
Орлова Євгенія Валеріївна
Факультет: Інститут інформатики і штучного інтелекту
Кафедра: Систем штучного інтелекту
Спеціальність «Системи штучного інтелекту»
Аналіз методів і моделей автоматичної побудови онтологій
Науковий керівник: доц. Єгошина Ганна Анатоліївна
Реферат за темою випускної роботи
Вступ
1. Актуальність теми
2. Мета і задачі дослідження
3. Очікувана наукова новизна
4. Огляд досліджень та розробок по темі
4.1 Світовий рівень
4.2 Національний рівень
4.3 Локальний рівень
5. Поняття онтології
6. Класифікація онтологій
6.1 Класифікація за ступенем формальності
6.2 Класифікація онтологій по вмісту
6.3 Класифікація за метою створення
7. Області застосування онтологій
8. Методи автоматичної побудови онтологій
8.1 Представлення онтологій у вигляді кінцевого автомата
8.2 Побудова семантичної карти ресурсу
8.3 Підхід на основі лексико-синтаксичних шаблонів
8.4. Автоматична побудова онтології по колекції текстових документів
Висновки
Список літератури
Вступ
Інтернет – це велике інформаційне поле, величезна база знань, що містить докладні відомості наукового, історичного, політичного, повсякденного характеру. Інтернет можна порівняти з величезним словником, що описує нашу планету і всі процеси, що супроводжують розвиток людської цивілізації, які відбувалися, відбуваються і можуть відбутися в майбутньому.
На сьогоднішній день практично вся інформація, яка доступна у Інтернет не містить семантики і тому її пошук, релевантний запитам користувача, а також інтеграція в рамках конкретної предметної області ускладнені. Для забезпечення ефективного пошуку, веб-програма повиненна чітко розуміти семантику документів, представлених в мережі. У зв'язку з цим, можна спостерігати бурхливий ріст і розвиток технологій Semantic Web, що відбувається в даний час. Консорціумом W3C була розроблена концепція, яка базується на активному використанні метаданих, мові розмітки XML, мові RDF (Resource Definition Framework – Середа Опису Ресурсу) і онтологічному підході. Всі запропоновані засоби дозволяють здійснювати обмін даними та їх багаторазове використання.
1. Актуальність теми
Важливою проблемою у розвитку Інтернет є його інтелектуалізація, і пов'язані з цим інтеграція даних, якісний пошук, інтеграція Веб служб і багато іншого. Ефективні засоби для зазначених завдань пропонуються в рамках підходу Semantic Web.
Онтології отримали широке поширення в рішенні проблем представлення знань та інженерії знань, семантичної інтеграції інформаційних ресурсів, інформаційного пошуку і т.д. Інтелектуальні системи на основі онтологій показали на практиці свою ефективність, проте побудова онтології вимагає експертних знань у досліджуваній предметній області і займає суттєвий обсяг часу, тому актуальним завданням є автоматизація процесу побудови онтології.
2. Мета і задачі дослідження
Метою даної магістерської роботи є підвищення ефективності методу автоматичної побудови онтології по колекції текстових документів.
Для досягнення поставленої мети необхідно вирішити наступні завдання:
- розглянути мови опису онтологій;
- проаналізувати області застосування онтологій;
- розглянути мови опису онтологій;
- провести аналіз існуючих методів автоматичної побудови онтологій;
- реалізувати автоматичне побудова онтології на основі результатів попередньої кластеризації колекції текстових документів.
3. Очікувана наукова новизна
Запропоновано нову модифікацію методу автоматичної побудови онтології по колекції текстових документів з попередньою кластеризацією колекції текстових документів. В якості алгоритму кластеризації пропонується алгоритм LSA / LSI.
4. Огляд досліджень та розробок по темі
4.1 Світовий рівень
Кандидат технічних наук за спеціальністю «Системи та засоби штучного інтелекту» Щербак С.С. створив блог, де обговорюються теми штучного інтелекту, онтологій і Semantic Web (Shcherbak.net).
Одним з ключових напрямків центру штучного інтелекту (ІЦІІ) є методи семантичного пошуку та аналізу полуструктурірованное інформації (http://skif.pereslavl.ru).
На даний момент існує багато зарубіжних систем, що відносяться до класу інструментів онтологічного інжинірингу, які підтримують різні формалізми для опису знань і використовують різні машини виводу з цих знань. Серед вже розроблених онтологій найбільш відомими і об'ємними є CYC (http://www.cyc.com) і SUMO (http://www.ontologyportal.org/).
4.2 Національний рівень
У харківському національному університеті радіоелектроніки Бондаренко М.Ф., Соловйова Е.А., Єльчанінов Д.Б., Кулібаба В.В. та ін вивчають методи створення онтологічних систем і засобів їх підтримки.
Вчені кафедри математичної інформатики Київського національного університету імені Тараса Шевченка становлять ядро проекту «Українська Лінгвістична Лабораторія» (http://lingvoworks.org.ua). Тему онтологій особливо детально розглядають Ніконенко, Марченко, Глибовець.
4.3 Локальний рівень
У статті Бажанової А. І., Мартиненко Т. В. «Дослідження застосування онтологічних моделей для семантичного пошуку» проаналізовано основні засоби побудови онтологій. Проведено порівняльний аналіз основних моделей подання даних в онтологіях, а також основних мов опису онтологій і редакторів для роботи з ними [1].
Болотова В.І. у своїй випускний роботі на тему «Інструментальні засоби створення баз знань на основі системи онтологій» розглядає розробку класифікації відомих з літератури властивостей онтологій, зручною для систематичного оцінювання онтологій на практиці [2].
Анохіна В.С. в авторефераті до магістерської роботи розглядає автоматизацію вилучення знань з Internet у формі онтології для побудови прикладних баз знань [3].
5. Поняття онтології
Онтології є новими інтелектуальними засобами для пошуку ресурсів у мережі Інтернет, новими методами подання та обробки знань і запитів. Вони здатні точно та ефективно описувати семантику даних для деякої предметної області та вирішувати проблему несумісності і суперечливості понять. Онтології володіють власними засобами обробки (логічного виводу), відповідними задачам семантичної обробки інформації. Так, завдяки онтологіям, при зверненні до пошукової системи користувач матиме можливість отримувати у відповідь ресурси, семантично релевантні запиту (рис. 1 [4]).
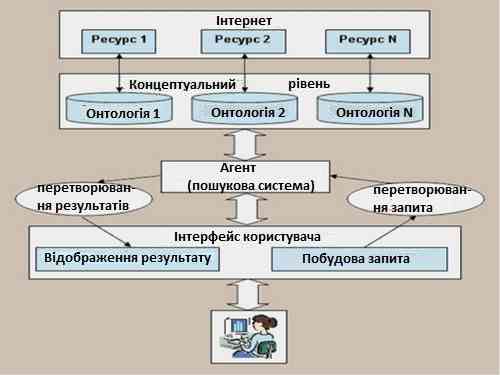
Рисунок 1 – Схема пошуку на основі онтологій
Відомі кілька підходів до визначення поняття онтології, але загальноприйнятого визначення до цих пір немає, оскільки залежно від кожної конкретної задачі зручно інтерпретувати цей термін по-різному: від неформальних визначень до описів онтологій в поняттях і конструкціях логіки і математики [4]. Нижче буде наведено найбільш часто використовується.
Онтологія – це спроба всеосяжної та детальної формалізації певної галузі знань за допомогою концептуальної схеми. Зазвичай така схема складається зі структури даних, що містить всі релевантні класи об'єктів, їх зв'язки і правила (теореми, обмеження), прийняті в цій галузі.
6. Класифікація онтологій
У проектуванні онтологій умовно можна виділити два напрями, якi до деякого часу розвивалися окремо. Перше пов'язане з представленням онтології як формальної системи, заснованої на математично точних аксіомах. Другий напрямок розвивався в рамках комп'ютерної лінгвістики та когнітивної науки. Там онтологія розумілася, як система абстрактних понять, що існують тільки у свідомості людини, яка може бути виражена природною мовою (або якоюсь іншою системою символів). При цьому зазвичай не робиться припущень о точності або несуперечності такої системи.
Таким чином, існує два альтернативних підходи до створення і дослідження онтологій. Перший (формальний) заснований на логіці (предикатів першого порядку, дескриптивної, модальної і т.п.). Другий (лінгвістичний) заснований на вивченні природної мови (зокрема, семантики) і побудові онтологій на великих текстових масивах, так званих корпусах.
Нині дані підходи тісно взаємодіють. Йде пошук зв'язків, які дозволяють комбінувати відповідні методи. Тому іноді буває складно відокремити лексичні онтології з елементами формальної аксіоматики від логічних систем з включеннями лінгвістичних знань. Незалежно від різних підходів можна виділити три основні принципи класифікації онтологій [5]:
- за ступенем формальності;
- за наповненням, змістом;
- за метою створення.
6.1 Класифікація за ступенем формальності
Зазвичай люди і комп'ютерні агенти (програми) мають певне уявлення значень термінів. Програмні агенти іноді надають специфікацію вхідних і вихідних даних, які можуть бути використані як специфікація програми. Подібним чином онтології можуть бути використані, щоб надати конкретну специфікацію імен термінів і значень термінів. В рамках такого розуміння (де онтологія є специфікацією концептуальної моделі – концептуалізації) існує простір для варіацій. Онтології можуть бути представлені як спектр в залежності від деталей реалізації (рис. 2 [5]).
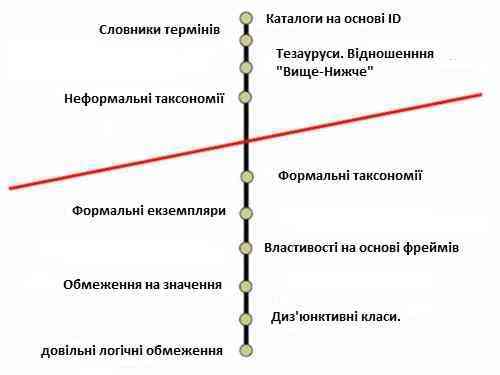
Рисунок 2 - Спектр онтологій
Cпектр онтологій за ступенем формальності подання, використання тих чи інших формальних елементів. Кожна точка відповідає наявності деяких ключових структур в онтології, що відрізняють її від інших точок на спектрі. Коса риса умовно відділяє онтології від інших ресурсів, що мають онтологічний характер.
6.2 Класифікація онтологій по вмісту
Ця класифікація дуже схожа на попередню, але тут акцент зміщується на реальний вміст онтології, а не на абстрактну мету (рис. 3 [5]).
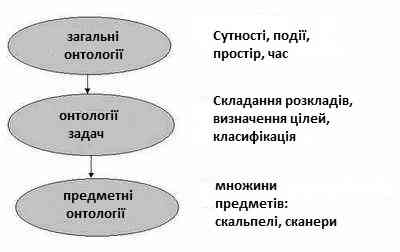
Рисунок 3 - Класифікація онтологій по вмісту
6.3 Класифікація за метою створення
В рамках цієї класифікації виділяють 4 рівня (рис. 4 [5]): онтології уявлення, онтології верхнього рівня, онтології предметних областей та прикладні онтології.
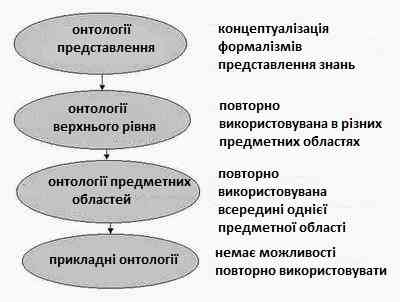
Рисунок 4 - Класифікація онтологій за метою створення
7. Області застосування онтологій
Онтології розробляються і можуть бути використані при вирішенні різних завдань, у тому числі для спільного застосування людьми або програмними агентами, для можливості накопичення та повторного використання знань в предметній області, для створення моделей і програм, що оперують онтологіями.
Онтології можуть бути використані скрізь, де потрібна обробка даних, що враховує їх семантику. В силу початкової орієнтованості мови OWL на машинну обробку, правильне застосування онтологій може, з одного боку, істотно спростити і, з іншого боку, відкрити нові можливості в розробці додатків, що вирішують завдання автоматизованої обробки і доступу до даних. Далі будуть приведені кілька варіантів використання онтологій.
Наприклад, у роботі [6] автори використовують онтології для «витягу значимої інформації з web-сторінок при індексуванні». Передбачається підвищення якості інформаційного пошуку за рахунок видалення навігаційної частини з web-сторінок, поділу web-сторінок на змістовну і навігаційну частини. Дані методи засновані на виділенні однакових частин сторінок з одного сайту. В деякій мірі ця технологія частково закриває потребу в семантичному пошуку.
В роботі [7] для вирішення завдання підвищення ефективності пошуку в мережі Інтернет пропонується будувати портали знань, кожен з яких надає доступ до ресурсів мережі Інтернет певної тематики. Основу таких порталів знань складають онтології, що містять опис структури і типології відповідних мережевих ресурсів.
Цікаве застосування онтологій реалізовано в ДО РАН [8]. Фахівцями була побудована «медична» онтологія, що дозволяє робити висновки. Задавши симптоми, за допомогою онтологій можна вивести діагноз. Ще одне застосування описано в статті [9], "використання онтології для побудови інноваційних ланцюжків у системі підтримки інноваційної діяльності в регіоні". Система реалізується у вигляді Інтернет-порталу і включає в себе, з одного боку, інформаційну систему із засобами створення та інтеграції пов'язаних з інноваціями різнорідних інформаційних ресурсів, а з іншого, - розвинені засоби персонального участі в інноваційній діяльності фахівців різного профілю. Важливим компонентом, що забезпечує інтелектуалізацію таких робочих місць, є механізм, що підтримує інтерактивне побудова інноваційних ланцюжків. Створення ланцюжків виконується по автоматично генерується сценарієм, структура якого визначається структурою інноваційної ланцюжка, заданої в онтології інноваційної діяльності та видом інноваційного запиту.
Одна з найбільш важливих завдань, яке можна вирішити, використовуючи онтології - це семантичний пошук. В даний час проблема пошуку інформації у великих масивах порівнюється з проблемою Вавилонської вежі. Ця проблема ускладнюється ще й тим, що існуючі пошукові механізми здійснюють пошук інформації без урахування семантики слів, що входять до запиту, а також контексту, в якому вони використовуються.
Завдяки онтологій, з'явилася можливість створення семантичних мереж. Найважливішу роль в семантичній мережі повинні грати спеціальні програми - інтелектуальні агенти, у завдання яких входить робота з інформацією, представленою в семантичній мережі. Агенти за завданнями користувачів будуть знаходити джерела інформації, запитувати дані, зіставляти і перевіряти їх на відповідність критеріям пошуку, а потім видавати відповідь у зручній для користувачів формі (рис. 5 [10]).
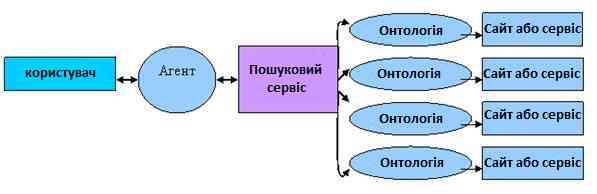
Рисунок 5 - Пошук потрібної інформації через пошуковий сервіс, який працює з семантичної мережею.
8. Методи автоматичної побудови онтологій
Інтелектуальні системи на основі онтологій показали на практиці свою ефективність, але побудова онтології вимагає експертних знань у досліджуваній предметній області і займає суттєвий обсяг часу. Проблемою автоматизації побудови онтологій займаються багато вчених. Нижче будуть розглянуті деякі з уже існуючих методів автоматичної побудови онтологій.
8.1 Представлення онтологій у вигляді кінцевого автомата
Будемо припускати, що онтології представляються у вигляді орграфа G = (V, E), де множина вершин V представляє безліч предметних областей, а множина ребер E - бінарне відношення між цими предметними областями [11]. З кожним таким Орграф G = (V, E) будемо асоціювати кінцевий (взагалі кажучи) частковий детермінований автомат без виходів A = (V, X = V, f, S, F), де V - множина станів, яке також служить вхідним алфавітом даного автомата, S - підмножина початкових станів, F - підмножина заключних станів (яке, зокрема, може бути порожнім), а функція переходів даного автомата визначається таким чином: f (u, v) = v тоді і тільки тоді, коли (u, v) E і не визначено в інших випадках.
Приклад: нехай дана онтологія представлена на рисунку 6.
Рисунок 6 - Онтологія О1
Автомат для наведеної вище онтології наведено на рисунку 7.

Рисунок 7 – Автомат для онтології О1
(анімація: 7 кадів, 7 циклів повторення, 142 Кб)
Представлення онтологій у вигляді кінцевого автомата без виходів дозволяє ввести операції на онтологіях. Операції на автоматах означають операції на регулярних мовах, які акцептуються цими автоматами [12].
Цю множину операцій (у разі потреби) можна розширювати в двох напрямках. Одним з таких напрямків є розширення операціями на графах (введення і видалення вершини і ребра, з'єднання графів, ізоморфного з'єднання декартового добутку і т. д.). Іншим напрямком є алгебра відносин. Оскільки кожна онтологія є представленням деякої сукупності відносин (зокрема: одного), то можна вводити операції реляційної алгебри.
Яке з можливих напрямків буде вибрано, залежить від практичних потреб використання онтологій.
8.2 Побудова семантичної карти ресурсу
Для автоматизації процесу побудови онтології пропонується використовувати текстовий зміст масиву Веб ресурсів описового характеру певної тематики.
Базовим є завдання розробки алгоритму автоматичної побудови семантичної карти веб ресурсу за допомогою аналізу його тексту. Семантична карта ресурсу – це відображення контенту Веб ресурсу в концептуалізацію його змісту, представленому у вигляді OWL онтології [13].
Семантична карта ресурсу будується на основі особливостей мови, які дозволяють витягати семантичні конструкції з тексту. Дослідження проводилися наступним чином:
- формувався набір пар «текст – конструкція мови OWL»;
- за набором виявлених пар «текст – OWL конструкція» виявлялися правила, що дозволяють автоматизувати процес відображення тексту у відповідну OWL конструкцію.
Семантична карта будується в два етапи, на першому будується формальна семантична OWL конструкція, на другому відбувається прив'язка отриманої конструкції до конкретної предметної області [14].
Формулюються правила, що використовують синтаксис мови. Правила синтаксичного рівня, виявляють семантику на основі принципів побудови словосполучень і речень. Правила формулюються, як конструкції з різних частин мови, частин речень, прийменників і союзів, а також конкретних слів. Додатково вводиться поняття предмета – сутності, про яку йдеться в пропозиції, предмет може складатися з декількох слів. Поняття предмета також використовується для формулювання правил.
Окремо виділяються правила, які самі не будують семантичну конструкцію, але визначають, яким чином (до яких словами) застосовувати правила, безпосередньо виявляють семантичні конструкції [15].
Один з підходів перетворення формальних семантичних конструкцій в конструкції, прив'язані до семантики конкретної предметної області – джерело знань зі структурою подібної таблиці 1.
Таблиця 1 – Структура джерела знань
| Слово | Характерна властивість |
| Abstract | ступінь деталізації |
| Editor | редагує |
Для того щоб прив'язати отриману семантичну модель до предметної області яка нас цікавить, використовується словник відповідної тематики. У підсумковій онтології фіксуються тільки ті семантичні конструкції, в яких беруть участь терміни зі словника предметної області. Словник може створюватися експертом або автоматично на основі статистичних методів класифікації.
8.3 Підхід на основі лексико-синтаксичних шаблонів
Даний підхід був запропонований в [16] і належить до групи методів автоматичної побудови онтологій, що використовують лінгвістичні засоби.
Прихильники підходу стверджують, що для побудови онтологій слід активно використовувати всі рівні аналізу природної мови: морфологію, синтаксис і семантику. Таким чином, для автоматичної побудови онтології автором використовується один з методів семантичного аналізу текстів природною мовою - лексико-синтаксичні шаблони.
Як метод семантичного аналізу лексико-синтаксичні шаблони давно використовуються у комп'ютерній лінгвістиці і являють собою характерні висловлювання й конструкції певних елементів мови [17]. Дана методика семантичного аналізу не є спеціалізованою на певну предметну область.
На основі лексико-синтаксичних шаблонів виділяються онтологічні конструкції [18]. Наприклад, з пропозиції «Студент - це людина, яка навчається в університеті», пропонована в [16] система виділить класи «студент», «людина» і ставлення «subclass-of» між ними.
В цілому відзначається, що лексико-синтаксичні шаблони як метод семантичного аналізу текстів природною мовою - в разі великого обсягу колекції шаблонів - є ефективним засобом для автоматичної побудови онтологій.
8.4. Автоматична побудова онтології по колекції текстових документів
В роботі [19] пропонується підхід до вирішення проблеми автоматичної побудови онтологій, переважно заснований на статистичних методах аналізу текстів природною мовою.
Побудова онтологій розділена на 3 етапи:
- попередня підготовка колекції;
- визначення класів онтології;
- визначення відносин «is-a» і «synonym-of», побудова ієрархії класів.
На якість побудови онтології впливає попередня підготовка тексту, зокрема, особливості колекції документів. Кластеризація документів по загальній тематиці може скоротити час, що витрачається на створення онтології. Для поліпшення одержуваної в результаті роботи системи онтології, пропонується провести попередню кластеризацію документів колекції таким чином, щоб в один кластер потрапляли тематично близькі документи, а подальшу роботу проводити окремо з кожним отриманим кластером.
На першому етапі побудови онтології потрібно виділити класи що входять до її складу. Слід зазначити, що поняття лінгвістичної онтології строго пов'язані з термінами. Таким чином, дана задача зводиться до визначення термінів розглянутої предметної області.
Алгоритми вилучення термінів з текстів природною мовою можна розділити на дві групи: статистичні та лінгвістичні. Однак перші володіють певною перевагою, оскільки їх використання не залежить від лінгвістичних особливостей конкретної мови. Підхід до вилучення термінів у розглянутому методі є переважно статистичним. Передбачається, що існуючі статистичні методи можуть показати кращі результати, якщо доповнити їх певними евристиками.
Попередньо в якості базових евристик пропонується використовувати наступні:
- ім'я класу містить хоча б один іменник;
- загальновживані слова мають більшу частотою зустрічальності, і приблизно рівної в документах з різних кластерів;
- кількість інформації терміна з декількох слів більше, ніж кількість інформації окремих слів.
Етап виділення відносин між класами створить найбільші труднощі. У зв'язку з чим, спочатку має сенс говорити про автоматичне тезаурус (таксономії з термінами). В якості базових відносин, що діють між термінами, визначимо відносини «is-a» і «synonym-of».
Для виділення відносини «is-a» можна скористатися кількісним підходом до інформації. Для цього було використано припущення, що кількість інформації терміна з декількох слів більше, ніж кількість інформації окремих слів, що входять до його складу.
Запропонований підхід дозволяє виділити тільки базові відносини, необхідні для побудови таксономії. Однак передбачається, що можливо його розширення для виділення інших відносин.
Висновки
У результаті досліджень було встановлено, що широке поширення отримали підходи, засновані на статистичному аналізі тексту на природній мові. У таких підходах онтологія будується по колекції текстових документів.
На якість побудови онтології впливає попередня підготовка тексту, зокрема, особливості колекції документів. Кластеризація документів по загальній тематиці може скоротити час, що витрачається на створення онтології.
В якості алгоритму кластеризації пропонується алгоритм LSA / LSI. Алгоритм LSA / LSI - це реалізація основних принципів факторного аналізу стосовно до безлічі документів. Даний метод кластеризації дозволяє успішно долати проблеми синонімії та омонімії, властиві текстового корпусу базуючись тільки на статистичній інформації про безліч документів / термінів.
Список літератури
1. Бажанова А. И. Исследование применения онтологических моделей для семантического поиска / А.И. Бажанова, Т.В. Мартыненко // Інформаційні управляючі системи та комп'ютерний моніторинг (ІУС та КМ – 2011) / Матеріали II науково-технічної конференції студентів, аспірантів та молодих вчених. – Донецьк, ДонНТУ – 2011, с. 244-248.
2. Болотова В.А. Инструментальные средства создания баз знаний на основе системы онтологий / автореферат к магистерской работе // http://masters.donntu.ru/2010/fknt/bolotova/diss/index.htm
3. Анохина В.С. в Автоматизацию извлечения знаний из Internet в форме онтологии для построения прикладных баз знаний / автореферат к магистерской работе // http://www.masters.donntu.ru/2005/fvti/anohina/diss/work.htm
4. Клещев А. С. Математические модели онтологий предметных областей. Часть 1. Существующие подходы к определению понятия «онтология» / А.С. Клещев, И.Л. Артемьева // Информационные процессы и системы. – 2001. – № 2 – С. 20 – 27.
5. Соловьев В.Д. Онтологии и тезаурусы: учеб. пособие / В.Д. Соловьев, Б.В. Добров, В.В. Иванов, Н.В. Лукашевич; Казанский гос. ун-т, МГУ им. М.В. Ломоносова Казань. – М.: Казань, 2006. – 157 с.
6. Агеев М.С. Извлечение значимой информации из web-страниц для индексирования / М.С. Агеев, И.В. Вершинников, Б.В. Добров // «Интернет-Математика-2005»: семинар в рамках Всеросс. науч. конф. RCDL'2005. – 2005. – С. 283 – 301.
7. Боровикова О.И. Организация порталов знаний на основе онтологий / О.И. Боровикова, Ю.А. Загорулько // Компьютерная лингвистика и интеллектуальные технологии: тр. междунар. конф. «Диалог 2002», Протвино, 6–11 июня 2002 г. – Т.2. – С. 76 – 82.
8. Сайт института информатики и процессов управления [электронный ресурс]: http://www.iacp.dvo.ru.
9. Булгаков С.В. Использование онтологий для построения инновационных цепочек в системе поддержки инновационной деятельности в регионе / С.В. Булгаков, Ю.А. Загорулько // Труды VI-й Междунар. конференции «Проблемы управления и моделирования в сложных системах». – Самара: Самарский Научный Центр РАН, 2004 – С. 328 – 333.
10. Голиков Н.В. Применение онтологий / Н.В. Голиков // VII Всерос. конф. молодых ученых по мате мат. моделированию и информационным технологиям, Красноярск, 1 – 3 ноября 2006 г. – С. 82.
11. Овдей О.М. Обзор инструментов инженерии онтологий / О.М. Овдей, Г.Ю. Проскудина // Журнал ЭБ. – 2004 – №4.
12. Бениаминов Е.М. Алгебраические методы в теории баз данных и представлении знаний / Е.М. Бениаминов. – М.: Научный мир, 2003 – 184 с.
13. Сайт Щербака С. С., кандидата технических наук по специальности «Системы и средства искусственного интеллекта»// URL:http://shcherbak.net.
14. Сообщество Semantic Web // http://www.w3.org/2001/sw.
15. Бевзов А.Н. Разработка методов автоматического индексирования текстов на естественном языке для информационно-поисковых систем / А.Н. Бевзов // Труды X Всеросс. науч. конф. Электронные библиотеки: перспективные методы и технологии, электронные коллекции – RCDL'2008 – С. 401 – 404.
16. Рабчевский Е. А. Автоматическое построение онтологий на основе лексико-синтаксических шаблонов для информационного поиска / Е.А. Рабчевский // Труды XI Всеросс. науч. конф. «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». – Петрозаводск, 2009.
17 Королев А.Н. Лингвистическое обеспечение информационно-поисковой системы Excalibur RetrievalWare: Аналитический аспект / А.Н. Королев // материалы конференции «Корпоративные Информационные Системы», 1999.
18. Анисимов А.В. Система обработки текстов на естественном языке / А.В. Анисимов, А.А. Марченко // Искусственный интеллект. – 2002. – № 4. – С. 157 – 163.
19. Мозжерина Е. С. Автоматическое построение онтологии по коллекции текстовых документов // Электронные библиотеки: Перспективные Методы и Технологии, Электронные коллекции – RCDL 2011 – Воронеж, 2011 – С. 293 – 298.
Важливе зауваження
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.