
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета магістерської роботи
- 3. Нові технології обробки даних
- 4. Методи сортування, які зараз використовують
- 4.1 Сортування вставкою
- 4.2 Сортування бульбашкою
- 5. Огляд розробок за темою
- 5.1 Модуль сортування з послідовним введенням даних
- 5.2 Модуль сортування з паралельним введенням даних
- Висновки
- Перелік посилань
Вступ
На сьогоднішній день в світі існує більше 130 мільйонів комп'ютерів і більше 80 % з них об'єднані в різні інформаційно-обчислювальні мережі від малих локальних мереж в офісах до глобальних мереж типа Internet. Всесвітня тенденція до об'єднання комп'ютерів в мережі обумовлена рядом важливих причин, таких як прискорення передачі інформаційних повідомлень, можливість швидкого обміну інформацією між користувачами, здобуття і передача повідомлень (факсів, E-Mail листів та іншого) не відходячи від робочого місця, можливість миттєвого здобуття будь-якої інформації з будь-якої точки земної кулі, а так само обмін інформацією між комп'ютерами різних фірм виробників що працюють під різним програмним забезпеченням.
Такі величезні потенційні можливості які несе в собі обчислювальна мережа і той новий потенційний підйом який при цьому випробовує інформаційний комплекс, а так само значне прискорення виробничого процесу не дають нам право не приймати це до розробки і не застосовувати їх на практиці.
Тому необхідно розробити принципове рішення питання по організації ІВС (інформаційно-обчислювальній мережі) на базі вже існуючого комп'ютерного парку і програмного комплексу, що відповідає сучасним науково-технічним вимогам з врахуванням зростаючих потреб і можливістю подальшого поступового розвитку мережі у зв'язку з появою нових технічних і програмних рішень [1].
З підвищенням числа запитів користувачів, зростає навантаження на маршрутизатори. Виникають черги, відбувається затримка інформації, втрата пакетів даних.
Особливо ця перевантаженість стосується сенсорних локальних обчислювальних систем. Де відбувається одночасний контроль великої кількості параметрів, постійний “опит” датчиків і детекторів. Це створює великий потік інформації, який необхідно прийняти і вчасно обробити.
Виникає потреба динамічно змінювати черговість обслуговування заявок від однорідних об'єктів з одноранговими пріоритетами, стани яких можуть відрізнятися і стати критичними в потоці інформації.
1. Актуальність теми
Динамічне управління чергами заявок на обслуговування в мережі шляхом адаптації її структури до стану вхідних і вихідних потоків є актуальним завданням у сенсорних локальних обчислювальних системах, що працюють у реальному часі. Управління розподілом потоків може бути здійснене як за рахунок управління структурою мережі шляхом зміни ємкості пучків каналів в безпровідних телекомунікаційних системах, або перерозподілом каналів мережі при зміні інформаційних взаємодій між окремими парами вузлів комутації, так і за рахунок управління шляхами передачі потоків без зміни структури мережі.
2. Мета магістерської роботи
Мета магістерської роботи полягає в дослідженні існуючих алгоритмів сортування і обробки черги даних на обслуговування, а так само створення найбільш вигідного алгоритму. Основою для розробки нового методу сортування і обробки даних є сучасні ПЛІС FPGA.
Постановка завдання:
На основі аналізу традиційних методів управління обслуговуванням інформаційних потоків, алгоритмів апаратного і програмного впорядковування даних, необхідно представити оптимальний за часом метод динамічного управління потоками інформації і здійснити синтез системи з наступними функціями: формування інформації, що управляє, для перебудови дисципліни обслуговування на підставі параметрів стану вхідного потоку (статичного пріоритету, величини штрафу за втрату заявки, швидкості "старіння" заявки в черзі на обслуговування); вибір оптимального алгоритму управління в реальному масштабі часу залежно від завантаження системи.
Кінцевим результатом роботи має бути функціональна схема структури комутаційного пристрою, яка перебудовується програмно, та реалізовується на FPGA.
3. Нові технології обробки даних
Реконфігурована обробка даних (reconfigurable computing), є новітньою технологією, яка використовує кристали ПЛІС типа FPGA (Field Programmable Gate Array) для апаратної реалізації алгоритмів. На відміну від традиційної Нейманівської для фону архітектури, що забезпечує універсальне рішення для всіх алгоритмів, архітектура, заснована на кристалах FPGA, дозволяє розробникові проектувати структуру для кожного окремого алгоритму. Логічна щільність або кількість вентилів кристалів FPGA визначає, якої складності алгоритм може бути реалізований. Алгоритм може також бути розбитий на фрагменти, які багато разів передаються в той же самий пристрій, приводячи до техніки, званою реконфігурацією під час виконання. Таким чином, технологія "Reconfigurable computing" представляє зміну парадигми в проектуванні комп'ютера. Крім того, лінія розділу між програмованими процесорами і кристалами FPGA стає менш помітною: сучасні кристали FPGA (серії Virtex IІ-pro) включають збільшену локальну пам'ять, апаратні помножувачі, які є стандартними складовими сучасних мікропроцесорів, а також апаратні ядра RISC процесорів POWERPC. Під обчислювальними системами, що конфігуруються, розуміються обчислювальні платформи, архітектура яких може бути змінена програмно для реалізації кожного конкретного застосування. Код програмного забезпечення, що завантажується в комп'ютер, що конфігурується, є форматованим проектом, розробленим для певного алгоритму.
Проблема об'єднання апаратних і програмних засобів є значимішою, ніж збільшення логічної щільності і розширення області додатків. На відміну від систем проектування минулого нові платформи повинні задовольняти потребам і навикам фахівців – інженерів-розробників апаратних і програмних засобів. Використання таких платформ робить можливою верифікацію проектів в реальному масштабі часу за рахунок об'єднання апаратних засобів системи, що розробляються, з довкіллям. Бар'єри між апаратними і програмними засобами починають стиратися, оскільки програмне забезпечення дозволяє конфігурувати апаратні засоби під час його роботи. Така технологія розробки об'єктних апаратних засобів надає проектувальникові можливість роботи з проектами, написаними на стандартній мові програмування "C", і завантаження цих проектів відповідною прикладною програмою, використовуваною як функція мови "C". Унікальна властивість реконфігуріруємості дозволяє в реальному часі ефективно виконувати відладку цифрових проектів [2].
4. Методи сортування, які зараз використовують
4.1 Сортування вставкою
Сортування вставкою є останнім з класу простих алгоритмів сортування. При сортуванні вставкою спочатку упорядковуються два елементи масиву. Потім робиться вставка третього елементу у відповідне місце відносно до перших двох елементів. Потім робиться вставка четвертого елементу у список з трьох елементів. Цей процес повторюється до тих пір, поки всі елементи не будуть впорядковані. Наприклад, для масиву "dcab" сортування вставкою проходіть таким чином:
- початкове становище: d c a b;
- перший прохід: c d a b;
- другий прохід: a c d b;
- третій прохід: a b c d [3].
4.2 Сортування бульбашкою
Розташуємо масив зверху вниз, від нульового елементу – до останнього. Ідея методу: крок сортування полягає у проході знизу до гори по масиву. По дорозі є видимими пари сусідніх елементів. Якщо елементи деякої пари знаходяться в неправильному порядку, то міняємо їх місцями.
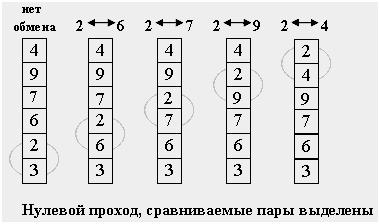
Рисунок 1 – Початкове положення сортування
Після нульового проходу по масиву "вгорі" виявляється "найлегший" елемент - звідси аналогія з бульбашкою. Наступний прохід робиться до другого зверху елементу, таким чином другий за величиною елемент піднімається на правильну позицію... Робимо проходи по нижній частині масиву, що все зменшується, до тих пір, поки в ній не залишиться лише один елемент. На цьому сортування закінчується, оскільки послідовність впорядкована за збільшенням [4].
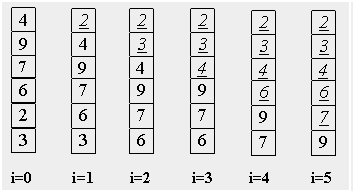
Рисунок 2 – Кінцевий результат сортування
5. Огляд розробок за темою
Даною проблематикою в нашому університеті займаються у спеціальній лабораторії ПЛІС FPGA, заснованою фахівцями з Німеччини.
5.1 Модуль сортування з послідовним введенням даних
Ряд авторів (А. А. Гріценко, С. Ю. Сероштан, Ю. Е. Зінченко) розробили апаратний модуль сортування з послідовним введенням даних і мінімальним часом обробки.
У даній статті розглядається рішення задачі сортування, тобто задачі упорядкування безлічі чисел ![]() так,
щоб наступне обмеження було коректним
так,
щоб наступне обмеження було коректним ![]() .
У цій статті розглядається не яка-небудь з програмних реалізацій алгоритму, а розробка апаратного модуля, який вирішуватиме поставлену задачу.
.
У цій статті розглядається не яка-небудь з програмних реалізацій алгоритму, а розробка апаратного модуля, який вирішуватиме поставлену задачу.
Використання спеціальних апаратних модулів для вирішення тих завдань, які раніше, здебільше, вирішувалися програмно, стало на даний момент актуальним завданням у зв'язку з активним розвитком, а також поширенням, різних видів програмованих логічних інтегральних схем (ПЛІС). Сучасні ПЛІС прийнято розділяти на класи, ґрунтуючись, зокрема, на способі їх програмування. Відповідно до даної класифікації можна виділити ПЛІС FPGA, які користуються все більшою популярністю серед розробників. У свою чергу, ПЛІС FPGA розділяють на ПЛІС з низькою і з високою вартістю. Ключова відмінність полягає, в першу чергу, в складності їх архітектури. Зокрема, це виражається в складності базового елементу, тобто, генератора функції. У даній статті розглядаються схеми, які мають низьку вартість, тобто, це ПЛІС сімейств Altera Cyclone і Xilinx Spartan. Причиною для розробки пропонованого модуля сортування стало дослідження підходів до мінімізації часу роботи модуля. Тобто, мінімізації часу, який необхідний для обробки одного елементу послідовності, яка упорядковується. Основною для модуля, що розробляється, стала схема, яка була описана у статті. Слід зазначити, що даний опис має досить низький рівень деталізації. Тому в даній статті розглядається варіант його реалізації, який може використовуватися у базисі ПЛІС FPGA [5].
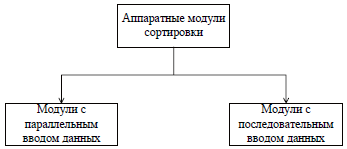
Рисунок 3 – Класифікація апаратних модулів сортування за критерієм способу вводу даних
5.2 Модуль сортування з паралельним введенням даних
Тематика моєї роботи переплітається з розробками вищезгаданих авторів і є альтернативним варіантом. Відмінність полягає у введенні даних.
Робота даного модуля здійснюється в два етапи. Етап 1.
Відбувається накопичення інформації. Сенсорні датчики знімають свідчення і передають їх на входи даних регістрів (A-D), де стають двійковими послідовностями. Ці послідовності попарно поступають з регістрів на схеми порівняння. У компараторі відбувається порівняння, і залежно від того яке значення більше, з'явиться сигнал на виході GT або LT. У випадку, якщо значення якоїсь пари виявляться рівними, передбачений ланцюжок з логічними елементами OR і NOR. Тоді для подальшого порівняння береться одне із значень (у даному варіанті значення з виходу GT).
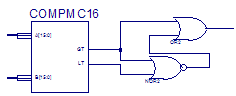
Рисунок 4 – ланцюг елементів логіки OR та NOR
Окрім компаратора вхідні дані поступають на мультиплексор, в якому здійснюється вибір на основі даних схеми порівняння. Аналогічно відбувається і на іншій парі регістрів С і D. Далі ми маємо вже 2 максимальних значення з 4-х регістрів. Ці 2 значення так само проходять ланцюг компаратора і мультиплексора, на виході якого залишається одне максимальне значення. Це значення по ланцюгу зворотного зв'язку поступає на другий вхід мультиплексора, який встановлений на початку нашої схеми.
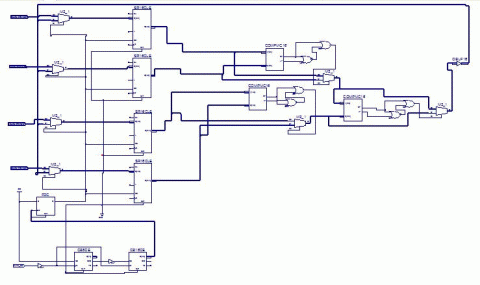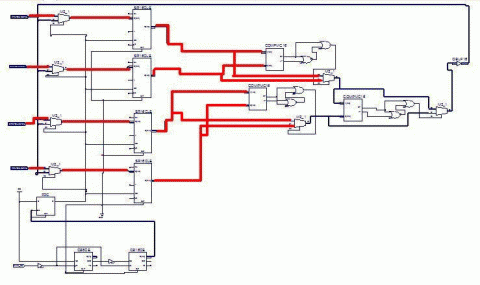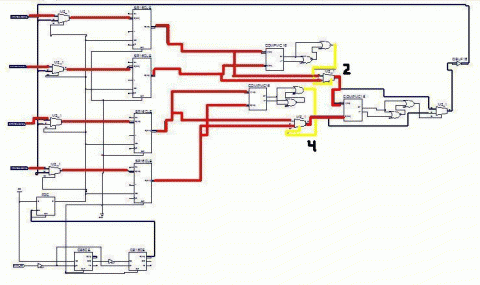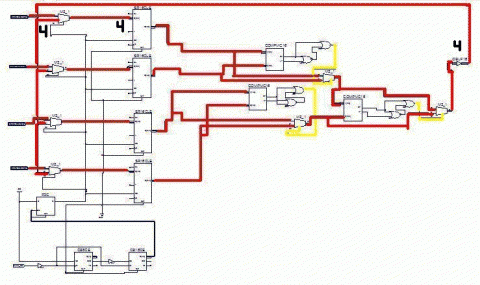
Рисунок 4 – Вибір найбільшого значення у схемі
(аніимація: 8 кадрів, 250 килобайт)
Включення до роботи схеми прапора (тригера) відбувається через інтервал часу, рівний проходженню вхідних даних від датчиків, через мультиплексори на регістри + час проходження схеми впорядковування. Його основне завдання – дозвіл на пересилку інформації від регістру з критичним значенням діагностичного параметра до регістру, вміст якого буде першим в черзі заявок на обробку.
Оскільки схема складається з однакових рівнів, то їх кількість складатиме ![]() , де n – кількість регістрів на вході.
, де n – кількість регістрів на вході.
Висновки
У магістерській роботі вирішується актуальне науково-технічне завдання, яке присвячене дослідженню і модифікації сучасних методів сортування. У рефераті розглянуто два варіанти апаратних модулів сортування. Обидва методи мають високу продуктивність, що дозволяє своєчасно доставляти важливу інформацію по каналу зв'язку. Перевага полягає в простоті реалізації і мінімалізації часу обробки прийнятих пакетів даних, а так само однакова елементна база на кожній ланці ланцюжка. Останнім часом сильний поштовх до розвитку отримали саме реконфігуровані методи обробки даних, оскільки дозволяє розбивати складні алгоритми на окремі фрагменти.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.
Перелік посилань
- Компьютерные сети [Электронный ресурс]. http://www.radioland.net.ua.
- Палагин А.В., Опанасенко В.Н., Сахарин В.Г. Системы верификации на основе реконфигурируемых устройств. – ISSN 1028-9763. Математические машины и системы, 2004, № 2.
- Сортировка вставкой. http://borlpasc.narod.ru/inzik/glava1/sortivs.htm.
- Сортировка пузырьком. http://algolist.manual.ru/sort/bubble_sort.php.
- Гриценко А. А., Сероштан С.Ю., Зинченко Ю.Е. Разработка аппаратного модуля сортировки с последовательным вводом данных и минимальным временем обработки. / Наукові праці ДонНТУ ISSN 1996-1588, Серія "Інформатика, кібернетика та обчислювальна техніка" випуск 13(185), 2011.
- Поляков А. К. Языки VHDL и VERILOG в проектировании цифровой аппаратуры / А.К. Поляков. – М.: СОЛОН-Пресс, 2003. – 320 с.
- Максфилд К. Проектирование на ПЛИС. Курс молодого бойца / К. Максфилд. – М.: Издательский дом «Додэка-XXI», 2007. – 408 с.
- Палагин А. В. Реконфигурируемые вычислительные системы: Основы и приложения / А. В. Палагин, В. Н Опанасенко. – К.: Просвіта, 2006. – 280 с.: ил.
- Grout I. Digital systems design with FPGAs / I. Grout. – Elsevier, 2008. – 724 pp.
- Batcher K. E. Sorting networks and their applications / K. E. Batcher. – "Goodyear Aerospace Corporation", 1968. – 8 pp.
- Жабин В.И. Исследование методов построения вычислительных устройств на основе FPGA / В.И. Жабин, Н.А. Ковалев // Технология и конструирование в электронной аппаратуре. – 2002. – № 2. – С. 35-39.