Название: Системы оптического распознавания текста в Linux – обзор и сравнительное тестирование
Источник: Виртуальная энциклопедия
Одна из областей, в которых отставание Linux от Windows считается значительным и трудно преодолимым, является оптическое распознавание текста. Так как необходимость распознать текст время от времени появляется практически у каждого пользователя компьютера, потребность в программном обеспечении такого рода надо признать актуальной проблемой. В связи с этим недавно я решил потратить немного времени и провести сравнительное тестирование имеющихся систем оптического распознавания текста (OCR), доступных в Linux. Для полноты картины рассматривались как локально устанавливаемые программы, так и онлайновые сервисы.
Методика тестирования
Для более объективной оценки возможностей пакетов оптического распознавания я подготовил три образца. Первый из них представляет собой страницу текста из книги «Война и мир». Данная страница из электронной книги в формате PDF была импортирована в GIMP с разрешением 300 dpi и сохранена в формате png. Таким образом, она представляет собой практически идеальный объект для распознавания и все программы должны с этим справиться без труда.
Второй образец представляет собой ту же страницу, но импортированную уже с разрешением 200 dpi и сохраненную в формате jpg с уровнем качества 60%. Любопытно посмотреть, как это скажется на качестве распознавания.
Для третьего образца та же самая страница была импортирована с разрешением уже 150 dpi. После импортирования на рисунок в GIMP был наложен фильтр «Фотокопия», имитирующий копировальную машину, что еще больше усложняет распознавание.
Что касается полученных результатов, они приведены в таблице. Показателем точности распознавания является отношение количества правильно распознанных слов к общему количеству слов в документе, выраженное в процентах и определяемое с помощью утилиты dwdiff.
Само собой, автор не претендует на какую-либо стопроцентную достоверность полученных результатов. При использовании других образцов результаты могут значительно измениться.
А теперь рассмотрим наших кандидатов.
ABBYY FineReader for Linux
Не секрет, что уже в течение многих лет единоличным лидером на рынке оптического распознавания является российская компания ABBYY со своим продуктом Fine Reader. В настоящее время компания предлагает пакет ABBYY FineReader Engine 8.0 CLI for Linux, включающий утилиту командой строки для распознавания и SDK для встраивания движка распознавания в различные корпоративные системы документооборота и т.д. Полная версия программы стоит 149 евро, при этом количество распознаваемых страниц ограничено величиной 12000 в год. Есть и более дорогие версии, в которых это количество значительно больше. Более подробную информацию можно получить на странице проекта. При такой стоимости покупать программу для домашнего использования возможно и не стоит, однако даже для небольшой компании она выглядит вполне приемлемо. Триальная версия позволяет распознать 100 страниц, ее мы и испытаем.
Для начала необходимо скачать архив с программой весом 290 Мб. Для получения триального ключа необходимо заполнить несложную форму на этом же сайте. Мне через пару дней после ее заполнения пришел ответ с ключом. В архиве находится файл abbyyocr.run и инструкция по установке, которая в общем заключается в запуске вышеуказанного файла на выполнение от имени суперпользователя (все это делалось в Ubuntu 10.10):
$ sudo ./abbyyocr.bin
В процессе установки программа запросила ключ, после чего благополучно активировалась. Программа имеет множество ключей командной строки, позволяющих гибко настроить параметры распознавания. Я использовал команду вида:
$ abbyyocr –rl Russian English –if sample.jpg –f RTF –of sample.rtf
В целом здесь все понятно. Ключи –if и –of задают распознаваемый файл и файл, в который записывается результат работы программы. С помощью –f задается формат вывода. Необходимо отметить, что если в тексте имеются слова на иностранном языке, необходимо обязательно задать его вторым после ключа –rl. В противном случае программа будет пытаться распознать все на русском.
ABBYY Fine Reader Online
Для полноты картины необходимо рассмотреть еще один продукт от ABBYY – онлайновый сервис ABBYY Fine Reader Online. Ранее он позволял после несложной регистрации распознавать бесплатно до 10 страниц в день, теперь же бесплатно можно распознать только три страницы сразу после регистрации, после чего необходимо платить. Минимальный пакет стоит 3$ за 20 страниц. Сервис поддерживает большое количество языков и форматов файлов.
Cuneiform
На второе место по известности среди систем OCR можно смело поставить программу cuniform. Первоначально программа CuneiForm была разработана компанией Cognitive Technologies как коммерческий продукт. CuneiForm поставлялся с некоторыми моделями сканеров. Однако после нескольких лет перерыва разработки, 12 декабря 2007 года анонсировано открытие исходных текстов программы, которое состоялось 2 апреля 2008 года.
По умолчанию в Ubuntu 10.10 доступна достаточно старая версия 0.7. Однако после добавления соответствующего PPA можно стать обладателем версии 1.0.
Для Cuneiform написаны два графических интерфейса –YAGF и CuneiformQt.
Для тестирования я использовал версию 1.0.0, установленную из вышеуказанного PPA. Распознавание производилось с помощью команды вида:
$ cuneiform –l rus –o sample.txt sample.jpg
В руководстве cuneiform приводится опция –fax, которая включает оптимизацию работы программы для распознавания документов, переданных с помощью факса, однако при ее использовании результат получается хуже, поэтому я не привел его в таблице.
GOCR
GOCR – это свободная кроссплатформенная система оптического распознавания текстов, работающая из командной строки. Программа пока находится в ранней стадии разработки, поэтому имеет ряд серьезных недостатков (например, распознает только одноколоночный текст). Кроме того, изучение man-страницы показало, что опций, позволяющих задать язык распознавания, программа не имеет, что подтвердилось экспериментом – русский текст gocr пытается распознать как английский. Естественно, в таблицу я данную программу включать не стал.
Ocrad
Ocrad – это система оптического распознавания, разрабатываемая в рамках проекта GNU. Программа использует метод выделения характерных признаков (feature extraction). Она читает побитовое изображение в формате pgm/pbm и генерирует текст в байтовом (8-битном) формате. Ocrad содержит анализатор макета, способный отделять столбцы или блоки текста, часто встречающиеся в печатных страницах. К сожалению, поддержка русского языка также отсутствует напрочь. Поэтому из нашего сравнения программу исключаем.
Tesseract
Tesseract – свободная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-;х по середину 1990-х. Затем ее разработка была заморожена на 10 лет. В августе 2006 г Google купил её и открыл исходные тексты под лицензией Apache 2.0 для продолжения разработки. В настоящий момент программа уже работает с UTF-8, поддержка языков (включая русский с версии 3.0) осуществляется с помощью дополнительных модулей.
Так как в репозиториях Ubuntu присутствует 2-я версия программы, а русский язык поддерживается только с релиза 3.0.0, программу я собирал из исходных текстов по инструкциям, найденным в сети.
Итак, скачиваем архив с исходными текстами (в моем случае это tesseract-3.00.tar.gz, но с выходом новых версий название может быть другим), распаковываем его и переходим в директорию с исходными кодами.
Для корректной работы tesseract необходим пакет leptonica – ПО с открытым исходным кодом, необходимое для приложений, работающих и анализирующих изображения. Устанавливаем его:
$ sudo apt–get install leptonica–progs $ sudo ldconfig
Кроме того, для работы tesseract необходимо установить следующие пакеты: libpng12-dev, libjpeg62-dev, libtiff4-dev, zlib1g-dev, libtool build-essential. Устанавливаем и их, а затем из директории с исходным кодом начинаем конфигурирование и сборку программы:
$ ./runautoconf $ ./configure $ make $ sudo checkinstall
При подтверждении опций необходимо изменить имя пакета (номер 2) на tesseract-ocr.
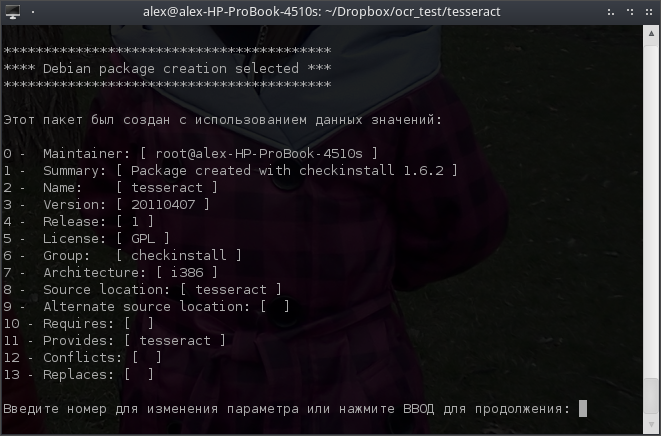
Все остальные опции принимаем по умолчанию. В результате будет установлен tesseract 3.0, а также собран deb-пакет, поэтому в следующий раз программу можно будет устанавливать обычным способом с помощью GDebi.
С первого раза программа у меня не собралась, пожаловавшись на отсутствие каталога /usr/local/share/tessdata. После того, как я создал его вручную, процесс завершился благополучно.
Теперь необходимо скачать с сайта программы пакет поддержки русского языка (rus.traineddata.gz), распаковать его и скопировать содержимое архива (а это должен быть один файл rus.traineddata) в директорию /usr/local/share/tessdata/.
Изображения перед распознаванием необходимо прнобразовать в формат tiff.
Для распознавания я использовал команду вида:
$ tesseract sample.tiff sample.txt –l rus
Если программа не заработала и возникают ошибки, связанные с отсутствием необходимых библиотек или правами доступа, выполните следующие команды:
$ sudo chmod 777 /usr/local/share/tessdata/*.traineddata $ export LD_LIBRARY_PATH=/usr/local/lib[/code]
Теперь все должно работать.
Для tesseract имеется графический интерфейс tesseract-gui, который тоже надо собирать из исходного кода. У меня он запустился, но распознавать текст почему–то не захотел. Еще есть система OCRopus, которая может использовать движок tesseract. Собственно поэтому я ее отдельно рассматривать не стал.
SILVERCODERS OCR Server
Данная программа представляет собой мощную коммерческую серверную систему распознавания, предназначенную для предприятий и поддерживающую 189 языков, среди них и русский. Она разработана специально для интегрирования в корпоративные системы документооборота. Триальной версии для свободного скачивания нет, поэтому опробовать мне эту систему не удалось.
Free OCR
Free OCR – бесплатный онлайн-сервис для оптического распознавания текста, использующий движок tesseract. Размер загружаемого изображения ограничен 2 Мб. Поддерживаются форматы JPG, GIF, TIFF BMP и PDF (только первая страница, в скором времени обещают поддержку первых 10 страниц). Также, существует лимит на 10 изображений в час.
Сервис распознает множество языков – русский, украинский, английский, немецкий, французский, турецкий, большинство восточноевропейских языков.
img2txt
img2txt – многоязычный онлайн-сервис для оптического распознавания текста. Поддерживаются форматы JPG, PNG, TIFF с размером файла до 2 Мб. В будущем обещают поддержку PDF и DJVU. На Википедии сервис обозначен как коммерческий и проприетарный, однако на самом сайте никакой информации об типе лицензии и используемом движке нет. Мои три тестовые страницы распознались без проблем. Никакой оплаты или хотя бы регистрации не просили.
OnlineOCR
OnlineOCR – еще один онлайн-сервис, теперь уже коммерческий (28 языков, включая русский). Поддерживает ввод в форматах TIFF (multi-page), JPEG/JPG, BMP, PCX, PNG, GIF, PDF (multi-page), файлы до 20 мб; вывод в PDF, MS Word, MS Excel, HTML, RTF, TXT. Минимальный пакет, который можно купить, составляет 10 страниц за 5 рублей. Зарегистрированный пользователь имеет свой кабинет, в котором хранятся загруженные файлы и результаты распознавания. К сожалению, возможность бесплатной работы с сервисом настолько ограничена, что протестировать его не удалось. Причем попытка оплатить 10 страниц с помощью СМС также закончилась неудачно.
NewOCR
NewOCR – бесплатный OCR сервис, поддерживающий 29 языков распознавания, включая русский. Позволяет загружать файлы в форматах JPEG, PNG, GIF, BMP, многостраничный TIFF размером до 5 Мб, а также многостраничные PDF размером до 20 Мб. Поддерживается многоколоночное форматирование текста.
Кроме того, необходимо отметить, что на рынке имеется еще одна коммерческая система распознавания от компании vividata, однако стоимость этой программы составляет $2400 (!) плюс по $100 за каждый дополнительный язык, отдельная плата, например, за модуль вывода в PDF ($1200) и т.д., поэтому я даже не стал заморачиваться с ее установкой. Ко всему прочему программа видимо очень давно не обновлялась (файлы в установочном архива датируются 2001 годом) и сами разработчики сомневаются в том, что она заработает на современных дистрибутивах. Поэтому тестировать vividata я не стал.
Также я решил включить в таблицу Google Docs, так как эта служба в настоящее время также позволяет производить распознавание русского текста. По имеющимся данным она использует tessract, однако нельзя исключить, что в своем сервисе Google использует какие-нибудь дополнительные наработки, поэтому интересно сравнить ее с остальными.
Результаты сравнительного тестирования систем оптического распознавания
| Программа (сервис) | Точность распознавания, % | ||
| Образец 1 | Образец 2 | Образец 3 | |
| FineReader for Linux | 100% | 100% | 87% |
| FineReader Online | 100% | 100% | 94% |
| Cuneiform 1.0.0 | 94% | 94% | 17% |
| Tesseract 3.0.0 | 97% | 98% | 5% |
| Free OCR | 96% | 93% | 61% |
| img2txt | 96% | 94% | 24% |
| NewOCR | 94% | 94% | 41% |
| Google Docs | 93% | 96% | 58% |
Выводы
Результаты, приведенные в таблице, показывают, что при хорошем качестве распознаваемого материала все участвовавшие в тестировании программы обеспечивают высокое качество распознавания, причем снижение разрешения с 300 до 200 dpi практически не влияет на результат. В то же время при распознавании некачественного материала ABBYY Fine Reader явно вырывается вперед, что неудивительно, учитывая ресурсы, задействованные в разработке данного приложения. Однако в целом можно отметить, что широко распространенное суждение о том, что для Linux нет хороших систем оптического распознавания текста, сегодня уже не выдерживает критики.
Для нерегулярного домашнего применения подойдет любая из представленных в обзоре бесплатных систем, а для организации, деятельность которой связана с частым использованием систем распознавания, особенно если дело касается факсов и другого материала посредственного качества, стоит подумать о покупке Fine Reader, тем более, что открытый API позволяет интегрировать его в любую корпоративную систему документооборота.