Шелюк Артем Евгеньевич



Проблема интеллектуального управления данными является одной из самых актуальных тем в современной индустрии хранения данных. Увеличение накапливаемого объема данных промышленных систем в процессе их эксплуатации приводит к усложнению управления и последующего анализа на основе традиционных моделей.
По прогнозам, в 2012 г. объем цифровой информации приблизится к 1800 экзабайт, в 10 раз превысив объем цифровой информации в 2006 г. Не менее 95% этих данных – это трудно поддающиеся управлению неструктурированные данные, например электронная почта, документы Word, видео и т.п., причем 90% этой информации никогда не будет прочитано.
Практически вся информация в сети Интернет не содержит семантики и поэтому ее поиск, релевантный запросам пользователя, в рамках конкретной предметной области является достаточно серьезной проблемой. Для обеспечения эффективного поиска и управления, веб-приложение должно четко понимать семантику документов, представленных в сети.
В современном мире главенствующую роль занимает информация. Иногда это выглядит вполне обоснованно, иногда спекулятивно, иногда совершенно беспочвенно, но она всегда имеет огромное влияние на принимаемые решения. Общий объем информации постоянно растет, все время появляются новые её источники. Усваивать и выделять нужную информацию становится все сложнее.
Потому основной проблемой в развитии является его интеллектуализация, и связанная с этим интеграция данных, качественный поиск, интеграция Веб служб и многое другое. Эффективные средства для указанных задач предлагаются в рамках подхода Semantic Web.
Целью работы является разработка средств и методов, которые позволяют создавать хранилища структурированных и частично-структурированных данных на основе семантического представления, а также управлять этими данными на высоком уровне абстракции.
Для выполнения поставленной цели необходимо решить существующие задачи:
Графический инсрументарий семантического браузера планируется реализовывать на языке Java с использованием объектно-ориентированных библиотек расширяемого каркаса IDE Eclipse:
В результате работы должен быть разработан инструментарий, который позволит просматривать внутреннюю структуру баз данных и частично-структурированных файлов, выполнять переходы по объектам на основе отношений между ними, поддерживает различные уровни кратности (один к одному, один ко многим) и типы отношений.
Иснтрументарий будет включать в себя: 1) инструментарий моделирования, который позволяет спроектировать предметную область (в качестве основного метода описания предметной области используются диаграммы UML); 2) инструментарий привязки данных к элементам концептуальной модели (отображение для управления данными через соответствующие им концепты); 3) непосредственно, браузер для просмотра концептов, их ассоциированных связей, объемов и выборок данных и пр.
Реализованные средства позволят работать с информацией на качественно ином уровне, а сам семантический браузер может является основой для построения информационных и аналитических систем.
Онтология — детальная формализация некоторой области знаний с помощью концептуальной схемы. Обычно такая схема состоит из структуры данных, содержащей все релевантные классы объектов, их связи и правила (теоремы, ограничения), принятые в этой области.
Классифицикая онтологий:
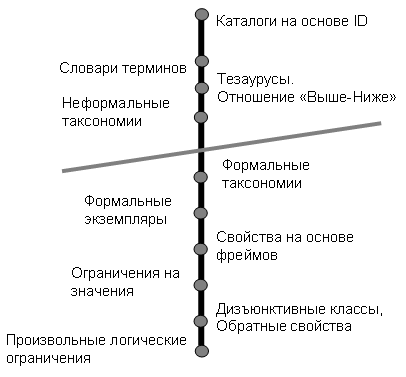
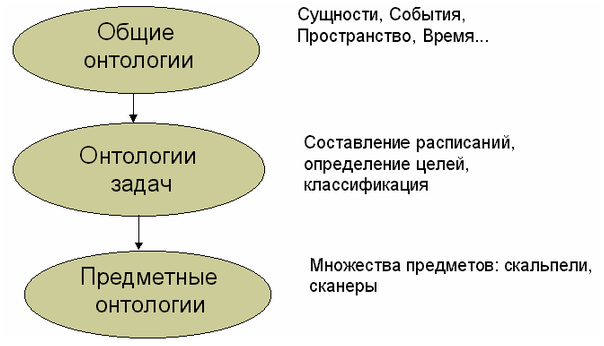

Общие онтологии описывают наиболее общие концепты (пространство, время, материя, объект, событие, действие и т.д.), которые независимы от конкретной проблемы или области. В эту категорию попадают и онтологии представления, и онтологии верхнего уровня.
Онтология, ориентированная на задачу — это онтология, используемая конкретной прикладной программой и содержащая термины, которые используются при разработке ПО, выполняющего конкретную задачу. Она отражает специфику приложения, но может также содержать некоторые общие термины (например, в графическом редакторе будут и специфические термины — палитра, тип заливки, наложение слоев и т.д., и общие — сохранить и загрузить файл). Задачи, которым может быть посвящена онтология, могут быть самыми разнообразными: составления расписания, определение целей, диагностика, продажа, разработка ПО, построение классификации. При этом онтология задачи использует специализацию терминов, представленных в онтологиях верхнего уровня (общих онтологиях)[18].
Предметная онтология (или онтология предметов) описывает реальные предметы, участвующие в какой-либо деятельности (производстве). Например, это может быть онтология всех частей и компонентов самолетов определенной марки (Boeing) и сведения об их поставщиках, характеристиках, способе соединения друг с другом и т.п.
Основная идея Semantic Web заключается в том, чтобы сделать информацию, передаваемую в Web, более формализованной и удобной для машинного восприятия, в частности, для того чтобы ее можно было идентифицировать и классифицировать. По мнению авторов технологии Semantic Web, это может достигаться посредством введения метаданных, которые должны сопровождать любую информацию и рассказывать о ее происхождении, формате и многом другом, что должно радикальным способом облегчить поиск информации в Web и ее обработку[17].
Основываясь на открытых стандартах, технологии Semantic Web позволяют описывать и выделять смысловую информацию (семантику) из произвольных данных, в частности содержания документов или кода приложений. Говоря, что машина понимает семантику документа, подразумевается не только интерпретация набора символов, содержащихся в документе, но и то, что машина понимает смысл документа, то есть значение документа в целом. Следующие технологии являются основными в составе Semantic Web:
Ключевым элементом технологий Semantic Web является уникальная система идентификации объектов. URI (Uniform Resource Identifier) – это идентификатор какого-либо объекта (ресурса) в глобальной сети. Любой элемент, схема или модель данных семантической сети должны иметь собственный уникальный адрес (URI). Сейчас используются два типа идентификаторов.
1. Универсальный указатель ресурсов (Uniform Resource Locator, сокр. URL) – это URI, который, помимо идентификации ресурса, указывает на способ обращения с ресурсом путем описания способа доступа к нему или его положения в сети.
2. Универсальное имя ресурса (Uniform Resource Name, сокр. URN) – это URI, который идентифицирует ресурс с помощью имени в определенном пространстве имен. Это позволяет ссылаться на ресурсе без использования информации об его расположении.
Второй базовый компонент Semantic Web – это модель данных Resource Description Framework (RDF), которая позволяет объединить информацию из произвольных источников. Формат RDF наиболее полезен в обеспечении совместного использования информации, смысл которой может одинаково интерпретироваться различными программными агентами. Специфика модели данных RDF состоит том, что ресурсы и свойства идентифицируются с помощью глобальных идентификаторов (URI). RDF описывает предметную область в терминах ресурсов, свойств ресурсов и значений свойств. RDF-данные можно расценивать как совокупность утверждений – субъект, предикат и объект утверждения, и представлять в виде направленного графа, образуемого такими утверждениями.
Следующий уровень в пирамиде технологий Semantic Web занимает RDF Schema – язык описания словарей RDF-терминов. RDFS служит фундаментом для более богатых языков описания онтологий предметной области, которые позволяют адаптировать к Web системы логики и обеспечить семантическую обработку данных. Схема RDF представляет собой систему типов для Semantic Web и позволяет определить классы ресурсов и свойства как элементы словаря, в частности задать, какие свойства с какими классами могут быть использованы.
Базовый строительный блок модели данных RDF – утверждение, представляющее собой тройку: ресурс, именованное свойство и его значение. В терминологии RDF эти три части утверждения называются соответственно: субъект (subject), предикат (predicate) и объект (object). Ресурсом в данном случае называют все, что описывается средствами RDF. Это может быть обыкновенная Web-страница или какая-то ее часть, например, отдельный элемент HTML разметки. Также ресурсом может являться целая коллекция страниц, например, Web-сайт. И, наконец, в качестве ресурса может выступать нечто, не являющееся доступным непосредственно через Интернет, например, произвольный предмет из мира вещей.
В RDF под свойством (Property) следует понимать некий аспект, характеристику, атрибут или отношение, используемое для описания ресурса. Каждое свойство имеет свой специфический смысл, допустимые значения, тип ресурсов, к которым оно может быть применено, а также отношения с другими свойствами. Для обеспечения уникальности имен свойства придерживаются концепции URI, т.е. свойство становится потенциальным объектом для описания при помощи RDF отдельно от характеризуемого ресурса и имеющегося значения[17]ю
Таким образом, каждое свойство в RDF само является ресурсом и может иметь свои собственные атрибуты. Этот факт превращает модель данных из дерева, которым является XML-разметка, в ориентированный граф. Вершинами этого графа являются субъекты и объекты, а дугами – именованные свойства. Поскольку свойство в свою очередь может быть субъектом некоторого утверждения, графы могут быть как линейными, так и вложенными, например, мы можем выражать сомнение или согласие с каким-либо утверждением или указывать источник получения сведений.
Одним из общезначимых свойств является «type», относящееся к пространству имен, задаваемому непосредственно спецификацией RDF. Оно позволяет указать класс описываемого ресурса. Это может быть автомобиль, человек, книга и т.п., а может быть некоторая последовательность объектов (для выражения данного факта существует специальное значение «Seq», также принадлежащее к пространству имен RDF). Согласно спецификации, значение свойства может иметь один из двух типов.
Первый – это ресурс, задаваемый некоторым URI. Второй тип – литерал, есть некоторое текстовое значение характеристики. Впрочем, литерал может выражать собой значение любого примитивного типа данных, присутствующего в XML. Его текст также может содержать в себе некую разметку, например, XML, но отличительной особенностью такой разметки является то, что она не обрабатывается RDF-процессором и воспринимается как обычная строка[17].
Модель данных сама по себе всего лишь скелет. Для того чтобы описание обрело некий смысл, необходимо воспользоваться словарями, которые задаются при помощи дополнительной технологии – RDF Schema, играющей для RDF такую же роль, что и схема для XML. Под словарем понимается совокупность ресурсов, использующихся для описания свойств других ресурсов; классов ресурсов, которые могут быть описаны при помощи заданных свойств; и ограничения, налагаемые на их значения или наборы допустимых значений. При этом классы могут состоять в отношении «подкласс» и аналогично свойства могут быть связаны отношением «подсвойство».
Модель данных, построенная при использовании надлежащих словарей, предлагает осмысленное описание ресурсов, но этого еще не достаточно для понимания Web машинами. Подобно тому, как один человек не имеет возможности передать знание другому, если они оба умеют говорить на одном языке, но используют для этого различную лексику, цель не будет достигнута, пока не будут разработаны единые словари для описания каких-то фактов, и программы не смогут пользоваться ими.
Реальное значение RDF невозможно оценить, пока он используется для внутренних целей отдельно взятого приложения. Польза от внедрения RDF будет тогда, когда он станет средством межпрограммного взаимодействия, обмена данными, когда машины получат способность комбинировать информацию, полученную из различных источников, тем самым, получая какую-то новую информацию.
Чем больше приложений в Интернете смогут работать с данными, тем выше станет их ценность [5]. В то же время RDF прекрасно подходит и для представления самих данных, их структуры и связей. Таким образом, при применении специально разработанных RDF-схем (в качестве средства описания онтологии предметной области) технология Semantic Web может быть использована для выражения информации, относящейся к некоторым разделам знаний, понятным для различных приложений Интернета образом.
Выбирая базовую IDE для написания плагина визуализации, было решено рассматривать только Eclipse, т.к если писать плагин для этой IDE, то он разрабатывается как внешний модуль, и практически никогда не требует изменения самой IDE, поскольку вся необходимая функциональность предоставляется базовой средой разработки. Так же Eclipse изначально задумывался не как единый продукт, а как множество модулей, взаимодействующих друг с другом. Поэтому сразу же вопрос написания разнообразных плагинов был широко освещён и по данной теме на официальном сайте присутствует большое количество учебных материалов, статей и примеров.
Основные преимущества Eclipse:
Для реализации графических элементов плагина была выбрана библиотека GEF (Graphical Editing Framework). GEF − фреймворк, специально разработанный для платформы Eclipse. Считается, что GEF довольно сложный фреймворк для изучения, но при этом он имеет ряд преимуществ по сравнению с другими фреймворками. GEF состоит из следующих компонент:
Структура Eclipse плагина (графическое представление структуры плагина представлено на рисунке 1.4). Он состоит из следующих частей.
JAR-файл, содержащий плагин, должен иметь определенное имя и находится внутри определенной директории Eclipse, где IDE сможет найти и загрузить его. Имя файла должно содержать идентификатор плагина, потом подчеркивание, и версию: com.qualityeclipse.favorites_1.0.0.jar.[9,11]
Плагин Eclipse, как любой компонент имеет ряд особенностей и функций.
Плагин может объявлять точки расширения так, чтобы другой плагин мог изменять (обычно увеличивать) функциональность оригинального плагина в соответствии с нуждами разработчика. Такой механизм позволяет делать дополнения независимыми, поскольку начальный плагин в этом случае может ничего не знать о дополнении, которое его расширит. Для каждой точки расширения должна быть указана ее категория и список атрибутов, необходимых, чтобы этой точкой воспользоваться.

В MANIFEST.MF объявлены свойства сборок OSGi и (не всегда) пакетов Java, которые должны быть доступны другим сборкам. Bundle-SymbolicName позволяет задать уникальное имя сборки.
Манифест является первым XML-дескриптором компонента. Работа с дескрипторами компонентов начинается при старте платформы Eclipse. Загрузчик плагинов просматривает каталоги plugins (и/или links) в поисках установленных компонентов, и для каждого компонента анализирует файлы MANIFEST.MF и plugin.xml. При этом в памяти строится структура связей сборок и их описаний (реестр плагинов), но загрузки кода компонентов не происходит (структура управления плагинами занимает в памяти несоизмеримо меньше места, чем «обычный» набор плагинов).
Второй основной дескриптор компонента (наряду с манифестом) – xml-дескриптор, который должен находиться в файле plugin.xml. Этот дескриптор также анализируется загрузчиком плагинов Eclipse до того, как будет загружаться и исполняться код плагина. Основная задача этого дескриптора – описать связи, настройки компонентов, его взаимодействие с другими компонентами и аспектами визуального представления плагинов, которые создаются с помощью механизма «точек расширения». Основное назначение точки расширения – объявить уникальный идентификатор, который будет использован конкретными расширениями для ссылки на точку расширения[10].
В данной работе была рассмотрена основная классификация онтологий, а также их языков описания. Выполнен обзор технологий Semantic Web, принципов построения модели RDF и использования словарей RDF: Schema. Также были изучены методы разработки приложения для расширяемого каркаса IDE Ecipse, и библиотека GEF (Graphical Editing Framework) для реализации графической части интсрументария.
На момент написания данного реферата магистерская работа еще является не завершенной. Предполагаемая дата завершения: декабрь 2012 г., ввиду чего полный текст работы, а также материалы по теме могут быть получены у автора или его руководителя только после указанной даты.