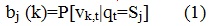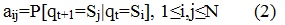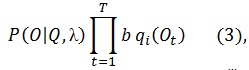Аннотация
Шевченко А.И., Меркулова Е.В. Создание специализированной компьютерной системы диагностики переломов бедренной кости по рентгенограммам. Выбран объект диагностики. Изучены материалы по теме диагностики переломов, классификации переломов. Проанализированы существующие методы обработки изображений, их достоинства и недостатки, выбраны оптимальные методы обработки изображений для СКС.
Общая постановка проблемы
Телемедицина позволяет поднять эффективность лечения и диагностики на качественно новый уровень. С помощью телемедицинских технологий можно, например, удаленному больному, оказать высококвалифицированную медицинскую помощь. Врачи могут поставить диагноз, на основании полученных через электронную почту или Интернет изображений рентгеновских снимков, компьютерных томограмм и т.д. В связи с тем, что зачастую основная часть узких специалистов в различных областях медицины работает в специализированных медицинских центрах крупных городов, это привело к определенной централизации медицинской помощи. Достижения телемедицины устраняют необходимость в физическом присутствии специалиста на месте.
К основным задачам телемедицины относят: повышение уровня обслуживания, снижение стоимости медицинских услуг, обслуживание удаленных субъектов, устранение изоляции.
Целью работы является исследование и выбор методов обработки изображения костей для специализированной компьютерной системы. Разработка СКС диагностики переломов бедренной кости.
К основным задачам относятся:
1. Анализ существующих компьютерных систем диагностики переломов.
2. Исследование и выбор методов классификации обработки изображений переломов костей для СКС.
3. Экспериментальное исследование выбранных методов и адаптация их для СКС.
4. Разработка структуры СКС и математическое, программное, информационное обеспечения для СКС.
Исследования
Объектом исследования является изображение бедренной кости (рентгенограмма). По анатомической локализации бывают переломы: проксимального конца, тела (диафиза), дистального конца. В данной работе рассматриваются переломы тела бедренной кости, т. е. диафиза (рис.1, а).
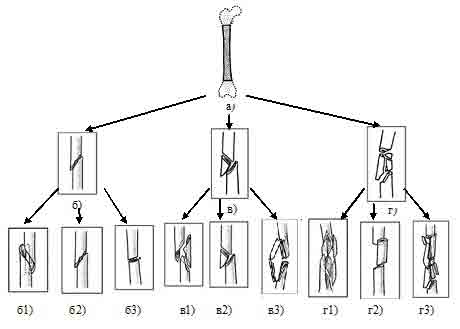
Рисунок 1 – Классификация переломов
Переломы диафиза делятся на простые (рис.1, б) – это простое круговое нарушение целостности диафиза, клиновидные (рис.1, в) – переломы с одним или несколькими промежуточными фрагментами, при котором после репозиции сохраняется контакт между основными отломками, а также сложные (рис.1, г) – это переломы с одним или несколькими промежуточными фрагментами, при котором после репозиции отсутствует контакт между основными отломками.
В свою очередь простые переломы бывают: спиральные (рис.1, б1), косые (рис.1, б2) и поперечные (рис.1, б3). Клиновидные переломы делятся на спиральные (рис.1, в1), изгиб клина (рис.1, в2) и фрагментированные (рис.1, в3). Комплексные переломы: спиральные (рис.1, г1), сегментные (рис.1, г2) и нерегулярные (рис.1, г3).
На рис. 2 представлены рентгенограммы кости со спиральным переломом с образованием дополнительного клиновидного фрагмента и простым поперечным перелом.
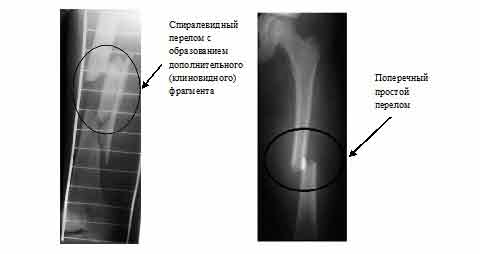
Рисунок 2 – Рентгенограммы бедренной кости
Были проанализированы следующие методы классификации обработки изображений: метод сравнения эталонов, методы оптического потока, а также методы, основанные на геометрических характеристиках. Все они имеют некоторые недостатки.
Недостаток метода сравнения эталонов заключается в том, что он требует много ресурсов как для хранения участков, так и для их сравнения. В виду того, что используется простейший алгоритм сравнения, изображения должны быть сняты в строго установленных условиях: не допускается заметных изменений ракурса, освещения и пр.
К недостаткам метода оптического потока в первую очередь относится его вычислительная трудоёмкость. На специализированном параллельном компьютере сравнение двух изображений занимало больше минуты. Метод неспособен извлекать компактный набор характеристик для хранения и поиска в базе.
Метод, основанный на геометрических характеристиках предъявляет строгие требования к условиям съёмки, нуждается в надёжном механизме нахождения ключевых точек для общего случая. Кроме того, требуется применение более совершенных методов классификации или построения модели изменений. В общем случае этот метод не самый оптимальный.
Марковские модели
Выбран основной метод, который будет использоваться при обработке изображения в данной СКС. Методы основаны на Марковских моделях. Марковские модели являются мощным средством моделирования различных процессов и распознавания образов. По своей природе Марковские модели позволяют учитывать непосредственно пространственно-временные характеристики сигналов, и поэтому получили широкое применение в распознавании речи, а в последнее время – изображений.
Цифровое изображение – суть случайный двумерный дискретный сигнал, который наблюдается системой. Последовательность наблюдений О=о1, о2, …, оT, где оt – сигналы, упорядоченные по пространственным отношениям, может извлекаться из изображения различными способами. В силу этого описательные способности полученных моделей могут различаться.
Каждая модель λ=(A, B, π) представляет собой набор N состояний S={S1, S2,…, SN}, между которыми возможны переходы. В каждый момент времени система находится в строго определённом состоянии. При переходе в каждое состояние генерируется наблюдаемый символ, который соответствует физическому сигналу с выхода моделируемой системы. Набор символов для каждого состояния V={v1, v2,…, vM}, количество символов M. Существуют так же модели, в которых набор символов для всех состояний одинаков.
Символ в состоянии qt=Sj в момент времени t генерируется с вероятностью:
Набор всех таких вероятностей составляет матрицу B={bj(k)}, где bj(k) – вероятность выпадения k-го значения параметра в j-м состоянии.
Матрица A={aij} определяет вероятность перехода из одного состояния в другое состояние:
Считается, что A не зависит от времени.
Также модель имеет вероятность начальных состояний π=πi, где πi=P[q1=Si] – вероятность того, что в начальный момент система окажется в i-м состоянии.
Модель λ=(A, B, π) с настроенными параметрами может быть использована для генерирования последовательности наблюдений. Для этого случайно, в соответствии с начальными вероятностями π выбирается начальное состояние, затем на каждом шаге вероятность B используется для генерации наблюдаемого символа, а вероятность A – для выбора следующего состояния. Вероятность P генерирования моделью λ последовательности состояний O:
где Q=q1, q2,…,qT – последовательность состояний.
Предполагается, что наблюдения статистически независимы.
В распознавании образов скрытые Марковские модели применяются следующим образом. Каждому классу i соответствует своя модель λ. Распознаваемый образ (изображение) представляется в виде последовательности наблюдений O. Затем для каждой модели λ вычисляется вероятность того, что эта последовательность могла быть сгенерирована именно этой моделью. Модель λj, получившая наибольшую вероятность, считается наиболее подходящей, и образ относят к классу j.
Модель называется «скрытой», так как нас, как правило, не интересует конкретная последовательность состояний, в которой пребывает система. Мы либо подаем на вход системы последовательности типа O={o1,o2,…oT}, где каждое oi – значение параметра, принимаемое в i-й момент времени, а на выходе ожидаем модель λ={A,B,π} с максимальной вероятностью генерирующую такую последовательность, – либо наоборот подаем на вход параметры модели и генерируем порождаемую ей последовательность.
Структура СКС
Основная последовательность операций при распознавании изображений приведена на рис. 3.
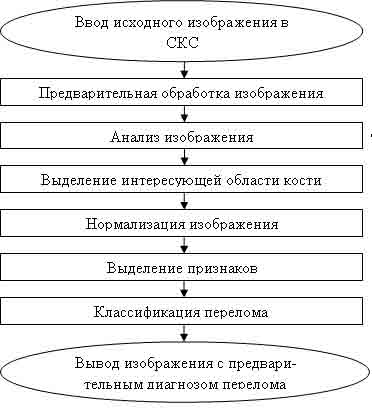
Рисунок 3 – Последовательность операций при распознавании
В большинстве случаев процесс автоматической классификации проводится в три этапа:
1. Этап подготовки изображения включает в себя непосредственный ввод изображения с камеры и предварительную обработку. Предварительная обработка, состоящая в максимальном приближении исследуемого изображения к эталонному или нормализованному. Чаще всего для медицинских изображений это пространственно инвариантные операции, сдвиг, изменение яркости, изменение контраста, квантование и геометрические преобразования (изменение масштаба, поворот оси). Теория этих преобразований хорошо разработана и, как правило, не вызывает трудностей при использовании современных ЭВМ.
2. Выделение признаков, при которых функция, представляющее обработанное изображение, подвергается функциональному преобразованию, выделяющему ряд наиболее существенных признаков, которые кодируются действительными числами. Выделение признаков заключается в математических преобразованиях изображения в зависимости от задачи анализа. Это может быть вычитание из эталона, вычитание постоянной составляющей для исключения мешающих теней, дифференцирование или автокорреляция для выделения контура, частотная фильтрация и многие другие. Правильный выбор алгоритма обработки имеет решающее значение для следующего этапа преобразования и представляет наибольшую трудность.
3. Классификация признаков. Полученные в результате предыдущей операции наборы действительных чисел, описывающие выделенные признаки, сравниваются с эталонными числами, заложенными в память машины. ЭВМ на основании такого сравнения классифицирует изображение, т. е. относит его к одному из известных видов, например, норма или патология. Набор действительных чисел, характеризующих выделенные признаки, при этом можно рассматривать как точку в n-мерном пространстве. Если в это пространство предварительно введены области, занимаемые тем или иным классом в пространстве, называемом пространством признаков, либо, что случается чаще, задана плотность вероятности для каждого класса, появляется возможность с известной вероятностью отнести данное изображение к определенному классу.
Выводы
В сфере современных информационных технологий большое внимание уделяется повышению качества рентгеновских снимков для улучшенной работы с ними, также проводится всевозможная автоматизация процессов обработки медицинских изображений с целью более точного определения параметров и характеристик.
Выбран объект диагностики, изучены материалы по теме диагностики переломов, классификации переломов, проанализированы существующие методы обработки изображений, их достоинства и недостатки, выбраны оптимальные методы обработки изображений для СКС.
Список использованной литературы
1. Перетягин, Г. И. Цифровая обработка изображений в информационных системах/Г. И. Перетягин, А.А. Спектор. – Новосибирск, 2000.
2. International Telecommunication Union [Electronic resource]/ Интернет-ресурс – Режим доступа: http://www.mmro.ru/files/mmro9.pdf – Загл. с экрана.
3. Гультяева, Т. А. Скрытые марковские модели с одномерной топологией в задаче распознавания лиц./ Т. А. Гультяева, А. А. Попов. – Новосибирск, 2006.