Automatic Ontology Construction for a National Term Bank
Автор: Bodil Nistrup Madsen, Hanne Erdman Thomsen, Jakob Halskov, Tine Lassen
Источник: Presenting terminology and knowledge engineering resources online p. 502-533, Nicolson & Bass, 2010
Keywords: ontology, knowledge extraction, knowledge structuring, data merging, knowledge dissemination, term bank.
Introduction
A prerequisite for continuous use and development of a national LSP in small countries like for example Denmark is free access to a term bank comprising domain knowledge in Danish and foreign languages. Domain specific knowledge goes beyond traditional dictionary information. In order to clarify and distinguish the meanings of domain specific concepts these must be described by means of characteristics and relations to other concepts, i.e. in the form of domain specific ontologies (concept systems). On the basis of these it is possible to develop consistent definitions that further understanding and correct use of terms. Terminology work that includes development of ontologies is a very labour-intensive task, and therefore most companies cannot afford this kind of work.
In our paper we present a project, the aim of which is to develop innovative and advanced methods for dynamic and automatic extraction of knowledge about concepts from texts and for automatic construction of ontologies. The project builds on and further develops the results of the CAOS project - Computer-Aided Ontology Structuring - which was carried out at Copenhagen Business School in the period 1998-2007. The project received funding by the Danish Research Council for the Humanities from 1998 to 2001.
In the project we will also develop methods for automatic merging of terminological data from various existing sources. In the process of bringing together data from different sources it is a big challenge to avoid double entries comprising the same concept in several entries, with varying formulation of the definitions and different translations. We are not aware of any existing term banks that have solved this problem. We will develop methods for automatic construction of ontologies on the basis of definitions from the various data sources and methods for automatic merging of entries based on the merging of these ontologies.
Furthermore we will develop methods for target group oriented knowledge dissemination. Most other term banks only offer restricted possibilities for setting up user specific search and presentation profiles.
Background
For a long period, many resources have been allocated to general language dictionaries, lexical databases and word nets. There is, however, a big need for domain specific knowledge within scientific, technical, economical and legal domains which can be made accessible by means of a Danish term bank. In 2008, the language committee of the Danish Government, issued a report, Sprog til tiden (‘Language on demand’), in which the importance of a freely accessible national term bank is emphasised. In December 2009 the Danish Parliament encouraged the Government to analyse advantages and involved resources in establishing a Danish term bank and a national terminology centre, which can further the development of LSP and ensure knowledge sharing between research institutions and society.
Central concepts related to terminological ontologies
As an introduction to the description of the current project we present some central concepts related to terminological ontologies. A terminological ontology is a domain-specific ontology; c.f. the categorisation of ontologies in (Guarino 1998). Terminological ontologies differ from other types of ontologies by comprising feature specifications and subdivision criteria.
The term “terminological ontology” is a synonym for “concept system”, which is used in terminology work, e.g. (ISO 704 2000).
Terminological ontologies as a basis for concept clarification
In figure 1 we present an example of an ontology for concepts related to disease prevention. This example is an extract from a morecomprehensive ontology from the health care sector, illustrating only type relations, i.e. the green lines connecting the concepts, often referred to as ISA-relations. In terminological ontologies we use the terms “superordinate concepts”, “subordinate concepts” and coordinate concepts” instead of “hypernyms”, “hyponyms” and “cohyponyms”. In figure 1, universal prevention is a subordinate concept of revention.
From figure 1 it is clear that universal prevention is characterised by the intended target group, while primary prevention is characterised by the phase in the clinical course (even before there is a patient). Without this information, one might think that those two terms were synonymous, but an analysis of their characteristics, which are given below the concepts (e.g. [TARGET GROUP: population]), makes it clear that this is not the case.
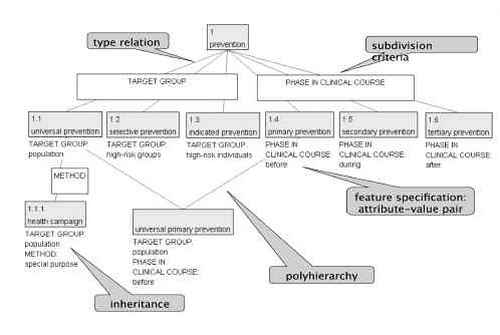
Figure 1. Extract of and ontology for prevention
The characteristics of the concepts are presented as feature specifications in the form of attribute value pairs, e.g. [TARGET GROUP: population], cf. (Carpenter 1992). On the basis of these feature specifications, subdivision criteria are introduced (white boxes with text in capital letters) which illustrate that the three coordinate concepts 1.1- 1.3 differ with respect to target group, while the three concepts 1.4-1.6 differ with respect to phase in clinical course. The subdivision criteria help the user to understand the meaning of the concepts, give a good overview and help the terminologist in writing consistent definitions. The definition of a concept is given by means of the position in the ontology and the characteristics. The ontology in figure 1 has been created using the concept modelling module i-Model of the terminology and knowledge management system i-Term ®, developed by the DANTERM Centre (the terminology centre) at the Copenhagen Business School. The concept modelling in i-Model is based on user input, and has no automatic consistency checking facilities.
Terminological ontologies implemented in CAOS
The principles of the terminological ontologies presented here have been developed in the research and development project CAOS - Computer- Aided Ontology Structuring - whose aim was to develop a computer system for semi-automatic construction of ontologies, cf. (cf. Madsen et al. 2004b; Madsen et al. 2005). CAOS was carried out by Bodil Nistrup Madsen, Hanne Erdman Thomsen and Carl Vikner at CBS, Dept. of International Language Studies and Computational Linguistics. The prototype includes an interactive graphical user interface which allows the user to build terminological ontologies on the basis of information entered while reading domain-specific texts. CAOS warns the user about inconsistencies and errors and informs users whenever they insert information that conflicts with the principles and constraints of the system.
In the CAOS prototype, facilities for semi-automatic checking of inconsistencies were developed. In the new project we will further develop facilities for automatic consistency checking, automatic changes to ontologies, automatic positioning of concepts and dynamic updating of the ontologies on the basis of the enriched information that they contain. To our knowledge no other systems have such capabilities.
In Figure 2 we present a part of the ontology from Figure 1, which is here constructed with the CAOS prototype.
Diagrams in CAOS are rendered in a UML-based notation. The type relations (ISA-relations) are represented by means of lines with arrow heads connecting the concepts. All types of concept relations can be used in CAOS. The system offers a set of concept relations organised in a taxonomy, cf. (cf. cf. (Madsen et al. 2002). It is also possible for the user to introduce user-defined relations.
The backbone of terminological concept modelling in CAOS is constituted by characteristics modelled by formal feature specifications, i.e. attribute-value pairs, as for example [TARGET GROUP: population]. This approach to modelling characteristics was proposed in (Madsen 1998), (Thomsen 1998) and (Thomsen 1999, cf. also (Carpenter 1992). The use of feature specifications is subject to principles and constraints described in detail in (Madsen et al. 2004b; Madsen et al. 2005). Subordinate concepts inherit the characteristics of superordinate concepts, e.g. health campaign inherits the characteristic: [TARGET GROUP: population] from the concept universal prevention.
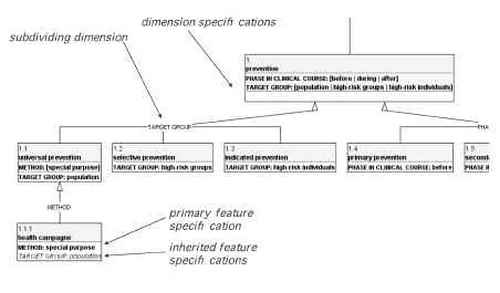
Figure 2. Extract of an ontology for prevention modelled in CAOS
Polyhierarchy can be introduced, i.e. one concept may be related to two or more) superordinate concepts. In figure 1 the concept universal primary prevention is an example of this. A very important principle in such cases is that the superordinate concepts of a concept inheriting characteristics from two (or more) concepts must always belong to two (or more) different subdivision criteria otherwise the ontology must be changed.
We have formalised subdivision criteria that have been used for many years in terminology work, by introducing dimensions and dimension specifications which form the basis for the facilities for semi-automatic construction of ontologies and for consistency checking. A dimension of a concept is an attribute occurring in a (non-inherited) feature specification of one or more of its subordinate concepts, i.e. an attribute whose possible values allow a distinction between some of the sub-concepts of the concept in question. A dimension specification consists of a dimension and the values associated with the corresponding attribute in the feature specifications of the subordinate concepts: DIMENSION: [value1| value2| ...], e.g.”TARGET GROUP: [high-risk groups|high risk individuals]” in Figure 2.
The principles for constructing ontologies mentioned here are unique. No other ontology projects or systems make use of these principles that result in very precise descriptions of domain specific concepts. In the next two sections we describe our new project in more detail.
Terminological ontologies versus word nets and other types of ontologies
Lexical ontologies for general language, so called wordnets, which allow the user to navigate in a network of concepts, are being developed in many countries. A well known example of an electronic network is Princeton WordNet (http://wordnet.princeton.edu/), for which several graphical browsers have been developed. In Denmark a Danish wordnet, DanNet (http://www.wordnet.dk/), has been under development since 2005. DanNet is based on the Danish dictionary, Den Danske Ordbog (http://ordnet.dk/ddo).
Ontologies covering specific domains are also developed, but they normally differ from terminological ontologies as defined in our work. Examples are UMLS, Unified Medical Language System (http://www.nlm.nih.gov/research/umls/) and SNOMED CT (http://www.ihtsdo.org/snomed-ct/), Systematized Nomenclature of Medicine-Clinical Terms, which has also been translated into Danish. In the period 2003-2006 the Aarhus School of Business, Aarhus University, worked on two projects: MEDVID and MEDTERM. MEDVID (http://www.asb.dk/article.aspx?pid=568#medvid) focused on knowledge sharing, dissemination and communication within the medico-technical and the medical scientific area. The project was a cooperation between companies, research centres and translation companies exchanging knowledge on language use, translation and communication in the medical area. The intention of the project MEDTERM was the development of a multilinguistic, internet-based dictionary supporting knowledge sharing within the medical field (http://www.asb.dk/article.aspx?pid=568#medterm).
These data collections have all been build manually, which is a very labour-intensive task, and to our knowledge methods for dynamic updating have not been developed.