Назад в библиотеку
Reservoir computing approaches to recurrent neural network trainingАвторы: Herbert Jaeger, Mantas Lukosevicius АннотацияHerbert Jaeger, Mantas Lukosevicius. Reservoir computing approaches to recurrent neural network training. The article deals with the concept of reservoir computing, the structure, key features and benefits of reservoir computing before the neural networks with time delays. AbstractEcho State Networks and Liquid State Machines introduced a new paradigm in artificial recurrent neural network (RNN) training, where an RNN (the reservoir) is generated randomly and only a readout is trained. The paradigm, becoming known as reservoir computing, greatly facilitated the practical application of RNNs and outperformed classical fully trained RNNs in many tasks. It has lately become a vivid research field with numerous extensions of the basic idea, including reservoir adaptation, thus broadening the initial paradigm to using different methods for training the reservoir and the readout. This review systematically surveys both current ways of generating/adapting the reservoirs and training different types of readouts. It offers a natural conceptual classification of the techniques, which transcends boundaries of the current brand-names of reservoir methods, and thus aims to help in unifying the field and providing the reader with a detailed IntroductionArtificial recurrent neural networks (RNNs) represent a large and varied class of computational models that are designed by more or less detailed analogy with biological brain modules. In an RNN numerous abstract neurons (also called units or processing elements) are interconnected by likewise abstracted synaptic connections (or links), which enable activations to propagate through the network. The characteristic feature of RNNs that distinguishes them from the more widely used feedforward neural networks is that the connection topology possesses cycles. The existence of cycles has a profound impact: This review article concerns a particular subset of RNN based research in two aspects: RNNs (of the second type) appear as highly promising and fascinating tools for nonlinear time series processing applications, mainly for two reasons. First, it can be shown that under fairly mild and general assumptions, such RNNs are universal approximators of dynamical systems. Second, biological brain modules almost universally exhibit recurrent connection pathways too. Both observations indicate that RNNs should potentially be powerful tools for engineering applications. Despite this widely acknowledged potential, and despite a number of successful academic and practical applications, the impact of RNNs in nonlinear modeling has remained limited for a long time. The main reason for this lies in the fact that RNNs are dificult to train by gradient descent based methods, which aim at iteratively reducing the training error. While a number of training algorithms have been proposed (a brief overview is given in Section 2.5), these all suffer fromthe following shortcomings: In this situation of slow and dificult progress, in 2001 a fundamentally new approach to RNN design and training was proposed independently by Wolfgang Maass under the name of Liquid State Machines and by Herbert Jaeger under the name of Echo State Networks. This approach, which had predecessors in computational neuroscience and subsequent ramifications in machine learning as the BackpropagationDecorrelation learning rule, is now increasingly often collectively referred to as Reservoir Computing (RC). The RC paradigm avoids the shortcomings of gradientdescent RNN training listed above, by setting up RNNs in the following way: Fig. 1 graphically contrasts previous methods of RNN training with the RC approach. 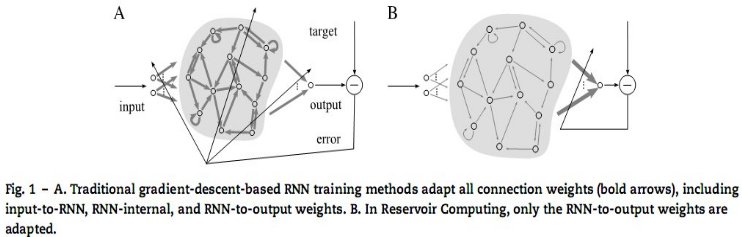
Figure 1 – Methods of RNN training with the RC approach These encouraging observations should not mask the fact that RC is still in its infancy, and significant further improvements and extensions are desirable. Specifically, just simply creating a reservoir at random is unsatisfactory. It seems obvious that, when addressing a specific modeling task, a specific reservoir design that is adapted to the task will lead to better results than a naive randomcreation. Thus, the main stream of research in the field is today directed at understanding the effects of reservoir characteristics on task performance, and at developing suitable reservoir design and adaptation methods. Also, new ways of reading out from the reservoirs, including combining them into larger structures, are devised and investigated. While shifting from the initial idea of having a fixed randomly created reservoir and training only the readout, the current paradigm of reservoir computing remains (and differentiates itself from other RNN training approaches) as producing/training the reservoir and the readout separately and differently. This review offers a conceptual classification and a comprehensive survey of this research. As is true for many areas of machine learning, methods in reservoir computing converge from different fields and come with different names. We would like to make a distinction here between these differently named tradition lines, which we like to call brands, and the actual finer-grained ideas on producing good reservoirs, which we will call recipes. Since recipes can be useful and mixed across different brands, this review focuses on classifying and surveying them. To be fair, it has to be said that the authors of this survey associate themselves mostly with the Echo State Networks brand, and thus, willingly or not, are influenced by its mindset. References
|