетические алгоритмы (GA);
-Эволюционная стратегия;
-Эволюционное программирование;
-Генетическое программирование.
Различия этих подходов в основном состоят в способе представления решения и в различии эволюционных операторов, используемых в моделировании. Все парадигмы широко используются для испытательного поколения цифровых систем.
Классический "простой" ГА [1] использует двоичные строки (например, 0011101), чтобы представить особь. Поэтому он выглядит очень привлекательным использованием ГА для методов решения проблем АТГН для DS на структурных и функциональных уровнях описания. Так генетические алгоритмы успешно используются для генерации тестов цифровых схем [1, 2] (с восьмидесятых) наряду с детерминированными структурными методами. Несколько ГА-систем, основанных на АТГН были разработаны такие как КРИС, GATEST [1], Гатто [2], DIGATE [1] и другие. В отличие от известных АТГН мы используем вычислительные кластера на базе локальной интрасети. Опыт показывает, что генетические алгоритмы дают лучшие результаты для схем, ориентированных на обработку данных, в то время как детерминированные методы более успешно работают для последовательной схемы с трудной логикой управления.
Параллельные версии разработаны для некоторых систем, например, Гатто *, Гатто +, CGATTO [3] для увеличения покрытия ошибок и уменьшения процессорного времени. Различные системы использованы для различных параллельных компьютерных архитектур и различных инструментов программы. В этой статье мы представляем параллельный Г. А. , который позволяют расширить эффективность ГА. для этой проблемы. В отличие от известных АТГН мы используем вычислительные кластера на базе локальной интрасети.
Целью автоматической генерации тестов является построение входных последовательностей двоичных наборов, которые проверяют любой физический недостаток возможно в процессе производства (или) эксплуатации логических схем. Однако существует огромное количество возможных потенциальных физических дефектов. Некоторые классы неисправностей, которые имитируют реальные физические дефекты, как правило, рассматриваются. Таким образом, ошибка модели (один или несколько) физических недостатков.
На практике чаще всего рассматривается по одному стеку в константных неисправностях, генерации тестов, на которые обычно дает удовлетворительные результаты (покрытия ошибок) для реальных неисправностей в цепях. В случае необходимости (низкий охват ошибки), испытания могут быть получены и для других типов ошибок, таких как короткое замыкание, обрыв (короткий), задержки распространения сигналов и т. д. Известно, что испытания поколения является NP-трудной задачей, которая означает, что в худшем случае это решается путем перечисления всех возможностей [3]. Поэтому, несмотря на тот факт, что разработано большое число последовательных структурных методов испытания поколения, которые на протяжении многих схем дают хорошие результаты (высокий уровень охвата ошибки), были сделаны попытки для распараллеливания поколения испытания [1].
Во время генерации тестов для цифровых схем с применением Г. А. , как особь может быть использована последовательность испытаний представлены в виде бинарных таблиц. Популяция состоит из фиксированного числа тестовых последовательностей, возможно, различной длины.
Для выбранной кодировки отдельных особей и популяции можно использовать следующие проблемно-ориентированные генетические операторы [2]:
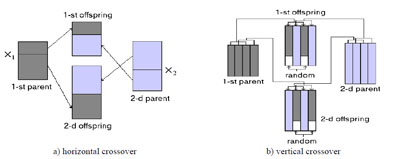
1) Кроссовер. Будут реализованы два типа операции (рис. 1): вертикальные и горизонтальные кроссовера, которые выполняются в соответствии с вероятностями и Рv и Ph=1- Рv;
2) мутации. Три вида этого оператора соответственно используются с вероятностями Pm1, Pm2 и Pm3, а также:
- удаление одного входного вектора в случайно выбранной позиции. Применение этой операции позволяет уменьшить длину генерируемой последовательности испытаний в том случае, когда удаленный вектор не ухудшает испытания свойств последовательности;
- добавление одного входного вектора в любом положении, что также позволяет расширить область поиска решений;
- случайная замена бита в серии испытаний.
Поскольку целью генерации тестов является вид входной последовательности, в которой максимально отличаются значения сигналов в ошибке и хороших схемах, качество тестовой последовательности (фитнес-функции) может быть оценена как мера разности значений сигналов в ошибке и хорошей схеме. В простейшем случае программы логического моделирования хороших схем используются для этой цели, позволяя оценить значения сигналов на двух соседних (по времени) тестовых. На основе даты хорошего моделирование разработаны следующие фитнес-функции:
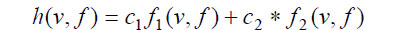
где f1и f2 - ряд изменений сигналов на выходах логических элементов и триггеров соответственно (С2>>C1); Фитнес-функция для последовательности определяется как взвешенная сумма фитнес-функции отдельных моделей ввода:
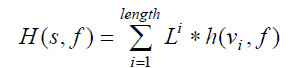
где S проанализированная последовательность;vi - вектор из рассматриваемой последовательности, i - позиция вектора в последовательности,f - с учетом ошибки 0
Сегодня предлагаются многочисленные модификации и обобщения GA [4]. Параллельно ГА (PGA) примерно предстоящих и очень перспективным с теоретическими исследованиями и практической точек зрения приложений. ГА присущий "внутренний" параллелизм и возможностб распределенных вычислений способствовать развитию параллельных ГА. Прежде всего необходимо отметить, что основой PGA является структурирование популяции - разложение на несколько подгрупп (подмножества). Это разложение может быть выполнено различными методами, которые определяют различные типы PGA.
В этом разделе для распараллеливания ГА мы используем модель «рабочий-фермер» ("клиент-сервер"), потому что она требует небольших изменений в существующей программной реализации тестов ГА и дает неплохие результаты. При таком подходе каждый процессор имеет свою собственную копию популяции. Расчет расходов значений фитнес-функции равномерно распределены по всем процессорам. Для всех процессоров используется список неисправностей. Поэтому для N особей и P процессоров берется популяция с каждый процессором. Значения фитнес-функции вычисляются по работникам процессора и отправляется в один выбранный фермером процессор, который собирает всю информацию и передает его для всех процессоров. Каждый процессор содержит информацию о значениях фитнесс-функции для всех особей и может создать следующее поколение популяции на этой основе.
На первом этапе каждый рабочий процессор загружает поколение (моделирование) одной подпоследовательности. Для баланса список незамеченных недостатков разбивается на примерно одинаковые подгруппы. Так процессор фермер выполняет центральная часть (ядро) испытания алгоритма генерации, а логического моделирования (безотказной ошибки) цифровых схем реализуются на процессорах-рабов. Ошибка моделирования является наиболее важным с точки зрения расчета расходов. Известны различные методы распределенного моделирования ошибки, которые в основном базируются на разложении: 1) схем на подсхемы; 2) серии испытаний на подпоследовательностей. Мы будем принимать комбинированный подход этих двух методов.
На первом и втором этапах моделирования входных последовательностей распределяются между рабочими процессорами. На первом этапе каждый рабочий процессор загружает поколения (моделирование) одной подпоследовательности. Для баланса список незамеченных недостатков разбивается на примерно одинаковые группы.
В конце каждого из трех этапов помещаются точки синхронизации. Когда процессор-мастер приходит в эти точки, он идет в режиме ожидания, а все рабочие процессоры не будет делать с задачами, которые гарантируют глобальную правильность алгоритма. Таким образом работа распределена между процессорами сбора и работников следующим образом.
Процессор мастер получает результаты и, соответственно, изменение глобальной структуры данных (общий список ошибок, значения фитнес-функции для особей и т. д.). Процессор-работник сохраняет локальную копию схемы (во внутреннем формате) и список ошибок. Каждый «работник» принимает входную последовательность от «фермера» и определяет обнаруженные недостатки по этой последовательности, логического моделирования и вычисляет значения фитнесс-функции для особей. Он посылает полученные результаты к мастеру и ждет следующую задачу. Процессор-мастера:
• Выполняет все операции ввода-вывода с пользователем и файловой системой: он читает описание схемы и список ошибок, и пишет, сгенерированной последовательности тестовый вход;
• Первоначально работает «раб» процессов на имеющихся ресурсах;
• Распространяет копии (очная форма) схем и списки ошибок каждый рабочий процессор;
• Организует контроль процесса создания тестов: как только входной последовательности соответствует неисправность моделирования, он посылает соответствующее сообщение для активации рабочих процессоров;
- Процессор с обнаруженным списком ошибок и незамеченными недостатками от других рабочих процессоров требует много ресурсов.
Заключительные результаты (тест входных последовательностей и покрытия ошибок) близки к результатам, полученными на одной компьютерной системе владельца с использованием аналогичного алгоритма. Качество решения (охват испытаний ошибки) здесь не потерялось и в большинстве случаев стало лучше, и время тестов существенно растет. Диаграмма потока данных представленного алгоритма представлена на рис. 2.
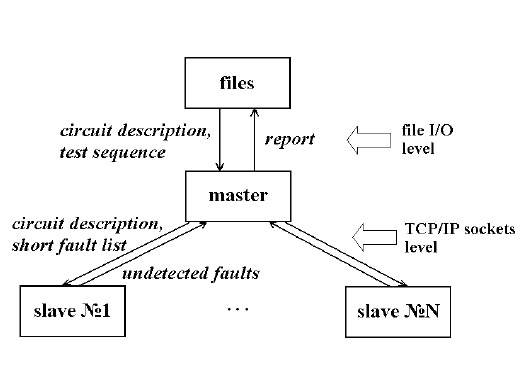
Описанный выше распределенный генетический алгоритм генерации тестов базируется в основном на распределенном алгоритме моделирования неисправностей. Теперь мы коротко опишем этот метод.
Одной из центральных проблем цифровых устройств является диагностика моделирования ошибки цифровых схем. Повышение сложности современных устройств делает задачу сокращения времени моделирования ошибки по-прежнему актуальны. Один из возможных способов ускорить процедуру моделирования ошибки адаптация существующих алгоритмов для многопроцессорных вычислительных систем (кластеров) реализации.
Распределенное моделирование ошибки организована подобным образом и основывается также на подходе «рабочий-фермер», как распределенной генерации тестов. Один процессор здесь выбран в качестве фермера (мастер) и оставался процессором - как и рабочие (рабы). Там существует несколько подходов к реализации распределенного моделирования ошибки: разбиение схемы [4] и перегородки ошибки список [4]. Наш алгоритм основан на перегородки списка ошибки.
Ядром этого процесса является ««параллельное моделирование ошибки» процедура, которая является регулярной симулятором ошибки, что используется в реализации одного процессора. В нашем случае мы использовали дом, построенный на доказательствах ошибки. Отметим основные преимущества этого алгоритма, что делает его очень успешным: 1) динамическая обработка ошибки - лист: неисправность устраняется по списку ошибки в то же время он обнаружил, не выполняет моделирование для этой ошибки дальше; 2) ошибки сортировки, которая позволяет включать в одной группе недостатки, которые вызывают те же события моделирования; 3) метод функционального инъекции ошибки.
Мастер-процесс начинается с поиска порядка расчета клиентов. Далее он делит полный список ошибок в подсписки пропорционально количеству найденных клиентов. Тогда для всех клиентов следующая последовательность операций выполняется в цикле: посылает описание схемы во внутреннем формате; посылает испытания и соответствующий короткий список ошибок. После этого мастер пошел в состоянии ожидания данных от клиентов. На следующем шаге мастер получает результаты ошибки моделирования с каждого клиента, и делает общий доклад: покрытия ошибок, общее время моделирования, время моделирования на любом компьютере.
Эти особи принимаются в соседних процессорах субпопуляциях, а затем независимой эволюции на каждом процессоре-"острове" и продолжается. 5 распределенных генераций тестов на основе "модели острова"
В этом разделе употребляется для распараллеливания ГА "модель острова". Здесь отдельные субпопуляции, которые инициализируется случайным образом и развивались независимо, осуществляется на каждом процессоре. В данной итерации некоторые субпопуляции обмениваются с некоторыми особями определенным образом. Каждый процессор выбирает лучшие особи собственной субпопуляции и отправляет их на соседние процессоры субпопуляций (окрестности концепция параметра метода).
В этом подходе есть больше шансов получить качественное решение, поскольку в разных областях пространства поиска исследованы на разных процессорах. Кроме того, в этом случае возможно сокращение времени поиска из-за лучшей индивидуальной миграции.
В связи с миграцией лучших тестовых последовательностей каждый процессор может определять ошибки быстрее, чем в случае самостоятельной работы в группах. Одним из наиболее важных параметров этой модели способность популяции (индивидуальный номер) субпопуляции. Влияние и выбор этого параметра, будут рассмотрены ниже. В отличие от предыдущего метода ("рабоче-фермер" модель), где ГА. работает только на центральных процессорах и процессорах мастер-рабов используются только для фитнес- функции, в этом подходе полное Г. А. осуществляется на каждом процессоре. Иными словами, каждый процессор выполняет полный цикл работ ГА. Эволюция: безотказной ошибки логического моделирования, генерации тестовых последовательностей. Каждый процессор работает с полной цепью и ошибкой. В то же время есть две причины ускорения процесса генерации тестов по крайней мере. Каждый процессор работает с субпопуляцией меньшей размерности, что меньше времени требуется.
Осуществление и экспериментальные исследования распределенных ГА генерации тестов и моделирования
Разработанные алгоритмы были реализованы с использованием блокирующих сокетов технологии в C + + Builder среды программирования. Для компьютерных экспериментов был использован вычислительный кластер на базе 100 Мбит местной интрасети. Узлы кластера имеют следующие параметры: Intel Celeron с частотой 2 ГГц процессор, оперативная память 256 Мб, ОС Windows XP.
Для исследования эффективности предложенных алгоритмов следующие временные параметры были рассчитаны во время компьютерных экспериментов: все время моделирования процессов, номер событий в ошибке моделирования, целый ряд мероприятий. Для сравнения были приняты экспериментальные результаты алгоритмов из [2].
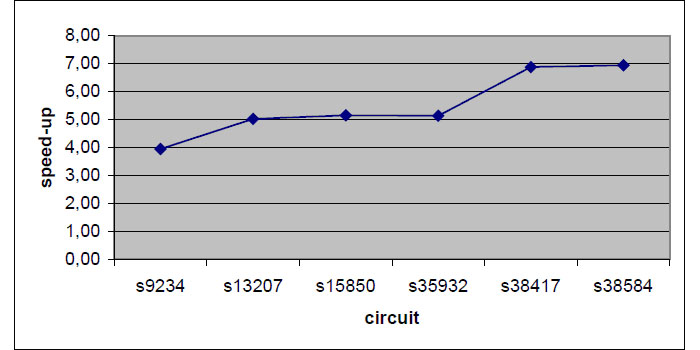
Сначала давайте рассмотрим экспериментальные результаты, полученные для распределенных ГА. С реализацией, основанной на "рабочий-фермер" модели. Диаграммы моделирования ускорения для контура s35932 (ISCAS89), при условии изменения числа процессоров-клиента от 1 до 8, представлены на рис. 3. Учитывая экспериментальные результаты подтверждается эффективность предлагаемых методов распараллеливания моделирования алгоритма. Наконец, на рис. 4 результаты моделирования для больших схем тесте ИСОГД представлены. Эти данные показывают, относительно ускорения с увеличением размера схемы. Это объясняется тот факт, что для больших схем распараллеливания расходы сводятся сравнить с затратами ошибки моделирования.

Пусть, далее, рассмотреть результаты реализации тестов с распределенными ГА. , который основан на "модели острова". В таблице 1 представлены экспериментальные результаты, которые показывают, ускорения и контроля качества в течение нескольких схем из ISCAS89. В этом случае 8 процессоров и метод кольца миграции были применены.
Полученные результаты подтверждают эффективность генерации тестов и ошибки моделирования алгоритмов распараллеливания. Сравнение экспериментальных результатов показывает, что "Фермер-работник" модель дает более ускорения по сравнению с "моделью острова" относительно друг-процессорной системы и существенно проще в программной реализации. Но "модели острова" поднимает покрытия ошибок генерируемых испытаний особенно для больших схем.