
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Научная новизна
- 4. Обзор исследований и разработок
- 4.1 Нейронные сети
- 4.1.1 Разработка метода с использованием нейронных сетей и ГА
- 4.2 Генетические алгоритмы
- 4.2.1 Разработка метода с использованием ГА
- Выводы
- Список источников
Введение
Эффективность работы любой отрасли в значительной мере определяется уровнем информационных технологий и широтой их применения. В медицине особое значение приобретает направление, связанное с разработкой систем поддержки принятия решений, развитием телемедицины, поскольку все эти усовершенствования и определяют новые диагностические и лечебные возможности. Системы интеллектуальной поддержки принятия врачебного решения (диагностического или лечебного) информируют врача о критических ситуациях в состоянии пациента, связанных с выходом отдельных показателей состояния организма за допустимые значения. Хорошо известно, что человек не в состоянии следить за поведением более семи каких-либо объектов (параметров) одновременно. Поэтому с ростом количества сообщаемых такими системами фактов критического изменения показателей состояния пациента анализ ситуации и принятие врачом диагностических и лечебных решений становится все более затруднительным. Легко себе представить, что запредельное количество поступающей к врачу информации способно стать помехой для принятия обоснованных врачебных решений. Таким образом, система оказания интеллектуальной поддержки решениям врача, должна взять на себя функцию предварительного сжатия и обобщения информации, выделения существенных элементов и отсеивания ненужной, мешающей информации.
1. Актуальность темы
Ежегодно в мире при родах и в послеродовом периоде умирает 350–370 женщин. Самая частая причина смертности – акушерское кровотечение. Акушерские кровотечения являются одним из самых опасных осложнений, которые могут произойти во время родов, частота их появления 2–3% из всех случаев. Возможность прогнозирования патологической акушерской кровопотери накануне родов позволит своевременно создать запасы кровезаменителей, плазмы, препаратов крови, возможно и аутокрови, а также оказать адекватную терапию с привлечением высококвалифицированных реаниматологов, акушеров-гинекологов и сосудистых хирургов для проведения органосохраняющих операций (перевязка сосудистых пучков и подчревных артерий) в случае развития послеродового кровотечения.
2. Цель и задачи исследования
Целью исследования является выбор направления собственных исследований в области прогнозирования развития патологий в акушерстве и гинекологи, разработка СКС прогнозирования развития потери крови при родах с помощью ГА.
Основные задачи исследования:
- Анализ поставленной проблемы прогнозирования развития патологий в акушерстве и гинекологии
- Рассмотрение существующих методов прогнозирования развития патологий в акушерстве и гинекологии.
- Разработка алгоритма прогнозирования развития патологий в акушерстве и гинекологии.
- Разработка программного обеспечения СКС прогнозирования развития патологий в акушерстве и гинекологии.
Объект исследования: процесс проектирования и разработки методов получения знаний медицинских систем поддержки принятия решений.
Предмет исследования: методы разработки получения знаний для систем поддержки принятия решений в акушерстве и гинекологии.
Методы исследования базируются на методах искусственного интеллекта, основных положениях теории вероятностей и математической статистики. Предполагается применить метод группового учета аргументов, генетический алгоритм.
3. Научная новизна
Научная новизна заключается в кодировании хромосомы и применении генетического алгоритма для построения регрессионной модели и отбора факторов риска одновременною.
Нейронные сети можно рассматривать как современные вычислительные системы, которые преобразуют информацию по образу процессов, происходящих в мозгу человека. Обрабатываемая информация имеет численный характер, что позволяет использовать нейронную сеть, например, в качестве модели объекта с совершенно неизвестными характеристиками. Другие типовые приложения нейронных сетей охватывают задачи распознавания, классификации, анализа и сжатия образов.
В самом упрощенном виде нейронную сеть можно рассматривать как способ моделирования в технических системах принципов организации и механизмов функционирования головного мозга человека. Согласно современным представлениям, кора головного мозга человека представляет собой множество взаимосвязанных простейших ячеек – нейронов, количество которых оценивается числом порядка 1010. Технические системы, в которых предпринимается попытка воспроизвести, пусть и в ограниченных масштабах, подобную структуру (аппаратно или программно), получили наименование нейронные сети.
Данный метод сложно реализуем так как практически тяжело отследить правильность работы данного метода на этапе отладки. А так же невозможность интерпретации промежуточных данных и сложность разъяснения результатов работы сети делает данный метод крайне неудобным для применения у данном случае.
Отбор информативных параметров выполняется с помощью нейронных сетей (НС) [4, 5] и генетических алгоритмов (ГА) [2, 3]. Такой подход совместное использование НС и ГА) позволит не просто выполнить отбор факторов риска, а выбрать информативный набор данных, сохранив взаимосвязанные переменные.
Для реализации такого подхода сначала необходимо разработать НС для определения риска развития акушерских кровотечений. Для практики самым важным является определение риска потери крови при родах более чем 0,5% от массы тела, с целью принятия соответствующих мер. В этом случае, по сути, выполняется классификация на два класса: патологическое кровотечение и допустимое. Для реализации поставленной задачи в такой форме целесообразно использовать многослойную НС прямого распространения. Такой тип НС показывает хорошие результаты при обучении с учителем, а так как у нас имеется обучающая выборка с реальными медицинскими данными, то выберем многослойную НС для классификации на патологическую и обычную потерю крови при родах. Таким образом, на первом этапе необходимо выбрать архитектуру нейронной сети и обучить ее. Учитывая то, что в дальнейшем (при отборе факторов риска) на каждом шаге выполнения ГА будет происходить обучение НС, целесообразно выбирать архитектуру сети с минимальной сложностью, что позволит уменьшить время выполнения программы. Под сложностью сети будем предполагать вычислительную сложность алгоритма обучения НС. Под вычислительной сложностью алгоритма обучения будем понимать количество операций за один шаг обучения. Известно, что для алгоритма обратного распространения количество операций связано линейной зависимостью с синаптическими весами (включая пороги) [3]. Т. е. вычислительную сложность определяет число скрытых слоев и число нейронов на каждом из них. В результате проведенных экспериментов выбрана архитектура НС, представленная на рис. 1. Количество входов обусловлено максимальным количеством факторов риска (после кодирования их получили 99). Выбранные активационные функции – гиперболический тангенс и линейная функция.
После того как определена и успешно обучена НС, выполняется ГА, который подает различные комбинации факторов риска на входы НС и затем выполняется попытка обучить сеть при такой комбинации отобранных факторов риска. Принцип реализации кодирования хромосомы представлен на рис. 2. Каждая хромосома представляет собой последовательность определенного количества битов (определяется максимальным количеством факторов риска). Значение каждого бита равно 1, если фактор с соответствующим номером присутствует в данном наборе, и нулю, если этот фактор отсутствует. Предусмотрены различные варианты параметров ГА в качестве метода селекции можно выбирать колесо рулетки или турнир (с указанием количества особей в туре); в качестве метода редукции предусмотрена элитарная стратегия, полная замена, частичная замена популяции (с указанием процента заменяемых особей); можно задавать вероятность операции мутации и скрещивания (предусмотрен одноточечный и двухточечный оператор скрещивания). В качестве критерия останова можно использовать определенное количество итераций или указать количество повторений результата.
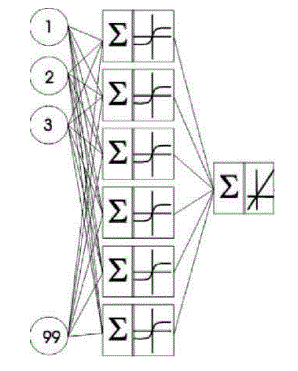
Рисунок 1 – Архитектура нейронной сети
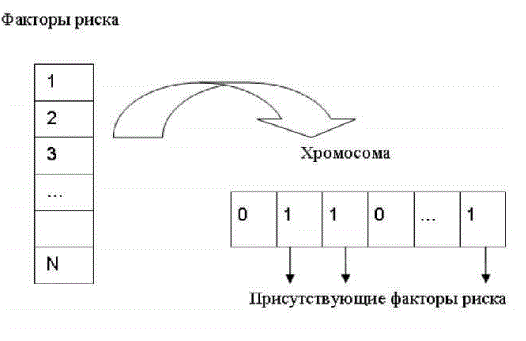
Рисунок 2 – Кодирование хромосомы
В предлагаемом подходе для выделения признаков использован генетический алгоритм, который имеет модифицированную схему реализации применительно к задаче многокритериальной оптимизации. В то время как большинство подобных методов, используемых для решения таких задач, использует единый, составной оптимизируемый критерий [4]. Решением задачи в данном случае является несколько недоминируемых подмножеств признаков. Разработана фитнесс-функция (1), которая предполагает поиск решения, являющегося оптимальным согласно двум критериям – учитывается точность классификации и количество факторов риска. К тому же данная фитнесс-функция позволяет задавать желаемое соотношение точности классификации и количества факторов риска.
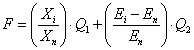 |
(1) |
где Xi – количество присутствующих факторов риска в i-й хромосоме, Xn – максимальное количество факторов риска, Ei – ошибка обучения НС для i-й хромосомы, En – ошибка обучения НС при использовании максимального количества факторов, Q1 и Q2 – коэффициенты, с помощью которых регулируется соотношение между точностью классификации и числом факторов риска. Рекомендуется выбирать диапазон значений (2), и придерживаться условия (3).
| (2) |
| (3) |
После этапа подготовки данных получили обучающий массив размером 99 х 100, где 99 входных параметров и 100 обучающих примеров. Данная выборка разделена на две – по 50 примеров в каждой. По первой выборке проводилось обучение нейронной сети и отбор признаков с помощью генетических алгоритмов. В результате количество факторов уменьшилось практически в два раза. Затем, на второй выборке успешно протестирована нейронная сеть, с использованием только выделенных факторов. Таким образом, результат можно считать положительным и переходить к этапу построения и обучения аналитической системы прогнозирования потери крови при родах.
Генетический алгоритм представляет собой метод, отражающий естественную эволюцию методов решения проблем, и в первую очередь задач оптимизации. Генетические алгоритмы – это процедуры поиска, основанные на механизмах естественного отбора и наследования. В них используется эволюционный принцип выживания наиболее приспособленных особей. Они отличаются от традиционных методов оптимизации несколькими базовыми элементами. В частности, генетические алгоритмы:
- обрабатывают не значения параметров самой задачи, а их закодированную форму;
- осуществляют поиск решения исходя не из единственной точки, а из их некоторой популяции;
- используют только целевую функцию, а не ее производные либо иную дополнительную информацию;
- применяют вероятностные, а не детерминированные правила выбора.
Поиск (суб)оптимального решения задачи выполняется в процессе эволюции популяции – последовательного преобразования одного конечного множества решений в другое с помощью генетических операторов репродукции, кроссинговера и мутации. Наличие у генетических алгоритмов целой «популяции» решений совместно с вероятностным механизмом мутации, позволяют предполагать меньшую вероятность нахождения локального оптимума и большую.
Генетические алгоритмы предназначены для решения задач оптимизации. Примером подобной задачи может служить обучение нейросети, то есть подбора таких значений весов, при которых достигается минимальная ошибка. При этом в основе генетического алгоритма лежит метод случайного поиска. Основным недостатком случайного поиска является то, что нам неизвестно сколько понадобится времени для решения задачи. Для того, чтобы избежать таких расходов времени при решении задачи, применяются методы, проявившиеся в биологии. При этом используются методы открытые при изучении эволюции и происхождения видов. Как известно, в процессе эволюции выживают наиболее приспособленные особи. Это приводит к тому, что приспособленность популяции возрастает, позволяя ей лучше выживать в изменяющихся условиях.
Впервые подобный алгоритм был предложен в 1975 году Джоном Холландом (John Holland) в Мичиганском университете. Он получил название «репродуктивный план Холланда» и лег в основу практически всех вариантов генетических алгоритмов. Однако, перед тем как мы его рассмотрим подробнее, необходимо остановится на том, каким образом объекты реального мира могут быть закодированы для использования в генетических алгоритмах [6].
Представление объектов
Из биологии мы знаем, что любой организм может быть представлен своим фенотипом, который фактически определяет, чем является объект в реальном мире, и генотипом, который содержит всю информацию об объекте на уровне хромосомного набора. При этом каждый ген, то есть элемент информации генотипа, имеет свое отражение в фенотипе. Таким образом, для решения задач нам необходимо представить каждый признак объекта в форме, подходящей для использования в генетическом алгоритме. Все дальнейшее функционирование механизмов генетического алгоритма производится на уровне генотипа, позволяя обойтись без информации о внутренней структуре объекта, что и обуславливает его широкое применение в самых разных задачах.
В наиболее часто встречающейся разновидности генетического алгоритма для представления генотипа объекта применяются битовые строки. При этом каждому атрибуту объекта в фенотипе соответствует один ген в генотипе объекта. Ген представляет собой битовую строку, чаще всего фиксированной длины, которая представляет собой значение этого признака.
Кодирование признаков, представленных целыми числами
Для кодирования таких признаков можно использовать самый простой вариант – битовое значение этого признака. Тогда нам будет весьма просто использовать ген определенной длины, достаточной для представления всех возможных значений такого признака. Но, к сожалению, такое кодирование не лишено недостатков. Основной недостаток заключается в том, что соседние числа отличаются в значениях нескольких битов, так например числа 7 и 8 в битовом представлении различаются в 4-х позициях, что затрудняет функционирование генетического алгоритма и увеличивает время, необходимое для его сходимости. Для того, чтобы избежать эту проблему лучше использовать кодирование, при котором соседние числа отличаются меньшим количеством позиций, в идеале значением одного бита. Таким кодом является код Грея, который целесообразно использовать в реализации генетического алгоритма. Значения кодов Грея рассмотрены в таблице ниже:
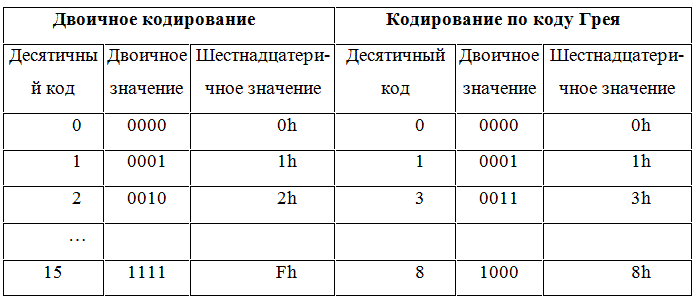
Таблица 1 – Соответствие десятичных кодов и кодов Грея
Таким образом, при кодировании целочисленного признака мы разбиваем его на тетрады и каждую тетраду преобразуем по коду Грея.
В практических реализациях генетических алгоритмов обычно не возникает необходимости преобразовывать значения признака в значение гена. На практике имеет место обратная задача, когда по значению гена необходимо определить значение соответствующего ему признака.
Таким образом, задача декодирования значения генов, которым соответствуют целочисленные признаки, тривиальна.
Схема функционирования генетического алгоритма
Теперь, зная как интерпретировать значения генов, перейдем к описанию функционирования генетического алгоритма. Рассмотрим схему функционирования генетического алгоритма в его классическом варианте.
- Инициировать начальный момент времени t=0. Случайным образом сформировать начальную популяцию, состоящую из k особей:
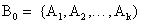
- Вычислить приспособленность каждой особи
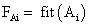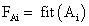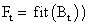 , i=1…k и популяции в целом
, i=1…k и популяции в целом 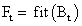 (также иногда называемую термином фиттнес). Значение этой функции определяет насколько хорошо подходит особь, описанная данной хромосомой, для решения задачи.
(также иногда называемую термином фиттнес). Значение этой функции определяет насколько хорошо подходит особь, описанная данной хромосомой, для решения задачи.
- Выбрать особь
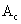 из популяции
из популяции 
- С определенной вероятностью (вероятностью кроссовера) выбрать вторую особь из популяции
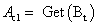 и произвести оператор кроссовера
и произвести оператор кроссовера 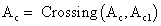 .
.
- С определенной вероятностью (вероятностью мутации) выполнить оператор мутации .
- С определенной вероятностью (вероятностью инверсии) выполнить оператор инверсии
 .
.
- Поместить полученную хромосому в новую популяцию
 .
.
- Выполнить операции, начиная с пункта 3, k раз.
- Увеличить номер текущей эпохи t=t+1.
- Если выполнилось условие останова, то завершить работу, иначе переход на шаг 2.
Теперь рассмотрим подробнее отдельные этапы алгоритма.
Наибольшую роль в успешном функционировании алгоритма играет этап отбора родительских хромосом на шагах 3 и 4. При этом возможны различные варианты. Наиболее часто используется метод отбора, называемый рулеткой. При использовании такого метода вероятность выбора хромосомы определяется ее приспособленностью, то есть ![]() .
Использование этого метода приводит к тому, что вероятность передачи признаков более приспособленными особями потомкам возрастает. Другой часто используемый метод – турнирный отбор. Он заключается в том, что случайно выбирается несколько особей из популяции (обычно 2) и победителем выбирается особь с наибольшей приспособленностью.
Кроме того, в некоторых реализациях алгоритма применяется так называемая стратегия элитизма, которая заключается в том, что особи с наибольшей приспособленностью гарантировано переходят в новую популяцию. Использование элитизма обычно позволяет ускорить сходимость генетического алгоритма. Недостаток использования стратегии элитизма в том, что повышается вероятность попадания алгоритма в локальный минимум.
.
Использование этого метода приводит к тому, что вероятность передачи признаков более приспособленными особями потомкам возрастает. Другой часто используемый метод – турнирный отбор. Он заключается в том, что случайно выбирается несколько особей из популяции (обычно 2) и победителем выбирается особь с наибольшей приспособленностью.
Кроме того, в некоторых реализациях алгоритма применяется так называемая стратегия элитизма, которая заключается в том, что особи с наибольшей приспособленностью гарантировано переходят в новую популяцию. Использование элитизма обычно позволяет ускорить сходимость генетического алгоритма. Недостаток использования стратегии элитизма в том, что повышается вероятность попадания алгоритма в локальный минимум.
Другой важный момент – определение критериев останова. Обычно в качестве них применяются или ограничение на максимальное число эпох функционирования алгоритма, или определение его сходимости, обычно путем сравнивания приспособленности популяции на нескольких эпохах и остановки при стабилизации этого параметра.
При построении математической функции классификации или регрессии основная задача сводится к выбору наилучшей функции из всего множества вариантов. Дело в том, что может существовать множество функций, одинаково классифицирующих одну и ту же обучающую выборку (рис. 3).
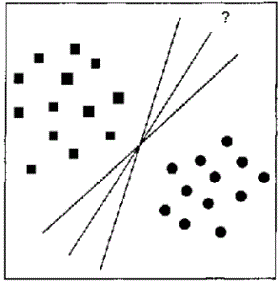
Рисунок 3 – Варианты линейного разделения обучающей выборки
Для построения регрессионной модели необходимо выполнить отбор необходимых факторов и затем рассчитать коэффициенты уравнения. Естественно выбирая тот или иной набор параметров можно получать различные регрессионные модели, причем многие из них будут показывать хорошие результаты. Таким образом, для построения оптимальной модели необходимо решить две задачи: выбрать факторы риска, которые будут переменными множественной регрессии; и рассчитать коэффициенты уравнения. Отбор факторов риска является непростой задачей [4], которую можно решать с помощью ГА [5]. Предлагается решать эти две задачи одновременно.
Разработка метода
Стандартный ГА [3, 2] предполагает следующую последовательность, (рис.4).

Рисунок 4 – Простой генетический алгоритм
- На первом этапе выполняется генерация начальной популяции, где случайным образом генерируется некоторое количество особей. Важным этапом является разработка способа кодирования хромосомы, так как каждая особь это возможное решение задачи (уравнение множественной регрессии).
Мы предлагаем следующую структуру хромосомы, (рис. 5). Каждая особь представляется последовательностью определенного количества битов (определяется максимально возможным количеством факторов риска). Значение каждого бита может быть равно «1», если фактор с соответствующим номером присутствует в данном уравнении регрессии, и «0», если этот фактор отсутствует.
Таким образом, каждой хромосоме соответствует регрессионная модель, построенная методом наименьших квадратов (МНК), с соответствующим ее структуре набором факторов риска.

Рисунок 5 – Кодирование хромосомы
(анимация: 7 кадров, 6 циклов повторения, 39,2 килобайт) - Второй этап подразумевает расчет фитнес-функции. В качестве фитнес-функции выступает ошибка регрессионной модели, которая может рассчитываться по формуле (4):
где N – количество примеров в обучении, y – полученный результат регрессионной модели, yy – действительный результат.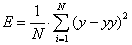
(4)
Рассчитанная ошибка сопоставляется каждой хромосоме. Лучшая особь будет иметь минимальную ошибку, то есть минимальную фитнес-функцию.
Третий этап является реализацией генетического алгоритма. Генетические операторы выполняются стандартные. - Наиболее распространенный метод реализации оператора репродукции (ОР) – построение колеса рулетки, в котором каждой хромосоме соответствует сектор, пропорциональный ее значению фитнесс-функции, что обеспечивает большую вероятность выбора лучших особей для оператора кроссинговера.
- Применяется простой оператор кроссинговера (ОК), который выполняется в 3 этапа:
1) выбираются две хромосомы (родители) из текущей популяции;
2) случайно выбирается точка скрещивания – число k из диапазона [1,2…n–1], где n – длина хромосомы;
3) две новых хромосомы ,
, 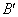 (потомки) формируются из A и B путем обмена подстрок после точки скрещивания, (рис. 6).
(потомки) формируются из A и B путем обмена подстрок после точки скрещивания, (рис. 6).
ОК выполняется с заданной вероятностью (отобранные два родителя не обязательно производят потомков).
Рисунок 6 Формирование хромосом оператором кроссинговера
- Оператор мутации (ОМ) играет вторичную роль и его вероятность обычно мала. Оператор мутации выполняется в 2 этапа:
1) в хромосоме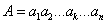 случайно выбирается k-ая позиция (бит) мутации(1 <= k <= n);
случайно выбирается k-ая позиция (бит) мутации(1 <= k <= n);
2) производится инверсия значения гена в k-й позиции, формула (5).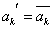
(5) - Следующий этап алгоритма предполагает расширение популяции за счет добавления новых, только что созданных особей.
- Затем полученную популяцию сокращаем до исходных размеров (работает оператор редукции), путем отбора лучших особей.
- Критериев останова работы алгоритма будет два: максимально заданное количество шагов; незначительное изменение значения фитнес-функции.
- После выполнения критерия останова выполняется поиск лучшей особи в конечной популяции, что является результатом работы алгоритма (уравнение множественной регрессии). В случае, не выполнения критерия останова, переходим на пункт 2.
Выводы
Процесс проектирования и разработки методов получения знаний медицинских систем поддержки принятия решений является одним из важных методов диагностики. В сфере современных технологий недостаточное внимание уделяется разработке СКС прогнозирования развития патологий в акушерстве и гинекологии, что дает возможность усовершенствовать и определить новые диагностические и лечебные возможности. Для повышения достоверности определения патологий при беременности на ранних стадиях можно внедрить разработанные методы и раньше начать применение профилактических мероприятий, направленных на снижения угрозы риска здоровья будущей мамы.
Магистерская работа посвящена актуальной научной задаче повышения достоверности определения патологий при беременности на ранних стадиях, внедрению разработанных методов для применения профилактических мероприятий, направленных на снижения угрозы риска здоровья будущей мамы. В рамках проведенных исследований выполнено:
- Пронализировано поставленная проблема прогнозирования развития патологий в акушерстве и гинекологии.
- Рассмотрены существующие методы прогнозирования развития патологий в акушерстве и гинекологии.
- Разработан алгоритм прогнозирования развития патологий в акушерстве и гинекологии.
- Подготовка рассмотренного математического аппарата для разработки программного обеспечения СКС прогнозирования развития патологий в акушерстве и гинекологии.
Рассмотрена актуальная задача выбора лучшей регрессионной модели, для прогнозирования потери крови при родах. В дальнейшем планируется реализовать рассмотренный математический аппарат и провести эксперименты на реальных медицинских данных, предоставленными сотрудниками центра материнства и детства. Планируется разработка и внедрение системы поддержки принятия решений (СППР) прогнозирования акушерских кровотечений.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Саймон Хайкин Нейронные сети: полный курс, 2-е издание. : Пер. с англ. / Саймон Хайкин // Издательский дом «Вильямс». – М.: 2006. – 1104 c.
- Д. Рутковская Нейронные сети, генетические алгоритмы и нечеткие системы / Д. Рутковская М. Пилиньский, Л. Рутковский. – М.: 2004. – 452 c.
- Ю.О. Скобцов Основи еволюційних обчислень / Ю. О. Скобцов. – Донецьк: ДонНТУ, 2009. – 316 с.
- Т.А. Васяева Анализ методов отбора факторов риска развития патологий в акушерстве и гинекологии / Т. А. Васяева, Д.Е. Иванов, И.В. Соков, А.С. Сокова // Збірка матеріалів ІІ Всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених.ІУС КМ-2011 11–13 квітня 2011р., Донецьк: ДонНТУ, 2011. – № 1. – С. 209–212.
- Т.А. Васяева Отбор факторов риска потери крови при родах / Т.А. Васяева, Д.Е. Иванов, И.В. Соков. // Інтелектуальні системи прийняття рішень і проблеми обчислювального інтелекту: Матеріали міжнародної наукової конференції. – Херсон: ХНТУ, 2011. – № 1. – 472 с.
- Г.К. Вороновский Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Г.К. Вороновский, К.В. Махотило, С.Н. Петрашев, С.А. Сергеев // заказное. – Х.: ОСНОВА, 1997. – 112 с.
- М.В. Медведев Дифференциальная ультразвуковая диагностика в гинекологии. // М.В. Медведев, Б.И. Зыкин, В.Л. Хохолин, Н.Ю. Стручкова. – М.: Видар, 1997.
- Генетические алгоритмы [Электронный ресурс]. – Режим доступа: http://www.gotai.net/documents/doc-ga-002.aspx.
- Популярно про генетичні алгоритми [Электронный ресурс]. – Режим доступа: http://www.victoria.lviv.ua/html/oio/html/theme10.htm.
- Genetic Algorithms [Электронный ресурс]. – Режим доступа: http://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol4/tcw2/report.html.