Фонетико-акустическая база данных для многоязычного синтеза речи по тексту
Авторы: Лобанов Б.М., Цирульник Л. И., Б. Пьорковска, Я. Рафалко, Э. Шпилевский
Источник: Труды международной конференции «Диалог 2006»
|
Назад в библиотеку
Фонетико-акустическая база данных для многоязычного синтеза речи по текстуАвторы: Лобанов Б.М., Цирульник Л. И., Б. Пьорковска, Я. Рафалко, Э. Шпилевский АннотацияПроводится анализ особенностей фонетических систем белорусского, польского и русского языков, на основе которого предлагается общий подход к созданию единой фонетико-акустической БД для многоязычного синтеза речи по тексту. Описываются принципы создания и обработки текстовых и речевых корпусов для каждого из языков. ВведениеВ настоящее время для некоторых славянских языков, таких как русский, чешский, польский, украинский, уже существует практически используемые или экспериментальные образцы синтезаторов речи по тексту (СРТ) [1]. Не имеется, однако, никаких сведений о создании многоязычных СРТ для славянских языков, а также СРТ для белорусского языка. Данная работа является продолжением проводимых ранее исследований, базирующихся на аллофонно-волновом представлении речевого сигнала [2] и направленных на разработку многоголосых [3] и многоязычных [4] СРТ. Синтез речи по тексту на славянских языках — белорусском, польском, русском — предполагает создание фонетико-акустической базы данных, построенной на единых принципах, отражающих внутри- и межъязыковую специфику фонетических систем и позиционно-комбинаторных явлений, порождающих аллофонию речи. Для этого необходимо определить принципы создания и обработки текстовых и речевых корпусов для каждого из языков и особенности формирования на их основе БД аллофонов и мультифонов. Решению именно этих вопросов посвящена данная работа. 1. Особенности фонетических систем белорусского, польского и русского языковФонетические
системы языков, относящихся к группе славянских, имеют между собой значительное
сходство, однако каждый из них обладает также специфическими особенностями,
иногда значительными. Исследуемые фонетические системы белорусского, польского
и русского языков являются относительно близкими, особенно русского и
белорусского. В белорусском языке насчитывается 41 фонема, из них 6 гласных и
35 согласных, а в русском всего — 42, гласных — 6 и согласных — 36. Польский
язык фонетически более разнообразен. В нём насчитывается 51 фонема, из них 8
гласных и 43 согласных. В таблице 1 представлена обобщённая информация о
фонемном составе 3-х языков и об их различии по способу и месту образования. В
каждой ячейке таблицы представлены имена фонем, характеризующихся
определённым способом и местом
образования, для белорусского, польского и русского языков порядке В таблице 1 затемнены ячейки, фонетическое качество звуков которых имеет практически полное сходство для каждого из языков. Как видно из таблицы, количество таких ячеек в процентном отношении ко всем использующимся ячейкам довольно значительно — 66%. Отличительные особенности фонетических систем белорусского и русского языков заключаются в следующем. В белорусском языке отсутствуют следующие фонемы:
В белорусском языке имеется ряд специфических фонем, отсутствующих в русском:
Таблица 1. Фонетические системы белорусского, польского и русского языков
Сравнивая фонетическую систему польского языка с русским, отметим некоторые её особенности. В польском языке присутствуют все фонемы, характерные для русского языка, однако произношение мягких фонем Ш и Ч отличается от польских мягких Ś и Ć, артикуляторный уклад которых промежуточный между мягкими русскими С, Ш и Ц, Ч соответственно. Кроме того, в польском языке имеется ряд специфических фонем, отсутствующих в русском:
Если сравнить фонетические системы всех рассматриваемых языков, а также каждую из пар языков, подсчитывая количество совпадений в ячейках таблицы 1, то получим следующие значения в процентах к общему количеству используемых ими ячеек:
Как это ни удивительно на первый взгляд, но белорусский язык по фонетическому составу отличается почти в равной степени как от польского, так и от русского. Сказанное, конечно, не учитывает статистику употребления тех или иных фонем в различных языках. Так, хорошо известно, что схожие по звучанию русские и польские фонемы /t’/, /d’/, /s’/, /z’/, /l/, употребляемые в русском языке очень часто, в польском встречаются гораздо реже. В близких по звучанию словах вместо них используются, соответственно, специфические польские фонемы — /ć/, /dź/, /ś/, /ź/, /ł/. 2. Мини- и макси-наборы аллофонов для синтеза белорусской, польской и русской речиКак известно, в речевом потоке фонемы реализуются в виде аллофонов, или иначе, в виде позиционных и комбинаторных оттенков фонем. Позиционный фактор учитывает позицию данной фонемы относительно словесного, акцентно-группового, синтагматического и фразового ударения. Комбинаторный фактор учитывает ближайшее фонемное окружение. В общем случае невозможно дать точную оценку количества аллофонов, т.к. она напрямую зависит от степени детализации учёта влияния позиционных и комбинаторных факторов. Однако качество синтезированной речи напрямую зависит от степени детализации. Стремление к большей детализации может привести к огромному количеству аллофонов (несколько сот тысяч), что делает задачу создания БД аллофонов неразрешимой. Опыт создания русскоязычных СРТ [2] показал, что синтезированная речь достаточно высокого качества может быть достигнута при некоторых определённых условиях генерации позиционных и комбинаторных аллофонов. Были исследованы 2 типа аллофонных наборов: так называемые макси- и мини- наборы. При использования макси-набора аллофоннов для синтеза русской речи создаются следующие позиционные аллофоны гласных: ударный - (0), частично ударный - (1), первый предударный - (2), не первый предударный - (3), заударный - (4). Всего 5 позиций. С учётом левого контекста создаются следующие комбинаторные аллофоны гласных: после синтагматической паузы - (0), после большинства губных - (1), переднеязычных - (2) и заднеязычных - (3) твёрдых, после /Л/ - (4), /Р/ - (5), /М/ - (6)/, /Н/ - (7), после большинства мягких - (8), после /Р’/ - (9), /M’/ - (10), /Н’/ - (11), после гласных /У/ - (12), /О/ - (13), /А/ - (14), /Э/ - (15), /Ы/ - (16), /И/ - (17). Всего 18 левых контекстов. Для учёта правого контекста создаются следующие комбинаторные аллофоны гласных: перед синтагматической паузой - (0), перед переднеязычными и заднеязычными твёрдыми согласными и гласными /У/, /О/, /А/, /Э/ ,/Ы/ - (1), перед губными твёрдыми - (2), перед губными мягкими - (3) перед не губными мягкими согласными и гласным /И/ - (4). Всего 5 правых контекстов. Итого, для 6-ти гласных создаются Nv = 5*18*5*6 = 2700 аллофонов. Позиционные аллофоны согласных для макси-набора включают два положения: в ударном слоге – (0) и в безударном слоге – (1). Левый контекст согласных включает следующие группы: после паузы - (0), после глухих - (1) и звонких - (2) согласных, после гласных - (3). Правый контекст: перед паузой - (0), перед глухими - (1) и звонкими - (2) согласными, перед безударными - (3) и ударными - (4) гласными. Итого, для всех 36-ти согласных создаются Nc = 2*4*5*36 = 1440 аллофонов. Всего создаётся: 2700 + 1440 = 4140 аллофонов русской речи. При использования мини-набора для синтеза русской речи создаётся только 2 типа позиционных аллофонов гласных: ударный - (0), безударный - (1). С учётом левого контекста создаются следующие комбинаторные аллофоны гласных: после синтагматической паузы - (0), после твёрдых губных - (1), передне- и среднеязычных - (2), после твёрдых заднеязычных и гласных - (3) и после мягких - (4). Всего 5 левых контекстов. С учётом правого контекста создаются следующие комбинаторные аллофоны гласных: перед синтагматической паузой - (0), перед переднеязычными и заднеязычными твёрдыми согласными и гласными /У/, /О/, /А/, /Э/, /Ы/ - (1), перед губными согласными - (2), перед мягкими согласными и гласной /И/ - (3). Итого, для 6-ти гласных создаются Nv = 2*5*4*6 = 240 аллофонов. Аллофоны согласных создаются только с учётом правого контекста: перед паузой - (0), перед глухими - (1) и звонкими - (2) согласными, перед безударными - (3) и ударными - (4) гласными. Итого, для всех 36-ти согласных создаются Nc = 5*36 = 180 аллофонов. Всего создаётся: 240+180=420 аллофонов русской речи. Полученные оценки количества аллофонов, рассчитанные теоретически, являются сильно завышенными из-за того, что, во-первых, очень многие позиционные и комбинаторные ситуации вообще не встречаются в речи и, во-вторых, для многих аллофонов акустические различия настолько невелики, что ими можно пренебречь. В результате, как показывает практика, используемое количество аллофонов в макси-наборе оказывается более чем в 2 раза, а в мини-наборе в 1,5 раза меньшим. Результаты подсчёта теоретического и практически используемого количества аллофонов для каждого из 3-х языков приведены в таблице 2. Таблица 2.Количество аллофонов
Для обозначения имён аллофонов при синтезе речи используется имена соответствующих фонем (латинские буквы), а также 3 цифровых индекса. При этом 1-й индекс обозначает позицию фонемы относительно полноударного гласного, 2-й индекс – левый контекст, а 3-й индекс — правый контекст. В таблице 3 приведены единые обозначения аллофонов, используемых для синтеза речи на трёх славянских языках. Таблица 3.Перечень имён аллофонов, используемых для синтеза речи на белорусском, польском и русском языках
3. Текстовые и речевые корпусы для создания БД аллофоновПроцесс создания БДаллофонов включает следующие этапы:
Текстовые корпусы
созданы на основе специально подобранного набора слов в количестве, равном
числу используемых в каждом из языков аллофонов. Каждое из слов отбиралось
исходя из критерия наилучшей репрезентации данного аллофона в речи диктора.
Речевые корпусы, соответствующие текстовым корпусам, создавались в студийных
условиях специально проинструктированными профессиональными дикторами. Ниже, в
таблицах 4 и 5, приведены фрагменты списка слов для создания ( Таблица 4. Фрагмент списка слов для
Таблица 5. Фрагмент списка слов для
Таблица 6. Мини-набор аллофонов согласной /R/ для 3-х языков
Таблица 7. Мини-набор аллофонов ударной гласной /А/ для 3-х языков
4. Процедура создания БД звуковых волн аллофоновПроцедура обработки созданной речевой базы включает фонемную сегментацию
речевого сигнала, аллофонную маркировку сегментов и сохранение полученного
набора сегментов естественной речевой волны в аллофонно-волновой БД. Совершенно
очевидно, что хотя использование для синтеза макси-набора обеспечит наивысшее
качество речи, его создание Общая схема процедуры создания мини- и макси-БД аллофоных волн представлена на рис.1. 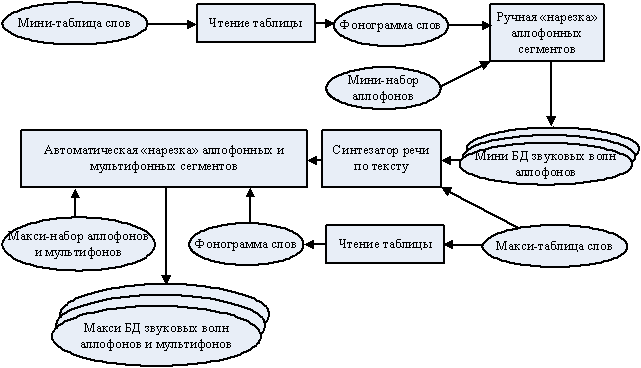
Рис. 1. Процедура создания мини- и макси-БД звуковых волн аллофонов ЗаключениеРазработанные мини- и макси-наборы аллофонов для белорусского, польского и русского языков, а также созданные в соответствии с описанной технологией БД аллофонных волн для трёх языков используются в многоязычном и многоголосовом синтезаторе речи по тексту. Кроме очевидного преимущества разработанной единой фонемно-аллофонной классификации — возможности создания многоязычного синтезатора — описанный подход позволяет также синтезировать речь с заданным акцентом, например, русскую речь с белорусским акцентом. Такое применение системы может понадобиться, в частности, при персонализированном синтезе речи по тексту для передачи индивидуальных фонетических особенностей дикции. Список литературы1. http://www.speech.cs.cmu.edu/comp.speech/. 2. Лобанов Б.М. Синтез речи по тексту // Четвёртая Международная летняя школа-семинар по искусственному интеллекту. Сб. науч. тр. Мн.:Изд. БГУ, 2000. С. 57-76. 3. Lobanov B.M., Tsirulnik L.I. Phonetic-Acoustical Problems of Personal Voice Cloning by TTS // Proc. of the
International Conference 4. Shpilewski E., Piurkowska B., Rafalko J., Lobanov B., Kiselov V.,
Tsirulnik. Polish TTS in Multi-Voice Slavonic
Languages Speech Synthesis System. // Proc. of the International Conference
5. Лобанов Б.М., Киселёв В.В. Автоматизация
клонирования персонального голоса и дикции для систем синтеза речи по тексту //
Международная конференция 6. Цирульник Л.И. Автоматизированная система клонирования фонетико-акустических характеристик речи // Информатика. № 1(9).Мн., 2006. С. 37-46. |
|||||||||||||||||||