Введение
в разработку с использованием CUDA
Титаренко
К. К.
Примечания
Материал, предоставляемый в ходе
презентации, служит, прежде всего, для обеспечения необходимой базы для
рассмотрения приведенных ниже практических примеров.
Таким образом, к примеру, разделы
«Квалификаторы типа функции» или «Функции мультипроцессора» излагаются в
объеме, необходимом для приведенных выше целей, но не являются исчерпывающим
описанием, которое, при необходимости, может быть найдено в фирменной документации.
Подготовка к разработке
Инструменты разработчика,
установка, настройка, сборка примеров из SDK, создание
проекта
Ссылки
— CUDA Driver,
CUDA Toolkit, CUDA SDK
http://www.nvidia.com/object/cuda_get.html
—
Visual Studio (как
вариант при разработке в ОС Windows) http://www.microsoft.com/exPress/
—
CUDA VS
Wizard (опционально) http://sourceforge.net/projects/cudavswizard/
Модель программирования
Ядро, иерархия потоков, иерархия
памяти, стек программного обеспечения CUDA,
вычислительная способность
Ядро (kernel)
—
C-функция, исполняемая N раз
параллельно N-ю разными CUDA-потоками
—
Определяется с помощью спецификатора __global__
—
Вызывается с применением <<<…>>>-синтаксиса
Иллюстрации


Идентификатор потока
—
Каждый поток, исполняющий ядро, наделяется
уникальным идентификатором thread ID
—
Этот идентификатор доступен из ядра через
встроенную переменную threadIdx
Иллюстрация

Иерархия потоков
—
Потоки группируются в 1-, 2- или 3-мерные блоки, идентификация с
помощью threadIdx.{x|y|z}
—
Размер блока доступен из ядра через встроенную переменную
blockDim.{x|y|z}
—
Блоки группируются в 1- или 2-мерную сеть, идентификация с
помощью blockIdx.{x|y}
—
Размер сети доступен из ядра через встроенную переменную gridDim.{x|y}
Иллюстрация

Некоторые особенности
—
Блоки, составляющие сеть, исполняются в любом порядке,
параллельно или последовательно (это зависит от конфигурации ядра и
возможностей оборудования)
—
Параметры конфигурации ядра (размеры сети и блоков)
обычно диктуются не количеством процессоров в системе, а размерностью решаемой
задачи
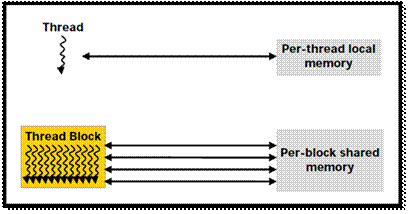
Иерархия памяти
— Каждый
поток обладает собственной локальной памятью (private
local memory)
—
Потоки, принадлежащие одному блоку, имеют доступ к разделяемой памяти (shared
memory), время существования которой совпадает с временем существования
блока
—
Любому потоку доступна глобальная память (global
memory)
Иллюстрации

Неизменяемая (read-only) память
— Константная память (constant
memory) – кэшируется
—
Текстурная память (texture memory) –
кэшируется, поддерживает разные режимы адресации, фильтрацию данных
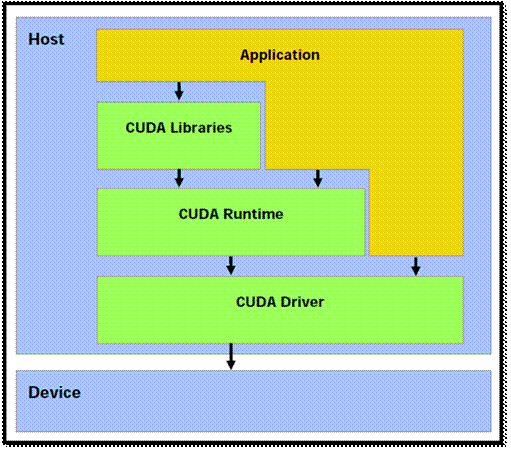
Стек ПО CUDA
Вычислительная способность
—
Вычислительная способность (compute
capability – CC) определяется старшим и младшим
номерами ревизии
—
Старший номер определяет версию архитектуры
—
Младший – указывает на инкрементальные улучшения
—
Технические спецификации CC могут
быть найдены в документации к SDK
Аппаратная реализация
Архитектура Tesla,
структура мультипроцессора, функции мультипроцессора, система с несколькими GPU
Архитектура Tesla
—
Представлена компанией NVIDIA
в ноябре 2006
—
Предназначена как для графических, так и неграфических
вычислений общего назначения
—
Построена на масштабируемом массиве мультипроцессоров
—
Занимает широкий сегмент рынка – от высокопроизводительных GeForce 2xx
и профессиональных Tesla и Quadro до
недорогих широко распространенных GeForce 8xxx/9xxx.
Структура мультипроцессора
—
8 скалярных ядер
—
2 специальных блока для вычисления трансцендентных функций
—
Встроенная в кристалл разделяемая память (on-chip
shared memory)
—
Блок выдачи инструкций
—
Текстурный и константный кэш
Функции мультипроцессора
—
Создание, управление, выполнение параллельных потоков с нулевыми
накладными затратами на планирование
—
Работа с потоками осуществляется группами, называемыми warps (в
данных условиях 32 потока)
—
Реализация интринзик-функции барьерной синхронизации __syncthreads() одной
инструкцией
Иллюстрация

Система с несколькими GPU
—
Использование нескольких GPU
в качестве CUDA-устройств
в системе с множеством GPU возможно в случае, если
это устройства одного типа
—
SLI режим должен быть отключен
Интерфейс программирования
Набор расширений к языку C,
квалификаторы типа функции, квалификаторы типа переменной, конфигурация ядра,
элементы Runtime API
Набор расширений к языку C
—
Квалификаторы типа функции
—
Квалификаторы типа переменной
—
Синтаксис конфигурации ядра (<<<…>>>)
—
4 встроенных переменных (gridDim, blockDim, blockIdx, threadIdx)
Квалификаторы типа функции
—
__device__ –
встраиваемая (inline) функция, выполняемая на устройстве; рекурсия запрещена,
статические переменные запрещены
—
__global__ – ядро,
выполняемое устройством; рекурсия запрещена, статические переменные запрещены;
возвращаемый тип – только void, при
вызове требует указания конфигурации
Квалификаторы типа переменной
—
__shared__ – переменная
находится в разделяемой памяти блока потоков, время существования совпадает с
временем существования блока, видима потокам только данного блока
—
__constant__ –
переменная находится в константной памяти, время существования совпадает с
временем существования приложения, видима всем потокам
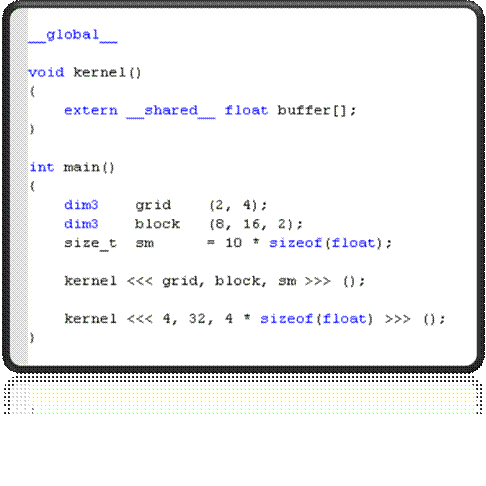
Конфигурация ядра
—
<<<grid, block,
shmem>>>
—
grid – задает размеры сети в блоках
—
block – задает размеры блока в потоках
—
shmem – задает размер динамической разделяемой памяти в байтах
(опционально, по умолчанию 0)
Иллюстрация
Элементы Runtime API
—
Управление линейной памятью: cudaMalloc, cudaMemcpy, cudaFree
— Управление
массивами: cudaMallocArray, cudaMemcpyToArray, cudaFreeArray
—
Управление текстурами: cudaBindTextureToArray,
cudaUnbindTexture
Практическая часть
Иллюстрация нескольких подходов к
разработке и оптимизации на примере задачи решения СЛАУ с использованием
нейронной сети
Подробно прокомментированный
исходный код всех примеров может быть получен из репозитория:
http://svn6.assembla.com/svn/cnnslaes/trunk
Постановка задачи
—
Дана СЛАУ Ax = b
размерностью n, где A
– квадратная матрица коэффициентов, x
– вектор неизвестных, b
– вектор свободных членов
—
Реализовать приложение, решающее данную СЛАУ, используя следующий
итерационный метод:
x[0] = {0, 0…, 0}
y[k] = f(Ax[k] - b)
x[k+1] = x[k] - 2hATy[k], где
k – номер итерации;
x[k] – вектор
неизвестных на k-й
итерации;
f(x) – вектор-функция,
компонент результата которой вычисляется по правилу: f[i](x) = x[i], если
|x[i]| >
Epsilon, f[i](x) = 0,
иначе;
h – параметр итерационного процесса;
AT – транспонированная матрица A
Выделение функциональных
блоков
•
Вычисление вектора Y на k-й
итерации (функция нейронной сети)
•
Вычисление очередного приближения вектора неизвестных X (блок
настройки)
Распределение задачи по
потокам
—
Блок А: один поток – одна компонента вектора Y
—
Блок Б: один поток – одна компонента
очередного приближения вектора неизвестных X
Реализация функции активации
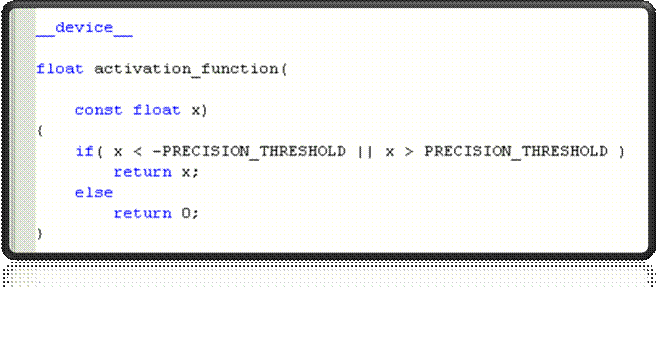
Реализация функции нейронной
сети

Реализация блока настройки

Конфигурация и запуск ядер
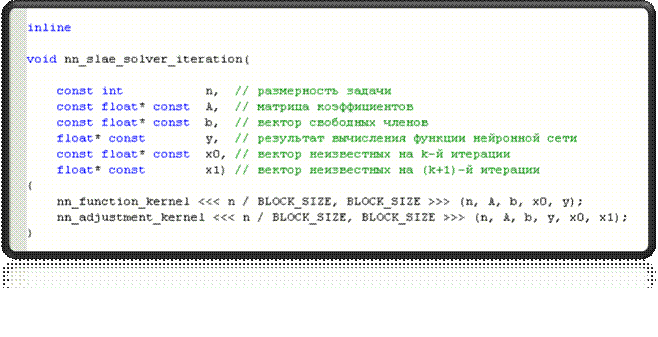
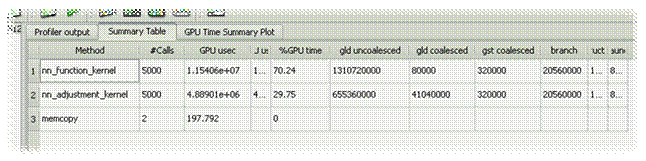
Анализ производительности

Coalesced access (CC
1.0-1.1)

Uncoalesced access (CC
1.0-1.1)
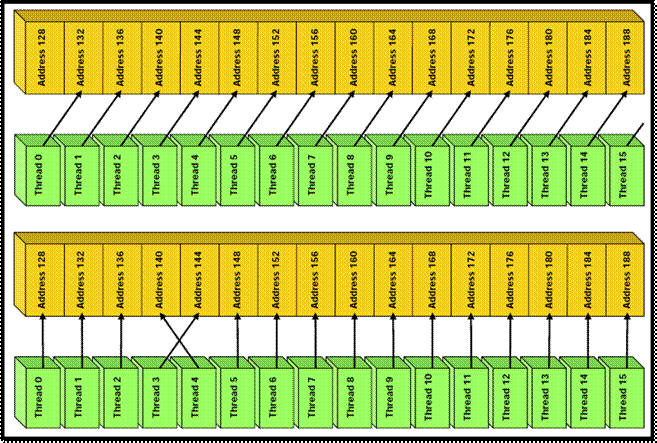
Uncoalesced access (CC
1.0-1.1)

Оптимизация доступа к памяти
Ø
Высокий приоритет: оптимизировать доступ к глобальной
памяти ядром nn_function_kernel, задействовав разделяемую память
Ø
Средний приоритет: оптимизировать доступ к глобальной
памяти ядром nn_adjustment_kernel, задействовав разделяемую память
Оптимизация доступа к
глобальной памяти (на примере ФНС)

Анализ производительности


Сравнение с предыдущей
версией
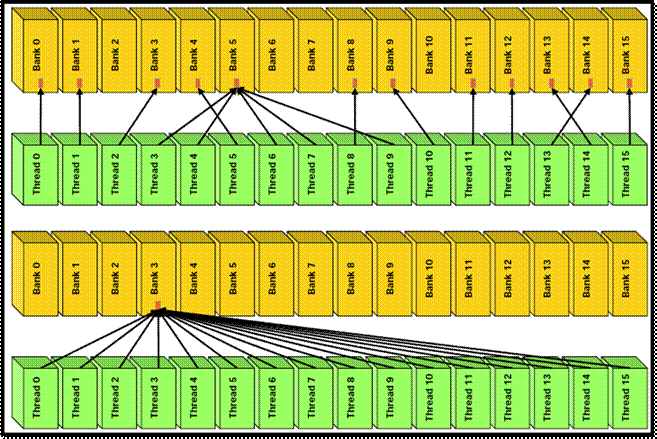
Доступ к разделяемой памяти
без конфликтов банков
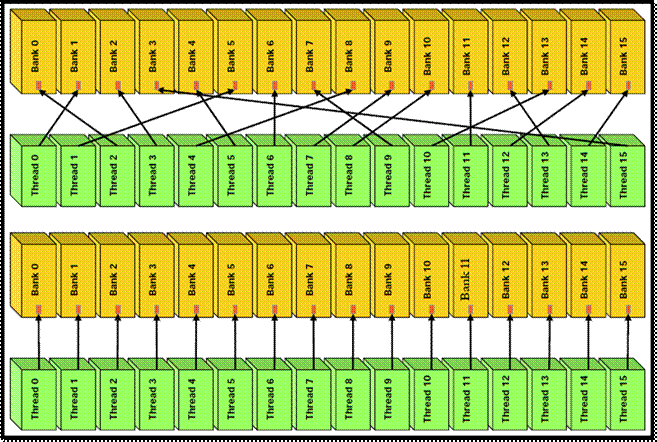
Доступ к разделяемой памяти с
конфликтами банков

32-bit word broadcasting
Иной вариант оптимизации доступа
к глобальной памяти
—
Использовать текстуры вместо линейных участков
глобальной памяти, не подлежащих изменению, а также обращение к которым является uncoalesced.
—
Исключить обращения к разделяемой памяти, влекущие за собой конфликты
банков
Внесение изменений (на
примере ФНС)

Анализ производительности

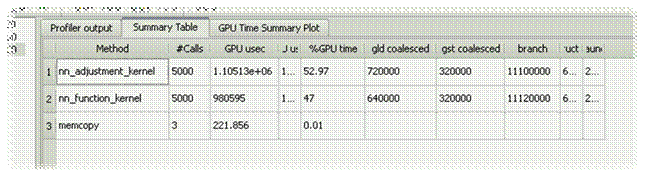
Сравнение с предыдущими
версиями
Сравнение с предыдущими
версиями
—
Отсутствуют uncoalesced
обращения к глобальной памяти
—
Отсутсвует сериализация warps
—
Загрузка устройства (occupancy) 66,7%
Подведение итогов
Общие направления оптимизации (в
порядке убывания приоритета), производительность зависит от…, использованные и
рекомендующиеся материалы
Общие направления оптимизации
(в порядке убывания приоритета)
—
Максимизация числа исполняющихся параллельно блоков
кода
—
Оптимизация доступа к памяти для достижения максимальной
пропускной способности
—
Оптимизация использования инструкций для достижения максимального
показателя инструкций/сек
Производительность зависит
от…
—
Алгоритма решения задачи
—
Оптимальности доступа к памяти
—
Количества перемещений данных хост-устройство
—
Минимизации количества расходящихся ветвлений (divergent
branches)
—
Степени загрузки устройства вычислениями
—
Организации иерархии потоков
—
... т. д.
Использованные и
рекомендующиеся материалы
— NVIDIA
CUDA Programming Guide
— NVIDIA
CUDA Best Practices Guide
—
NVIDIA CUDA Reference Manual
Спасибо за внимание!
Имеются ли вопросы?