
| Резюме Биография Реферат Библиотека Ссылки Отчет о поиске Индивидуальный раздел |
|
Тема: Методы и алгоритмы оптимизации доступа к пространственным данным в СУБД HBase Содержание:
Типичные задачи интеллектуального анализа пространственных данных включают кластеризацию, классификацию и определение трендов. Основное отличие между извлечением знаний в обычных базах данных и в пространственных – это то, что атрибуты соседей определенного пространственного объекта имеют влияние на сам этот объект. Поэтому алгоритмы извлечения знаний из пространственных данных сильно зависят от эффективности процесса определения отношения соседства для какого-либо пространственного объекта. Операция определения отношения соседства между пространственными объектами требует много вычислительного времени. Простой алгоритм поиска соседних объектов имеет вычислительную сложность , так как необходимо просматривать все пары объектов. Таким образом, целью работы является анализ проблемы актуальности данных генерирующихся в ГИС, а также выявление методов и алгоритмов, с помощью которых можно эффективно индексировать пространственные данные [1]. В последнее время появляется большое количество информационных систем генерирующих пространственные данные. Такие системы обычно называют геоинформационными системами (ГИС). Это такие системы как сенсорные сети, системы дистанционного зондирования Земли, спутниковый мониторинг транспорта и др. Все это говорит о том, что количество и объемы пространственных баз данных будут продолжать быстро расти. Интеллектуальный анализ этих данных может дать много полезной информации о реальном физическом мире и помочь в решении своих задач экспертам таких предметных областей как экология, землеустройство, муниципальное управление, транспорт, экономика и многих других. Научная новизна состоит в использовании кодов Мортона и древовидной структуры данных такой, как дерево квадрантов, которые позволят индексировать пространственные объекты для их дальнейшей обработки. Такой подход должен обеспечить высокую производительность в распределенных системах использующих СУБД HBase. Планируемые практические результаты С помощью данной работы предполагается получить решение проблемы индексации пространственных данных получаемых из геоинформационных систем. Обзор геоинформационных систем
Существенным отличием ГИС от других информационных систем с пространственной локализацией данных является включение в описание пространственных объектов топологических характеристик и классификация на этой основе пространственных объектов на: точечные, линейные и площадные (ареальные). Временной аспект, как правило, включает три фактора долговременный, средне временный и оперативный. С этим аспектом связана характеристика качества информации – актуальность и процедура актуализации данных.
По временной характеристики информация, хранимая и ГНС, обычно подразделяется на:
Системы распределенного хранения и обработки данных Для работы с большими объемами данных в последнее время все активнее используется распределенное хранение и обработка. Причем наблюдается переход от использования высокопроизводительных мэйнфреймов к кластерным системам, состоящим из большого числа недорогих серверов с архитектурой x86-64 [2]. После опубликования фирмой Google статей раскрывающей принципы хранения и обработки данных, реализованные ей для своих сервисов [3, 4], появились открытые проекты, реализующие эти принципы. Наиболее успешным из них на сегодняшний день является проект Hadoop. Hadoop является свободным Java фреймворком, поддерживающим выполнение распределённых приложений, работающих на больших кластерах, объединяющих обычные сервера под управлением открытой операционной системы Linux. Для распределенного хранения данных используется файловая система Hadoop Distributed File System (HDFS), которая является открытым аналогом Google File System (GFS). Поверх этой файловой системы работает СУБД HBase, которая является аналогом СУБД BigTable от Google [3]. В Hadoop реализована вычислительная парадигма, известная как MapReduce [4]. Согласно этой парадигме приложение разделяется на большое количество небольших заданий, каждое из которых может быть выполнено на любом из узлов кластера. Все эти технологии позволяют достичь очень высокой агрегированной пропускной способности кластера. Эта система позволяет приложениям легко масштабироваться до уровня тысяч узлов и петабайт данных. Поэтому разработку пространственных индексов мы будем выполнять для СУБД HBase. Математические методы решения задачи Для построения пространственного индекса предлагается использовать структуру данных дерево квадрантов (quadtree) . Дерево квадрантов – это древовидная структура данных, в которой корневой и каждый внутренний узел имеет четыре дочерних узла [4]. Эта структура данных была разработана специально для разбивки двумерного пространства с помощью рекурсивного разделения его на четыре квадранта (рис. 1).

Рисунок 1 – Принцип использования дерева квадрантов 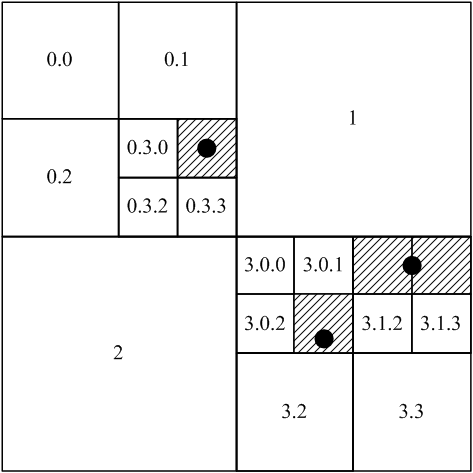
Рисунок 2 – Индексация пространственных объектов, разбивка на блоки Корень дерева делит область на 4 квадранта СВ, СЗ, ЮЗ, ЮВ (в соответствии с картой). Каждый уровень дерева квадрантов требует два бита кода Мортона. Для кодирования географических координат мы предлагаем использовать код длиной 64 бита. Так как географические координаты Земли варьируются от -90° до 90° по широте и от -180° до 180° по долготе 64-х битный код Мортона позволит задавать координаты с точностью вплоть до седьмого знака после запятой в десятичном представлении градусов. Коды Мортона были выбраны благодаря простоте расчета номера ячейки по геометрическим координатам. Пространственные базы данных оперируют такими двумерными геометрическими объектами как точка, ломаная линия и многоугольник. Точка в двумерном пространстве представляется двумя географическими координатами: долготой и широтой. Рассмотрим алгоритм определения кода Мортона для координат точки в двумерном пространстве: для того, чтобы получить код Мортона для узла содержащего точку , достаточно перевести индексы x и y в бинарное представление, после чего построить новое число, по очереди беря по одному разряду из двоичного представления каждого числа [5, 6]. Рассмотрим теперь более сложный случай, когда индексируется пространственный объект, представленный ломаной или многоугольником. Любой двумерный объект может быть заменен описанным прямоугольником (bounding box) [7, 8] с некоторой потерей точности. Это позволяет упростить расчеты и значительно увеличить скорость обработки пространственных запросов. Использование этого подхода является обычной практикой при построении индексов пространственных данных. Таким образом, произвольный двумерный объект при индексации представляется в виде описанного прямоугольника. Дерево квадрантов обладает свойством адаптивности. Это означает. Что пространственные объекты могут индексироваться узлами разного уровня. Все зависит от площади индексируемого объекта. Если индексируется точка, то используется узел нижнего уровня (рис. 2, рис. 3). Если же индексируется объект представленный прямоугольником, то ссылка на него записывается в узел, размер которого минимально превышает размер этого прямоугольника [1]. 
Рисунок 3 – Индексация пространственных объектов, древовидная структура
Взаимное влияние между пространственными объектами определяется топологическим отношением, расстоянием и направлением между объектами.
Для определения топологических отношений между двумя пространственными объектами A и B обычно используются следующие предикаты [9, 10]:
В результате работы был проведен анализ геоинформационных систем, выявлены основные их недостатки в плане индексирования и извлечения пространственных данных. Для решения данной проблемы был разработан метод индексации пространственный данных в СУБД HBase.
|
