Самая старая и распространенная структура сайтов.
При создании сайта применяется современная блочная структура, которая имеет ряд преимуществ перед обычной HTML версткой сайтов.
Фреймы используются для разбивки окна браузера на несколько областей, каждая из которых представляет собой отдельный HTML-документ (фрейм). Как правило, фреймы используются для облегчения навигации по сайту, создания навигационного меню. Тем не менее, большинство разработчиков избегают использования фреймов, поэтому в дальнейшем этот вид структуры сайта рассматриваться не будет.
Стоит также отметить, что существуют web-страницы, структура которых комбинирует в себе использование TABLE и DIV.
Таким образом, будем считать, что очищенная страница от информационного шума представляется в виде:
![]() , (1)
, (1)
где ![]() – функция очистки,
– функция очистки,
![]() – исходный сайт,
– исходный сайт,
![]() – вектор, который определяется набором следующих признаков.
– вектор, который определяется набором следующих признаков.
В пределах статьи будут рассматриваться следующие признаки вектора ![]()
![]() – количество изображений,
– количество изображений,
![]() –количество flash контента,
–количество flash контента,
![]() – количество гиперссылок ,
– количество гиперссылок ,
![]() –количество таких тегов как <ul>,<ol>,<li>.
–количество таких тегов как <ul>,<ol>,<li>.
Для каждого признака необходимо определить интервал значений, который будет считаться нормой. Отклонения за максимальную границу интервала будем принимать как признак информационного шума, который требует очистки.
Разработка алгоритма очистки от информационного шума
Приняв во внимание все сильные и слабые стороны существующих инструментальных средств, остановим свой выбор на идеи создания букмарклета.
Букмарклет(bookmarklet) – это javascript-код, который сохраняется как закладка в браузере. Он работает за счет использования протокола < a href="javascript:..." >.
Алгоритм очистки web-страниц от информационного шума состоит из следующих этапов:
- Букмарклет получает адрес страницы для ее обработки.
- Для заданной страницы определяется структура DOM дерева из HTML-кода.
- Происходит проход по DOM дереву и классификация тегов(узлов) по соответствующим признакам.
- Далее определяются значимые узлы.
- Система обрабатывает информационные блоки, выделяет блок основного контента, отсекая теги, помеченные как информационный шум (медиа, навигация, ссылки и прочее).
- Обработанная страница отображается для пользователя.
- В случае, если произошло отсечение важной информации, пользователь отменяет обработку. Страница отображается ему в первичном виде с рамками вокруг различных блоков контента. Отметив нужный блок, пользователь сохраняет результат. Страница вновь проходит обработку, в ходе которой отмеченные пользователем блоки отсекаться не будут. Обработанная страница отображается для пользователя вместе с сообщением, в котором будет предложено сохранить результаты обработки страницы в системе.
- Адрес обрабатываемой страницы и результаты ее обработки сохраняются.
Экспериментальное исследование определения значений параметров информационных блоков
Для выделения информационных блоков необходимо разработать средство позволяющее работать с html-кодом страницы непосредственно в окне браузера. Кроме этого для определения типа информационного блока необходимо рассчитать значения его параметров.
Для исследования был разработано специальное программное обеспечение – букмарклет, который выделяет div и table верхнего уровня, определяет количество заданных признаков в пределах структурного блока и по странице в целом. Набор исследуемых параметров определен в постановке задачи.
Исследование проводилось по следующей методике: для каждого из 10 поисковых запросов из разных областей было загружено по 20 первых веб-ресурсов, выданных поисковой системой Google. Каждая страница была проанализирована и разбита на структурные блоки (div и table верхнего уровня). Для каждого блока и для всей web-странице в целом было посчитано количество изображений, ссылок, списков и flash-объектов. В результате выше перечисленных действий было получена выборка, состоящая приблизительно из 500 записей. Пример использования букмарклета для проведения исследования показан на рис.2.
На основе вычисленных характеристик выделим границы каждого признака значения, внутри которых будет считаться нормой, а в случае отклонения от максимальной границы признак будет признан информационным шумом. Вычисленные значение приведем в табл.2.
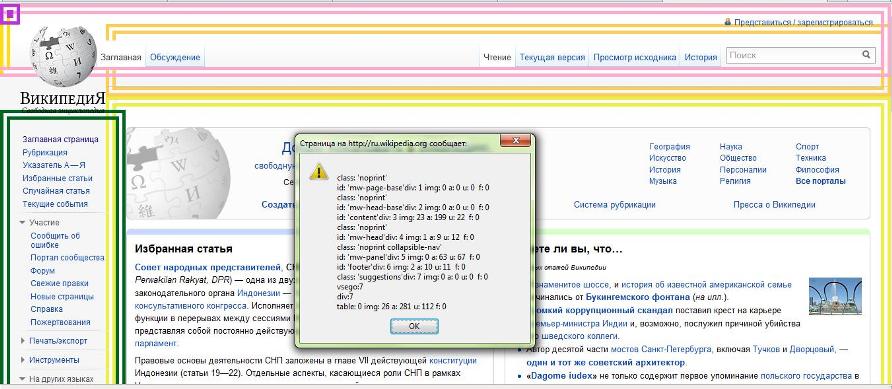
Рисунок 2 – Пример использования букмарклета
Таблица 2 – границы характерных признаков для различных типов сайтов
Тип сайта |
Признак информационного блока |
|||||
Количество изображений |
Количество ссылок |
Количество элементов списков |
Количество flash-объектов |
|||
min |
max |
min |
max |
max |
max |
|
Фотосайты |
12 |
195 |
22 |
1089 |
120 |
1 |
Видеосайты |
14 |
277 |
96 |
1177 |
336 |
4 |
Торренты |
12 |
120 |
88 |
1885 |
216 |
3 |
Поисковые модули |
1 |
71 |
27 |
270 |
213 |
1 |
Интернет магазины |
22 |
296 |
72 |
1005 |
838 |
4 |
Обычные сайты |
0 |
289 |
10 |
3218 |
320 |
2 |
Выводы
В статье рассмотрена проблема определения основного контента web-страницы, который будет полезен для пользователя. Предложены статические характеристики, в зависимости от которых будет определяться значимость информационных блоков, а так же определены специфические виды сайтов, для которых статические характеристики будут отличны от обычных web-страниц.
Литература
- И. Некрестьянов, Е. Павлова. Обнаружение структурного подобия HTML-документов. СПГУ, 2002. - С. 38 – 54. / Интернет-ресурс. – Режим доступа: www/ URL: http://meta.math.spbu.ru
- Р.Ф. Кузнецов, Н.В. Мурашов. Оценка влияния извлечения значимой информации на качество классификации web-страниц
- Soumen Chakrabarti. Integrating the Document Object Model // In Proceedings of WWW10, May 1-5, 2001, / Интернет-ресурс. – Режим доступа: www/ URL: http://www10.org/cdrom/papers/489
- Определение понятия «информационный шум» / Интернет-ресурс. – Режим доступа: www/ URL: http://mediart.ru/blog/kiberzhurnalistika/742-1-pered-viborami-kak-upravlyat-smi-chtobi-oni-ne-upravlyali-vami.html
- Краковецкий А. Очищаем веб-страницы от информационного шума / Интернет-ресурс. – Режим доступа: www/ URL: http://msug.vn.ua/Posts/Details/3333