
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 4. Автоматизированное наполнение звуковой базы синтезатора речи с использованием методов кратномасштабного анализа
- 4.1. Алгоритм сегментации с использованием метода кратномасштабного анализа
- 4.2. Модификация алгоритма
- 5. Интонационные конструкции русской речи
- 6. Обзор методов синтеза речи с интонационной окраской
- 6.1. Синтез интонационной составляющей речевого сигнала с применением сплайновой интерполяции
- 6.2. Синтез монотонной и выразительной речи методом Unit Selection
- Выводы
- Список источников
Введение
Разрабатываемые на сегодняшний день системы способны не только выполнять различные операции по вычислению и обработке информации, но и производить ее распознавание и восстановление по исходным данным. В последнее время такие системы пользуются огромным интересом не только в научной, но и в практических областях деятельности людей. Одной из актуальных задач данных систем является синтез речи.
Синтезом речи называется процесс восстановления формы речевого сигнала по его параметрам.
При проектировании и создании современных синтезаторов речи часто используют звуковую базу [1], содержащую либо отдельные фонемы, либо их сочетания, либо полноценные записи слов, либо словосочетания в зависимости от подхода к синтезу. На первых этапах создания синтезаторов наполнение базы может производиться вручную. Однако такой подход чреват временными затратами на поиск необходимых сегментов, субъективным человеческим восприятием звукового сигнала, сложностью воспроизведения результатов такого наполнения. В связи с этим встает вопрос автоматизации данного процесса с использованием методов сегментации речи.
Существует большое количество методов сегментации речи, основанных на различных математических аппаратах: дискретном вейвлет-преобразовании [2], динамическом программировании [3], преобразовании логарифмического спектра [4]. Они позволяют получать воспроизводимые результаты сегментации речи с разным качеством и точностью. Особым требованием к методам сегментации является дикторонезависимость, поскольку данное свойство позволяет, не изменяя параметры метода под отдельного диктора, получить базу звуков для различных голосов.
К современным системам синтеза речи предъявляются требования разборчивости и естественности (натуральности) звучания. Разборчивость подразумевает правильное распознавание человеком всех слов синтезированной речи. Большинство современных систем синтеза речи демонстрируют хорошую разборчивость, приближающуюся к разборчивости естественной речи. В то же время практика показывает, что разборчивая, но неестественно звучащая речь не удовлетворяет требованиям пользователей. Естественность синтезированной речи оценивается по тому, насколько она похожа на речь живого человека.
Под речью с интонационной окраской понимается выражение отношения читающего текст к содержанию этого текста и к аудитории. Как правило, стиль и смысл текста диктуют выбор стиля речи. В речи с интонацией подчеркнуты отдельные слова, выделены паузами определенные участки текста и т.д.
1. Актуальность темы
Синтез речи по тексту может быть использован в технике связи, в информационно справочных системах, для помощи людям с нарушениями опорно-двигательного или зрительного аппаратов, выдачи информации о технологических процессах, в военной и космической технике, в робототехнике. В перспективе разработка высококачественных систем синтеза речи по тексту является необходимым шагом в направлении более тесного общения человека с компьютером. В целом речевой синтез может потребоваться во всех случаях, когда получателем информации является человек.
На основе выше сказанного можно сделать вывод, что магистерская работа посвящена актуальной научной задаче синтеза речи.
2. Цель и задачи исследования, планируемые результаты
Целью магистерской работы является разработка программного обеспечения для синтеза слов и словосочетаний русский речи с моделированием интонационной окраски.
Для достижения поставленной цели необходимо решить следующие задачи:
- Сегментирование речевого сигнала диктора для автоматизированного наполнения базы звукосочетаний синтезатора.
- Анализ вводимого текста.
- Транскрибирование проанализированного текста.
- Склеивание звукосочетаний из базы синтезатора без щелчков по транскрипции.
- Определение интонационной конструкции текста.
- Приведение речевого сигнала к заданному мелодическому контуру.
Объект исследования: речь, как последовательность звуков, являющихся реализациями конкретных фонем.
Предмет исследования: алгоритмы моделирования мелодического контура при синтезе речи и их программная реализация.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Разработка алгоритма сегментации речевого сигнала с использованием метода кратномасштабного анализа, что позволит в дальнейшем автоматизировать процесс наполнения базы звуков синтезатора.
- Разработка алгоритма определения интонационной конструкции текста.
- Разработка алгоритма наложения мелодического контура на синтезируемый речевой сигнал.
Для экспериментальной оценки полученных теоретических результатов в качестве практических результатов планируется разработка программной реализации синтезатора речи.
3. Обзор исследований и разработок
Синтезом речи занимались такие ученые как Дж. Фланаган [5], Фант Г. [6–7], Сорокин В.К. [1], Лобанов Б.М. [8]. В их трудах рассмотрены теоретические и экспериментальные основы синтеза и анализа речи, а также описаны конкретные практические результаты в решении задач компьютерного синтеза.
Для синтеза русской речи необходимо иметь представление об фонетической составляющей русского языка. Данный вопрос изложен в трудах Буланина Л.Л.[9], Бондарко Л.Б. [10] и Бондарко Л.В. [11]. Интонационные конструкции сформулированы Брызгуновой Е.А. [12], Пешковским А.М. [13] и Цеплитисом Л.К. [14].
Подходы к интонационной окраске синтезируемого речевого сигнала предложены в статьях Людовик Т.В. [15–16] и Киломолдаева М.Н. [17].
В статьях Вишняковой О.А. [2], Давыдова А.Г. [3], Колокова А.С. [4], Ермоленко Т.В. [18–19], Сорокина В.Н. [20] изложены алгоритмы сегментации речевого сигнала, которые можно использовать в целях автоматизированного наполнения звуковой базы синтезатора речи.
Математические аппараты используемые при обработке звукового сигнала собраны в книгах Сергиенко А.Б. [21], Р. Лайонса [22], Э. Айфичера [23], Умняшкина С.В. [24].
4. Автоматизированное наполнение звуковой базы синтезатора речи с использованием методов кратномасштабного анализа
4.1. Алгоритм сегментации с использованием метода кратномасштабного анализа
Как известно, речевой сигнал состоит из квазистационарных участков, соответствующих голосовым и шипящим фонемам, перемежаемых участками со сравнительно быстрыми изменениями спектральных характеристик сигнала (межфонемные переходы, взрывные и смычные фонемы, внутрисловные переходы речь-пауза) [20]. В пределах стационарных участков значительную роль для анализа речи играют спектральные особенности сигнала, определяемые передаточной характеристикой речевого тракта, изменяющейся в процессе артикуляции. Можно сказать, что речевой сигнал характеризуется нелинейными флуктуациями различных масштабов. Поэтому весьма эффективным для анализа речевого сигнала представляется кратномасштабный анализ и вейвлет-преобразование.
Разложение по вейвлетам речевого сигнала длиной N отсчетов представляет собой сумму следующего вида [25]:
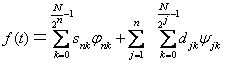
где Snk — коэффициенты аппроксимации; djk> — детализирующие коэффициенты; φnk — масштабированная скейлинг-функция φ; ψjk — смещенная версия скейлинг-функции материнского вейвлета ψ; n — уровень детализации.
Масштабирование и смещение функций φ и ψ находятся следующим образом:
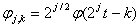
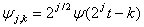
Алгоритм сегментации, основанный на кратномасштабном анализе сигнала содержит следующие шаги [18]:
- Речевой сигнал, оцифрованный с частотой дискретизации 22 050 Гц, разбивается на перекрывающиеся окна размером 512 отсчетов с половинным перекрыванием окна.
- Сигнал раскладывается по U уровням (U=6, использовалось кратномасштабное вейвлет-преобразование в базисе Добеши 8).
- Для каждого j-го уровня строится числовая последовательность:
- Используя соотношение:
- Находится общее количество предполагаемых границ для всех уровней sum(ti), i=(1;N).
- Выбирая пороговый коэффициент gпор изменяющийся в пределах [0;1], получаем неравенство для поиска межфонемного перехода:
- Вычисляем координату границы межфонемного перехода, усредняя сформированный по неравенству выше массив найденных границ.
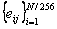
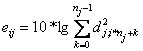
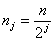
где i – номер скользящего окна; nj – размер скользящего окна на j-ом уровне; n — размер окна в исходном сигнале.
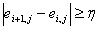
где ɳ= 3,5.
Определяются предполагаемые границы между окнами с номерами i и i+1.
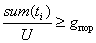
4.2. Модификация алгоритма
При использовании метода кратномасштабного анализа на записях целых слов было определено, что возможно появление в результатах меток границ, не соответствующих ни одной из позиций транскрипции. Пример такого случая показан на рисунке 1 на записи слова машина
. На рисунке видно, что кроме настоящих границ между фонем на звуковом сигнале поставлено две лишние метки: на гласной а
и шипящей ш
. Такая ситуация происходит из-за неверно подобранных параметров ɳ и gпор. Поэтому исходный метод является дикторозависимым — для каждого диктора и отдельных случаев необходимы свои параметры ɳ и gпор.
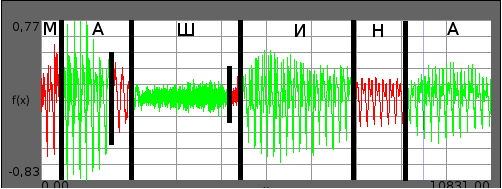
Рисунок 1 — Сегментация слова
машинаметодом кратномасштабного анализа
Поскольку сегментация применяется на записях целых слов с априорным знанием транскрипции, то это позволяет ориентироваться на необходимое количество меток сегментов.
С целью усовершенствования алгоритма предлагается следующая модификация:
- Подсчет количества необходимых меток сегментирования N:
- Изменение параметров ɳ и gпор в диапазонах [2.5;4] и [0.4;1] соответственно для формирования вектора T, задающего всевозможные уникальные метки границ;
- Проверяется выполнение условия (1) в векторе Т:
- Если длина вектора Т больше N, то формируется вектор P, описывающий скорость изменения мощности спектра на границах:
- До тех пор, пока размер вектора T больше N, из вектора T удаляются границы, соответствующий которым элемент вектора P является минимальным.
N = S - 1,
где S - количество фонем в транскрипции слова.
T[i] - T[i+1] < 512, (1)
где T[i] — значение границы в i позиции вектора; T[i+1] — значение границы в следующей позиции вектора.
Если условие (1) выполнялось, то граница T[i] полагалась следующему значению:
T[i] = (T[i]+T[i+1])/2
а значение метки границы T[i+1] удаляется из вектора T.
P[i] = |Fmax(j) - Fmax(j-1)| + |Fmax(j) - Fmax(j+1)|;
j=T[i]/256,
где j — это номер окна в 256 отсчетов звукового сигнала для границы T[i]; Fmax(j) — максимальное значения спектра звукового сигнала в j окне.
Таким образом величина P[i] характеризует скорость изменения мощности спектра на границе T[i]. На действительных границах величина P[i] имеет намного большее значение чем на ненастоящих. Это поясняется тем что на межфонемных переходах спектр будет различаться, а во время произнесения отдельной фонемы будет практически идентичен на соседних окнах.
Описанный алгоритм позволяет независимо от заданного диктора сформировать необходимую базу звуков для синтезатора речи.
5. Интонационные конструкции русской речи
Интонационная конструкция [13] — совокупность интонационных признаков, достаточных для дифференциации значений высказываний и передачи таких параметров высказывания, как коммуникативный тип, смысловая важность составляющих его синтагм, актуальное членение.
В русском языке всего выделяется 7 интонационных конструкций [12].
1. Первая интонационная конструкция (ИК–1, см. рис. 2).
В предцентровой части ИК–1 колебания тона имеют восходяще-нисходящее направление или сосредоточены в средней полосе ее диапазона. Гласный центра произносится с нисходящим движением тона ниже уровня предцентровой части. Постцентровая часть произносится ниже уровня предцентровой части. ИК–1 употребляется при повествовании, в простых предложениях и в сложноподчиненных предложениях с препозицией главной части, синтаксически завершенной, стоящей перед придаточной. Эта интонационная конструкция выражает собственно завершенность, в которой отсутствует смысловое противопоставление или сопоставление.x
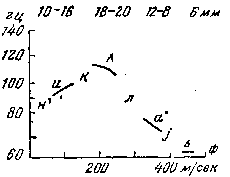
Рисунок 2 — Первая интонационная конструкция
2. Вторая интонационная конструкция (ИК–2, см. рис 3).
В предцентровой части колебания тона сосредоточены в средне-верхней полосе ее диапазона. Гласный центра произносится с нисходящим или ровным движением тона в диапазоне предцентровой части или ниже ее, если центр находится в конце конструкции; уровень тона выше, чем в ИК–1. Гласный центра характеризуется, в отличие от ИК–1, усилением словесного ударения по сравнению с другими ударными слогами. Постцентровая часть произносится на уровне тона ниже предцентровой. ИК–2 употребляется при вопросе, повествовании и волеизъявлении. При выражении вопроса ИК–2 употребляется в предложениях с союзом или с вопросительными местоимениями. В предложениях с местоимениями широко используется передвижение центра ИК–2 как средства смыслового противопоставления. При повествовании, как и при вопросе, ИК–2 является средством смыслового выделения или противопоставления. ИК–2 употребляется при обращениях, приветствиях, в восклицаниях.
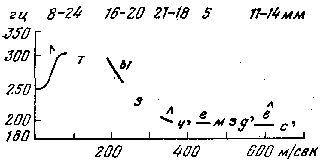
Рисунок 3 — Вторая интонационная конструкция
3. Третья интонационная конструкция (ИК–3, см. рис 4).
В предцентровой части ИК–3 колебания тона сосредоточены в средней полосе ее диапазона. Гласный центра произносится с восходящим движением тона выше уровня предцентровой части; в конце гласного тон ровный или нисходящий. Постцентровая часть произносится на уровне тона ниже предцентровой. ИК–3 употребляется при вопросе, повествовании, волеизъявлении. Также ИК–3 употребляется при собственно вопросе, при повторении вопроса (в ответе), переспросе. В повествовании ИК–3 в не конечной синтагме сигнализирует незавершенность высказывания.
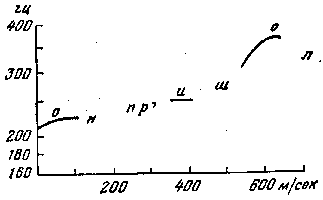
Рисунок 4 — Третья интонационная конструкция
4. Четвертая интонационная конструкция (ИК–4, см. рис 5).
В предцентровой части ИК–4 колебания тона сосредоточены в средн-ерхней полосе ее диапазона или образуют восходящ-исходящее направление. Гласный центра произносится на уровне тона ниже предцентровой части; при этом варьируется ровное, нисходящее, нисходящ-осходящее, восходящее направление тона. Постцентровая часть произносится выше уровня центра и предцентровой части. ИК–4 употребляется при вопросе, повествовании и волеизъявлении. Также ИК–4 употребляется при выражении вопроса, который связан сопоставительными отношениями с предшествующим предложением. В повествовании ИК–4, наряду с ИК–3, сигнализирует о незавершенности высказывания. ИК–4, в отличие от ИК–3, придает речи официальность.
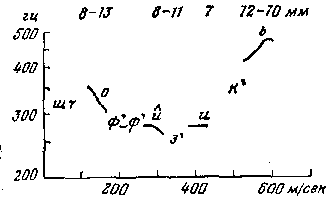
Рисунок 5 — Четвертая интонационная конструкция
5. Пятая интонационная конструкция (ИК–5, см. рис 6).
ИК–5, в отличие от других интонационных конструкций, имеет два центра, которые следуют друг за другом или разъединены несколькими слогами; поэтому ИК–5 возможна в предложении, имеющем минимум два слога. В предцентровой части колебания тона сосредоточены в сред-нижней полосе ее диапазона. Гласный первого центра произносится с восходящим движением тона выше уровня предцентровой части. Длительность согласных и гласного центра увеличена в среднем в два раза по сравнению с другими ударными слогами: за это время можно произнести еще один слог. Уровень тона между центрами выше в предцентровой части, но ниже уровня первого центра. На гласном второго центра тон понижается. Оба центра характеризуются также усилением словесного ударения. Постцентровая часть произносится ниже уровня предцентровой. ИК–5 употребляется преимущественно при повествовании и частично при волеизъявлении и вопросе.
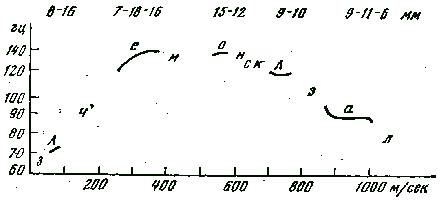
Рисунок 6 — Пятая интонационная конструкция
6. Шестая интонационная конструкция (ИК–6, см. рис 7).
В предцентровой части ИК–6 колебания тона сосредоточены в средней полосе ее диапазона. Гласный центра произносится с восходящим движением тона выше уровня предцентровой части. Более высокий уровень тона отличает ИК-6 от ИК–4. Постцентровая часть произносится выше уровня предцентровой части. ИК–6 употребляется преимущественно в повествовании и частично в вопросе. При повествовании ИК–6, наряду с ИК–3 и ИК–4, сигнализирует в неконечной синтагме о незавершенности высказывания. При этом ИК–6 преобладает в торжественн-риподнятой речи.
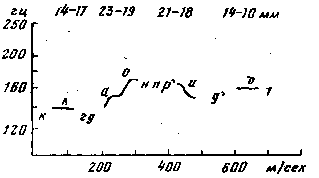
Рисунок 7 — Шестая интонационная конструкция
7. Седьмая интонационная конструкция (ИК–7, см. рис 8).
В предцентровой части ИК–7 колебания тона сосредоточены в средней полосе ее диапазона. Гласный центра произносится с восходящим движением тона выше уровня предцентровой части; гласный заканчивается смычкой голосовых связок, и это отличает ИК–7 от ИК–3. В результате смычки открытый слог становится закрытым, а в закрытом слоге гласный соединяется с согласным через артикуляцию смычки. Смычка голосовых связок акустически воспринимается как резкий перерыв звучания гласного и хорошо прослушивается в отрицании н-
. В этом отрицании дефис показывает разделение двух гласных смычным элементом. Постцентровая часть ИК–7 произносится на уровне тона ниже предцентровой. ИК–7 употребляется в повествовании. В предложениях с местоименными словами, функционирующими как частицы, ИК–7 сигнализирует невозможность или отрицание.
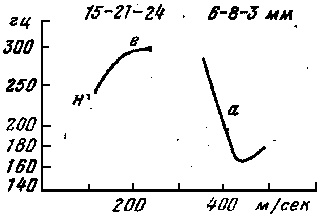
Рисунок 8 — Седьмая интонационная конструкция
6. Обзор методов синтеза речи с интонационной окраской
6.1. Синтез интонационной составляющей речевого сигнала с применением сплайновой интерполяции
В данном подходе [17] для синтеза речевого сигнала по компилятивному принципу необходимо предварительно получить формализованное описание его фонетических и интонационных свойств. Для всех фонем необходимо указать интонационные характеристики. В их число входит и множество опорных точек параметрических кривых. При этом параметры соседних фонем должны быть плавно согласованны.
На рисунке 9 показаны основные этапы синтеза речевого сигнала по компилятивному принципу с применением гладких параметрических кривых заданных ограниченным множеством опорных точек.
Для достижения качественного синтеза важно плавно регулировать следующие параметры речевого сигнала:
- Контур частоты основного тона – это главная интонационная составляющая речи.
- Амплитудные огибающие, основным назначением которых является динамическое регулирование амплитудного уровня сигнала. Совместное увеличение амплитуды и частоты сигнала приводит к увеличению его громкости.
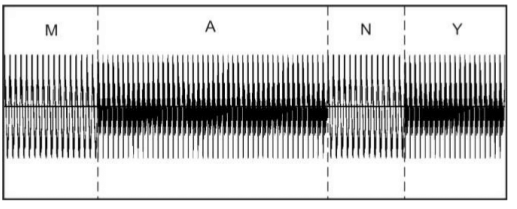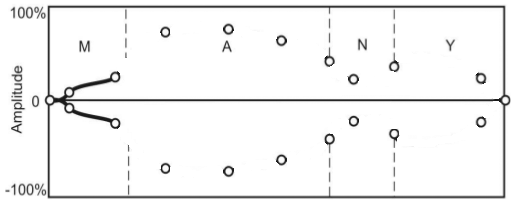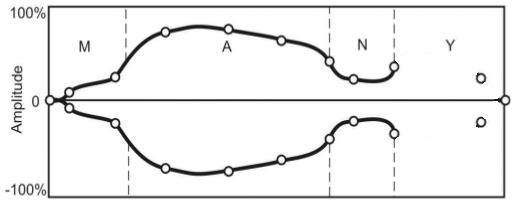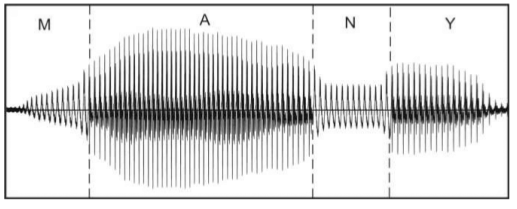
Рисунок 9 — Этапы наложения интонационной конструкции на речевой сигнал с помощью сплайновой интерполяции (анимация: 8 кадров, 5 циклов повторения, 145 килобайт)
При компилятивном синтезе [8] на основе базовых фрагментов речи путем различных алгоритмических манипуляций звуковому сигналу придают необходимую форму. Заданная форма речевого сигнала может зависеть от множества различных факторов: от языка, индивидуальных особенностей голоса, текста, требуемой интонации, скорости и громкости произношения и т. д.
Заранее подготовленный, нормализированный по длительности фонем, общему уровню амплитуд и плавно соединённый из различных фрагментов речевой сигнал подаётся на вход системы регулирования параметров. В зависимости от требуемых интонационных характеристик формируется контур частоты основного тона и накладывается на исходный речевой сигнал. Затем на сигнал накладываются амплитудные огибающие.
Для задания кривой выделяется ограниченное множество опорных точек. Выбирается их оптимальное расположение так чтобы наилучшим образом аппроксимировать исходную функцию контролируемого параметра. Изначально в качестве опорных точек выбираются экстремумы аппроксимируемой функции.
6.2. Синтез монотонной и выразительной речи методом Unit Selection
Другой подход к синтезу речи с интонационной окраской методом Unit Selection описан в статье [15]. В настоящее время этот подход является наиболее распространенным [27]. Он основан на генерации речевого сигнала путем конкатенации естественных речевых отрезков, выбираемых из речевой базы данных. Как правило, используются речевые отрезки, соответствующие отдельным звукам или дифонам. Большое количество элементов базы данных, различающихся спектральными и просодическими характеристиками, позволяет синтезировать речь с высокой степенью естественности. Чем больше объем речевой базы данных, тем с большей вероятностью в ней будут найдены необходимые для синтеза речевые отрезки и меньше придется модифицировать синтезированный сигнал, добиваясь необходимых значений длительности, частота основного тона (F0) и плавных переходов от одного звука к другому. Известно, что любая модификация речевого сигнала отрицательно сказывается на качестве его звучания.
Важной составляющей метода Unit Selection является алгоритм выбора элементов из базы данных. Проблема состоит в том, что приходится решать, какие критерии выбора важнее: контекст, интонация, длительность и т.д. Поскольку сбалансированность критериев не достигнута, а выбор осуществляется автоматически, процесс синтеза речи иногда выходит из-под контроля
[28], и синтезированная речь воспринимается как неуравновешенная
.
В системе синтеза украинской речи [16] используется разработанный в МНУЦИТиС фонемно-трифонный метод синтеза речи в амплитудно-временной области, являющийся вариантом метода Unit Selection. Объединение метода синтеза с разработанными индивидуализированными просодическими моделями позволяет озвучивать тексты в соответствии с выбранными голосами и стилями чтения.
Разработанная система синтеза индивидуализированной украинской речи (рис. 10) состоит из следующих компонентов: речевых баз данных, лингвистического процессора, модуля выбора элементов из речевой базы данных, акустического процессора.
Речевые базы данных используются не только в процессе синтеза речи. Содержащаяся в их аннотациях информация служит для предварительной настройки моделей произношения диктора. В процессе синтеза речи настроенный лингвистический процессор генерирует фонемно-просодическую транскрипцию входного текста в виде последовательности фонем с вычисленными просодическими характеристиками длительности и интонационного контура.
Модуль выбора элементов из базы данных сравнивает фонемно-просодическую транскрипцию входного текста (то есть информацию о том, что и как должно синтезироваться) с аннотацией базы данных (то есть с информацией о том, какой речевой материал имеется в наличии). Модуль выбора оценивает и выбирает элементы речевой базы данных в соответствии с характеристиками, определенными при анализе текста.
Выбранные элементы конкатенируются акустическим процессором и озвучиваются акустической системой.
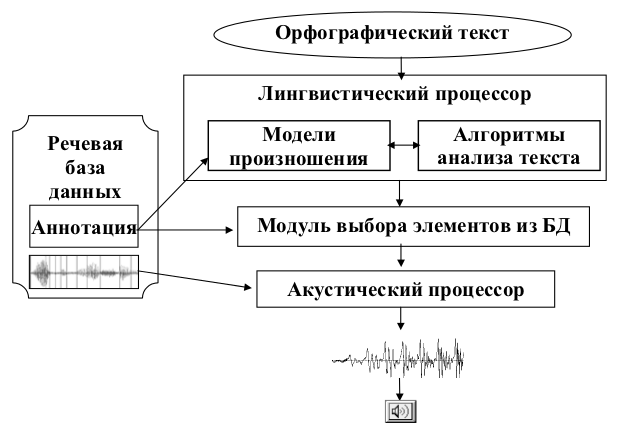
Рисунок 10 — Блок-схема системы синтеза украинской речи по тексту
Вычисление длительности фонем осуществляется с помощью модели, параметрами которой являются: средняя длительность фонемы (по аннотации РБД), тип контекста, в котором она находится в синтезируемом высказывании, и набора коэффициентов длительности для данной фонемы, соответствующих типу контекста. В процессе синтеза речи тип контекста устанавливается с учетом коммуникативного типа синтагмы, наличия в синтагме логического ударения, позиции фонемы по отношению к началу/ концу синтагмы, типа слога (открытый, закрытый) и сегментного типа непосредственного левого и правого окружения (ударная/безударная гласная, согласная фонемы). Для вычисления длительности фонемы ее средняя длительность умножается на коэффициент, соответствующий типу контекста.
Модель интонирования используется для вычисления интонационных контуров — последовательностей значений F0 на протяжении текста. Модель основана на том, что главной интонационной единицей речи считается синтагма — часть фразы, имеющая выраженный интонационный контур. Синтагма состоит из одной или нескольких акцентных групп. Акцентная группа (акцентная единица) — это одно или несколько слов, объединенных общим ударением. Разработанная модель интонирования близка к модели интонационных портретов акцентных единиц, предложенной Б.М. Лобановым [8].
Параметрами интонационной модели являются:
- коммуникативный тип синтагмы, определяемый в настоящее время по знаку пунктуации и некоторым лексико-грамматическими показателям (вопросительные слова, союзы и т.д.);
- количество акцентных групп в синтагме;
- место ядерной (главной) акцентной группы в синтагме;
- наборы целевых значений F0 для каждой акцентной группы.
В любой синтагме обязательно присутствует ядерная акцентная группа (АГ), несущая главное (синтагматическое) ударение. В общем случае, если в синтагме две АГ, то первая из них является начальной, а вторая — ядерной. Если акцентных групп три или больше, то первая из них является начальной, со второй по предпоследнюю включительно — предъядерной, последняя — ядерной. Наличие логического ударения в синтагме может сделать ядерной любую АГ, в этом случае все АГ, следующие за ядерной, считаются заядерными.
Каждый коммуникативный тип синтагмы имеет свой интонационный контур, состоящий из интонационных контуров входящих в нее АГ. Каждая АГ синтагмы состоит из ядра — ударной гласной, предъядра — всех фонем АГ, находящихся перед ударной гласной, и заядра — всех фонем АГ, находящихся после ударной гласной. Главное предположение модели интонирования состоит в том, что топологические свойства просодических характеристик не изменяются (или изменяются незначительно) с изменениями фонетического контекста и числа фонем в предъ- и заядре АГ [8].
Контур АГ задается последовательностью 10 значений F0. Контур синтагмы задается 10n значениями F0, где n — количество АГ в синтагме. Интонационные контуры акцентных групп синтагмы накладываются
на их фонемные транскрипции, каждое из 10 целевых значений F0 приписывается соответствующим целевым точкам АГ. Первые два из 10 целевых значений F0 задают движение F0 на предъядре АГ; значения F0 с 3 по 8 задают изменение F0 на ядре (ударной гласной); последние два значения F0 описывают движение F0 на заядре АГ.
Выводы
Синтез речи является актуальной задачей. На момент написания данного реферата получены следующие результаты:
- разработан алгоритм сегментации речевого сигнала для автоматизированного наполнения базы звуков синтезатора;
- рассмотрены интонационные конструкции русского языка;
- рассмотрены существующие подходы к созданию интонационной окраски.
Дальнейшие исследования направлены на следующие аспекты:
- определение интонационной конструкции текста;
- приведение речевого сигнала к заданному мелодическому контуру.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Сорокин В.К. Синтез речи / Сорокин В.К. — М. : Наука, 1992. — 392 с.
- Вишнякова О.А. Автоматическая сегментация речевого сигнала на базе дискретного вейвлет-преобразования / О.А. Вишнякова, Д.Н. Лавров // Математические структуры и моделирование — 2011, — Выпуск 23. С. 43–48.
- Давыдов А.Г. Использование периодичности речевого сигнала при фонемной сегментации речи / А.Г. Давыдов, Б.М. Лобанов // Доклады Белорусского государственного университета информатики и радиоэлектроники, № 2, 2006. — С. 69–74.
- Колоков А.С. Предварительная обработка и сегментация речевого сигнала в частотной области для распознавания речи / Колоков А.С. // Автоматика и телемеханика, № 6, 2003. — С. 152–162.
- Д. Фланаган Анализ, синтез и восприятие речи / Д. Фланаган — М. : Связь, 1968. — 395 с.
- Фант Г. Анализ и синтез речи / Фант Г. — Новосибирск : Наука, 1970 — 167 с.
- Фант Г. Акустическая теория речеобразования / Фант Г. — М : Наука, 1964. — 329 с.
- Лобанов Б.М. Компьютерный синтез и клонирование речи / Б.М. Лобанов, Л.И. Цирульник — Минск : Белорусская наука, 2008. — 316 с.
- Буланин Л.Л. Фонетика современного русского языка / Буланин Л.Л. — М. : Высшая школа, 1970. — 208 с.
- Бондарко Л.Б. Звуковой строй современного русского языка. / Бондарко Л.Б. — М. : Просвещение, 1977. — 175 с.
- Бондарко Л.В. Фонетическое описание языка и фонологическое описание речи / Бондарко Л.В. — Л. : ЛГУ, 1981. — 199 с.
- Брызгунова Е. А. Интонация. Русская грамматика / Брызгунова Е. А. — М. : Наука, 1980. — 378 с.
- Пешковский А.М. Интонация и грамматика. / Пешковский А.М. — М. : Избр. Труды, 1959. — 247 с.
- Цеплитис Л.К. Анализ речевой интонации / Цеплитис Л.К. — Рига : Зинтарис, 1974. — 270 с.
- Людовик Т.В. Автоматический синтез нейтральной и выразительной речи / Людовик Т.В. // Искусственный интеллект, № 1, 2010. — С. 9-02.
- Lyudovyk T. Unit Selection Speech Synthesis Using Phonetic-Prosodic Description of Speech Databases / Lyudovyk T., Sazhok M. // Proceedings of the International Conference
Speech and Computer
(SPECOM'2004). — St.-Petersburg (Russia), 2004. — Р. 594-599. - Калимолдаев М.Н. Синтез интонационной составляющей речевого сигнала с применением сплайновой интерполяции / М.Н. Калимолдаев, Е.Н. Амиргаливев, Р.Р Мусабаев [Электронный ресурс]. — Режим доступа : http://conf.nsc.ru/files/conferences/MIT-2011/fulltext/58039/58041/Калимолдаев_Статья.pdf
- Ермоленко Т.В. Алгоритмы сегментации с применением быстрого вейвлет-преобразования [Электронный ресурс]. — Режим доступа : http://www.dialog-21.ru/Archive/2003/Ermolenko.htm
- Ермоленко Т.В. Классификация фреймов речевого сигнала в задачах дикторонезависимого распознавания речи / Т.В. Ермоленко, А.В. Жук // Искусственный интеллект. — 2011. — № 3 — C. 152–161.
- Сорокин В.Н. Сегментация и распознавание гласных / В.Н. Сорокин, А.И. Цыплихин // Информационные процессы. — 2004. — Т. 4, № 2. — С. 20-04.
- Сергиенко А. Б. Цифровая обработка сигналов / Сергиенко А. Б. — СПб : Питер, 2006. — 751 с.
- Р. Лайонс Цифровая обработка сигналов / Р Лайонс — М : Бином-Пресс, 2011. — 654 с.
- Э. Айфичер Цифровая обработка сигналов. Практический подход / Э. Айфичер, Б. Джервис — М : Вильямс, 2004. — 992 с.
- Умняшкин С.В. Теоретические основы цифровой обработки и представления сигналов / Умняшкин С.В. — М : Форум, 2007. — 304 с.
- Дремин И.М. Вейвлеты и их использование / И.М. Дремин, О.В. Иванов, В.А. Нечитайло // Успехи физических наук. — 2001. — Т. 171, № 5. — С. 465-500.
- Taylor P. Text to Speech Synthesis / University of Cambridge, — 2007. 597 pp.
- Hunt A. Unit selection in a concatenative speech synthesis system using a large speech database / Hunt A., Black A. // Proceedings of the International Conf. on Acoustics, Speech, and Signal Processing. — Atlanta (USA), 1996. — Vol. 1. — P. 373-376.
- Perspective on the Next Challenges for TTS Research / [Schroeter J., Conkie A., Syrdal A. и др.] // Proceedings of the IEEE Workshop on Speech Synthesis. — 2002. — P. 211-214.