
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і завдання дослідження, плановані результати
- 3. Аналіз методів в умовах поставленого завдання
- 3.1 Кластерний аналіз
- 3.2 Типологія завдань кластеризації
- 3.3 Огляд обраного методу
- 3.4 Підхід до тестування. Психометрія
- 4. Пропозиції щодо структури магістерської роботи
- Висновки
- Список джерел
Вступ
Система підтримки прийняття рішень призначена для підтримки багатокритеріальних рішень у складній інформаційному середовищі. При цьому під багатокритериальностью розуміється той факт, що результати прийнятих рішень оцінюються не по одному, а за сукупністю багатьох показників (критеріїв), що розглядаються одночасно.
Інформаційна складність визначається необхідністю врахування великого обсягу даних, обробка яких без допомоги сучасної обчислювальної техніки практично нездійсненна. В цих умовах число можливих рішень, як правило, вельми велике, і вибір найкращого з них «на око» без всебічного аналізу може призводити до грубих помилок. СППР вирішує два основні завдання:
-вибір найкращого рішення з безлічі можливих (оптимізація);
-упорядкування можливих рішень по перевагу (ранжування).В обох задачах принциповим моментом є вибір сукупності критеріїв, на основі яких в подальшому будуть оцінюватися і зіставлятися можливі (альтернативні) рішення. Система СППР допомагає користувачеві зробити такий вибір. СППР, або DSS - потужний інструмент допомоги особі, що приймає рішення. Це єдина система даних, моделей і засобів доступу до них (інтерфейс). Роль СППР не обмежується зберіганням даних і видачею необхідних звітів. СППР покликані поліпшити роботу використовують знання людей шляхом застосування інформаційних технологій. У свою чергу, СППР можна умовно розділити на два типи. Це так звані інформаційні системи керівництва (EIS), призначені для негайного реагування на поточну ситуацію, і СППР з глибокою обробкою даних.
При цьому результатом застосування СППР, як правило, є отримання рекомендацій та прогнозів, які носять скоріше евристичний характер і не завжди є прямою вказівкою до подальших дій.
Для аналізу та вироблення пропозицій в СППР використовуються різні методи. Серед них: інформаційний пошук, інтелектуальний аналіз даних, пошук знань в базах даних, міркування на основі прецедентів, імітаційне моделювання, генетичні алгоритми, нейронні мережі та ін Деякі з них були розроблені в рамках штучного інтелекту. Якщо в основі роботи системи лежить один або кілька таких методів, то говорять про інтелектуальну СППР (ІСППР).
1. Актуальність теми
Сучасний страховий бізнес неможливо уявити без ефективних інформаційних технологій, однак вибір оптимального IT-рішення з урахуванням перспективних і поточних бізнес-задач страхової компанії до цих пір залишається вельми непростою справою. Як правило, цей вибір заснований на ретельному аналізі.
Крім класичних завдань вибору страхової компанії для страхування життя, майна, автострахування, в даний час у зв'язку з проведенням в Україні реформ у сферах охорони здоров'я та пенсійного забезпечення виникають нові питання вибору страхової компанії. Зокрема, необхідно буде вибирати кожному оптимальну для себе компанію для медичного страхування та недержавного пенсійного фонду (II етап пенсійної реформи). Розвиток недержавних форм пенсійного та медичного страхування в Україну наближають нас до європейських стандартів життя, а також вимагає (більше) сучасного, науково обгрунтованого, достовірного та ефективного вибору більш придатної для кожного громадянина компанії для різних видів і сфер страхування.
Отже, питання вибору страхової компанії в Україну в поточний час досить актуальне, і великий потік зарубіжних і нових вітчизняних компаній пропонують широкий діапазон послуг при різному рівні надійності. Щоб зробити правильний вибір в цьому розмаїтті варіантів необхідно мати надійний і в той же час простий у використанні інструмент прийняття рішень.
2. Мета і завдання дослідження, плановані результати
Метою роботи є розробка СППР, що надає зручні сервіси для вибору страхової компанії, найкращим чином задовольняє вимогам клієнта.
Для досягнення поставленої мети необхідно вирішити завдання:
- Визначити критерії для класифікації страхових компаній;
- Проаналізувати методи кластеризації стосовно угрупованню компаній;
- Розробити тестові питання і виконати їх крітерізацію за обраними параметрами;
- Розробити СППР.
3. Аналіз методів в умовах поставленого завдання
Поставлену задачу можна вирішити проведенням кластерного аналізу, використанням адаптивних нейронних мереж, що додасть динамізму і універсальності в запропоновану модель системи.
3.1 Кластерний аналіз
Кластерний аналіз виконує такі основні завдання:
-Розробка типології або класифікації.
-Дослідження корисних концептуальних схем групування об'єктів.
-Породження гіпотез на основі дослідження даних.
-Перевірка гіпотез або дослідження для визначення, чи дійсно типи (групи), виділені тим чи іншим способом, присутні в наявних даних.Застосування кластерного аналізу припускає наступні етапи:
-Відбір вибірки для кластеризації.
-Визначення безлічі змінних, за якими будуть оцінюватися об'єкти у вибірці.
-Обчислення значень тієї чи іншої міри подібності між об'єктами.
-Застосування методу кластерного аналізу для створення груп схожих об'єктів.
-Перевірка достовірності результатів кластерного рішення.Кластерний аналіз пред'являє наступні вимоги до даних:
-показники не повинні корелліровать між собою;
-показники повинні бути безрозмірними;
-розподіл показників повинно бути близько до нормального;
-показники повинні відповідати вимогу «стійкості», під якою розуміється відсутність впливу на їх значення випадкових факторів;
-вибірка повинна бути однорідна, не містити «викидів».Якщо кластерному аналізу передує факторний аналіз, то вибірка не потребує «ремонті» - викладені вимоги виконуються автоматично самою процедурою факторного моделювання (є ще одна перевага - z-стандартизація без негативних наслідків для вибірки; якщо її проводити безпосередньо для кластерного аналізу, вона може спричинити за собою зменшення чіткості поділу груп). В іншому випадку вибірку потрібно коригувати.
При аналізі результатів соціологічних досліджень рекомендується здійснювати аналіз методами ієрархічного агломеративні сімейства, а саме методом Уорда, при якому всередині кластерів оптимізується мінімальна дисперсія, в результаті створюються кластери приблизно рівних розмірів. Метод Уорда найбільш вдалий для аналізу соціологічних даних. В якості міри відмінності краще квадратичне евклідова відстань, яке сприяє збільшенню контрастності кластерів. Головним підсумком ієрархічного кластерного аналізу є дендрограмма або «бурульчатий діаграма». При її інтерпретації дослідники стикаються з проблемою того ж роду, що й тлумачення результатів факторного аналізу - відсутністю однозначних критеріїв виділення кластерів. В якості головних рекомендується використовувати два способи - візуальний аналіз дендрограми і порівняння результатів кластеризації. Візуальний аналіз дендрограми передбачає «обрізання» дерева на оптимальному рівні подібності елементів вибірки. «Виноградну гілка» (термінологія Олдендерфера М. С. та Блешфілда Р. К.) доцільно «обрізати» на позначці 5 шкали Rescaled Distance Cluster Combine, таким чином буде досягнуто 80% рівень подібності. Якщо виділення кластерів по цій мітці утруднено (на ній відбувається злиття декількох дрібних кластерів в один великий), то можна вибрати іншу позначку.
Тепер виникає питання стійкості прийнятого кластерного рішення. Перевірка стійкості кластеризації зводиться до перевірки її достовірності. Тут існує емпіричне правило - стійка типологія зберігається при зміні методів кластеризації. Результати ієрархічного кластерного аналізу можна перевіряти ітеративним кластерним аналізом за методом k-середніх. Якщо порівнювані класифікації груп респондентів мають частку збігів більше 70% (більше 2/3 збігів), то кластерне рішення приймається.
Перевірити адекватність рішення, не вдаючись до допомоги іншого виду аналізу, не можна. По крайней мере, в теоретичному плані ця проблема не вирішена. У класичній роботі Олдендерфера і Блешфілда «Кластерний аналіз» докладно розглядаються і в підсумку відкидаються додаткові п'ять методів перевірки стійкості:
- кофенетіческая кореляція - не рекомендується і обмежена у використанні;
- тести значущості (дисперсійний аналіз);
- методика повторних (випадкових) вибірок;
- тести значущості для зовнішніх ознак придатні тільки для повторних вимірювань;
- методи Монте-Карло.
3.2 Типологія завдань кластеризації
Типи вхідних даних:
- Кожен об'єкт описується набором своїх характеристик, які називаються ознаками. Ознаки можуть бути числовими або нечислових.
- Матриця відстаней між об'єктами. Кожен об'єкт описується відстанями до всіх інших об'єктів навчальної вибірки.
Цілі кластеризації:
- Розуміння даних шляхом виявлення кластерної структури. Розбиття вибірки на групи схожих об'єктів дозволяє спростити подальшу обробку даних і прийняття рішень, застосовуючи до кожного кластеру свій метод аналізу (стратегія «розділяй і володарюй»).
- Стиснення даних. Якщо вихідна вибірка надлишково велика, то можна скоротити її, залишивши по одному найбільш типовому представнику від кожного кластера.
- Виявлення новизни: виділяються нетипові об'єкти, які не вдається приєднати до жодного з кластерів.
У першому випадку число кластерів намагаються зробити поменше. У другому випадку важливіше забезпечити високу ступінь подібності об'єктів усередині кожного кластера, а кластерів може бути скільки завгодно. В третьому випадку найбільший інтерес представляють окремі об'єкти, які не вписуються ні в один з кластерів.
У всіх цих випадках може застосовуватися ієрархічна кластеризація, коли великі кластери дробляться на більш дрібні, ті в свою чергу дробляться ще дрібніші, і т. д. Такі завдання називаються завданнями таксономії.
Результатом таксономії є древообразная ієрархічна структура. При цьому кожен об'єкт характеризується перерахуванням всіх кластерів, яким він належить, звичайно від великого до дрібного.
Серед методів кластеризації виділяють:
- K-середніх (K-means);
- Метод нечіткої кластеризації C-середніх (C-means);
- Графова алгоритми кластеризації;
- Статистичні алгоритми кластеризації;
- Алгоритми сімейства FOREL;
- Ієрархічна кластеризація або таксономія;
- Нейронна мережа Кохонена;
- Ансамбль кластерізаторов;
- Алгоритми сімейства КRAB;
- EM-алгоритм;
- Алгоритм, заснований на методі просіювання.Метод K-середніх (K-means). Алгоритм є версією EM-алгоритму, що застосовується також для поділу суміші Гауссіан. Він розбиває безліч елементів векторного простору на заздалегідь відоме число кластерів k.
Основна ідея в тому, що на кожній ітерації Переобчислювати центр мас для кожного кластера, отриманого на попередньому кроці, потім вектори розбиваються на кластери знову відповідно до того, який з нових центрів виявився ближчим за обраною метриці.
Алгоритм завершується, коли на якийсь ітерації не відбувається зміни кластерів. Це відбувається за кінцеве число ітерацій, так як кількість можливих розбиттів кінцевого безліч звичайно, а на кожному кроці сумарна квадратичне ухилення V зменшується, тому зациклення неможливо.
Демонстрація алгоритму
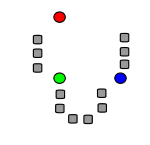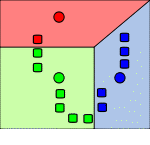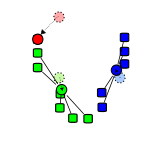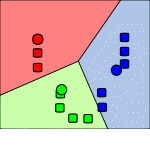
Рисунок 2 - Дія алгоритму в двовимірному випадку. Початкові точки вибрані випадково.
(анімація: 4 кадру, 10 циклів повторення, 16 кілобайт)
Кадр 1 - Вихідні точки і випадково вибрані початкові точки.
Кадр 2 - Точки, віднесені до початкових центрам. Розбиття на площині -
діаграма Вороного щодо початкових центрів.
Кадр 3 - Обчислення нових центрів кластерів (Пошук центру мас).
Кадр 4 - Попередні кроки повторюються, поки алгоритм не зійдеться.Проблеми k-means:
-Не гарантується досягнення глобального мінімуму сумарного квадратичного ухилення V, а тільки одного з локальних мінімумів.
-Результат залежить від вибору вихідних центрів кластерів, їх оптимальний вибір невідомий.
-Число кластерів треба знати заздалегідь.Розширення і варіації. Широко відома і використовується нейромережева реалізація K-means - мережі векторного квантування сигналів (одна з версій нейронних мереж Кохонена).
Нейронні мережі Кохонена - клас нейронних мереж, основним елементом яких є шар Кохонена. Шар Кохонена складається з адаптивних лінійних суматорів («лінійних формальних нейронів»). Як правило, вихідні сигнали шару Кохонена обробляються за правилом "переможець забирає все»: найбільший сигнал перетворюється в одиничний, інші звертаються в нуль.
За способами настройки вхідних ваг суматорів і по важливість справ розрізняють багато різновидів мереж Кохонена. Найбільш відомі з них:
- Мережі векторного квантування сигналів, тісно пов'язані з найпростішим базовим алгоритмом кластерного аналізу (метод динамічних ядер або K-середніх).
- Самоорганізуються карти Кохонена (Self-Organising Maps, SOM).
- Мережі векторного квантування, яких навчають, з учителем (Learning Vector Quantization).Метод нечіткої кластеризації C-середніх (C-means) дозволяє розбити наявне безліч векторів (точок) потужністю p на задане число нечітких множин. Особливістю методу є використання нечіткої матриці приналежності U з елементами uij, що визначають приналежність i-го елемента вихідної безлічі векторів - j-му кластеру. Кластери описуються своїми центрами сj - векторами того ж простору, якому належить вихідна безліч векторів.
У ході виконання завдання нечіткої кластеризації C-means вирішується завдання мінімізації наступної цільової функції E = ∑∑uijm • | | xi-cj | | ² при обмеженнях ∑juij = 1, i = 1 .. p.
FOREL (Формальний Елемент) - алгоритм кластеризації, заснований на ідеї об'єднання в один кластер об'єктів в областях їх найбільшого згущення.
Мета кластеризації - розбити вибірку на таке (заздалегідь невідоме число) таксонів, щоб сума відстаней від об'єктів кластерів до центрів кластерів була мінімальною за всіма кластерам. Тобто наше завдання - виділити групи максимально близьких один до одного об'єктів, які в силу гіпотези схожості і будуть утворювати наші кластери.
Необхідні умови роботи:
- Виконання гіпотези компактності, яка передбачає, що близькі один до одного об'єкти з великою ймовірністю належать до одного кластеру (таксону).
- Наявність лінійного або метричного простору кластерізуемих об'єктів.
Вхідні дані - кластерізуєма вибірка( може бути задана ознаковими описами об'єктів - лінійне простір або матрицею попарних відстаней між об'єктами, в реальних задачах часто зберігання всіх даних неможливо або безглуздо, тому необхідні дані збираються в процесі кластеризації); Параметр R - радіус пошуку локальних згущень (можна задавати як з апріорних міркувань (знання про діаметр кластерів), так і налаштовувати ковзаючим контролем); у модифікаціях можливе введення параметра k - кількості кластерів.
Вихідні дані - кластеризація на заздалегідь невідоме число таксонів
Принцип роботи - на кожному кроці ми випадковим чином вибираємо об'єкт з вибірки, роздуваємо навколо нього сферу радіуса R, всередині цієї сфери вибираємо центр ваги і робимо його центром нової сфери. Т.ч. ми на кожному кроці рухаємо сферу в сторону локального згущення об'єктів вибірки, тобто намагаємося захопити якомога більше об'єктів вибірки сферою фіксованого радіуса. Після того як центр сфери стабілізується, всі об'єкти всередині сфери з цим центром ми позначаємо як кластеризованих і викидаємо їх з вибірки. Цей процес ми повторюємо до тих пір, поки вся вибірка не буде кластерізовани.
Алгоритм:
- Випадково вибираємо поточний об'єкт з вибірки.
- Позначаємо об'єкти вибірки, що знаходяться на відстані менше, ніж R від поточного.
- Обчислюємо їх центр тяжіння, позначаємо цей центр як новий поточний об'єкт.
- Повторюємо кроки 2-3, поки новий поточний об'єкт не співпаде з колишнім.
- Позначаємо об'єкти всередині сфери радіуса R навколо поточного об'єкта як кластеризованих, викидаємо їх з вибірки.
- Повторюємо кроки 1-5, поки не буде кластерізовани вся вибірка.
Евристики вибору центра ваги: у лінійному просторі - центр мас; в метричному просторі - об'єкт, сума відстаней до якого мінімальна, серед усіх всередині сфери; об'єкт, який всередині сфери радіуса R містить максимальну кількість інших об'єктів з усієї вибірки (повільно); об'єкт, який всередині сфери маленького радіуса містить максимальну кількість об'єктів (зі сфери радіуса R).
Спостереження:
- Доведено збіжність алгоритму за кінцеве число кроків.
- У лінійному просторі центром ваги може виступати довільна точка простору, в метричному - тільки об'єкт вибірки.
- Чим менше R, тим більше таксонів (кластерів).
- У лінійному просторі пошук центру відбувається за час О (n), в метричному O (n ²).
- Найкращих результатів алгоритм досягає на вибірках з хорошим виконанням умов компактності.
- При повторенні ітерацій можливе зменшення параметра R, для якнайшвидшої збіжності.
- Кластеризація сильно залежить від початкового наближення (вибору об'єкта на першому кроці).
- Рекомендується повторна прогонка алгоритму для виключення ситуації «поганий» кластеризації, унаслідок невдалого вибору початкових об'єктів.
Переваги:
- Точність мінімізації функціонала якості (при вдалому підборі параметра R).
- Наочність візуалізації кластеризації.
- Збіжність алгоритму.
- Можливість операцій над центрами кластерів - вони відомі в процесі роботи алгоритму.
- Можливість підрахунку проміжних функціоналів якості, наприклад, довжини ланцюжка локальних згущень.
- Можливість перевірки гіпотез схожості і компактності в процесі роботи алгоритму.Недоліки:
- Відносно низька продуктивність (вирішується введення функції перерахунку пошуку центру при додаванні 1 об'єкта всередину сфери).
- Погана застосовність алгоритму при поганій разделимости вибірки на кластери.
- Нестійкість алгоритму (залежність від вибору початкового об'єкта).
- Довільне за кількістю розбиття на кластери.
- Необхідність апріорних знань про ширину (діаметрі) кластерів.Після роботи алгоритму над готової кластеризацією можна робити деякі дії:
- Вибір найбільш репрезентативних (представницьких) об'єктів з кожного кластера. Можна вибирати центри кластерів, можна кілька об'єктів з кожного кластера, враховуючи апріорні знання про необхідну репрезентативності вибірки. Т. О. за готовою кластеризації ми маємо можливість будувати найбільш репрезентативну вибірку
- Перерахунок кластеризації (многоуровненвость) з використанням методу КНП.
Областi застосування:
- Рішення задач кластеризації
- Рішення задач ранжирування вибірки.Математично таксономією є древообразная структура класифікацій певного набору об'єктів. Вгорі цієї структури - об'єднуюча єдина класифікація - кореневий таксон - яка відноситься до всіх об'єктів даної таксономії. Таксони, що знаходяться нижче кореневого, є більш специфічними класифікаціями, які відносяться до піднабору загального набору класифікуються об'єктів. Сучасна біологічна класифікація, наприклад, являє собою ієрархічну систему, основа якої складають окремі організми (індивідууми), а вершину - один всеосяжний таксон; на різних рівнях ієрархії між основою і вершиною знаходяться таксони, кожен з яких підпорядкований одному і тільки одному таксону вищого рангу.
Точка зору, яка стверджує, що людський мозок організовує своє знання про світ в такі системи, часто грунтується на епістемології Іммануїла Канта.
EM-алгоритм (англ. Expectation-maximization (EM) algorithm) - алгоритм, використовуваний в математичній статистиці для знаходження оцінок максимальної правдоподібності параметрів ймовірнісних моделей, у випадку, коли модель залежить від деяких прихованих змінних. Кожна ітерація алгоритму складається з двох кроків. На E-кроці (expectation) обчислюється очікуване значення функції правдоподібності, при цьому приховані змінні розглядаються як спостережувані. На M-кроці (maximization) обчислюється оцінка максимального правдоподібності, таким чином збільшується очікуване правдоподібність, що обчислюється на E-кроці. Потім це значення використовується для E-кроку на наступній ітерації. Алгоритм виконується до збіжності.
Часто EM-алгоритм використовують для розділення суміші Гауссіан.
3.3 Огляд обраного методу
Обгрунтування обраного методу
Рішення завдання зі строго фіксованим набором критеріїв, що описують діяльність страхових компаній з рівнем значущості в описі загальної ситуації, призвело б до статичної моделі.
Мережі векторного квантування сигналів додають динамізм у вирішення завдання кластеризації, можлива реалізація адаптивності складеної моделі, що зробило б систему універсальної при доповненні рядом критеріїв і ступенем значущості в описі об'єкта в цілому. Також частина модуля висновку може бути реалізовано семантичними правилами.
Докладний огляд обраного методу
Шар Кохонена складається з деякої кількості n паралельно діючих лінійних елементів. Всі вони мають однакове число входів m і отримують на свої входи один і той же вектор вхідних сигналів x = (x1, ... xm). На виході jго лінійного елемента отримуємо сигнал
Yi = Wj0 + ∑ Wij * Xi,
де Wji - ваговий коефіцієнт iго входу jго нейрона, Wj0 - пороговий коефіцієнт.
Після проходження шару лінійних елементів сигнали посилаються на обробку за правилом "переможець забирає все»: серед вихідних сигналів Yj шукається максимальний; його номер jmax = argmax j {yj}. Остаточно, на виході сигнал з номером jmax дорівнює одиниці, решта - нулю. Якщо максимум одночасно досягається для декількох jmax, то або вживають усіх відповідних сигнали рівними одиниці, або тільки перший у списку (за згодою). «Нейрони Кохонена можна сприймати як набір електричних лампочок, так що для будь-якого вхідного вектора загоряється одна з них.»
Самоорганізаційна карта Кохонена. Ідея та алгоритм навчання
Завдання векторного квантування полягає, по своїй суті, в найкращій апроксимації всієї сукупності векторів даних k кодовими векторами Wj. Самоорганізуються карти Кохонена також апроксимують дані, проте за наявності додаткової структури в сукупності кодових векторів (англ. codebook). Передбачається, що апріорі задана деяка симетрична таблиця «заходів сусідства» (або «заходів близькості») вузлів: для кожної пари j, l (j, l = 1, ... k) визначено число ηjl () при цьому діагональні елементи таблиці близькості рівні одиниці (ηjj = 1).
Вектори вхідних сигналів x обробляються по одному, для кожного з них знаходиться найближчий кодовий вектор («переможець», який «забирає все») Wj (x). Після цього всі кодові вектори Wl, для яких ηj (x) l ≠ 0, перераховуються за формулою
Wlnew = Wlold (1 - ηj (x) l * θ) + x * ηj (x) l * θ, де θ (0,1) - крок навчання. Сусіди кодового вектора - переможця (по апріорно заданої таблиці близькості) зсуваються в ту ж сторону, що і цей вектор, пропорційно міру близькості.
Найчастіше, таблиця кодових векторів представляється у вигляді фрагмента квадратної решітки на площині, а міра близькості визначається, виходячи з евклідової відстані на площині.
самоорганізуються карти Кохонена служать, в першу чергу, для візуалізації і первинного («розвідувального») аналізу даних. Кожна точка даних відображається відповідним кодовим вектором з решітки. Так отримують уявлення даних на площині («карту даних»). На цій карті можливе відображення багатьох шарів: кількість даних, що потрапляють у вузли (тобто «щільність даних»), різні функції даних і так далі. При відображенні цих верств корисний апарат географічних інформаційних систем (ГІС). У ГІС підкладкою для зображення інформаційних шарів служить географічна карта. Карта даних є підкладкою для довільного за своєю природою набору даних. Вона служить заміною географічній карті там, де її просто не існує. Принципова відмінність в наступному: на географічній карті сусідні об'єкти мають близькими географічними координатами, на карті даних близькі об'єкти мають близькими властивостями. За допомогою карти даних можна візуалізувати дані, одночасно наносячи на підкладку супроводжуючу інформацію (підписи, анотації, атрибути, інформаційні розмальовки). Карта служить також інформаційною моделлю даних.
3.4 Підхід до тестування. Психометрія
Тестування дозволяє здійснити взаємодія потреб людини з можливостями системи. Грамотно організоване тестування дає максимально точний результат.
Вимоги до тестування:
- Надійність і валідність мають відношення до узагальненість показників тестів - визначення того, які висновки за тестовими показниками є обгрунтованими. Надійність стосується висновків про узгодженість вимірювання. Узгодженість визначається по-різному: як тимчасова стійкість, як схожість між імовірно еквівалентними тестами, як однорідність в рамках одного тесту або як порівнянність оцінок, що виносяться експертами. При використанні методу «тест-ретест» надійність тесту встановлюється шляхом повторного його проведення з тією ж групою через певний проміжок часу. Потім два отриманих набору показників порівнюються з метою визначення ступеня подібності між ними. При використанні методу взаємозамінних форм, на вибірці обстежуваних проводяться два паралельних вимірювання. Залучення експертів («оцінювачів») до оцінки якості паралельних форм тесту дає міру надійності, наз. надійністю оцінювачів. Цей метод часто застосовують, коли є необхідність в експертній оцінці.
- Валідність характеризує якість висновків, одержуваних на основі результатів проведення вимірювальної процедури.
- Валідність розглядається як здатність тесту відповідати поставленим цілям і обгрунтовувати адекватність рішень, прийнятих на основі результату. Недостатньо валідний тест не може вважатися інструментом вимірювання і використовуватися на практиці, оскільки часто отриманий результат може серйозно впливати на майбутнє тестування.
Виділяється три види валідності тестів.
Конструктная (концептуальна) валідність. Її потрібно визначити, якщо тест вимірює властивість, що має абстрактний характер, тобто не піддається прямому вимірюванню. У таких випадках необхідне створення концептуальної моделі, яка б пояснювала дане властивість. Цю модель і підтверджує або спростовує тест.
Критеріальна (емпірична) валідність. Показує, наскільки співвідносяться результати тесту з якимсь зовнішнім критерієм. Емпірична валідність існує в двох видах: поточна критеріальна валідність - кореляція результатів тесту з обраним критерієм, що існують у даний час; прогностична критеріальна валідність - кореляція результатів з критерієм, який з'явиться в майбутньому. Визначає, наскільки тест пророкує прояв вимірюваного якості в майбутньому, враховуючи вплив зовнішніх факторів і власної діяльності тестованого.
Змістовна валідність. Визначає, наскільки відповідає тест його предметної області, тобто вимірює він якість, для вимірювання якого призначений, у репрезентативної вибірки. Щоб підтримати змістовну валідність тесту, необхідні його регулярні перевірки на відповідність, тому що реальна картина прояву певної якості може змінюватися у вибірки з плином часу. Оцінка змістовної валідності повинна проізвдітся експертом в предметній області тесту.Процес валідизації тесту повинен являти собою не збір доказів його валідності, а комплекс заходів щодо підвищення цієї валідності.
Більшість процедур аналізу завдань припускають: а) реєстрацію числа досліджуваних, що дали правильну або неправильну відповідь на певне завдання; б) кореляцію окремих завдань з ін змінними; в) перевірку завдань на систематичну помилку (або «необ'єктивність»). Частку піддослідних, впоралися із завданням тесту, наз., Можливо не цілком точно, труднощами завдання. Спосіб покращити завдання - підрахувати відсоток вибору кожного варіанту відповіді на завдання з множинним вибором; корисно також обчислити середній тестовий показник випробовуваних, що вибрали кожен варіант.
Ці процедури дозволяють контролювати, щоб варіанти відповідей виглядали правдоподібними для непідготовлених досліджуваних, але не здавалися правильними найбільш знаючим. Відбір завдань, які сильно корелюють з показником повного тесту, максимізує надійність як внутрішню узгодженість тіста, тоді як відбір завдань, які сильно корелюють із зовнішнім критерієм, максимізує його прогностичну валідність. Описова аналогова модель цих кореляцій називається характеристичною кривою завдання; в типових випадках - це графік залежності частки досліджуваних, правильно відповідають на питання, від їх сумарного тестового показника. Для ефективних завдань ці графіки є позитивні висхідні криві, не знижуються в міру приросту здібності.
Область психометрії пов'язана з кількісним підходом до аналізу тестових даних. Психометрична теорія забезпечує дослідників і психологів математичними моделями, що використовуються при аналізі відповідей на окремі завдання або пункти тестів, тести в цілому та набори тестів. Прикладна психометрія займається застосуванням цих моделей і аналітичних процедур до конкретних тестовим даними. Чотирма областями психометричного аналізу є нормування і прирівнювання, оцінка надійності, оцінка валідності та аналіз завдань. Кожна з цих областей містить набір певних теоретичних положень і конкретні процедури, які використовуються при оцінці якості роботи тесту в кожному окремому випадку.
Нормування тестів - складова частина їх стандартизації, зазвичай включає проведення обстеження репрезентативної вибірки осіб, визначення різних рівнів виконання тестів і переклад сирих тестових оцінок в загальну систему показників. Тести іноді прирівнюють, коли існують різні форми того ж самого тіста. Прирівнювання призводить оцінки за всіма формами до загальної шкалою.
Існують наступні основні стратегії прирівнювання: перший метод передбачає проведення кожної форми тесту на еквівалентній (наприклад, випадкової відібраної) групі респондентів, а потім оцінки за цим різним формам встановлюються т. о., щоб рівні оцінки мали рівні процентільние ранги (та ж сама пропорція респондентів отримує ту ж або нижчу оцінку); при більш точному методі всі респонденти заповнюють всі форми тесту, і для визначення еквівалентності показників використовуються рівняння, третій часто використовуваний метод пов'язаний з проведенням загальних тесту або частини тесту з усіма респондентами; загальна оцінна процедура служить в якості «зв'язує» тесту, який дозволяє всі наступні вимірювання прив'язувати до єдиної шкалою; при проведенні обстеження з використанням різних форм одного і того ж тесту в кожну включаються кілька «анкерних завдань», що виконують функцію такого «зв'язує» тесту.
4. Пропозиції щодо структури магістерської роботи
Структура складається з реалізації 3х етапів:
- формування бази знань
- кластеризації критеріїв оцінки діяльності страхових компаній
- механізму прийняття рішення (вибору)Критерій вибору компанії може бути описаний як:
minL = ∑ (КiL-∑Kijn)²,
де КiL-набір, яким експерти описують успішність діяльності страхової фірми, Kijn - j-й елемент множини, який обрав респондент в результаті проходження тесту. Таким чином стає можливим максимально врахувати інтереси і потреби конкретної людини при виборі страхової компанії.
Надалі планується провести аналіз і розглянути можливість застосування адаптивного навчання нейронної мережі в складі розроблюваної системи. Виявити проблеми з навчанням НС при додаванні нових критеріїв, знайти шляхи вирішення. Провести бесіду з фахівцями в області консалтингових послуг у сфері страхування та фінансових інвестицій для виявлення ступеня важливості кожного критерію в описі діяльності страхових компаній.
Висновки
В ході виконання науково-дослідної роботи був вивчений об'єкт комп'ютеризації, визначено шляхи його автоматизації та обгрунтовано необхідність розробки нової системи; проаналізовано методи кластерного аналізу, нейромережевої моделі Кохонена.
Подальші дії визначаються необхідністю розробки математичних і алгоритмічних моделей функціонування, а також розробку програмної архітектури, придатною для практичної реалізації системи.
В економічно високорозвинених країнах процес вибору страхової компанії для однієї людини, підприємства та цілої галузі здійснюється консалтинговими фірмами. Це незацікавлені організації, які глибоко і комплексно вивчають потреби замовника, неупереджено і всебічно аналізують пропозиції, можливості та результати діяльності безлічі страхових компаній, і роблять вибір оптимального варіанту страхової компанії.
Для такої складної і дуже відповідальній діяльності і потрібна доступна, гнучка й ефективна система, описана в роботі. У міру розвитку ринку послуг страхування і консалтингу в Україну, вона буде все більш і більш затребуваною в нашій країні.
Описана система може також успішно застосовуватися при виборі банку, інвестиційної компанії та хедж-фонду.
Залишився ще ряд питань, які будуть вирішені в результаті подальшого аналізу предметної області, вибору статичної складової в математичній моделі і складової, яку необхідно аналізувати і обробляти динамічними методами, що дозволить отримати більш гнучку систему.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи і матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Список джерел
- Системы поддержки принятия решений. IT Спец [Электронный ресурс]: Режим доступа :URL: abc.org.ru/
- Business Intelligence [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Business_Intelligence
- Кластерный анализ [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Кластерный_анализ
- Нейронная сеть Кохонена [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Нейронная_сеть_Кохонена
- Комплексные программные решения EPAM Systems [Электронный ресурс]: Режим доступа :URL: epam-group.ru/solutions-EPAM_solutions.htm
- Нейронные сети [Электронный ресурс]: Режим доступа :URL: gotai.net/documents-neural_networks.aspx
- Внедрение информационных технологий как один из путей повышения эффективности деятельности страховой компании [Электронный ресурс]: Режим доступа :URL: economic-innovations.com/article/introduction_information_technology_as_one_way_enhancing_effectiveness_insurance_company
- K-means [Электронный ресурс]: Режим доступа :URL: K-means - Википедия
- How many kinds of Kohonen networks exist? [Электронный ресурс]: Режим доступа :URL: faqs.org/faqs/ai-faq/neural-nets/part1/section-11.html
- Самоадаптирующиеся нейронные сети [Электронный ресурс]: Режим доступа :URL: 314159.ru/neuroinformatics.htm
- Методы многомерной классификации и сегментации. Кластерный анализ [Электронный ресурс]: Режим доступа :URL: nickart.spb.ru/analysis/cluster.php
- Адаптивные сети и системы. Нейронные сети [Электронный ресурс]: Режим доступа :URL: neuronet.narod.ru/
- Обучение без учителя [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Обучение_без_учителя
- Психометрия [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Психометрия
- Рейтинг страховых компаний Украины [Электронный ресурс]: Режим доступа :URL: forinsurer.com/ratings/nonlife/
- Кластерный анализ [Электронный ресурс]: Режим доступа :URL: statsoft.ru/home/textbook/modules/stcluan.html
- Факторный анализ — Википедия [Электронный ресурс]: Режим доступа : URL: ru.wikipedia.org/wiki/Факторный_анализ