СУБД для анализа Больших Данных
Автор: Кирилл Вахрамеев
Источник: издательство «Открытые системы» , № 10, 2011
Аннотация
Кирилл Вахрамеев СУБД для анализа Больших Данных. Виртуализация изменила ИТ, за исключением сегмента высоконагруженных приложений и серверов больших баз данных, однако сегодня и здесь, благодаря таким решениям, как HP Vertica, наступает время революционных изменений, но совершенно иного плана.
Еще совсем недавно активно обсуждались способы организации работы множества малонагруженных компьютеров с целью облегчения управления ими, компактного размещения, консолидации и минимизации потребления энергии. Одним из возможных способов решения этих проблем стала виртуализация серверов, которая сегодня прочно вошла в практику. Однако для высоконагруженных серверов больших баз данных виртуализация оказалась неэффективной, вместе с тем проблема анализа Больших Данных стимулировала поиск решений и в этой области.
Большие Данные (Big Data) — это совокупность структурированных и неструктурированных, постоянно растущих данных, а также методов, инструментов и методов их обработки в распределенной сети с учетом многообразия форматов и источников данных. Целью обработки является получение понятных человеку результатов, обобщающих поведение изучаемых объектов и позволяющих его прогнозировать. Ключевой момент здесь — непрерывное поступление новых данных, но аналитики, как правило, не любят, когда данные меняются во время выполнения запроса, поскольку изменения могут исказить результат. Значит, надо уметь анализировать их «мгновенно», за время, сравнимое со временем их поступления.
Было бы неверно характеризовать Большие Данные лишь объемом как таковым, поскольку любой фиксированный объем хранения, скажем 100 Гбайт, позавчера казался велик, сегодня помещается в мобильном устройстве, а послезавтра его не хватит и на один фрагмент семейной хроники. Большие Данные — типичный пример перехода количества в качество. Это не количество байтов, а, по аналогии с Большой Водой или Большой Нефтью, такой объем, который трудно хранить и обрабатывать традиционными способами, причем в реальном времени.
Зачем собирать и обрабатывать?
О том, зачем нужна бизнес-аналитика как таковая, написано много – общее состоит в том, что она необходима для снижения рисков принятия ошибочных решений в быстро меняющемся мире. Важно знать, где аналитик встретится с Большими Данными, — сегодня, как правило, это комплексы, отслеживающие состояние и тренды поведения рукотворных и нерукотворных больших, взаимосвязанных стохастических систем.
- Мобильные сервисы, предоставляющие пользователям мобильных устройств сведения о быстро меняющихся условиях, например о рынках акций, о местах на парковках, о наличии товаров в ближайших магазинах, о пробках, потоках транспортных средств, требующих, чтобы сбор, хранение, анализ и распространение данных осуществлялись в реальном времени. Нужное для мобильных сервисов качество линий связи, в свою очередь, достигается, если телекоммуникационные компании эффективно предсказывают поведение клиентов, выявляют нарушения, оптимизируют загрузку линий и т. д., причем быстро меняющимся случайным фактором здесь может быть не только непредсказуемость пользователей, но и природные явления, мешающие прохождению сигнала.
- Природные системы, для предсказания поведения которых требуется сбор и обработка Больших Данных, при этом желательно учитывать человекозависимые геофизические процессы, например тепловые выбросы, зависящие от активности крупных рукотворных объектов (больших заводов, тепловых и гидравлических электростанций и т. п.), поскольку они могут существенно менять картину природных процессов.
- Крупные предприятия, в свою очередь, не только изменяющие климат, но и предоставляющие данные для анализа и предсказания ситуации на рынке, изучения и прогнозирования поведения сотрудников, клиентов, поставщиков и регуляторов, что позволяет наладить эффективное взаимодействие с ними, оптимизировать операционные расходы и контролировать ключевые индикаторы производительности, отслеживать подозрительные сделки, оценивать общественные и экономические тенденции, влияющие на изменение настроений заказчиков, регуляторов и рынков, в том числе и финансовых.
- Финансовые рынки, кроме перечисленных областей анализа требующие оценки изменений стоимости финансовых инструментов в реальном времени для трейдерских целей, анализа рисков, фрод-мониторинга для исключения мошеннических транзакций и других действий, подверженных ошибкам, которые могут стоить экстремально дорого, поэтому на страже их стабильности стоят различные службы.
- Службы безопасности и аудит, осуществляющие анализ и прогноз поведения людей, выявление подозрительных лиц и сделок, проверяющие соответствие документов законодательным нормам и работающие над извлечением и анализом сведений о субъектах рынков — людях, обычно организуемых в те или иные сообщества.
- Социальные сети, вовлекающие социально активных людей, анализ предпочтений и поведения которых позволяет оптимизировать процессы продвижения продуктов и услуг. Изучение мотивов поведения пассивных членов общества требует взаимодействия с другими системами, например медицинскими.
- Система здравоохранения, осуществляющая не только сбор и анализ результатов медицинских исследований, учет историй болезни и т. п., но и обрабатывающая собранные Большие Данные с целью, в частности, прогнозирования и локализации эпидемий.
Практически во всех перечисленных системах используются технологические датчики, генерирующие массу данных, сбор, хранение и анализ которых может оказаться весьма сложным в силу их больших объемов и/или скорости поступления.
Чем обрабатывать?
Майкл Стоунбрейкер в статье «Один размер пригоден для всех»: идея, время которой пришло и ушло» обращает внимание на то, что специализированные СУБД могут работать на два порядка быстрее универсальных, поэтому для каждого класса задач, вообще говоря, должна быть своя система, причем количество ее настроек должно быть минимальным (в универсальной системе множество настроек оправданно, а в специализированной все должно быть максимально оптимизировано на уровне кода). Многие из своих идей Стоунбрейкер проверил на практике, создавая стартапы, часть которых была впоследствии успешно продана. Одна из таких компаний — Vertica, выпускающая одноименную СУБД, специально предназначенную для решения аналитических задач в реальном времени. С сегодня эта компания вошла в состав HP.
Прототипом Vertica была экспериментальная СУБД C-Store, получившая свое название от метода хранения по колонкам. Продвигая Vertica на рынок, маркетологи обыграли четыре буквы C (в русском варианте «К»): Columns storage (хранение по колонкам), Compression (компрессия данных), Clustering (кластеризация) и Continuous performance (круглосуточная непрерывная работа 24х7х365).
- Хранение данных по колонкам позволяет считывать с дисков не всю запись целиком, а только нужные поля, участвующие в запросе, ведь колонка — это следующие друг за другом значения одного и того же поля, а поскольку в колонке могут встречаться повторяющиеся значения (как нулевые, так и, например, относящиеся к одному и тому же времени или одному и тому же имени объекта), то после сортировки сжатие данных оказывается эффективным.
- Компрессия данных применяется для упаковки колонок путем записывания числа повторений вместе с собственно значением поля, использования дельта-кодирования последовательных значений, сжатия LZ (Lempel-Ziv) для колонок с большим количеством уникальных значений и неотсортированных колонок, а также с помощью специальных алгоритмов компрессии для чисел в формате с плавающей запятой, для дат и ряда других типов полей. В результате в Vertica степень сжатия достигает 90%, а на таких данных, как журналы телекоммуникационных сетей и SNMP-трапов, еще выше, причем способ компрессии для каждого типа данных выбирается автоматически. Поскольку Vertica уникальна тем, что операции над данными в большинстве случаев можно выполнять без декомпрессии, то пропорционально уменьшается не только требуемый объем хранилища и число обращений к дискам, но и загрузка процессоров и памяти, особенно на операциях, которые специально оптимизированы для работы со сжатыми данными (например, scan и aggregate), в результате Vertica не нуждается в специализированных процессорах для компрессии и декомпрессии. Дополнительным ускоряющим фактором при обработке большого количества параллельных запросов является использование разных порядков сортировки в разных копиях колонок, выбираемых автоматически, а поскольку агрессивная компрессия экономит место, то можно хранить множество копий одних и тех же колонок в разных «проекциях» базы данных, которые представляют собой наборы колонок, хранящихся вместе. Можно хранить не только разные копии на разных дисках, но и разделять «проекции» по значению одного из полей на сегменты, располагающиеся и обрабатывающиеся на разных машинах.
- Кластеризация позволяет пропорционально увеличить производительность и заодно обеспечить не только масштабирование, но и отказоустойчивость. Кластер не содержит разделяемых ресурсов, следовательно, не тратит время на ожидание «локов» -блокировок ресурсов и потому не содержит средств управления распределенными блокировками. Фактически это машина с массовой параллельной архитектуров (Massive Parallel Processing, MPP) с большим количеством узлов, способных копировать данные друг друга. Важным моментом в архитектуре является полный отказ от ведения журналов, поскольку в большинстве случаев журнал становится узким местом при загрузке данных. Вместо журналов поддерживается множество копий колонок на разных узлах кластера, что и обеспечивает масштабируемость и отказоустойчивость.
- Круглосуточная в режиме 24х7х365 обеспечивается кластером, способным без остановки выполнения запросов выдержать сбои нескольких узлов. Для количественной оценки степени защищенности кластера архитекторы Vertica ввели термин «К-защита» (K-safety). Идея заключается в том, чтобы копии каждого из сегментов базы данных сохранялись на К+1 узлах кластера (рис. 1), и тогда при отказе K узлов еще можно восстановить базу данных. В СУБД Vertica такое восстановление выполняется автоматически — при замене неисправного узла или при расширении кластера на добавляемые машины переносится часть объектов с исправных узлов с поддержкой целостности и заданного значения параметра K. К-защита обеспечивает не только увеличение надежности, но и увеличение производительности пропорционально величине К, поскольку К+1 узлов могут в этом случае обрабатывать аналитические запросы, относящиеся к одним и тем же данным.
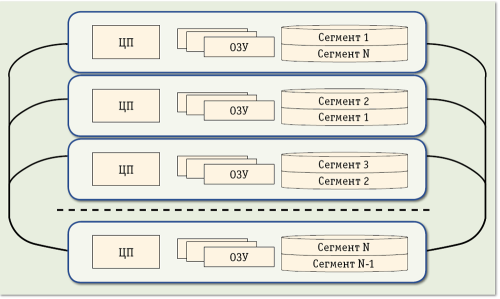
Рисунки 1 – Кластеризация СУБД Vertica с дублированием (К=1)
Как быть с загрузкой?
Согласно определению Больших Данных, нельзя прерывать работу по выполнению запросов на загрузку данных — идет непрерывный поток, а бизнес часто требует от аналитика отчет «уже вчера», поэтому времени на остановку для загрузки данных нет. В СУБД Vertica предусмотрен специальный механизм непрерывной загрузки данных без снижения скорости их чтения. Во-первых, чтение происходит в режиме snapshot isolation mode (изоляции мгновенного снимка), при котором читается последняя целостная копия данных, не зависящая от текущих вставок и удалений, поэтому блокировки базы данных на запись не требуется. Во-вторых, запись ведется в специальную область WOS (Write Only Store) в оперативной памяти, а чтение происходит с дисков — из области хранения типа ROS (Read Only Store), где обычно лежат данные (рис. 2), причем WOS не сортируется и не индексируется. Перенос записей из WOS в отсортированную ROS происходит большими блоками, автоматически и асинхронно с помощью специального процесса перемещения записей Tuple Mover. Так как этот процесс оперирует целиком всей WOS, то перемещение записей может быть очень эффективным, с одновременной сортировкой многих записей и сбросом их на диск в пакетном режиме. Обратной стороной этого механизма является практическая невозможность использования СУБД Vertica в качестве транзакционной, поскольку она оптимизирована для выполнения произвольных запросов и запросов, связанных с оперативной аналитической обработкой (OnLine Analytical Processing, OLAP), и для ее эффективной работы операции UPDATE и DELETE не должны превышать 1% общего числа операций. Следующим детищем Стоунбрейкера будет СУБД, оптимизированная специально для оперативной обработки транзакций (OnLine Transaction Processing, OLTP).
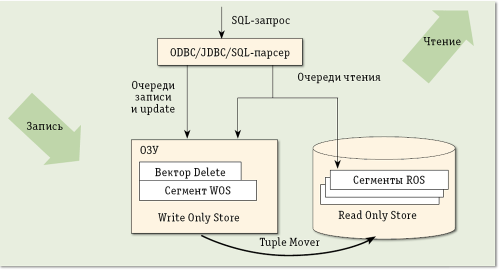
Рисунки 2 – Непрерывная загрузка в СУБД Vertica
Чем больше проекций, копий и чем выше значение K, тем больше ресурсов нужно для выполнения процедуры загрузки, поэтому параметр K не должен быть слишком велик — обычно используются значения 1 или 2. В таком режиме Vertica эффективно справляется с загрузкой при одновременном выполнении аналитических запросов, которые обрабатываются в 10-1000 раз быстрее, чем у «обычной», строковой СУБД на одном и том же оборудовании.
Для оптимизации работы можно перестраивать базу данных на ходу с помощью утилиты Vertica Database Designer, предназначенной также для выработки рекомендаций, обеспечивающих качественное выполнение типичных SQL-запросов, при разработке баз данных. Администратор баз данных, конечно, может изменить любые рекомендованные параметры, но во многих случаях эта утилита самостоятельно оптимизирует производительность, что сокращает время настройки.
Где берут аналитические приложения?
СУБД Vertica снабжена стандартным SQL-интерфейсом (ANSI SQL-99), имеющим расширения для работы с аналитическими запросами, при этом сжатие данных, хранение по колонкам и сегментирование таблиц конечному пользователю не видны. Обеспечивается совместимость с механизмами очистки данных, составления отчетности и бизнес-аналитики от Cognos, Informatica, Business Objects и SAS. Все это облегчает перенос уже накопленных баз данных, а также использование других аналитических приложений, имеющих стандартный SQL-интерфейс, коннекторы ODBC, JDBC или ADO.NET. Существующее аналитическое ПО (например, продукты SAS) можно подключать к СУБД Vertica, хотя специально разработанное ПО может быть эффективнее.
Предусмотрена бесплатная версия Vertica Community Edition, позволяющая разработчикам и аналитикам создавать собственные приложения и обмениваться опытом с сообществом пользователей Vertica. Данная редакция включает инструментарий разработчика для описания и выполнения аналитических запросов, позволяющий использовать аналитическую библиотеку внутри СУБД, а также обеспечивает встроенную поддержку для ряда функций: поиск серий событий по шаблону, объединение серий событий, линейная регрессия и т.д. Vertica Community Edition включает все свойства полной версии, но ограничена по масштабируемости — до 1 Тбайт данных и трех машин в кластере, что, однако, позволяет строить реальные системы для небольших компаний или отделов.
Виртуализация, облака и Vertica
Поскольку аналитическая СУБД Vertica изначально предназначена для работы в горизонтально масштабируемой MPP-среде и лицензируется не по процессорам, а по объему обрабатываемых данных, то ее легко помещать в облачные среды, например VMware vSphere или Amazon Elastic Compute Cloud. Преимуществом виртуализованной среды является быстрота развертывания, так как все узлы в комплексе Vertica одинаковы, а готовый образ виртуальной машины зарегистрированный пользователь может скачать с сайта. Виртуализованный, или облачный, вариант рекомендуется использовать для экспериментальных и непродолжительных аналитических проектов, а также предоставления аналитических сервисов в режиме SaaS пользователям одного облака.
Для работы с Большими Данными рекомендуется выделять для СУБД Vertica отдельное оборудование, хотя в случае публичных облаков это может быть услуга типа PaaS (платформа как сервис), а в случае частных самым простым путем будет приобретение Vertica Appliance с предустановленным ПО и сконфигурированным аппаратным комплексом. Выбрав одну из базовых моделей на 5, 10, 20 или 50 Тбайт, в дальнейшем можно наращивать ее емкость и производительность.
Кирилл Вахрамеев (kirill.vakhrameev@hp.com) – cпециалист по бизнес-критичным решениям компании HP, OpenVMS Ambassador (Москва).