
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Постановка проблеми очищення даних
- 3. Классификация існуючих помилок
- 4 Методи і засоби очищення даних в сучасних корпоративних інформаційних системах
- 5 Тип помилок. Пропуски в даних
- 6 Тип помилок. Cуперечливість інформації
- 7 Тип помилок. Дублювання
- 8 Тип помилок. Невідповідність форматів
- Висновки
- Перелік посилань
Вступ
В сучасному світі якісна інформація у великих корпораціях грає ключову роль. І багато проектів безпосередньо залежать від якості даних і реалізації їх на підприємстві. Тому дуже важливо, щоб кожна філія поставляkf такі дані, зміст яких мав невеликий коефіцієнт «забруднених» даних, інакше при їх інтеграції в Сховище даних відсоток «забруднення» зростає за експоненціальним законом.
Очищення даних (data cleaning, data cleansing або scrubbing) виявляє і видаляє помилки і невідповідності цих даних з метою поліпшення якості даних [ 5 ].
1. Актуальність теми
На сьогоднішній день у величезні корпорації надходить і обробляється велики кількість даних, особливо персональних, зібраних з усіх філій компанії. У кожній філії своя структура бази даних, і після інтеграції в єдине джерело даних (наприклад, в Сховища даних (СД)), виникає проблема вилучення достовірних даних через розрізнення даних у різному поданні, які необхідно в подальшому використовувати для аналізу. Такі дані будуть низької якості, тому що в них допускалися помилки, і обробляти їх втрачає всякий сенс. Тому, для отримання реальних висновків з існуючих даних, застосовують різні методи по їх корекції, виключення дублікатів та очищення.
Таким чином, завдання очищення даних в корпоративних інформаційних системах на сьогоднішній день є актуальною.
2. Постановка проблеми очищення даних
В даний час на ринку існує безліч засобів з очищення даних, таких фірм як Trillium Software, Group-1 Software, Innovative Systems, Vality /Ascential Software, First Logic, Deductor тощо [ 7 ]. Вони допомагають виявити і автоматично виправити найбільш важливі типи в персоналізації даних (наприклад: імена і адреси людей з використанням національного каталогу імен та адрес). Але ці засоби не ідеальні. Вони не можуть працювати з усіма типами «брудних» даних, і з цієї причини, не всі компанії використовують вже існуючі засоби. Немаловажну роль в їх застосуванні також відіграє і вартість цих програмних пакетів. Недостатня увага приділяється якості даних, пов’язана з тим, що відсутнє розуміння типів, обсягу забрудненості (які були імпортовані в Сховища даних), їх впливу (вони будуть у майбутньому впливати на достовірність отриманої інформації з Сховища даних).

Рисунок 1 – Очищення даних
(анімація: 5 кадрів, 6 циклів повторення, 14,2 кілобайт)
Для початку корпораціям необхідно розібратися в різноманітті можливих «брудних» даних, в джерелах їх появи, методах їх виявлення і очищення [ 6 ].
| П.І.Б. | Пол | Місто | Адреса | Модель машини | Телефон |
|---|---|---|---|---|---|
| ... < td> | ... | ... | ... | ... | ... |
| Іванов І.І. | М | Вул. Ходаковського д.6б кв. 5 | Corolla | +380502456987 | |
| Петров П.П. | ж | Макіївка | Вулиця Леніна д. 7 | Camry | 0635689568 |
| Сидоров С.С. | Донецьк | Просп. Ілліча д. 6 кв.8 | Yaris | (067) 356-87-98 | |
| Сидоров С.С. | M | Донецьк | Просп. Ілліча д. 6 кв.8 | Yaris | (067) 356-87-98 |
| ... | ... | ... | ... | ... | ... |
3. Класифікація існуючих помилок
Існує безліч видів помилок, які не залежать від предметної області. Таких помилок виділяють шість типів:
- Суперечливістю інформації називається така інформація, яка не відповідає законам, правилам або дійсності. Спочатку вирішується, що саме необхідно вважати суперечливим. Наприклад, за законами Україні пенсійну карту змінюють уразі зміни П.І.Б., але якщо людина народилася чоловіком, а вийшла на пенсію жінкою, суперечливість відсутній [ 3 ].
- аномальними значеннями називаються такі значення, які сильно вибиваються в цілому із загальної картини. Найчастіше такі значення коригують вручну. Це пов’язано з тим, що такі засоби прогнозування нічого не знають про природу процесів. Тому будь-яка аномалія буде сприйматися як абсолютно нормальне значення. Через це буде сильно спотворюватися картина майбутнього. Якийсь випадковий провал чи успіх буде вважатися закономірністю [ 3 ].
- Пропуск даних називається такий тип помилок, якщо в полях для заповнення відсутні дані або заповнені не до кінця. Ця проблема вважається дуже серйозною для більшості СД. Більшість методів прогнозування виходять із припущення, що дані надходять рівномірним постійним потоком. На практиці таке можна зустріти рідко. Тому одна з найбільш затребуваних областей застосування СД – прогнозування – виявляється реалізованої неякісно або зі значними обмеженнями [ 3 ].
- Шум – це дані, в яких показання значно вище або нижче оптимальних значень. Часто при аналізі даних стикаються з шумами. Він не несе ніякої цінної інформації, тільки заважає чітко розгледіти картину.
- Невідповідність форматів даних. Невідповідність форматів даних називаються однотипні дані, що мають різні формати подання.
- Помилки введення даних або друкарські помилки переважають у будь-яких даних, тому що вводяться людиною. Опечатки – це такий тип помилок, коли дані містять пропущені, зайві символи або спотворені дані.
- Дублювання – це повторювані дані. Повторення різних даних – найпоширеніша помилка при роботі з даними, які заносяться в Сховища даних.
Виходячи з наведених вище даних можна виявити такі типи помилок як:
- пропуски даних (не вказано місто);
- дублювання (Сидоров С.С. і Сидоров С.С.);
- протіворечівость інформації (Петров П.П. ж);
- невідповідність форматів даних (Вул. вулиця, Вул).
4. Методи і засоби очищення даних в сучасних корпоративних інформаційних системах
На сьогоднішній день існує величезна кількість методів по очищенню даних від помилок і неточностей. Ніхто з фахівців не скаже, який із них є найефективнішим, бо кожен метод абсолютно по-різному підходить до цієї проблеми.
Дану проблему вирішують трьома різними способами:
- простими методами;
- методами, що грунтуються на поняттях математичної статистики;
- засоби ETL (від англ. Extract, Transform, Load – дослівно «витяг, перетворення, завантаження» - один з основних процесів в управлінні сховищами даних [ 5 ]).
Прості методи (регулярні вирази, суворі формальні правила і т.д.) дуже примітивні і можуть вирішити дану задачу тільки частково, тому вчені вирішили задіяти математичну статистику та інтелектуальні методи.
Розраховуються необхідні показники за всіма даними, які є в наявності, тобто охоплює весь діапазон існуючих значень і прийнятих ознаками. На основі отриманих результатів одні методи можуть виділити підозрілу інформацію, яка сильно відрізняється від інших, а інші – Обчислити величини, які ймовірно найбільше схожі на справжні. Таким чином, аналізуючи відомості за допомогою статистичних характеристик, оцінюють загальну картину даних і вже на її тлі визначають можливі помилки з подальшим їх виправленням на підібрані схожі значення [ 2 ].
5. Тип помилок. Пропуски в даних
Цей тип помилок можна вирішити двома різними способами:
- Методом машинного словника. Він являє собою упорядкований безліч лінгвістичної інформації, яка зберігається в пам'яті комп'ютера в певному вигляді. Метод шукає необхідне перевиряємого слово в заздалегідь складеному машинному словнику. У нього повинні входити всілякі значення, прийняті даними полем. При роботі з особистою інформацією використовуються класифікатори. Класифікатор – це словник, що складається з назв об'єктів, класифікаційних угруповань, на які вони розбиті за ступенем подібності, і ідентифікують їх кодів. Наприклад, класифікатор телефонних кодів і мобільних операторів, класифікатор адрес і так далі. За допомогою саме класифікаторів можна позбавлятися від пропусків в полях. Тоді незаповнена частина інформації шукається в класифікаторі за наявними даними. Якщо буде знайдений тільки один підходящий варіант, то він вноситься замість пропуску. В іншому випадку всі знайдені значення видаються експерту, що приймає рішення, він вибирає, який з варіантів ближчий до вихідного [ 2 ].
- Інтелектуальний метод. Іноді в даних буває так, що забувають вказати місто чи індекс у полі адреси, тоді можна скористатися «поліпшенням». Поліпшення служить додатком до вже існуючої інформації ряду фактів, наприклад, можна додати країну, область, район, довгота і широта зазначеної місцевості і т.д. Також можна за допомогою цього методу привласнити клієнтам пол на підставі аналізу його імені та інших показників його профайла. Найбільш же цінним доповненням клієнтського профайла є додаткові дані, тобто дані третіх фірм, які містять демографічну та психографічну інформацію [ 2 ].
6. Тип помилок. Суперечливість інформації.
- Простий метод. За допомогою класифікатора ідентифікують коди визначані як «брудні» дані. Якщо хоча б одному перевіряємому значенню не буде сопоставлен його код або отримані коди пов’язаних даних суперечать один одному, то в них, швидше за все, була допущена помилка. Для того щоб усунути її, необхідно перевірити поля окремо на наявність помилок або розглядають додаткові значення, за якими можливо будуть відновлені втрачені дані. Потім знову необхідно проводити пошук кодів в класифікаторі з уже новими отриманими даними до тих пір, поки не буде усунутий цей тип помилок [ 2 ].
- Перевірка допустимості. Буває так, що людина може ввести неправильний код міста, в якому проживає або ж місто, може бути не зіставимо з районом проживання і т.д. В цьому випадку необхідно використовувати інтелектуальні засоби, за допомогою яких можливо здійснити розпізнавання допустимих міжнародних адрес. Деякі програми об’єднуються з програмами перевірки допустимості та файлами поштових адрес, перевіряючих допустимість міжнародних адресних даних [ 1 ].
7. Тип помилок. Дублювання
- Метод «жорстких» правил. Суть методу передбачає поетапне порівняння параметрів об’єктів із застосуванням «жорстких» правил розрахунку коефіцієнтів
збігу по кожному перевіряється полю. Отриманий коефіцієнт схожості об’єктів розраховується як сума коефіцієнтів по кожному полю і, якщо
його значення перевищує заданий поріг, то об’єкти вважаються дублікатами. На малюнку 1 механізм роботи представлений.
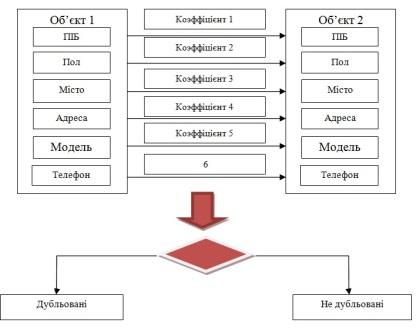
Рисунок 3 – Схема роботи методу «жорстких» правил- самонавчальний алгоритм пошуку дублікатів. Цей метод заснований на застосуванні самообучающихся моделей для пошуку потенційних дублікатів. Модуль складається з таких кроків: навчання і застосування моделей. На першому кроці необхідно підготувати вибірку даних, на якій буде відбуватися навчання моделі. Після цього кроку модель вводиться в режим промислової експлуатації. Застосування даного підходу передбачає періодичне перенавчання побудованих моделей, що дозволяє адаптувати їх під зміни в даних.
- Порівняння та обробка результатів. Даний модуль забезпечує порівняння та оцінку результатів, отриманих із застосуванням «жорстких» правил і самообучающихся моделей. Крім того, формується підсумковий набір потенційно схожих об’єктів. Потім потенційні дублікати піддаються угрупованню, правила якої завжди індивідуальні, залежно завдань. Один з доступних варіантів об’єднання дублікатів – формування груп схожих клієнтів, які проживають в одному районі або місто [ 4 ].
- Узгодження і консолідація. Узгодження необхідно для розстановки пріоритетів між полями (в процесі узгодження) та контролю черговості порівняння полів.
8. Тип помилок. Невідповідність форматів
Стандартизація. Дані імен, телефонів і адрес можуть вводитися в різних форматах, які цілком граматично коректні. Наприклад, "Вулиця", "Вул." І "Вул" позначають одне і те ж очевидне поняття в складі адреси. Або ж номери телефонів "(063) 111 11 11", "+380631111111" і "+38 (063) 1111111". У поштового і телефонного служби існують стандарти для цих та інших подібних випадків (поки тільки такі служби існує в Сполучених Штатів Америки і в Росії). Найважливішим об’єктом стандартизації є записи по клієнтах, точність яких може бути істотно підвищена за рахунок використання процесу узгодження, описаного далі. Спеціальні програми стандартизації трансформують такі поля в певний шаблон, що підходить для поштового і телефонного служби.
Висновок
Незважаючи на те, що існують безліч платформ, систем, інструментів для перетворення та очищення даних, їх все одно не вистачає. Ці кошти ідеально не приберуть дублювання, втрати даних, невідповідності. Тому і зараз фахівці намагаються знайти оптимальні варіації для рішення очищення даних
Перелік посилань
1. Чубукова И.А. Статья: Процесс Data Mining. Начальные этапы [электронний ресурс] — Режим доступу: http://www.intuit.ru/...
2. Беликова Александра. Статья: Проблема обработки персональных данных [электронний ресурс] — Режим доступу: http://www.basegroup.ru/library/...
3. Арустамов Алексей. Статья: Предобработка и очистка данных перед загрузкой в хранилище [электронний ресурс] — Режим доступу: http://sysdba.org.ua/proektirovanie-bd/etl/predobrabotka-i-ochistka-dannyih-pered-zagruzkoy-v-hranilische.html
4. Basegroup. Статья: Технология обработки клиентских баз [электронний ресурс] — Режим доступу: http://www.dupmatch.com/...
5. Статья: ETL. [электронний ресурс] — Режим доступу: http://ru.wikipedia.org/wiki/ETL
6. Вон Ким. Статья: Три основных недостатка современных хранилищ данных [электронний ресурс] — Режим доступу: http://citforum.ru/data...
7. Роналд Фоурино. Статья: Электронное качество данных: скрытая перспектива очистки данных [электронний ресурс] — Режим доступу: http://www.iso.ru/р... - Электронный ресурс, хранящий статьи, которые были обублекованные в известных журналах