
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор механизма речеобразования
- 3.1 Формирование звука
- 3.2 Классификация звуков
- 3.3 Классификация фонем
- 4. Запись речевого сигнала
- 5. Некоторые алгоритмы сегментации
- 5.1 Алгоритм поиска границ шипящих и глухих согласных звуков
- 5.2 Алгоритм разделения шипящих и глухих согласных
- 5.3 Алгоритм поиска границ гласных и звонких согласных звуков
- 5.4 «В-Н» - обработка числового массива
- 5.5 Выделение глухих согласных
- 5.6 Распознавание в паре классов «шипящая-пауза»
- 5.7 Сегментация чисто голосового сигнала
- 5.8 Сегментация при наличии шипящих и пауз
- 6. Определение конца слова. Обнаружение и выделение глухого взрывного звука в конце слова
- Выводы
- Список источников
Введение
Компьютеры
находят все более широкое применение во всех областях человеческой
деятельности. В настоящее время сдерживающим фактором к увеличению
количества
компьютеров в мире является неприятие их неподготовленным
пользователем, его
страх перед компьютерами. В определенной степени это неприятие связано
с
традиционными для вычислительной техники способами ввода информации, в
первую
очередь, ввода с клавиатуры.
До
недавнего времени процесс речевого общения человека и компьютера был
непременным атрибутом научно-фантастических романов и никем не
воспринимался
всерьез. Несколько лет назад ситуация кардинально изменилась. Сегодня
использование речевых технологий в прикладных программах в качестве
альтернативного средства взаимодействия в системе
«человек-компьютер»
приобретает все больший размах. Такой процесс носит вполне обоснованный
и
объективный характер в силу ряда причин. Во-первых, развитие речевых
средств
взаимодействия с персональным компьютером лежит в рамках мировой
тенденции
«очеловечивания» ПК, т.е. позволяет создавать интерфейсы,
максимально
дружественные пользователю. Во-вторых, миниатюризация современных
средств
управления и связи требует принципиально новых подходов к осуществлению
взаимодействия пользователя с такого типа устройствами. Для современных
технологий не представляет большого труда создание, например,
мобильного
телефона размером с авторучку, однако механический набор номера на
таком
телефоне будет сопряжен с определенными трудностями. Голосовой набор
номера и
авторизация в этом случае являются очевидным и наиболее подходящим
выходом.
В-третьих, для большого круга пользователей речевой способ общения с ПК
является единственно возможным в силу ограниченности их физических
возможностей
(люди с нарушениями опорно-двигательного аппарата, другими физическими
недостатками, слепые и т.д.) либо специфики профессии.
Большое
значение приобрели также задачи, связанные с быстрым поиском и
получением от
больших информационно-вычислительных систем («информационных
банков») нужных
сведений в виде обычных речевых сообщений, передаваемых по телефонным
каналам [1].
Все это сделало проблему автоматического распознавания речи
разносторонней и
актуальной.
В
настоящее время во всем мире ведутся работы по созданию более
естественных для
человека средств общения с компьютером, среди которых первое место
занимает
речевой ввод информации в компьютер. Проблема речевого ввода информации
осложняется рядом факторов: различием языков, спецификой произношения,
шумами,
акцентами, ударениями и т.п. Данная работа посвящена анализу существующих специфик алгоритмов и разработке новых подходов в распознавания речи, в частности по улучшению распознавания звуков русской речи находящихся в конце речевого сигнала.
В
любом языке существует некий набор звуков, который участвует при
формировании
звукового облика слов. Как правило, звук вне речи не имеет значения, он
приобретает его лишь как составная часть слова, помогая отличить одно
слово от
другого. Элементы этого набора звуков называются фонемами.
1. Актуальность темы и перспективы разработки систем распознавания речи
В настоящее время речевое распознавание находит все новые и новые области применения, начиная от приложений, осуществляющих преобразование речевой информации в текст и заканчивая бортовыми устройствами управления автомобилем. Все многообразие существующих систем распознавания речи [2] можно условно разделить на следующие группы:
1. Программные ядра для аппаратных реализаций систем распознавания речи;
2. Наборы библиотек, утилит для разработки приложений, использующих речевое распознавание;
3. Независимые пользовательские приложения, осуществляющие речевое управление и/или преобразование речи в текст;
4. Специализированные приложения, использующие распознавание речи;
5. Устройства, выполняющие распознавание на аппаратном уровне;
6. Теоретические исследования и разработки.
Технологии речевого распознавания нашли свое применение в различных областях. Однако в данной области множество проблем все еще остаются не решенными, многие идеи требуют дальнейшего развития. Так, программы, работающие с изолированными словами, достигли высокой точности в командных системах – в наиболее распространенных современных приложениях точность распознавания составляет в среднем 95-99% и зависит в основном от уровня шума. В то же время задача распознавания слитной речи в достаточной степени не решена, хотя в случае ограниченного словаря системы такого типа существуют (VoxReports на ядре ViaVoice, Verbmobil) и показывают высокие результаты по точности. В настоящее время множество работ посвящено проблеме распознавания слитной речи (ИПУ РАН, «Истра-Софт», IBM), т.к. именно такой тип речевого взаимодействия считается наиболее перспективным [3].
Важнейшим этапом обработки речи в процессе распознавания, является выделение информативных признаков, однозначно характеризующих речевой сигнал. Существует некоторое число математических методов, анализирующих речевой спектр. Здесь самым широко используемым является преобразование Фурье, известное из теории цифровой обработки сигналов. Данный математический аппарат хорошо себя зарекомендовал в данной области, имеется множество методик обработки сигналов, использующих в своей основе преобразование Фурье.
Не смотря на это, постоянно ведутся работы по поиску иных путей параметризации речи. Одним из таких новых направлений, является вейвлет анализ, который стал применяться для исследования речевых сигналов сравнительно недавно. Теория данного метода сейчас развивается учеными всего мира, и многие исследователи возлагают большие надежды на использование инструмента вейвлет анализа для распознавания речи.
Если рассмотреть речевые распознаватели с позиции классификации по механизму функционирования, то подавляющая их часть относится к системам с вероятностно-сетевыми методами принятия решения о соответствии входного сигнала эталонному – это метод скрытого Марковского моделирования (СММ), метод динамического программирования и нейросетевой метод. Например, нейронные сети могут быть использованы для классификации характеристик речевого сигнала и принятия решения о принадлежности к той или иной группе эталонов.
Нейросеть обладает способностью к статистическому усреднению, т.е. решается проблема с вариативностью речи. Многие нейросетевые алгоритмы осуществляют параллельную обработку информации, т.е. одновременно работают все нейроны. Тем самым решается проблема со скоростью распознавания – обычно время работы нейросети составляет несколько итераций. Сейчас многие разработчики используют аппарат нейронных сетей для построения распознавателей [4]. Однако, если сравнить показатели современных систем распознавания с показателями систем времен начала зарождения этой области науки, то можно сказать, что за прошедшие десятки лет исследователи недалеко продвинулись. Это заставляет некоторых специалистов сомневаться относительно возможности реализации речевого интерфейса в ближайшем будущем [5]. Другие считают, что задача уже практически решена. Большинство экспертов сходится во мнении, что для развития распознавания речи потребуется какое-то время. В рамках своего проекта «Super Human Speech Recognition» IBM надеется разработать коммерческие системы, преобразующие речь в печатный текст точнее, чем человек [6].
2. Цель и задачи исследования, планируемые результаты
Целью исследования данной области является разработка новых подходов по применению существующих алгоритмов по обработке речевого сигнала и их совершенствование по отношению к проблемам связанных с распознаванием в конце речевого сигнала.
Основные задачи исследования:
- Анализ существующих методов распознавания речи, положенных в их основу схем анализа речи, с точки зрения использования выделенных свойств.
- Ознакомление с множеством технологий, методологией обработки речи.
- Выявить важные для распознавания свойства языка и речи.
- Анализ существующих проблем и пути их разрешения.
- Изучение основных принципов записи речевого сигнала и его сегментации.
- Выделение основного направления дальнейшего изучения материала по заданной теме.
Объект исследования: существующие системы записи и распознавания речи, а также существующих методов и алгоритмов направленных на обработку речевого сигнала и дальнейшего его распознавания.
Предмет исследования: повышение эффективности алгоритмов сегментации по распознаванию звуков находящихся в конце речевого сигнала.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Разработка нового подхода к проблемам распознавания звуков находящихся в конце речевого сигнала.
- Определение областей применения данного распознавания.
- Модификация известных методов обработки речевого сигнала и оценка эффективности их применения в практических испытаниях.
Для экспериментальной оценки полученных теоретических результатов и формирования фундамента последующих исследований, в качестве практических результатов планируется разработка компьютерного приложения предварительно обладающее следующими свойствами:
- Запись речевого сигнала.
- Сохранение, загрузка и удаление записанного сигнала.
- Фильтрация речевого сигнала и его сегментация на отдельные фонемы.
- Вывод результата распознавания и его воспроизведение.
3. Обзор механизма речеобразования
Речь в физическом понимании – это акустический сигнал, генерируемый артикуляционными органами человека, передающийся через физическую среду, воспринимаемый ухом человека.
3.1 Формирование звука
При естественной или искусственной генерации речи в акустическом сигнале изменяются физические параметры [7]. Эти изменения воздействуют на мембрану уха, создают траектории звуковых образов, понимаемых человеком как соответствующие звуки данного языка.
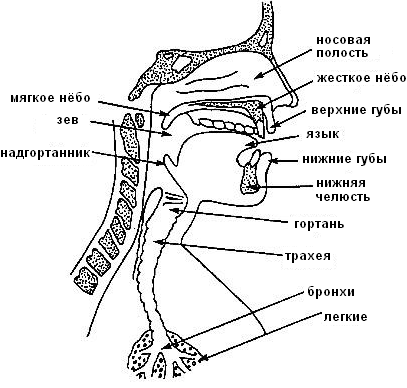
Рис. 1. Звуковой тракт человека
При разговоре грудная клетка расширяется и сжимается, прокачивая поток воздуха из легких по трахее через голосовую щель. Если голосовые связки напряжены, как при образовании звонких звуков типа гласных, то они вибрируют подобно релаксационному генератору и модулируют поток воздуха, превращая его в короткие импульсы. Если голосовые связки расслаблены, воздух свободно проходит через голосовую щель, не подвергаясь модуляции. Воздушный поток проходит через глоточную полость мимо основания языка и в зависимости от положения мягкого неба – через ротовую и носовую полости. Поток воздуха выходит наружу через рот или нос (или обеими путями) и воспринимается как речь [8]. В случае глухих звуков, таких, как с или п, голосовые связки расслаблены. При этом возможны два режима: либо образуется турбулентный поток, когда воздух проходит через сужение в голосовом тракте, либо возникает короткий взрывной процесс, вызванный повышенным давлением воздуха за точкой перекрытия голосового тракта. При изменении положения артикуляторов (губ, языка, челюсти, мягкого неба) во время произнесения непрерывной речи форма отдельных полостей голосового тракта существенно меняется.
Голосовой тракт человека представляет собой неоднородную акустическую трубку, простирающуюся от голосовой щели до губ. У взрослого мужчины она имеет длину около 17 см и частота ее первого (четвертьволнового) резонанса равна 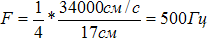 .
.
Площадь поперечного сечения акустической трубки неодинакова и зависит от положения артикуляторов, изменяясь от 0 до 20 см2. Голосовой тракт имеет некоторые устойчивые виды резонансных колебаний, называемые формантами, которые существенно зависят от расположения артикуляторов.
3.2 Классификация звуков
Звуки, участвующие в формировании речи, имеют две основные классификации: по артикуляционным признакам и по акустическим признакам.
Классификация звуков по артикуляционным признакам является крайне важной при использовании методов генерации и распознавания речи с помощью моделирования носоглотки, но для решения задач деления на фонемы более интересно рассмотрение акустических различий звуков [9]. По акустическим признакам звуки подразделяются:
Тональные звуки – образуются голосом при полном отсутствии шумов, что обеспечивает хорошую слышимость звука. К ним относятся гласные: а, э, и, о, у, ы.
Сонарные (звучные) – чье качество определяется характером звучания голоса, который играет главную роль в их образовании, а шум участвует в минимальной степени. К ним относятся согласные: м, м’, н, н’, л, л’, р, р’, j.
Шумные – их качество определяется характером шума - акустического эффекта от трения воздуха при сближенных или взрыве при сомкнутых органах речи:
- звонкие шумные длительные: в, в’, з, з’, ж;
- звонкие шумные мгновенные: б, б’, д, д’, г, г’;
- глухие шумные длительные: ф, ф’, с, с’, ш, х, х’;
- глухие шумные мгновенные: п, п’, т, т’, к, к’.
По производимыми звуками акустическому впечатлению выделяют следующие группы звуков:
- свистящие: с, с’, з, з’, ц;
- шипящие: ш, ж, ч, щ;
- твердые: п, в, ш, ж, ц и др.;
- мягкие: п’, в’, ч, щ и др.
Для дальнейшего анализа проведем информационные образы звуков различных групп.
Разница образов и звуков различных видов велика, что значительно облегчила бы задачу разделения звуков, если бы не присутствие нескольких затрудняющих работу факторов.
Во-первых, переход между различными звуками, как правило, осуществляется крайне плавно даже между звуками различных групп (исключение составляют некоторые взрывные согласные). Если же говорить о звуках одной группы, то становится проблематичным разделять переходные процессы от произнесения того или иного звука, например, в последовательности, воспринимаемой человеком как «иау», звук [а] фактически полностью теряет свой обычный образ в переходе от [и] к [у]. Под влиянием [и] и [у] несколько уменьшилась частота в [а], да и сама форма звука несколько трансформировалась.
Во-вторых, затруднительно назвать какие-либо постоянные критерии для успешного деления на звуки в связи со сложностью процесса их образования.
Вернемся к отображениям звуков и проанализируем общий вид гласных и сонарных звуков. Легко выявить некую общую закономерность, которая обусловлена происхождением звуков - звуки этих видов отдаленно напоминают реакцию некоторой системы на последовательность равноудаленных импульсов. Действительно, импульсами гласных и сонарных звуков являются колебания истинных и звуковых связок. Окончательный вид звуковые волны приобретают после прохождения через носоглотку, которая по своей сути является системой фильтров. Необходимо отметить, что изменения в напряжении истинных голосовых связок и артикуляции происходят значительно медленнее, чем колебания голосовых связок.
Заметим, что гласные и сонарные звуки состоят из участков затухания импульсов от основных колебаний истинных голосовых связок.
3.3 Классификация фонем
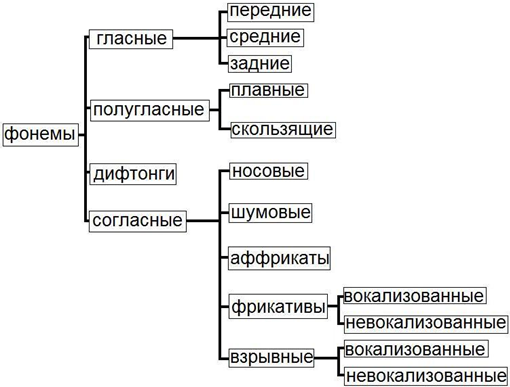
Рис. 2. Классификация фонем
На рисунке 2 приведена основная классификация речевых фонем.
Гласные образуются при квазипереодическом возбуждении голосового тракта неизменной формы импульсами воздуха, возникающими вследствие колебания голосовых связок. Гласные делятся на три подгруппы по положению языка в момент произнесения определенной гласной: передние, средние и задние.
Полугласными называются звуки, акустические характирестики которых меняются в зависимости от произносимого текста.
Согласные носовые звуки образуются при голосовом возбуждении, при этом рот закрыт и служит резонансной плоскостью, а сам звук выходит вместе с воздухом через нос.
Согласные фрикативные невокализованные звуки образуются путем возбуждения голосового тракта турбулентным воздушным потоком.
Согласные фрикативные вокализованные звуки образуются как и невокализованные звуки путем возбуждения голосового тракта, а также в этот момент колеблются голосовые связки.
Взврывные вокализованные согласные звуки образуются при смыкании голосового тракта в какой-то области полости рта. За смычкой воздух сжимается, а затем внезапно высвобождается.
Взрывные невокализованные согласные звуки имеют очень важные отличия от вокализованных. В период полного смыкания голосового тракта голосовые связки не колеблются. После этого периода, когда воздух за смычкой высвобождается, в течение короткого промежутка времени потери на трение возрастают из-за внезапной турбуленции потока воздуха. Далее шумовой воздушный поток из голосовой щели возбуждает голосовой тракт и после этого возникает голосовое возбуждение.
Аффрикаты являются смесью взрывного звука и фрикативного согласного.
Шумовые согласные образуются путем возбуждения голосового тракта турбулентным воздушным потоком, т.е без участия голосовых связок.
4 Запись речевого сигнала
За основу принимается 8-битная оцифровка звукового сигнала с частотой дискретизации 22050 Гц, так что его значения имеют 28 = 256 градаций: от 0 до 255. Предполагается использование системы в лабораторных условиях, при отсутствии существенного внешнего шума.
Записанный сигнал, содержащий речь, разбивается на отрезки по 256 отсчетов. Для каждого из них вычисляется отношение
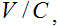 (1)
(1)
где
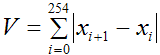 (2)
(2)
– численный аналог полной вариации, C – число точек постоянства, то есть моментов времени, для которых в следующий момент величина сигнала остается неизменной. Создается список значений величины (1), соответствующих последовательности упомянутых отрезков. При выделении элемента списка курсор в окне визуализации сигнала должен становиться в начало соответствующего отрезка. Далее «глазами» определяются элементы списка, соответствующие молчанию и определяется максимальный из них. Это число увеличивается на 0,1 и заносится в управляющий файл под именем StartPorog, а результат, увеличенный в 2 раза, – под именем EndPorog. Все это можно также сделать автоматически, записав перед настройкой, например, 30 тысяч отсчетов тишины.
После начала записи, произносится слово и нажимается кнопка остановки записи. После этого компьютер начинает вычислять для последовательных отрезков по 256 отсчетов величину (1), Определяются моменты, когда эта величина превышает StartPorog и становится меньше, чем EndPorog и в соответствующих местах сигнала проставляются метки или (и) часть сигнала между ними выделяется. Таким образом мы получаем записанное слово.
5 Некоторые алгоритмы сегментации
5.1 Алгоритм поиска границ шипящих и глухих согласных звуков
На каждом этапе работы системы происходит анализ транскрипции ре- чевого сигнала для выяснения его фонетического состава. При наличии в транскрипции шипящих (к которым в данной работе относятся [ш], [с], [ф], [х], [ц], [ч], [щ]), глухих взрывных согласных [п], [к], [т], [t], которые ассоциируются с паузой в сигнале (здесь t означает мягкое «т»), либо фонем [ж], [з] участок, который должен содержать одну из указанных и соседнюю с ней фонему, обрабатывается фильтром низких частот с частотой среза 500 Гц. Это уменьшает энергию участка, соответствующего каждой из перечисленных фонем. Далее происходит разделение сигнала на части с высокой и низкой амплитудой (энергией) [10,11].
Для этого вычисляется средняя амплитуда всего отфильтрованного участка: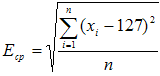 , где xi – значение i -го отсчёта участка, n – количество отсчетов (длина участка). Далее отфильтрованный участок разбивается на отрезки по 256 отсчетов и вычисляется амплитуда на каждом отрезке. В результате получаем массив значений амплитуды Ei. Чтобы определить границы между высокоамплитудной и низкоамплитудной частями сигнала, последовательно сравниваем каждое значение Ei c пороговой величиной T. Для шипящих и пауз полагаем T = 0.3* Eср , для [ж] и [з] полагаем T=Eср. Если Ei-1>T и Ei<Е, то, возможно, значение 256*i – это граница между высокоамплитудной и низкоамплитудной частями участка. Чтобы избежать появления лишних границ, дополнительно проверяется расстояние до предыдущей границы. Если оно не превышает 512 отсчетов, то значение 256*i пропускаем, иначе считаем значение 256*i очередной границей и запоминаем его вместе с предыдущей границей в списке сегментов Segment_Array. Участок с этими границами считается высокоамплитудным и соответствующим очередному голосовому звуку в транскрипции (либо нескольким голосовым звукам).
, где xi – значение i -го отсчёта участка, n – количество отсчетов (длина участка). Далее отфильтрованный участок разбивается на отрезки по 256 отсчетов и вычисляется амплитуда на каждом отрезке. В результате получаем массив значений амплитуды Ei. Чтобы определить границы между высокоамплитудной и низкоамплитудной частями сигнала, последовательно сравниваем каждое значение Ei c пороговой величиной T. Для шипящих и пауз полагаем T = 0.3* Eср , для [ж] и [з] полагаем T=Eср. Если Ei-1>T и Ei<Е, то, возможно, значение 256*i – это граница между высокоамплитудной и низкоамплитудной частями участка. Чтобы избежать появления лишних границ, дополнительно проверяется расстояние до предыдущей границы. Если оно не превышает 512 отсчетов, то значение 256*i пропускаем, иначе считаем значение 256*i очередной границей и запоминаем его вместе с предыдущей границей в списке сегментов Segment_Array. Участок с этими границами считается высокоамплитудным и соответствующим очередному голосовому звуку в транскрипции (либо нескольким голосовым звукам).
Если Ei-1<Т и Ei>T, то, возможно, 256*i – граница между высокоамплитудной и низкоамплитудной частями участка (при этом выполняется такая же проверка, что и в предыдущем случае). Участок с соответствующими границами считается низкоамплитудным и отвечающим очередному шипящему звуку, паузе либо [ж], [з] в транскрипции (либо сочетанию «шипящий – пауза»).
При работе алгоритма наличие транскрипции слова дает возможность контролировать правильность чередования высокоамплитудных и низкоамплитудных участков (т.е. если в транскрипции за шипящей следует голосовой звук, то алгоритм будет искать только переход от низкой амплитуды к высокой и наоборот). Это позволяет избежать появления лишних меток и повышает точность сегментации.
5.2 Алгоритм разделения шипящих и глухих согласных
Если в результате работы предыдущего алгоритма в списке сегментов присутствуют участки с низкой энергией, соответствующие сочетанию шипящих и глухих согласных звуков [п], [к], [т], [t], то для того, чтобы определить границу между ними, используется следующий алгоритм. Соответствующий участок исходного сигнала обрабатывается фильтром высоких частот с частотой среза 1500 Гц, и на нем строится массив значений амплитуды Ei (от левой границы до правой). Чтобы определить границу между шипящей и паузой, последовательно сравниваем каждое значение Ei c пороговой величиной, равной Eср. Если Ei-1>Eср и Ei<Eср, то, возможно, значение 256*i – это искомая граница. Чтобы избежать появления лишних границ, дополнительно проверяется расстояние от левой границы всего участка до найденной границы. Если оно не превышает 512 отсчетов, то значение 256*i пропускаем, иначе считаем значение 256*i очередной границей и запоминаем это значение вместе с левой границей участка в списке сегментов Segment_Array. Участок с этими границами считается высокоамплитудным и соответствующим шипящей, а следующий за ним низкоамплитудный участок – паузе. В список сегментов добавляются два новых участка.
5.3 Алгоритм поиска границ гласных и звонких согласных звуков
Если после работы предыдущих алгоритмов в списке сегментов присутствуют участки с высокой амплитудой, соответствующие сочетаниям подряд идущих гласных и звонких согласных звуков, для их разделения применяется фильтрация соответствующих участков сигнала фильтром высоких частот. Такая фильтрация сильно понижает энергию участков, соответствующих звонким согласным звукам, в то время как энергия гласных уменьшается незначительно.
Если участок содержит звук «и», то он обрабатывается фильтром высоких частот (ФВЧ) с частотой среза 3500 Гц (за исключением пар «ил» и «lи»). Для сочетаний «вы», «ил», «lи», «лу», «ду», «ву», «бу», «гу» используется ФВЧ с частотой среза 250 Гц, для сочетания «му» – частота среза 750 Гц. В случае остальных сочетаний участок обрабатывается фильтром высоких частот с частотой среза 500 Гц. Далее строится массив значений амплитуды Ei на рассматриваемом участке сигнала (от левой границы до правой). Чтобы определить границы между высокоамплитудными и низкоамплитудными участками сигнала, последовательно сравниваем каждое значение Ei c пороговой величиной T. Если согласная есть одна из фонем [б], [д], [г], то T = 0.5* Eср , иначе T = Eср . Если Ei-1>Т и Ei<Т, то, возможно, значение 256*i – это граница высокоамплитудными и низкоамплитудными участками сигнала. Чтобы избежать появления лишних границ, дополнительно проверяется расстояние до предыдущей границы. Если оно не превышает 600 отсчетов, то пропускаем значение 256*i , иначе считаем значение 256*i очередной границей и запоминаем его вместе с предыдущей границей в списке сегментов Segment_Array. Участок с этими границами считается высокоамплитудным и соответствующим очередному гласному звуку в транскрипции (либо нескольким гласным звукам). К гласным относятся [а], [о], [у], [е], [ы], [и], [э], [ю], [я].
Если Ei-1<Т и Ei>Т, то, возможно, 256*i – граница между низко- и высокоамплитудным участками сигнала (при этом выполняется такая же проверка, как и в предыдущем случае). В случае положительного результата первый участок считается низкоамплитудным и соответствует очередному звонкому согласному звуку в транскрипции ([б], [в], [г], [д], [л], [l], [м], [н]) (здесь l обозначает мягкое «л»). Работа алгоритма завершится, когда будут просмотрены все значения Ei.
5.4 «В-Н» - обработка числового массива
Пусть имеется одномерный числовой массив и задан некоторый порог р. Построим символьную последовательность S, поставив в соответствие членам массива, которые больше р, символ «В» (выше порога), остальным – символ «Н» (ниже порога).Для того чтобы устранить случайные единичные включения, для каждого промежуточного i-го элемента полученной символьной последовательности S выполняются две дополнительные обработки. Обработка «тройками», если s[i-1] = s[i+1] и s[i] ≠ s[i-1], то полагается s[i] = s[i-1]. Обработка «четверками», если s[i] = s[i+3] и s[i+1] ≠ s[i], s[i+2] ≠ s[i], то полагается s[i+1] = s[i] и s[i+2] = s[i].
5.5 Выделение глухих согласных
В данном пункте предлагается алгоритм выделения согласных С, Ш, Щ, Ц, Ч, Ф, Х, h, П, К, Т, t, произнесение которых происходит без участия голосовых связок. В основе его лежит обработка сигнала полосовым фильтром с интервалом пропускания от 100 до 200 Гц. Отфильтрованный сигнал нумеруется так, чтобы его максимальное значение равнялось 255 (либо минимальное значение равнялось нулю).
Упомянутые звуки отличаются от всех остальным тем, что после такой фильтрации их участки становятся подобными паузе и содержат большое число точек постоянства. Таким образом, на этих участках разность между числом точек непостоянства и числом точек постоянства будет отрицательной, что позволяет выделить их в массиве таких разностей, построенном для последовательности окон в 256 отсчетов. В таблице таких разностей будут приведены столбцы трех числовых массивов: массив чисел точек постоянства, массив чисел точек непостоянства и массив разностей.
Этот метод очень хорошо работает при обнаружении (детектировании) глухих согласных. Однако метки, отмечающие начало и конец соответствующего участка, иногда бывают смещены относительно ожидаемого положения.
5.6 Распознавание в паре классов «шипящая-пауза»
Рассмотрим для произвольно
выделенного участка речевого сигнала численный аналог полной вариации
«с переменным верхним пределом»:
Пусть
N1 – максимальное число, такое, что W(N1) ≤ 255.
Полагаем
где N2 –
максимальное число, такое, что W(N2) ≤ 255 и так далее.
Возникает массив чисел
На сегменте шипящей величина (3) быстро растет, поэтому участки возрастания величины W(n) от 0 до 255 относительно коротки, то есть числа (5) относительно малы. На сегменте паузы величина (3) растет медленно, и поэтому числа (5) относительно велики. Для различения шипящей и паузы введем порог p (для нашего оборудования 200). Возьмем выделенный сегмент глухих согласных и построим для него последовательность чисел (5). Те участки, для которых числа (5) превосходят p, относим к паузе (их объединение маркируем символом P), остальные – к шипящей (маркируем ее символом F). В результате компьютер расставит маркированные границы шипящих и пауз.
Рассмотрим случай слова, не содержащего глухих звуков. Разобьем сигнал на окна по 256 отсчетов, и на каждом из них вычислим значение вариации
Далее от начала слова берется интервал из 20 таких окон и вычисляется среднее значение соответствующих величин (6), которое принимается за порог. Производится «В-Н»-обработка числового массива с этим порогом. Затем интервал, на котором выполняются описанные процедуры, сдвигается вправо на одно окно и так далее. В результате возникает таблица вида, изображенного на рисунке 3.
Затем просматриваются все строки полученной таблицы и создается новая символьная последовательность S. Если текущая i-я строка таблицы начинается и заканчивается одним и тем же символом («Н» или «В»), то в S на i-ю позицию записывается соответствующий символ. Иначе считается количество вхождений каждого из символов в данной строке. Если количество «В» превышает количество «Н» или равно ему, то в S на соответствующую позицию записывается «В», иначе «Н». К полученной последовательности применяется «В-Н»-обработка. Метки сегментации ставятся там, где происходит смена символов «Н» на «В», или «В» на «Н». В-участок считается соответствующим гласному (возле левой метки проставляется символ W). Н-участок считается соответствующим звонкому согласному (возле левой метки проставляется символ С).
Если слово содержит шипящие или паузы, то мы выделяем их, как описано выше, после чего значения величины (6) для соответствующих им окон полагаем равными нулю и сегментируем сигнал только что описанным способом (шипящие и паузы автоматически попадают в число Н-участков). Для надежного выделения звонкого согласного непосредственно после шипящего или паузы порядок формирования S непосредственно после шипящего или паузы меняется: если в строке появляется «В», но она заканчивается на «Н», то ей сопоставляется «Н». Дальше все как описано выше. Аналогичная ситуация с голосовым согласным непосредственно перед шипящей или паузой.
Пусть произнесено слово «ЗАКОН», заканчивающееся звонким согласным. Визуализация соответствующего сигнала приведена на рисунке 7 с сегментацией в соответствии с только что описанными алгоритмами. Построим функцию W(n) (рис. 4).
На рисунке 6 показан результат вычисления массива (5).
Разработанная нами программа поддерживает соответствие между выделением строки в списке рисунка 6 и положением курсора на рисунке 5 (где представлен тот же график, что и на рисунке 4). Большие числа в конце списка соответствуют участку молчания, записанного в конце сигнала. Движемся по списку снизу вверх, проходя строки, числа в которых больше порога p1 (мы берем этот порог равным 1000). Выделяем строку, для которой число в предыдущей строке уже меньше p1. Выделенной строке соответствует положение курсора на рисунке 5. Это предполагаемый конец речевого сигнала.
Продолжаем движение по списку снизу вверх пока левый край курсора на рисунке 6 не совпадет с меткой P, или впервые не окажется левее нее. Суммируем все промежуточные числа списка и сравниваем вычисленную сумму Sum с порогом p2 (мы берем его равным 3000). В данном случае она оказывается меньше p2. Поэтому мы считаем метку P концом сигнала и удаляем маркировку P. В результате размеченная визуализация сигнала выглядит так:
Теперь произнесем слово «РОТ». Вот его визуализация с окончательной разметкой:
Вот график функции W(n) с курсором в позиции предполагаемого конца сигнала
Вычисляем сумму Sum, так же, как это сделано выше. В данном случае она оказывается больше порога p2 (курсор на рисунке 9 отстоит от метки P много дальше, чем в предыдущем примере). Поэтому истинным концом речевого отрезка мы полагаем позицию левого края курсора на рисунке 9. Сегмент от метки P до этой новой метки конца речевого отрезка - порождение глухого взрывного звука в конце слова. Пример работы алгоритма при произнесении слова «ЗВОНОК» приведен на рисунке 10.
Рис. 10. Пример работы алгоритма при произнесении слова «ЗВОНОК»
В данной работе были представлены некоторые методы цифровой обработки речевых сигналов. Была рассмотрена основная классификация звуков. Проведенный обзор направлений использования распознавания речи, а также созданные системы позволяют рассмотреть насколько велико, обширно и необходимо изучение данного направления. Также были получены некоторые результаты в данном направлении позволившие более точно распознать глухие взрывные в конце сигнала, тем самым предоставляя возможность выделить их из участка тишины. Все рассмотренные методы хорошо согласуются с современным состоянием цифровой техники, что позволяет упростить их реализацию, тестирование и проверку. Приведенные алгоритмы сегментации речи могут помочь при решении поставленной задачи в улучшении распознавания конца речевого сигнала.
Дальнейшие исследования направлены на следующие аспекты: 1. Изучение существующих алгоритмов, расширение и дополнение уже полученных результатов для комплексной реализации поставленной задачи.
2. Применение улучшеных методов сигментирования.
3. Разработка функциональной системы распознавания речи с реализацией рассмотренных алгоритмов и выполняющую поставленную задачу улучшения точности сегментации конца записанного слова.
При написании данного реферата магистерская работа еще не завершена.
Окончательное завершение: декабрь 2012 года. Полный текст работы
и материалы по теме могут быть получены у автора или его руководителя
после указанной даты.
1. Аграновский А.В. Автоматическая идентификация языка / А.В. Аграновский, О.Г. Можаев, Д.А. Леднов, М.Ю. Зулкарнеев // Искусственный интеллект. – 2002. – № 4. – С. 142-150.
2. Панов М.В. Современный русский язык. Фонетика / М.В. Панов – М.: Высшая школа, 1979. – 256 с.
3. Обжелян Н.К. Машины, которые говорят и слушают / Н.К. Обжелян, В.Н. Трунин-Донской. – К.: Штиинца, 1987. – 175 с.
4. Hosom J.P. Speech Recognition Using Neural Networks at the Center for Spoken Language Understanding / J.P. Hosom, R. Cole, M. Fanty // Center for Spoken Language Understanding, Oregon Graduate Institute of Science and Technology – July 1999.
5. Чекмарев А. Речевые технологии – проблемы и перспективы / А. Чекмарев // Компьютера. – 1997. – №49. – С. 26-43.
6. Speech recognition begins to makes itself heard [Електронний ресурс] / М. Broersma – Режим доступа к ресурсу: http://www.zdnet.co.uk/news/, October 2003.
7. Винцюк Т.К. Анализ, распознавание и интерпретация речевых сигналов / Т.К. Винцюк – К.: Наук. думка, 1987. – 262 с.
8. Мясникова Е.Н. Объективное распознавание звуков речи / Е.Н. Мясникова – Л.: Энергия, 1967. – 150 с.
9. Методы пофонемного распознавания, использующие свойства языка и речи [Електронний ресурс] / Г.В Дорохина // Искусственный интеллект – 2008. – №4. С. 332 – 338 – Режим доступа к журн.: http://www.nbuv.gov.ua/portal/natural/ii/2008_4/JournalAI_2008_4/Razdel4/06_Dorokhina.pdf.
10. В.Ю.Шелепов, А.В. Ниценко. К проблеме пофонемного распознавания // Искусственный интеллект. – 2005. – №4. – с.662-668.
11. Лекции о распознавании речи / Шелепов В.Ю. – Донецк: ІПЩІ «Наука і освіта», 2009. – 196 с.
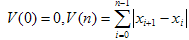 (3)
(3)
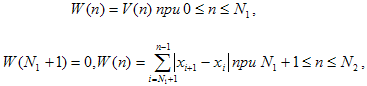 (4)
(4)
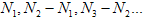 (5)
(5)
5.7
Сегментация чисто голосового сигнала
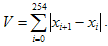 (6)
(6)
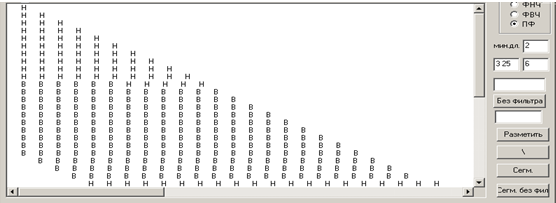
Рис. 3. Таблица, используемая при сегментации
5.8
Сегментация при наличии шипящих и пауз
6.
Определение конца слова. Обнаружение и выделение глухого взрывного звука в конце слова

Рис. 4. График функции W(n), соответствующий сигналу на рисунке 7

Рис. 5. Положение курсора, определяющее предполагаемый конец сигнала
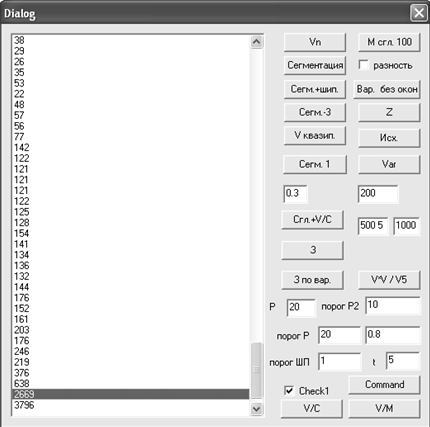
Рис. 6. Список в левой части окна представляет массив (5)

Рис. 7. Окончательная разметка сигнала слова «ЗАКОН» с отмеченным концом сигнала

Рис. 8. Визуализация сигнала для слова «РОТ» с окончательной разметкой

Рис. 9. График функции W(n) с курсором в позиции предполагаемого конца сигнала

(анимация: 6 кадров, 10 циклов повторения, 84.1 килобайт)
Выводы