Метод
автоматизированного извлечения знаний из слабоструктурированных источников и
его применение для создания кис
Авторы: Березкин Д.В.
Источник: http://www.raai.org/resurs/papers/kolomna2009/doklad/Berezkin.doc
1. ВВЕДЕНИЕ
В настоящее время в связи с постоянным ростом информации глобальной сети
Интернет необходимо развитие технологий, позволяющих использовать ее для
решения различных производственных задач предприятий и организаций. Потребность
в этом испытывают все пользователи, начиная от простых людей и кончая
специалистами крупных компаний, отвечающими за формирование информационных
источников. В связи с этим подавляющее большинство корпоративных информационных
систем (КИС) предусматривают подключение своих пользователей к Интернету с
соблюдением различных механизмов безопасности. Современные КИС в большинстве
случаев строятся с использованием WEB-технологий и представляют собой Интранет-системы. Для больших компаний количество
информации, распределенной на различных разнородных источниках во внутренней
сети, настолько велико, что здесь возникают проблемы, схожие с теми, которые
испытывает Интернет.
Разнообразная слабоструктурированная информация в сети Интернет не может
быть успешно использована на практике при отсутствии эффективного доступа. Так,
по оценкам экспертов, около 79% журналистов обращаются к Интернет в поисках
новостей, и лишь 20% из них находят ту информацию, которая им необходима [1].
Несмотря на выполняемые большие работы по совершенствованию методов поиска,
используемых поисковыми машинами, проблему вряд ли можно решить только таким
путем. И даже если представить такую ситуацию, что все существующие проблемы
поиска в их традиционной постановке будут решены, то большинство пользователей
по-прежнему останется недовольно, так как извлекаемая ими информация будет релевантна поисковому запросу, но не их насущным
потребностям.
Необходимо отметить направление, которое пытается преодолеть это
противоречие. Оно активно развивается консорциумом W3C и получило название Semantic Web [2]. По замыслу его
создателей реализация этой парадигмы в Интернете позволит информационным
системам в какой-то степени понимать содержание информации и выступать
«интеллектуальными посредниками», способными самостоятельно манипулировать ею
по заданию человека. В результате должен появиться новый Интернет, получивший
рабочее название Web
2. Осуществятся ли эти замыслы, покажет время, однако, уже многие технологии Semantic Web успешно применяются в
современных Интернет/Интранет системах. Например,
практически все новостные сайты поддерживают формат RSS (Really Simple Syndication, Rich
Site Summary, RDF Site Summary) [3], специально
предназначенный для легкого и быстрого обмена содержанием Web-сайтов.
Он является специальной формой RDF (Resource Description Framework) [4] представления
метаданных, реализованной в направлении Semantic Web для новостной
информации.
Поиск, фильтрация, сбор информации в Интернете для
использования в организациях в рамках КИС сопряжены с необходимостью тратить на
это большое время и использовать высококвалифицированный персонал. Необходимо
отметить, что информационный поток, «потребляемый» организацией из Интернета,
носит, как правило, выраженную предметную окраску, характеризуемую областью
интересов данной организации, а следовательно, в большинстве случаев, может
быть хорошо структурирован. В большинстве случаев специалисты, занимающиеся
сбором и анализом новостной информации из Интернет-источников, имеют достаточно
четкое представление о том, какая именно информация и из каких источников их
интересует, какой набор метаданных должен сопровождать ту или иную новость, в
какой тематический раздел КИС ее следует поместить. Это обстоятельство является
предпосылкой для создания модели знания о предметной области и открывает
возможность для автоматизации извлечения этих знаний.
2. СОВРЕМЕННЫЕ ТЕНДЕНЦИИ
В ОБЛАСТИ АВТОМАТИЗАЦИИ ПРОЦЕССА СБОРА ИНФОРМАЦИИ ИЗ ИНТЕРНЕТ-ИСТОЧНИКОВ
Решение перечисленных задач возможно путем создания автоматических и
автоматизированных систем сбора, фильтрации и анализа информации, так
называемых своеобразных «интеллектуальных посредников» между пользователем или
КИС организации и Интернетом. Подобная система выполняет всю «черновую» работу
по сбору и селекции информации из Сети и создает документальную базу данных в
определенной предметной области. Загрузка информации в базу данных
сопровождается ее классификацией и частичной структуризацией. Для последующей информационно-аналитической
работы конечному пользователю КИС предоставляются эффективные средства
навигации и поиска информации в созданной документальной базе данных.
Для более эффективного манипулирования Web данными, некоторые исследователи
обратились к идеям, взятым из области баз данных. Традиционные базы данных
работают с регулярной структурированной информацией и поэтому технологии баз
данных нельзя непосредственно применить к Web. Тем не менее, в Web доступно много
информации, которая обладает некоторой определенной структурой (например,
электронный каталог товаров, новости электронных СМИ и т.д.) [5], и возможность
использования структурированных запросов для таких ресурсов могла бы быть очень
полезной. Эти соображения стимулируют исследования в области организации
доступа к такой информации, которая обычно называется слабоструктурированной.
Традиционный подход состоит в извлечении данных из Web и отображении полученных данных
в некоторый промежуточный формат, а затем - в выполнении
структурированных запросов уже к этим извлеченным данным. Подход реализуется на
основе механизма посредников (wrappers) - программ, которые идентифицируют
искомую информацию в исходном документе и отображают ее в некоторый
промежуточный формат, например, XML (eXtensible Markup Language, Расширяемый язык
разметки).
Разработка и поддержка посредников вручную очень трудоемкий процесс (в
частности, из-за разнородности и нерегулярности обрабатываемой информации).
Поэтому различными коллективами специалистов многих стран ведется работа над
средствами автоматизации этой задачи.
Для этой цели предложен ряд языков описания программ-посредников, которые
позволяют значительно снизить объем программного кода, разрабатываемого
вручную.
Дальнейшая автоматизация ведется в направлении разработки алгоритмов,
которые автоматически генерируют программы-посредники. Для этого проводится
анализ набора документов, из которого предстоит извлекать информацию, и, в ряде
случаев, готовятся обучающие примеры. Задача извлечения является сложной, поскольку
требуется извлечь не только вид схемы данных, но также и связанную с ним
семантическую информацию (например, тип конкретного элемента данных) [5].
Достижение полной автоматизации в общем случае маловероятно, и речь может идти
о создании автоматизированных систем извлечения информации из Интернета.
Одна из основных трудностей, с которой сталкиваются разработчики подобных
систем, - это нерегулярность обрабатываемой информации. В частности, для
автоматической генерации извлекающего информацию посредника требуется
подготовить набор документов, из которых посредник и будет извлекать
информацию. При этом необходимо, чтобы набор был относительно регулярным, т.е.
страницы в этом наборе должны иметь схожую структуру тех разделов
(информационных блоков), которая содержит извлекаемую информацию. До сих пор
существование этого набора предполагалось априори, вопросы его создания не
рассматривались, что создавало определенные трудности при практическом
использовании подобных систем, поэтому в настоящей работе был проведен
предварительный анализ некоторых новостных сайтов, который позволил уточнить
алгоритмы извлечения.
3. АНАЛИЗ СПОСОБОВ
ПОСТРОЕНИЯ (ВЕРСТКИ) WEB-САЙТОВ
Задача извлечения информации из WEB была бы гораздо проще, если бы
существовал единый стандарт построения сайтов. Но, к сожалению, такие стандарты
отсутствуют – все многообразие сайтов и Web-страниц
объясняется фантазией веб-дизайнеров. Единственное, что их объединяет, - это язык HTML, который
определяет внешний вид Интернет-ресурсов, но не может описать его содержание.
Несмотря на отсутствие между различными Интернет-источниками хоть
какого-либо визуального сходства, все же есть несколько объединяющих их
тенденций. Был проанализирован ряд новостных сайтов. Выбор их продиктован тем,
что в настоящее время именно они являются Интернет-источниками для
информационной системы «Обзор СМИ» Совета Федерации Федерального Собрания
Российской Федерации, разработанной НПЦ «ИНТЕЛТЕК ПЛЮС» (www.inteltec.ru). Данная система осуществляет
автоматический сбор новостной информации и ее представление в Интранет-сети Совета Федерации [6] и является частью
информационно-коммуникационной системы (ИКС) Совета Федерации. Необходимость
практической реализации в этой системе методов автоматизации извлечения
информации из Интернета являлась одной из главных практических задач, решению
которой посвящен доклад.
Выполненный анализ показал следующее.
Основная масса страниц, на которых представлены новости, имеют
«двухуровневое представление». Под двухуровневым представлением мы понимаем
структуру сайта, когда существует заглавная страница, содержащая анонсы или
заголовки новостных сообщений, и набор страниц, содержащих непосредственно саму
новость. Однако не стоит исключать и такие источники, которые содержат
необходимые сообщения на первой странице (отсутствуют страницы второго уровня).
Заглавных страниц может быть несколько – по одной для каждого раздела. Из
соображений единого дизайна, эти страницы, как правило, мало чем отличатся друг
от друга.
Наряду с заглавными страницами разделов, на сайте может также находиться
лента новостей, содержащая все новости к текущему часу. Наличие подобной
страницы первого уровня сильно облегчает задачу сбора, так как отпадает
необходимость в просмотре страниц. Однако такие ленты не обязательно содержат
все новости сайта. Например, они могут включать новости только за
последние несколько часов, что неприемлемо в случае опросов с интервалом,
превышающим этот промежуток времени.
Страница второго уровня содержит блок с интересующим нас
сообщением, плюс некоторое обрамление. Этот блок содержит некоторый набор
реквизитов новостного сообщения: заголовок сообщения, дату и/или время
публикации, имя автора и непосредственно текст новости. У конкретных источников
некоторых полей может не быть, или вместо них могут появиться другие. Также
блок содержит некоторый «информационный» мусор, т.е. данные, не имеющие
отношения к конкретной извлекаемой новости или ее реквизитам, который при
извлечении сообщения надо постараться отфильтровать.
Выполненный анализ основных новостных сайтов российского Интернета показал,
что подавляющее большинство из них использует табличную структуру для
отображения информации, наряду с двухуровневым представлением.
Таким образом можно сделать вывод о том, что новостные источники, несмотря
на их внешнюю непохожесть, все же обладают некоторой определенной структурой,
которую распознаватели информации должны научиться выявлять.
4. ПОДХОДЫ К ИЗВЛЕЧЕНИЮ
ДАННЫХ И ЗНАНИЙ ИЗ WEB
Активные исследования в области работы со слабоструктурированной
информацией привели к появлению большого количества альтернативных
инструментов, используемых для создания программ-посредников [7]. Предлагаемые
подходы в исследовании проблемы извлечения данных из Web
используют методы, заимствованные из таких областей как: обработка данных на
естественном языке, языки и грамматики, машинное самообучение, информационный
поиск, базы данных и онтология. В результате, они предоставляют самые различные
возможности, поэтому строгих критериев для их сравнения пока не выработано.
Основной задачей извлечения данных из Web
является: получение определенных фрагментов информации (поля) из указанных HTML
документов в указанное время.
Она близка к задаче автоматической кластеризации и состоит в поиске
разложения множества HTML-документов D {d1 ,..., dn}
на классы C1 ,...,Ck ,
которые содержат документы со схожей структурой.
Задание отображения прикладных объектов в точки многомерного пространства
состоит в определении базиса признаков {ei},
формирующих многомерное пространство, и метода разложения документа по этому
базису (т.е. вычисления координат {wi}).
Для определения координат документа {wi} в
пространстве базисных признаков {ei} используются
различные подходы. В частности, авторами работы [8] предлагается использовать
подход, популярный при вычислении весов термов в поисковых системах,
использующих векторную модель представления документов. При этом: wi=tfi/(logN/ki), где tfi - это частота
встречаемости i-го признака, ki - количество документов, в которых он встречается, а N -
общее количество рассматриваемых документов. Для оценки качества кластеризации
предлагается использовать энтропийную меру. На
основании вычисления общей энтропии и энтропии кластера авторы работы [8]
вводят критерий «хорошего» кластера, который может быть обработан
автоматически. Затем вводится еще одна мера, отражающая возможность построения
многоуровневой иерархии кластеров.
Существует целый ряд других подходов к формализации задачи извлечения
слабоструктурированной информации из Интернет-источников. В них используется
логика ранжированных или неранжированных деревьев
первого или более высокого порядка (как правило, второго порядка) [9, 10], а
также логика на графах [11]. Эти методы относятся к перспективному, активно
развивающемуся направлению современной математической логики, которое в
настоящее время активно формируется. Эффективная реализация таких методов
требует разработки новых способов представления и хранения документов в
виде древовидных (а в самом общем случае – графовых)
структур, а также языков запросов к ним, что требует больших усилий на этапе
разработки. С точки зрения простоты реализации было решено использовать
стандартные средства представления документов и языки запросов, поэтому далее
эта группа методов не рассматривается.
Для систематизации существующих подходов можно использовать классификацию,
предложенную в работе [8], которая выделяет следующие группы методов и средств
их реализации: декларативные языки; использование HTML структуры; системы,
осуществляющие обработку данных на естественном языке; системы на основе
индуктивных логических рассуждений; средства моделирования; средства,
основанные на онтологии. Эта классификация не строгая и некоторые инструменты
могут относиться сразу к нескольким группам.
Исходя из выполненного анализа существующих методов извлечения, можно
сделать вывод, что страницы HTML едва ли могут быть обработаны посредством
обычного грамматического разбора, ввиду ряда причин. Основные из них
заключаются в том, что разработчики HTML-страниц пользуются неограниченной
свободой при недостатке средств синтаксического контроля. Следствием этого
является разнообразие способов структурирования данных в странице, так что два
логически однородных элемента данных могут быть форматированы совершенно
различным образом, либо даже содержать ошибки, т.е. части кода могут не вполне
соответствовать грамматике HTML (отсутствие закрывающих тэгов является
распространенным примером). Поэтому мы в первую очередь ориентировались на
подходы, использующие информацию об HTML-разметке.
5. МЕТОД ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ СЛАБОСТРУКТУРИРОВАННЫХ
ИСТОЧНИКОВ, ОСНОВАННЫЙ НА XML
С учетом анализа существующих подходов и методов извлечения информации из
Интернет-источников и проведенных экспериментальных исследований ряда новостных
сайтов, был выбран подход, основанный на информации об HTML-разметке,
который использует в качестве этой информации дерево, отображающее
структуру Web-страницы. Это позволяет использовать
преимущества иерархической структуры тэгов.
Для того, чтобы иметь возможность характеризовать структурные свойства
документа, мы рассматриваем его в виде дерева разбора согласно стандартной
объектной модели представления документов DOM (Document
Object Model - DOM) .
Корнем DOM-дерева для HTML страницы является тэг «html».
Внутренние узлы дерева соответствуют другим, используемым в документе
HTML-тэгам, дуги между которыми характеризуют вложенность их использования.
Листья дерева могут быть не только тэгами, но также и представлять текстовые
литералы.
Далее возникают две проблемы, которые нужно решить: 1) отсутствует
стандартный язык навигации по HTML, 2) отсутствует какая-либо стандартная
структура HTML-документов. Поэтому предполагается, что значительно проще извлекать
информацию из HTML-документов, если предварительно привести этот документ
к некоторой известной нам структуре, и после чего извлекать информацию уже из
нее [12-14]. Такой структурой будет XML-представление документа, к которому
будет преобразовываться исходный HTML-документ.
Необходимо также отметить, что HTML является основным, но не единственным
форматом представления данных в сети Интернет. Поэтому предлагается следующий
подход: если источником является HTML-страница, то она преобразуется в формат
XML, если это файл XML (например, RSS), то соответственно преобразование
опускается; затем из XML-документа извлекаются необходимые данные и
преобразуются к определенному формату (им может быть также XML). На рисунке 1
дано схематичное представление предлагаемого метода извлечения
информации, основанного на XML.
Применение данного метода позволяет решить следующие задачи: 1) обеспечение
доступа к источнику данных; 2) получение информации из HTML-страницы; 3)
структурирование информации (правка неверно сформированного HTML); 4)
сохранение информации в формате XML; 5) опрос XML-документа для извлечения
нужных пользователю данных.
Ключевым моментом в предложенном методе является преобразование
HTML-документа, имеющего слабовыраженную структуру, в формат XML.
Дополнительная сложность на этом этапе возникает из-за того, что многие
страницы Web-сайтов имеют дефектный формат, хотя
целый ряд браузеров, допускают такой формат и могут его обработать.
Для того, чтобы получить доступ к конкретной части XML-документа возможно
использование специального языка адресации частей XML-документа – Xpath . Запрос на XPath не
ограничивается обработкой элементов. Можно указать различные виды узлов,
включая атрибуты, текст, команды обработки и комментарии, или оставить его настраиваемым
с селектором для любого типа вершины.
С помощью Xpath чрезвычайно упрощается задача
поиска и описание типов обрабатываемых вершин в документе. Существенно
сокращается объем создаваемой программы, поскольку остается только обойти
дерево, чтобы проверить различные части. Поскольку Xpath,
по сути, представляет стандарт, он может применяться в самых различных модулях.

Рис. 1. Схематичное представление метода извлечения
Важным этапом извлечения является однозначная идентификация нужной
информации в слабоструктурированном источнике и включение ее в результирующий
документ (например, XML-документ, структура которого строго определена). Обычно
для этого используют информацию об абсолютном пути к нужным элементам или
привязку к их содержанию при помощи правил на языке регулярных выражений, а
также комбинацию этих способов [13-14]. Оба подхода могут быть успешными для
некоторых видов источников, но мало подходят для сбора новостной информации,
т.к. невозможно привязаться к контексту новости, а структура новостных блоков
на сайте также подвержена изменениям (меняется количество новостных статей,
некоторые блоки в какой-то момент могут быть пустыми и т.д.). При этом
комбинация подходов, также будет неэффективной. Поэтому в предлагаемом методе
применялись более сложные правила идентификации, использующие, наряду с
традиционными способами, привязку к типам элементов, определяемых их
атрибутами и учитывающие их разметку. На основании этих правил строятся
фильтры, которые связываются с конкретным источником.
6.
РЕАЛИЗАЦИЯ МЕТОДА ИЗВЛЕЧЕНИЯ
Один из вариантов реализации автоматизированной системы извлечения
информации заключается в написании отдельных посредников для каждого источника
информации. Именно такой вариант был первоначально реализован и внедрен в
Аппарате Совета Федерации Федерального Собрания Российской Федерации для сбора
новостной информации из разнородных источников в информационной системе «Обзор
СМИ», разработанной НПЦ «ИНТЕЛТЕК ПЛЮС» [15]. Примерно такие же принципы
заложены в аналогичных системах, используемых некоторыми органами
государственной власти России, разработанных другими компаниями. При таком
способе реализации для каждого новостного источника приходится создавать
отдельный скрипт-посредник, который обеспечивает сбор новостей.
В качестве дальнейшего развития системы извлечения было предложено создание
универсальной программы (скрипта-посредника), который мог бы обрабатывать любой
новостной источник.
Для решения данной задачи предполагается следующее:
1)
Разделить систему на настроечную и выполняемую части. При этом создается
отдельный XML-файл, описывающий как структуру новостных данных, так и схему их
верстки, характерные для каждого источника (заголовок новости, аннотация,
дата, время и др.) и единая программа-скрипт, использующая при сборе новостей
данный описатель.
2)
Создать визуальный редактор, который позволит специалисту без специальной
подготовки (не программисту), отметить на сайте необходимый ему блок информации
и реквизиты, содержащиеся в этом блоке. Основным результатом работы этого
визуального редактора является управление настроечным файлом.
Можно выделить основные этапы настройки системы извлечения на новый
Интернет-источник:
·
в редакторе после загрузки HTML-страницы источника новостей пользователь
выделяет новостные сообщения и определяет их реквизиты: заголовок, аннотацию,
дату, время;
·
в результате разметки формируется путь к каждому из реквизитов новости, а
также, составленный на языке обработки XML-данных – XPath.
При этом результат разметки визуально можно наблюдать в редакторе (изменяется
цвет фона области сайта, содержащий новостные сообщения);
·
данные заносятся в настроечный файл. Пользователь может проверить правильность
настроек;
·
создается (автоматически после выполнения пользователем соответствующей команды
в редакторе) универсальный скрипт, который на основании настроечного файла
соберет новости и загрузит их в указанное место.
Таким образом, создается один XML-файл, который описывает настройки каждого
источника новостей. При изменении верстки какого-либо источника пользователю не
составит труда быстро внести в него изменения.
Ниже приведена функциональная схема системы извлечения данных (рисунок 2).
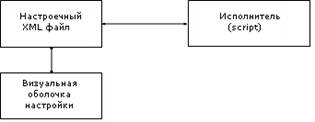
Рис. 2. Функциональная схема системы извлечения данных
Необходимо добавить, что данный подход, на наш взгляд, представляет собой
универсальное решение задачи извлечения информации из слабоструктурированных
источников и в дальнейшем сможет обрабатывать любой источник, в котором человек
при первоначальной настройке сможет выделить блоки и некоторый набор
обязательных и необязательных реквизитов.
Предполагается, что таким же способом можно собирать любую информацию с
WWW-ресурсов, меняться будет XML-файл и его описатель (DTD или XSD).
Предложенный подход был реализован в прототипе новой версии ранее
упомянутой информационной системы «Обзор СМИ», который включает в свой состав
средства извлечения данных и знаний из структурно разнородных источников,
созданные на основе изложенного подхода. В прототипе реализованы несколько
алгоритмов извлечения, выбор которых осуществляется пользователем исходя из того,
насколько строго структурирован информационный ресурс. Имеется возможность
выбрать строгий вариант извлечения, привязав извлекаемые реквизиты к
определенному месту его положения на странице, так и сделать правила извлечения
нечеткими, чтобы обеспечить извлечение нужной информации в случае небольших
изменений в верстке страниц.
Система выполняет автоматическое регулярное считывание новостей из
конкретных Интернет-источников и размещение этих новостей в локальное хранилище
информации. В качестве локального хранилища информации может использоваться
файловая система или база данных. В случае использования базы данных в качестве
локального хранилища информации, система выполняет систематизацию новостей и
предоставляет пользователям средства для контроля и коррекции проведенной
систематизации, а также средства по формированию обзоров новостных сообщений.
Данные проектируемой системы представляют собой XML-карточки, содержащие
основные реквизиты документа, документы с текстом сообщения, служебные файлы
описателя и журнала событий.
Перед началом работы система должна быть настроена администратором.
Администратор с помощью подсистемы визуальной разметки производит настройку на
конкретные источники информации. В результате действий администратора
происходит создание XML-файла описателя.
Подсистема первичной обработки приводит полученную информацию к формату,
необходимому для загрузки в базу. В процессе обработки формируется XML-файл,
содержащий информацию о реквизитах новости, и файл с текстом новости в формате html или doc. Если текст новости
представлен в виде архива (zip, rar,
arj, tar), то файл
предварительно разархивируется и проверяется на соответствие допустимым
форматам: html или doc. Для
обеспечения безопасности, данная подсистема имеет возможность пересылки данных
через FTP-сервер из незащищенной сети в защищенную. Далее следует загрузка
данных в базу. На этом заканчивается первичная обработка и управление
передается ИПС «ODB-text».
Процесс сбора данных осуществляется модулем сбора данных в автономном
режиме по установленному расписанию. Для этого используется описатель,
созданный администратором на этапе настройки. Данные о считанных документах и
результате выполнения процесса фиксируются в журнале событий. В основу
алгоритма работы модуля сбора данных положена двухуровневая схема доступа к
данным.
При разработке прототипа системы использовались языки Jscript
для реализации визуальной разметки источника и создания описателя, а также Perl для выполнения автоматического извлечения данных и их
первичной обработки.
7. ПРОВЕДЕНИЕ
ЭКСПЕРИМЕНТОВ И АНАЛИЗ ИХ РЕЗУЛЬТАТОВ
Эксперимент по считыванию данных проводился на ПК, имеющим следующую
конфигурацию: ЦП – IntelPentium III 450 МГц, ОЗУ –
768 МБ, ОС – MSWindows XP, 2000. Описатель был
сформирован заранее с помощью визуального редактора настройки на источники.
Данные о времени и объемах обработанной информации для различных источников
приведены в таблице 1.
Таблица 1. Результаты
проведенного эксперимента
|
Источник |
Объем
считанных данных |
Количество
XML карточек/ количество
текстов |
Время
формирования карточек и документов с текстом |
|
|
Утро (www.utro.ru) |
799 кБ |
55/41 |
5 мин |
|
|
Газета (www.gazeta.ru) |
937 кБ |
40/40 |
1 мин 11с |
|
|
Известия
(www.izvestia.ru) |
792 кБ |
40/40 |
3 мин 22с |
|
|
РосБизнесКонсалтинг (www.rbc.ru) |
442 кБ |
28/28 |
3 мин 53с |
|
|
Российский
налоговый курьер (www.rnk.ru) |
351 кБ |
10/10 |
20 с |
|
|
СМИ (www.smi.ru) |
351 кБ |
16/16 |
1 мин 26 с |
|
|
Прайм-тасс (www.prime-tass.ru) |
2 621 кБ |
100/100 |
9 мин 8с |
|
|
Чиркунов (tchirkounov.ru) |
995 кБ |
37/37 |
1 мин 44с |
|
|
КоммерсантЪ (www.kommersant.ru) |
325кБ |
13/12 |
3 мин 12с |
|
|
АКДИ (www.akdi.ru) |
40кБ |
15/15 |
13 с |
|
Проведенный эксперимент выявил ряд проблем автоматизации процесса сбора,
которые необходимо учитывать при проектировании средств извлечения знаний из
слабоструктурированных Интернет-источников для КИС. Их можно разделить на два
класса. К первому из них относятся трудности, связанные с «природой»
информационных ресурсов: разнородность информационных ресурсов и задача
унифицированного представления контента Web-ресурсов;
динамичность изменения содержимого информационных ресурсов; различное
«качество» и уровень «полезности» информации; доступность» информационных
ресурсов.
Ко второму классу относятся проблемы, касающиеся нагрузки на различные
элементы, участвующие во взаимодействии: минимизация нагрузки на каналы связи;
оптимизация нагрузки на модули сбора и накопления информации, а также всех
компонентов системы извлечения (алгоритмов, структур данных и т.д.).
Проведенные эксперименты с прототипом системы показали применимость на
практике предложенного метода извлечения. Выявленные при этом проблемы
планируется учесть при разработке промышленной версии системы. Дальнейшим
направлением развития метода является использование технологий семантического
анализа на основе Semantic Web.
Также планируется использовать инструменты, поддерживающие извлечение
информации из текстов на естественном языке, опирающиеся на различные методы
компьютерной лингвистики и методы машинного обучения [16], для дальнейшего
анализа и обработки извлеченных фрагментов.
Литература
1.
Ландэ Д.В. Поиск знаний в Internet. – М.:Диалектика,
2005.
2.
W3C Semantic Web Activity.
– http://www.w3.org/2001/sw/
3.
Спецификация RSS, 2000. – http://purl.org/rss/1.0
4.
Resource Description Framework (RDF) – http://www.w3.org/RDF/
5.
Методы и средства извлечения слабоструктурированных
схем из документов
в HTML и конвертирования HTML документов
в их XML представление. http://synthesis.ipi.ac.ru/synthesis/projects/XMLBIS/html2xml_html
6.
Голубев С.А., Толчеев Ю.К.,
Шаров Ю.Л. Опыт внедрения и использования информационно-поисковой системы
ODB-Text в Совете Федерации
Федерального Собрания РФ //
Современные технологии в управлении и образовании - новые возможности и перспективы использования. Сборник научных трудов. ФГУП НИИ "Восход",
МИРЭА. - М., 2001. – С. 58 – 61.
7.
A.H.F. Laender, B. A. Ribeiro-Neto,
Juliana S.Teixeria. A brief
survey of web data extraction tools. ACM SIGMOD Record 31(2),
pp 84-93. 2002.
8.
И. Некрестьянов, Е. Павлова.
Обнаружение структурного подобия HTML-документов. СПГУ,
2002. – С. 38 – 54. – http://meta.math.spbu.ru
9.
V. Crescenzi, G. Mecca. Automatic Information Extraction from Large Websites// Journal of
the ACM, Vol. 51, No. 5,
September 2004. – pp 731 – 779.
10.
G. Gottlob, C. Koch. Logic-based Web
Information Extraction // SIGMOD Record,
Vol. 33, No. 2, June 2004. – pp 87 – 94], [Logical definability and query languages over ranked and
unranked trees/ M.
Benedikt, L. Libkin and F.
Neven// ACM Transactions on Computational Logic (TOCL), 8(2) (2007), 1-62.
11.
B. Courcelle. the monadic second-order logic of graphs xvi: canonical graph decompositions//Logical Methods
in Computer Science, Vol. 2 (2:2) 2006, pp. 1–46. [Электронный
ресурс] – Режим доступа: www.lmcs-online.org,
свободный.
12.
J. Myllymaki. Effective Web
data extraction with standard XML technologies. in 10 International Word Wide Web Conference
(WWW 10), Hong Kong, May 2001.
13.
Wei Han, David Buttler, Calton Pu.
Wrapping Web data into XML, SIGMOD Record, vol. 30,
№3, September 2001. – pp 33 – 38.
14.
Weicheng Xie, Chuanhua
Zeng, Yan Lin, Yangqiang Chen. A Web data extraction technique based on XML. Xihua University.
15.
Подсистема сбора сообщений с сайтов новостей сети Интернет/
А.М. Андреев, Д.В.Березкин,
В.В. Морозов и др.// Труды №1 молодых ученых, аспирантов и студентов «Информатика и системы управления». – М.: Изд. МГТУ им. Н.Э. Баумана. – 2003. – С.409 – 410.
16.
Андреев А.М., Березкин
Д.В., Симаков К.В. Модель извлечения фактов из естественно-языковых текстов и метод ее обучения //Электронные
библиотеки: перспективные методы и технологии, электронные коллекции: Труды Восьмой Всероссийской
научной конференции
RCDL’2006 (г. Суздаль, 17 - 19 октября
2006 г.). – Ярославль: Ярославский
гос. унив.-т им. П.Г. Демидова, 2006. – С.252
– 261.