
Мы представляем Cloud Haskell, доменно-специфический язык для разработки программ в окружении с распределенной памятью. Этот язык реализован как небольшое подмножество языка Haskell и предоставляет модель коммуникации, основанную на передаче сообщений, которая была инспирирована языком Erlang, с сохранением совместимости с широко используемой на сегодняшний день моделью конкурентности с разделяемой памятью. Основное достижение данной работы, это метод сериализации замыканий функции для передачи их по сети. Cloud Haskell был реализован; мы представляем примеры кода и некоторые измерения производительности.
Cloud Haskell – это доменно-специфический язык для облачных исчислений, реализованный как небольшое подмножество языка Haskell. Он предоставляет программисту модель исчисления, базирующуюся на модели передачи сообщений, заимствованной из Эрланга, но с дополнительными преимуществами, которые исходят из таких характеристик Хаскела как функциональная чистота, строгая типизация и монады.
Модель передачи сообщений, популяризованная Эрлангом для высокодоступных приложений реального времени и MPI для высокопроизводительных вычислений, предусматривает то, что конкурентные процессы не имеют доступа к данным других процессов: любые данные должны передаваться от одного процесса другому при помощи явно отправляемых сообщений. Мы выбрали эту модель т.к. она делает явной коммуникационную трудоемкость и потому, что она делает конкурентный процесс естественным блоком отказа: т.к. процессы не имеют разделяемых данных, то данные одного процесса не могут быть испорчены из-за сбоя в другом.
Мы используем термин “облако” для обозначения большого числа процессоров с отдельной памятью, объединенных сетью и имеющих независимые режимы сбоя. Мы не считаем, что модель конкурентности с разделяемой памятью является подходящей для программирования облака. Это основано на том, что эффективная модель программирования должна сопровождаться моделью стоимости вычислений. В системе с распределенной памятью, наиболее значительной затратой, как энергии так и времени, является перемещение данных. Программист, пытающийся сократить эти затраты, нуждается в модели, где эти затраты сделаны явными, а не в той, которая отрицает сам факт перемещения данных – что собственно говоря и является предпосылкой симулированной разделяемой памяти
Во многих отношениях, сбой является определяющим фактором распределенных вычислений. В сети из сотен компьютеров, некоторые из которых могут дать сбой в течении комплексного вычисления; если нашим единственным выбором в случае сбоя является перезапуск вычисления с самого начала, то вероятность его успешного завершения стремительно уменьшается при масштабировании системы. Таким образом, система программирования для облака должна иметь возможность допускать частичный сбой. Опять же, Эрланг обладает решением этой проблемы, которое выдержало тест временем; мы не производим инноваций в этой области, принимая решение из Эрланга.
Если Эрланг всегда был настолько успешным решением, вы можете задать вопрос о том, что же нового приносит Хаскелл. Если вкратце, то это: функциональная чистота, типы и монады. Как в чистом функциональном языке, данные являются по умолчанию неизменяемыми, так что отсутствие разделяемых и изменяемых данных не должно стать большой потерей. Важно отметить, что неизменяемость позволяет реализации принимать решение о разделении или копировании данных: этот выбор семантически невидим, и таким образом может зависеть от расположения процессов. Что еще более важно, чистые функции являются идемпотентными; это означает, что функции, выполняющиеся на сбоящем оборудовании могут быть перезапущены где угодно без нужды в распределенных транзакциях или других механизмах для “отмены” эффектов. Типы в общем, и монадические типы в частности, помогают статически гарантировать свойства программ. К примеру, функция имеющая внешне видимый эффект, такой как отправка или получение сообщения, не может иметь такой же тип, как чистая функция. Монадические типы делают удобным программирование в effectful-стиле тогда, когда это удобно, при этом гарантирую что программист не может случайно перепутать чистый код и генерирующий эффекты.
Достижения данной работы перечислены ниже:
Описание интерфейсных функций Cloud Haskell (секции 2, 3). Следуя за Эрлангом, наш язык предоставляет систему для обмена сообщениями между легковесными конкурентными процессами, независимо от того, запущены они на одном компьютере, или на нескольких. Мы также предоставляем функции для запуска новых удаленных процессов, и для толерантности к ошибкам, что близко к Эрлангу. Однако, в отличие от Эрланга, Cloud Haskell также позволяет конкурентность с разделяемой памятью внутри одного из процессов.
Дополнительный интерфейс для передачи сообщений, использующий несколько типизированных каналов вместо единственного безтипового канала в Эрланге. Каждый канал реализован как пара портов; в то время как порт отправки может передаваться по сети, порт-получатель не может. Мы считаем что такой интерфейс хорошо сочетается со статической типизацией Хаскелла.
Метод сериализации замыканий функций, который позволяет функциями высшего порядка использоваться в распределенном окружении. Запуск удаленного процесса означает отправку представления функции и ее окружения по сети; наш подход делает окружение функции явным, и таким образом дает программисту контроль над коммуникационной трудоемкостью.
Демонстрация эффективности нашего подхода в форме раализации и конкретного приложения -примера. Мы также предоставляем измерения производительности из алгоритма кластеризации k-means.
Мы начнем с обзора базовых элементов Cloud Haskell: процессов, сообщений, того, что может быть отправлено в сообщении и мер защиты от ошибок. Все элементы нашего доменно-специфического языка (DSL) представлены на рис. 2.
Базовой единицой конкурентности в Cloud Haskell является процесс: конкурентное действие которое было “наделено” способностью отправлять и получать сообщения. Как и в Эрланге, процессы являются легковесными, с низкой стоимостью создания и назначения планировщиком. Процессы идентифицируются уникальным идентификатором процесса, который может быть использован для отправки сообщений новому процессу.
В большинстве отношений, Cloud Haskell следует за моделью Эрланга предпочитая механизм передачи сообщений как основной способ коммуникации между процессами. Наш язык отличается от Эрланга тем, что он поддерживает конкурентность с разделяемой памятью внутри одного процесса. Все существующие элементы Concurrent Haskell, как Mvar для изменяемых переменных и forkIO для создания легковесных потоков, все еще доступны программистам, которые хотят комбинировать передачу сообщений и разделяемую память, что проиллюстрировано на рис. 1.
Рис. 1: Процессы A и B не
разделяют память, хотя они и запущены
на од ином физ. Процессоре, т.е., на одном
узле. Вместо этого они коммуницируют
путем пересылки сообщений, отображенных
серыми стрелками. Это позволяет легко
переконфигурировать приложение чтобы
воспроизводить ситуацию с процессами
C и D. Процесс E создает несколько
легковесных потоков используя примитив
forkIO из Concurrent Haskell; эти потоки разделяют
память с процессом Е и друг с другом.
Однако, они не могут отправлять или
принимать сообщения из каналов процесса
Е., потому что это предполагает выполнение
в монаде ProcessM; потоки при этом выполняются
в монаде IO.
Наше вложение в виде DSL гарантирует что механизмы, специфичные для схемы с разделяемой памятью не может быть ненароком использовано между удаленными системами. Ключевая идея, которая делает это разделение возможным это то, что не все типы данных могут быть отправлены в сообщениях; в частности, Mvarы и ThreadId не являются сериализуемыми.
Любой процесс может отправлять и получать сообщения. Сообщения являются асинхронными, надежными и буферизованными. Все состояние, ассоциированное с сообщениями ( в основном очередь сообщений), оборачивается в монаду ProcessM, которая обновляется с каждым действием обмена сообщениями. Таким образом, любой код участвующий в обмене сообщениями должен быть внутри монады ProcessM. Основные примитивы это send и expect:

Перед тем, как мы обсудим эти примитивы в деталях, давайте рассмотрим пример их использования. “ping” это процесс, который принимает сообщения “pong” и отвечает отправкой сообщения “ping” процессу, отправившему pong. Используя send и expect, код для процессов будет выглядеть примерно так:

Эквивалент на Эрланге выглядит так:

Эти две программы имеют сходную структуру. Обе функции ping спроектированы как процессы. Они обе ожидают получения специфического сообщения; функция expect из Хаскелл принимает сообщение по типу, в то время как в Эрланге сообщения обычно принимаются путем сопоставления с образцом с кортежами, первый элемент которых является хорошо известным атомом. Программы ожидают сообщения “pong” и игнорируют все другие. Сообщение “pong” содержит внутри себя ID процесса-”партнера”, которому отправляется сообщение ответа. Это сообщение содержит ID процесса ping (self). В конце концов, они ожидают сообщения next путем повторения при помощи хвостовой рекурсии.
Обратите внимание, что в версии Эрланга, Ping и Pong являются атомами, в то время как в Хаскелле это типы, и таким образом должны быть объявлены явно. Как указано, определения Ping и Pong не полны, т.к. они должны быть задекларированы как реализующие интерфейс Serializable.
Функция send является функцией отправки сообщения общего назначения; она упаковывает порцию сериализуемых данных произвольного типа как набор бит, вместе с представлением этого типа (TypeRep), и передает обе(возможно через сеть) определенному процессу, выбранному аргументом ProcessId. При получении, входящее сообщение будет размещено в очереди сообщений, ассоциированной с процессом-получателем. Функция отправки соответствует оператору ! Из Эрланг.
С другого конца, наиболее простым способом получения сообщения является ф-я expect, которая просматривает очередь сообщений конкретного процесса и выделяет первое сообщение, тип которого соответствует (вычисленному) типу expect – сообщению Ping в нашем примере. Реализация expect просматривает очередь в поиске сообщения с нужным представлением типа, вынимает это сообщение из очереди, парсит его в единицу данных нужного типа и возвращает. Если нет сообщения нужного типа в очереди, expect ожидает его прибытия.
Когда мы готворили, что передаваемые данные должны быть сериализуемыми, мы имели ввиду что каждый элемент должен быть Serializable. Это гарантирует два свойства: то, что он Binary и Typeable. Binary обозначает, что put и get -функции доступны для кодирования и декодирования единицы данных в бинарную форму и обратно; Typeable означает что функция typeOf может быть использована чтобы создать TypeRep для представления типа элемента.
Хотя все примитивные типы Хаскела и большинство общеиспользуемых высокоуровневых структур данных являются Serializable, и тем самым могут являться частью сообщения, некоторые типы данных специально не являются сериализуемыми. Ярким примером является Mvar, тип Хаскела для изменяемых переменных. Т.к. Mvar позволяют сообщение между потоками с разделяемой памятью, не имеет большого смысла отправлять их удаленному процессу, который может не разделять память с текущим процессом. Хотя можно представить синхронную распределенную переменную, которая мимицирует семантику Mvar, такая переменная будет иметь совсем другую стоимостную модель, отличную от нормальной Mvar. Хотя ни стоимостная модель Мвар, ни ее реализация не могут быть сохранены в окружении, требующем коммуникацию между удаленными системами, мы запрещаем программистам использовать Mvar таким образом. Хотя отметим, что ничего не запрещает использования их внутри одного процесса: процессам позволено создавать локальные потоки при помощи forkIO. То же самое верно и для Tvar: тот факт что они не сериализуемы гарантирует что транзакции STM не пересекают процессов, но программисту можно использовать STM внутри процесса. К слову сказать, наша реализация использует STM для защиты очереди сообщений.
Для старта нового процесса в распределенной системе, необходим путь для указания того, где будет запущен процесс. Вопрос местоположения адресуется понятием узла. Узел может быть рассмотрен как независимое адресное пространство. Каждый узел идентифицируется при помощи NodeId, уникального идентификатора который содержит ip-адрес для связи с узлом. Таким образом, чтобы стартовать процесс нам необходима функция spawn которая принимает 2 параметра: NodeId, определяющий узел где будет выполняться процесс и некоторое выражение – код для выполнения. Т.к. Мы хотим чтобы код мог принимать сообщения, он должен быть обернут в монаду ProcessM. Функция spawn должна возвращать ProcessId, который в дальнейшем будет использован для отправки сообщения. Т.к. Spawn будет сама зависеть от обмена сообщениями, то эта функция тоже будет внутри монады ProcessM. Таким образом, ее тип будет выглядеть так:
![]()
В комбинации с ping и pong, spawn может использоваться так:

Этот код должен стартовать два новых процесса, размещенных на узлах someNode и otherNode, каждый из которых ожидает прибытия сообщений определенного типа. Для начала обмена, мы отправляем сообщение Pong процессу ping.
В Cloud Haskell настоящий тип spawn такой:
![]()
Разница между этим типом и нашим первоначальным определением в том, что второй аргумент это Closure (ProcessM ()) вместо простого ProcessM. Сериализация функции означает сериализацию двух вещей: представления ее кода, и представления ее окружения – более точно, байндингов ее свободных имен. Closure является как раз этим, но детали замыканий на удивление сложны.
Базовый обмен сообщениями:

Каналы:
Расширенный обмен сообщениями:

Управление процессами:

Отказоустойчивость в Cloud Haskell основана на идеях из Эрланга. Предпосылка отказоустойчивости в стиле Эрланга является такой, что когда что-либо происходит не так внутри процесса, лучшим выходом для процесса является его остановка; попытки восстановиться из этого состояния при помощи разных сложных действий обычно не приводят к надежности. Вместо этого, другой процесс должен перенимать функции остановленного. Для осуществления такого поведения, один процесс может мониторить другой; если наблюдаемый процесс останавливается, то процесс-монитор получает уведомление. Констатация истоков ошибки и восстановление после нее оставляются приложению или более высокоуровневому фреймворку.
Процесс может запросить уведомления о событии остановки другого процесса, по какой-либо причине, или только в случае ошибки, включающей в себя останавливающийся процесс. Примерами таких ошибок являются необработанные исключения, и недоступность узлана котором запущен процесс. Уведомления могут доставляться двумя путями: как асинхронные исключения, которые могут быть обработаны обычными средствами Хаскелла; или по сообщению, которое получается как любое другое сообщение.
Функции для установления мониторинга:

monitorProcess a b ma устанавливает однонаправленный мониторинг процесса. Т.е., процесс а будет уведомлен если процесс b остановится. Третий аргумент определяет будет ли процесс-монитор уведомлен исключением или сообщением.
LinkProcess соответствует функции link из Эрланга. Она устанавливает двунаправленный мониторинг между текущим процессом и данным процессом; если какой-либо из этих процессов завершится некорректно, то другой получит асинхронное исключение. LinkProcess объеявлен в терминах monitorprocess.
В секции 2.2, мы ввели функцию expect, которая позволяет нам получать сообщения определенного типа. Но что если наш процесс желает иметь возможность принимать сообщения многих типов? В идеале, мы хотели бы апроксимировать синтакс ф-и receive из Эрланга:

Этот код примет и ответит на несколько разных сообщений. Он делает это путем сопоставления с образцом на значениях сообщений, которые (по конвенции) являются кортежами. Каждый паттерн имеет соответствующее действие-обработчик. Строка 3 пытается принять кортеж, содержащий атом add , ID процесса, и два числа; когда находится сообщение такой формы, она вызовет заданный обработчик в строке 4, который вернет сумму двух чисел. В следующем паттерне, на строке 5, код отвечает на сообщение атомом divide, но только если делитель ненулевой; это контролируется синтаксисом when. В конце, третий паттерн(строка 7) отправит обратно атом div_by_zero, в ответ на все сообщения не обработанные предыдущими паттернами, что возникает при нулевом делителе. Паттерны проверяются для каждого сообщения в порядке их определения, так что последний паттерн достигается только при провале двух предыдущих.
Хаскелл не имеет типа данных атома, но идиоматическим способом представления различных сообщений является использование конструкторов типов. Представьте процесс, который должен иметь возможность выполнять математические операц ии удаленно, и должен уметь отвечать на два типа запросов: Add pid a b и Divide pid num den. Ответ должен быть отправлен обратно либо как значение Answer Double либо как DivByZero (сообщение об ошибке). Однозначно возможно создать тип сообщения, который будет представлять собой сумму все этих вариантов, применимый для использования в expect:

СуществуетЕсть
несколько проблем с использованием
суммы типа MathOp.
Помните, что ожидать
можно только выбора сообщения по
типам.Таким образом, процесс получения
MathOps сообщения должны быть в состоянии
повторно ответить на все варианты, даже
на те, которые не имеют смысла: по-видимому,
только процессы, клиент должен получить
ответ и DivByZero в то время как только
процесс расчета должны получать Add и
Divide. Тем более, упаковав все сообщения
в один тип сумму перерывы модульность
подвергая
Подробная информация о расчете процесса
клиента, когда мы добавим новые
математические операции, каждому клиенту
будет необходимо свой код, даже если
он не использует эту операцию.Хуже того,
один процесс, который предлагает больше,
чем одну службу не может держать их
отдельно; клиенты каждого из них будут
обязаны видеть интерфейсы обоих.
Чтобы избежать такого типа ложной зависимости между тем что должно быть отдельными модулями, лучше разбить одну MathOp на несколько типов, каждый из которых будет обрабатываться отдельно. Можно сделать три типа сообщений:

В добавок к определенным выше типам, ответ может быть отправлен клиенту просто как сообщение типа Double без оборачивания. Но теперь мы имеем другое затруднение: хотя expect может принимать любой тип сообщений, он может принимать только один тип сообщения за раз, и будет блокироваться до тех пор, пока сообщение нужного типа не попадет в очередь. Таким образом невозможно обработать определенные выше типы сообщений если мы не знаем очередности их прибытия. То что нам нужно, так это альтернатива выбору сообщения из Эрланга.
Как возможно реализовать многопутевой выбор в Хаскел? Во-первых, представим как обозначать пару, состоящую из типа сообщения и его соответствующего действия. Мы вводим match, который принимает обработчик сообщения параметром:
![]()
Когда match проверяет входящее сообщение, он сравнивает тип сообщения с типом а, параметром обработчика сообщения. Любое сообщение этого типа будет “выбранным”: оно будет удалено из очереди сообщения и передано обработчику.
Match является монадой MatchM, которя отвечает за предоставление match вместе с текущим состоянием очереди сообщений, и затем предоставляя вызывающему match результата теста. Match обычно используется с receiveWait, повторяющей receive из Эрланга.
![]()
Следующим шагом является объявление when из Эрланга, который позволяет сообщению быть протестированным предикатом. Эту функцию выполняет matchIf, первый параметр которой является предикатом, который тестирует сообщение без удаления его из очереди:
![]()
Теперь давайте использовать
эти инструменты для реализации математические
функции в
Haskell. Обратите внимание,
что шаблоны от версии Erlang на
стр. 4 были заменены на аргументы,
которые соответствуют лямбда-функции.

Комбинация receivewait и match соответствует синтаксису receive из Эрланга. MatchM проверяются по порядку для каждого сообщения в очереди. Когда получено совпадение, соответствующая лямбда-функция вызывается.
Обратите внимание,
что согласование на тип сообщения
не совсем то же самое
как
соответствующие сообщением значение. Например,
если частности матча
принимает
сообщения от определенного типа,
то все варианты этого типа
должны быть обработаны. В приведенном
выше примере, это нормально, потому
что Add типа имеет только один вариант,
построенный с помощью конструктора
Add.
Если вместо этого были суммы типа с второй
конструктор, то матч вызова,
что имеет дело только
с конструктором Add повысит
Исключение шаблону, если сообщение
с другими конструкторами получено
не было.
Очевидно что receivewait более гибкий чем expect. Кстати говоря, expect реализован в терминах receivewait:
![]()
При использовании receivewait или expect имеется риск того, что ф-я заблокируется при получении определенного типа сообщения. Что если нам необходим обработать очередь входящих сообщений, но не ожидать вечно? Эрланг позволяет делать это при помощи receive...after:

Этот код будет ожидать максимум 50 секунд для получения ответа на свой запрос; по истечении этого времени, он перестанет ожидать и отобразит ошибку. Соотвествующая функция в Cloud Haskell это receiveTimeout , очень похожая на receiveWait. Как и ReceiveWait, она принимает список паттернов, но также и принимает значение таймаута. Если таймаут истек, то функция возвращает Nothing.
![]()
Таким образом пример из Эрланга может быть транслирован в Хаскел так:

Как и в случае receive...after из Эрланга, receivetimeout может вызываться с таймаутом= 0, который имеет эффект проверки соответствующего сообщения и немедленного возврата если совпадение не найдено.
В предыдущем разделе мы показали как сообщение может быть отправлено процессу. Как можно видеть из типа send, любая сериализуемая структура данных может быть отправлена как сообщение любому процессу. Будет ли принято сообщение или нет (т.е. вытащено из очереди) процессом-получателем не определено до момента выполнения. Но что насчет строгой типизации Хаскела? Наверное, было бы неплохо иметь некоторые статические гарантии что сообщения будут отправлены получателям, которые могут их обработать.
Чтобы гарантировать это, мы предоставляем распределенные типизированные каналы как альтернативный способ отправки сообщения процессу напрямую. Каждый канал состоит из двух портов, порта-получателя и порта-отправителя. Сообщения вставляются через порт-отправитель, и вытаскиваются в порядке FIFO из порта-получателя. В отличии от идентификаторов процессов, каналы создаются с конкретным типом: порт-отправитель будет принимать только сообщения этого типа и следовательно предлагает сообщения только того типа.
Основные функции интерфейса каналов:

Критичным моментом является то, что SendPort хотя и может быть сериализован и скопирован на другие узлы, позволяя каналу принять данные из нескольких источников, то ReceivePort несериализуем и таким образом не может быть перемещен между узлами. Это ограничение устанавливается тем, что SendPort реализует Serializable, в то время как ReceivePort нет. Этот выбор был сделан во время проектирования; как следствие, порты-получатели в Хаскеле больше похожи на идентификаторы процессов в Эрланге или TCP-порты чем на на права получения(receive rights) в ядрах ОС Accent или Mach. Это решение отражает предполагаемую среду исполнения, в которой мы ожидаем использования каналов для коммуникации через сеть. Эта способность, предлагаемая ядром Mach, для перемещения порта-получателя из одного места в другое может быть очень полезна для перемещения ответственности с одного провайдера на другой, но только если это производится без риска потери потери сообщений в процессе передачи. Этого несложно добиться в ядре Mach, но намного сложнее в распределенной среде, особенно когда основная причина перемещения сервиса на новый сервер это поломка старого сервера.
Следующим шагом мы можем реформулировать наш пример с ping чтобы он использовал типизированные каналы. Процесс ping получает два порта: порт-получатель для отправления пингов и порт-отправитель для отправления понгов. Каждое сообщение теперь содержит порт-отправитель на который получатель должен ответить; т.о. Сообщение Ping содержит порт-получатель, и наоборот.

Существует аналогия между функцией expect и ее аналогом, основанным на каналах, receiveChan: обе функции получают сообщение определенного типа. Основанным на каналах аналогом receiveWait является семейство функций mergePorts., которые позволяют нам получать сообщение из одного из нескольких каналов.

Принимая в качестве аргумента список ReceivePort с одинаковым типом сообщений, эти функции вернут новый ReceivePort который при чтении с помощью receiveChan, предоставят сообщение принятое из одного из портов. MergePorts можно визуализировать , как принимающие несколько портов-фидеров и сворачивают их в один “общий” порт. Даже после получение слитого ReceivePort, оригинальные порты могут работать независимо как обычно. Сообщения получаемы из общего порта вытаскиваются из очереди конкретного порта и таким образом невозможно получить одно сообщение дважды.
MergePortsBiased и mergePortsRR отличаются порядком опроса входящих портов, что важно в случае когда более чем один порт имеет ожидание сообщений. Каждое последующее чтение из порта, созданного при помощи mergePortsBiased и таким образом общий порт “предпочитает” первый порт-фидер. Таким образом, если первый порт-фидер всегда ожидает сообщения, это может не дать другим портам получить сообщение.
Если такое поведение нежелательно, то можно использовать mergePortsRR. Порт создаваемый при помощи mergePortsRR. Будет производить ротацию в порядке опроса на каждом следующем чтении. Эффект является более “честным” чем round-robin мультипликация, что гарантирует то свойство, что при достаточном количестве чтений из общего порта, каждый порт-фидер получит шанс принять сообщение из своей очереди.
Cloud Haskell также предоставляет семейство функций combinePorts, которое служит для объединения портов разного типа, но они не обсуждаются в этой статье.
Как мы показали в секции 2.4, вопрос того как передавать замыкания функций от одного узла другому является фундаментальным. Он должен быть решен любой распределенной реализацией статически-типизированного, высокоуровневого языка программирования. Чтобы убедиться в том, насколько важным является этот вопрос, рассмотрим sendFunc, которая создает анонимную функцию и отправляет ее по каналу:
![]()
Обратим внимание что лямбда-функция отправляемая по каналу является замыканием, которое захватывает свободные переменные, в данном случае x. В общем случае, для сериализации функции требует также сериализации ее свободных переменных. Однако, типы этих свободных переменных не имеют отношения к типу самого значения функции, так что целиком неясно как сериализовать их.
Чтобы понять глубже эту проблему, давайте отвлечемся и рассмотрим проблему определения эквивалентности списков.
![]()
Это определение говорит, что если Eq a верно , мы можем сделать Eq a верным. Eq a означает что оператор эквивалентности == определен на типе a. Аналогично, Eq [a] означает что оператор эквивалентности определен на [a]: вторая строка в примере определяет это. Этот подход работает т.к. эквивалентность является структурным свойством типов: мы знаем что мы можем определенить эквивалентность списка при наличии свойства эквивалентности его элементов.
Теперь давайте вернемся обратно: к определению сериализуемости функции. Мы можем написать следующее:
![]()
но это не может быть выражено, и для этого есть хорошая причина: сериализуемость функции не является структурным свойством этой функции, т.к. точка зрения Хаскела на функцию является сугубо расширяющей. Другими словами, все что мы можем сделать с функцией, это применить ее; мы не можем произвести интроспекцию ее внутренней структуры.
Нельзя сказать что функции просто не являются сериализуемыми, т.к. любая реализация spawn должна иметь возможность определить функцию для удаленного запуска. К примеру, рассмотрим задачу создания нового удаленного процесса:

Вторым аргументом spawn является код который мы хотим запустить на удаленном узле, который является значением замкнутым на его свободные переменные, s, которые завязаны на SendPort на который удаленный процесс должен отправить ответ. Таким образом сериализация этого аргумента требует сериализации функции со свободной переменной. Мы можем избежать этой проблемы, т.к. самой сущностью распределенных исчислений является предоставление функции типа spawn которая стартует удаленное вычисление; в языке высшего порядка как Хаскел, это должно неотвратимо решать задачу сериализации замыкания какого-либо типа.
Одним из решений проблемы является реализация сериализации функциональных значений – и всех значений на самом деле – как примитивной операции, встроенной непосредственно рантаймом. Таким образом, рантайм позволяет сериализовать любое значение и передать его получателю по сети. При таком подходе, замыкания могут быть сериализованы путем сериализации их свободных переменных и добавлением к этому представления их кода. Этот подход используется каждым из распределенных языков высшего порядка, которые нам известны. Однако, встроенная сериализуемость имеет ряд недостатков:
она полагается на единственное встроенное понятие сериализуемости. Для сравнения, тип Serializable дает программисту контроль на тем как сериализуются значения. Для примера, структура данных может иметь избыточную информацию типа кеша, которая должна быть реконструирована на приемнике, вместо сериализации. Это непосредственная область прим енения классов типов!
Критичной является несериализуемость некоторых типов. К примеру, мы не хотим чтобы порт-получатель каналов был сериализуем, так чтобы отправители знали куда отправлять сообщения. Похожим образом, несериализуемые Tvar дают гарантии что транзакции STM не пересекают процесов
Сериализация значение и отправка его по с ети имеет важный эффект на стоимостную модель
В объектно-ориентированном мире, Java RMI также имеет сложный механизм сериализации. Java RMI требует от программиста явного указания того, какие объекты являются сериализуемыми, но прогрммист не должен явно писать методы сериализации полей объекта: этим занимается реализация самого языка. Однако, Java RMI также использует интроспекцию чтобы предоставить программисту контроль над тем, какие именно поля сериализуются и точной формой представления данных. Он также позволяет программисту управлять всем процессом сериализации путем реализации интерфейса Externalizable, который означает реализацию writeExternal и readExternal вручную. Как следствие, Java RMI избегает трех недостатков, обозначенных выше, в то же время автоматизируя сериализацию простых объектов.
Для десериализации, тем не менее, подход Java зависит от среды исполнения чтобы получить представление типа и найти десериализатор этого типа. У Хаскела такая возможность отсутствует, так что эта опция закрыта для нас. Однако, как означено выше, встраивание сериализации каждого значения не самый лучший инструмент. Предложение механизма сериализации для языка без рефлексии является одним из главных достижений этой работы.
Мы начинаем с простого наблюдения: некоторые функции могут быть быстро переданы получателю, в частности функции не имеющие свободных переменных. На настоящий момент мы упрощаем задачу тем, что считаем что каждый узел имеет одинаковый код. Исходя из этого предположения, замыкание без свободных переменных может быть сериализовано единственным символическим адресом(меткой).
Чтобы разделать значения которые могут быть сериализованы от тех, которые не могут, мы вводим новый конструктор типа (Static) для классификации таких значений. Этот конструктор является новым встроенным примитивом и инстансом Serializable.
Полезным является запомнить следующее правило:определяющим свойством значения типа Static t является то, что оно может быть сериализовано, и более того, оно может быть сериализовано без знания t. Реализация сериализует Static значение вначале вычисляя ег о, затем сериализуя метку в коде для результата вычисления. Возможно удивительно, но это работает не только для функций, но также и для значений данных типа Static Tree. Для этих мы просто статичеки выделяем переменную Tree и передаем метку его корня.
Вместе с новым конструктором типов мы вводим новые термины: ( static e) для нового типа, и (unstatic e) для его удаления. Решение о типизации для этих термов дается на рис. 3. Типовое окружение Г является множеством свободных переменных:

Вкратце:
Переменная является S-bound если она определена на верхнем уровне;
терм (static e) имеет тип (Static t) если е имеет тип t, и только если свободные переменные в е являтся S-bound.
Хотя они и простые, но эти правила имеют некоторые интересные последствия:
Переменная с
S-байндингом может иметь тип не-Static.
Рассмотрим байндинг верхнего уровня
для id: /![]() .
Т.к. Ф-я id является функцией верхнего
уровня, ее байндинг в Г будет иметь =
S, другими словами id имеет не-статический
тип id: s a->a. Однако, (Static id) имеет тип
(Static (a → a)) .
.
Т.к. Ф-я id является функцией верхнего
уровня, ее байндинг в Г будет иметь =
S, другими словами id имеет не-статический
тип id: s a->a. Однако, (Static id) имеет тип
(Static (a → a)) .
Переменная с байндингом D может иметь тип Static. К примеру:
![]() .
В этом примере, x является лямбда-байндингом
и таким образом имеет D-байндинг, но x
определнно имеет тип Static. Таким образом
полностью динамические функции могут
вычислять значения типа Static
.
В этом примере, x является лямбда-байндингом
и таким образом имеет D-байндинг, но x
определнно имеет тип Static. Таким образом
полностью динамические функции могут
вычислять значения типа Static
Свободные переменные
терма (static e) не должны иметь типы Static.
К примеру, этот терм правильно
типизирован:![]()
В примерах sendFunc и newWorker(введенных вначале этой секции) мы хотели передать замыкания которые явно не имели свободных переменных. Как статические термы могут в этом помочь? Они помогают тем, что делают возможной конверсию замыканий. Замыкание является просто парой содержащей указатель на код и окружение. При помощи Static термов мы можем попытаться представить замыкание напрямую в Хаскеле:
![]()
MkClosure принимает 2 аргумента: Static функцию и окружение какого-либо типа env. Тот факт что тип окружения неизвестен означает что два замыкания с одинаковым типом неотвратимо захватывают окружения с различными типами. Для примера, рассмотрим список замыканий:

Оба замыкания в списке имеют один тип, Closure Int, но первое захватывает Int как его окружение, в то время как второе захватывает Char.
Этот тип замыкания все еще несериализуем, т.к. env несериализуем. Это кажется легкой задачей, если сделать окружение сериализуемым:

Теперь сериализация проста:
![]()
Но как мы можем десериализовать замыкание? Сложность в том, что на получателе мы не знаем как тип захвачен внутри замыкания, и таким образом не знаем какой десериализатор использовать. Это изначально представляется странной проблемой. Возможно, мы должны отправить представление типа окружения и сделать проверку в рантайме? Это требует решения проблемы сериализации замыканий.
Однако к счастью ест ь простое и очевидное решение: осуществлять и сериализацию и десериализацию во время создания замыкания.. Другими словами мы освобождаемся от экзистенциальной квантификации, и просто требуем от окружения чтобы оно было ByteString:
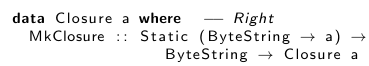
Хотя это может звучать устрашающе, это полностью общее решение, т.к. любое сериализуемое окружение сопровождается функциями encode и decode которые будут выполнять конвертацию в Bytesting.
Легко использовать конверсию замыкания unclosure:
![]()
Десериализация окружения производится внутри unclosure. Для замыкания на функции имеет смысл применять unclosure единожды, и применять результирующую функцию много раз.
Чтобы увидеть замыкания в действии, есть наш пример с sendFunc, выраженный при помощи замыканий:


Тип элементов который может быть отправлен в порт p теперь (Closure (Int → Int)). Вместо отправки простого лямбда-выражения в p, мы отправляем clo, замыкание содержащее пресериализованное окружение encode x, и статическую функцию sfun. Последнее десериализует его аргумент bs чтобы получить настоящее окружение x.
Теперь рассмотрим пример с newWorker. При использовании замыканий он выглядит так:

Тип spawn дан на рис. 2; он принимает замыкание вторым аргументом.
В этой секции мы ввели простой набор примитивов языка:
новый конструктор типов Static
новые терм в виде (static e)
новая примитивная функция unstatic
На этих примитивав основывается то, что мы можем вручную конструировать замыкания. Осуществление ручной конверсии является сложной для программиста задачей, и возможно стоит добавить немного синтаксического сахара для этого.
Static еще не был реализован в GHC, но мы реализовали некоторые несложные обходные пути чтобы позволить нам поэксперементировать с замыкания без изменения GHC.
Далее дан код для sendFunc используя эти обходные пути; мы будем использовать это как запущенный пример.

Программисту все еще необходимо производить конверсию замыканий вручную, путем объявления функции верхнего уровня (add1 в этом случае) первый аргумент которой является окружением. Однако это код гораздо более понятен чем код из секции 5.4.
Template Haskell splice $(mkClosure 'add1) запускается во время компиляции. Аргумент 'add1 в нотации Template Haskell для квотированного имени функции add1. MkClosure оперирует именами функций.
![]()
![]() .
.
Что ест ьadd1__closure? Это новая функция верхнего уровня возданная при помощи splice $(remotable ['add1]).
![]()
Это раскладывается на следующие определения:

Следующим шагом давайте рассмотрим как работают эти определения.
Мы иммитируем тип Static при помощи строки, которая служит меткой для функции чтобы вызвать ее в удаленном процессе.
![]()
Мы держим таблицу в монаде ProcessM которая проецирует эти строки на необходимую реализацию , собранную из десериализатора окружения, в нашем случае add1__dec. Эта таблица инициализируется вызовом к runRemote инициализирующим монаду ProcessM. Эта таблица может использоваться из монады:

Функция lookupStatic находит определение функции в таблице и производит проверку типа для гарантирования того что значение, возвращаемое ф-й имеет тип, ожидаемый вызывающим контекстом. Наша реализация статических типов является typesafe, просто проверки перекладываются на рантайм.
Однако, программист обязан делать следующее:
В каждом модуле необходим один вызов к $(remotable […]) с именами всех функций-аргументов mkClosure.
В вызове runRemote передается список всех определений __remoteTable, импортированных из каждого модуля с этим вызовом..
В конце, процесс развертки замыкания становится монадическим, что немного менее удобно программисту:

Cloud Haskell был протестирован с новыми версиями GHC. Код развивается быстро, текущая версия доступна на github.com. Некоторые функции реализации:
Процессы основаны на легковесных потоках Concurrent Haskell. Низкая инкрементальная стоимость запуска потоков важна, т.к. единичный узел может поддерживать сотни процессов, и процессы могут часто стартовать и завершаться.
Семейство функций mergePorts было довольно сложным для реализации. Было бы просто, но в то же время неверно стартовать отдельные треды для вызова receiveChan на нескольких ReceivePorts, что может вызвать состояние гонки(рейса). Представьте что может произойти если сообщения будут получаться конкурентно на двух портах и забираться конкурентно двумя потоками. Только одно из сообщений может быть возвращено; т.к. не существует пути чтобы отправить сообщение в очередь в той позиции, в которой оно было доэтого.
T emplate Haskell был использован для написания функций mkClosure и remotable, который автогенерирует код для вызова удаленных функций, как описано в разлделе 6.
У Эрланга есть замечательное свойство которое позволяет программным модулям обновляться на лету. Таким образом, когда выходит новая версия кода, он может быть передан каждому хосту в сети , где он обновит старую версию кода, без необходимости перезапуска системы. Мы решили не идти в этом направлении, отчасти из-за того что обнровление кода является проблемой которая может быть отделена от других аспектов построения распределенной системы., и из-за того что она сложно решается. Сложность особенно видна в случае Хаскела, который компилирует программы в машинный код и исполняет их при помощи ОС, в то время как интерпретатор Эрланга дает больше контроля над выполнением программ.
Т.к. Мы не реализоваывали динамическое обновление кода, Cloud Haskell код должен быть распространяться между удаленными хостами “без очереди”. В нашем окружении для разработки, это обычно делалось при помощи scp и подобного. Что еще более важно, это представляет программисту ответственность за то, чтобы все хосты имели одну и ту же версию исполняемого файла. Т.к. TypeReps является сугубо номинальными, и т.к. мы не хотим на уровне платформы проверять несовместимость типов, отправка сообщений между исполняемыми файлами которое использует одинаковое имя для обращения к разным типам с разной структурой что скорее всего даст ошибку десериализации.