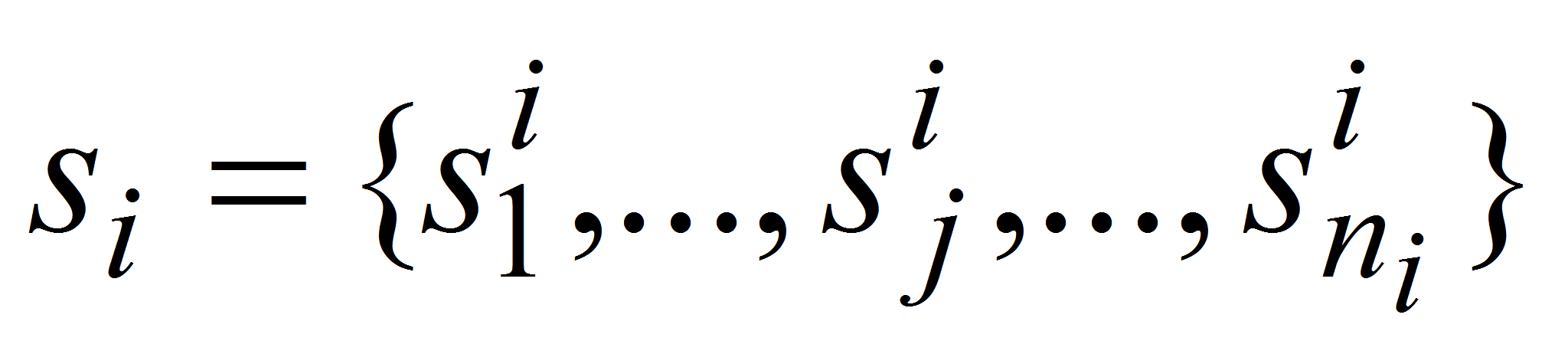 ,
где
,
где
Дорохина Г. В.*, Гнитько Д. С.**
Науч. руководитель к.т.н. Ермоленко Т.В.
*Институт проблем искусственного интеллекта
МОНМС Украины и НАН Украины
**Государственный университет информатики и искусственного интеллекта
Автоматическое выделение синтаксически связанных слов простого распространенного неосложненного предложения
Автоматическое выделения связанных по смыслу слов предложения применимо в задачах построения онтологий, словарей сочетаемости, извлечения знаний из текстов. В связной речи грамматическим выражением структурно-смысловых отношений является синтаксическая связь [1]. Трудность выделения синтаксических связей в предложении связана с характерным для русского языка свободным порядком слов и явлением омонимии на морфологическом и более высоких уровнях. Поэтому данную задачу обычно решают на основе статистических методов. В Украине средства автоматического анализа текста на основе лингвистических методов развиты недостаточно, что указывает на актуальность работы.
Объект исследования – простое распространенное неосложненное предложение русского языка.
Предмет исследования – методы автоматического выделения синтаксически связанных слов в предложении.
Цель работы – разработка методики автоматического выделения синтаксически связанных слов простого распространенного неосложненного предложения.
Данное исследование является развитием работы [2]. В нем использован перечень минимальных структурных схем (МСС) простых предложений [3].
Разработанная методика состоит из четырех этапов.
На первом
этапе проводим
морфологический
анализ словоформ
предложения. В
результате
предложение из
N
словоформ
представляется
вектором S
= (s1,...,
si,...,
sN).
Здесь i
– номер
словоформы в
предложении, si
– множество
вариантов
интерпретации
i-ой
словоформы:
,
где
![]() ,
,
![]() –
j-й
вариант написания
леммы, а
–
j-й
вариант написания
леммы, а
![]() – j-й
вариант
морфологической
информации.
– j-й
вариант
морфологической
информации.
На
втором этапе выполняем поиск пар потенциально связанных
вариантов интерпретации словоформ, для чего вводим отношение
η(x,y,t).
Оно принимает значение 1, если между вариантами интерпретации пары
словоформ
![]() и
и
![]() ,
,
![]() возможна
синтаксическая связь типа
возможна
синтаксическая связь типа
![]() .
Причем
x
– главное
слово,
y
– зависимое,
а T
– множество типов связей, объединяющее
множество
связей между главными членами предложения Tm
и
множество
связей со второстепенными членами предложения Ta
(управление, согласование, примыкание).
Элементы множества Tm
использованы
для задания шаблонов МСС
h={t},
.
Причем
x
– главное
слово,
y
– зависимое,
а T
– множество типов связей, объединяющее
множество
связей между главными членами предложения Tm
и
множество
связей со второстепенными членами предложения Ta
(управление, согласование, примыкание).
Элементы множества Tm
использованы
для задания шаблонов МСС
h={t},![]() .
.
Множество троек (x,y,t), для которых η (x,y,t)=1, обозначим через R. Множество первых компонент этих троек (главных слов) обозначим через A, множество вторых компонент (зависимых слов) обозначим через B.
На третьем этапе для сокращения количества вариантов интерпретаций словоформ формируем вектор S':
S' =(s'1, ..., s'i, ..., s'N),
![]() .
.
S' описывает множество D возможных морфологических разметок предложения (МРП):
D=s'1... s'i... s'N,
D={dk
:
dk=![]() }.
}.
Для анализа каждой k-й МРП ведем обозначения:
![]() ,
,
![]()
![]() ,
,
![]()
Пусть Pr – множество предлогов русского языка.
В ряде МРП dk присутствуют словоформы, не связанные с другими словоформами предложения. Также могут присутствовать dk, у которых предлоги не входят во множество главных слов A. Такие МРП нужно исключить. Дальнейшему рассмотрению подлежат элементы dk множества D, для которых справедливо:
![]() ,
,
![]() ,
,
![]() .
.
Переходим
к четвертому
этапу –
выбору допустимых
связей между
словами. Пара
(Fk,
Rk)
описывает орграф,
в котором
Fk
множество вершин,
а связи
![]() являются
именованными
ребрами из
вершины x
в вершину
y с
именем
t.
Подграфы этого
графа возможно
являются
деревьями.
Не все
они являются
деревьями
синтаксического
подчинения
(ДСП). Принимать
решение о
корректности МРП
и допустимости
отдельных связей
из множества
Rk
будем, исходя
из критериев:
являются
именованными
ребрами из
вершины x
в вершину
y с
именем
t.
Подграфы этого
графа возможно
являются
деревьями.
Не все
они являются
деревьями
синтаксического
подчинения
(ДСП). Принимать
решение о
корректности МРП
и допустимости
отдельных связей
из множества
Rk
будем, исходя
из критериев:
односвязность орграфов, заданных Fk и подмножествами связей Rk, не противоречащих шаблонам МСС;
равенство 1 полустепени захода вершин этих орграфов.
Анализируем соответствие Rk шаблону МСС h. Для этого введем множество Rm={Rmi}, где RmiRk одного типа, причем этот тип входит в шаблон h:
![]() .
.
При |Rm|<|h| предложение не соответствует h.
Введем RM={rmv}, где RM Rm1...Rmi... Rml и
rmv=((x1,y1,t1),...,(xl,yl,tl)) : при l >1 x1=x2,i>1 xi+1=yl.
Элемент rmv – основа для создания ДСП по шаблону h. Пусть g={(x,y,t)}, где (x,y,t) – элементы вектора rmv. В него необходимо добавить второстепенные связи множества c.
![]() Обозначим
Обозначим
![]() .
Если орграф (g',
Rk)
не односвязный,
то по rmv
невозможно построить корректное ДСП.
.
Если орграф (g',
Rk)
не односвязный,
то по rmv
невозможно построить корректное ДСП.
Иначе остается решить проблему вершин с полустепенью захода больше 1. Для каждой такой вершины оставляем по одной связи, исходя из требования: длина пути от корневой вершины до неё – максимальна. Если имеется одна вершина, в которую приводят n конкурирующих связей по путям одинаковой длины, считаем, что имеет место синтаксическая омонимия и все n связей корректны, а паре (Fk, g') соответствует n различных ДСП.
Перечень пар синтаксически связанных пар слов – объединение признанных корректными связей множества g', которые построены по всем Rmi для каждого Fk и шаблона h.
По этой методике создана программа. Выделенные в результате ее работы синтаксические связи – корректны. Их число значительно меньше числа потенциальных связей.
Литература
Лущай В.В. Заполнение позиционного состава предложения по принципу функциональной эквивалентности: интроспективный анализ в русле экспликационной грамматики / В.В. Лущай – Донецк: ДонНУ. – 2010. – 255с.
Дорохина Г.В. Ограничение количества гипотез фразы при распознавании слитной речи / Г.В. Дорохина // Известия ТРТУ – 2005. – № 10. – C. 54-60.
Белошапкова В.А. Современный русский язык / В.А. Белошапкова. – М.: Азбуковник. – 1997. – 928 с.