Нейронная сеть эхо состояний
Автор: Мартин Рамко
Автор перекладу: О.И. Камозина
Джерело: Department of Cybernetics and Artificial Intelligence, TU FEI Kosice, AI, 2005
Автор: Мартин Рамко
Автор перекладу: О.И. Камозина
Джерело: Department of Cybernetics and Artificial Intelligence, TU FEI Kosice, AI, 2005
Целью данной работы является описание нового вида рекуррентных нейронных сетей - сетей эхо состояний, упрощённый алгоритм работы который позволяет ускорить процесс обучения.
Echo state networks - это новый подход к анализу и обучению рекуррентных нейронных сетей, который приводит к быстрому, простому и конструктивному алгоритму для контролируемого обучения. Основополагающая идея ESN – использование большого « резервуара» рекуррентных нейронных сетей как поставщика интересной динамики с которой сочетается желаемый выход. Эта идея была независимо обнаружена Вольфгангом Маасом и его коллегами, также исследована под названием LSM ( liquid state machines ). Эти два подхода дополняют друг друга во многих аспектах.
Рассчитал довольно общий класс считывания данных функций для преобразования нейронных состояний в желаемый выходной сигнал, который в принципе может быть реализован последующей обработкой состояния сети сетью прямого распостранения.
С другой стороны, исследования ESN до сих пор сосредоточены на линейных и линейно-сигмоидных считывающих функциях, которые должны быть реализованы только путем присоединения выходной единицы в нейросеть.
Элементарными кирпичиками строения РНН являются нейроны ( мы будем использовать термин единицы), соединённые синаптическими связями ( соединениями), синаптическая сила которых кодируется весами. Различают входные единицы, внутренние ( или скрытые) единицы и выходные единицы. Сейчас, единица имеет активацию. Обозначим их так:
u(n) – активация входного нейрона;
x(n) – активация скрытого нейрона;
y(n) – активация выходного нейрона.
Иногда различия игнорируются, тогда используют во всех случаях x(n) .
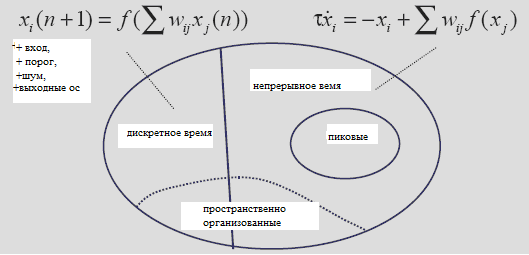
Рисунок 1 - Типология моделей РНН (неполная).
Существует много видов основных моделей РНН. Модели дискретного времени математически служат как карты итераций по дискретно временным шагам n = 1, 2, 3, ... . Модели непрерывного времени определяются через дифференциальные уравнения, решения которых определены по непрерывному времени t. Специально для целей биологического моделирования, непрерывные динамические модели могут быть довольно запутаны и описывать активацию сигналов на уровне отдельных активаций потенциалов ( пиков). Часто модель включает в себя спецификации пространственной топологии, наиболее частые – 2D поверхности, где нейроны локально связаны в сетчатко-подобные структуры.
Эта статья открывает особый вид дискретно временных моделей без пространственных структур. Наша модель состоит из К входных единиц с вектором активации (1.1) ; N внутренних единиц с вектором активации (1.2); L выходных единиц с вектором активации (1.3).
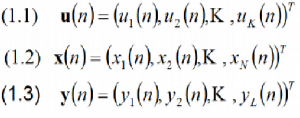
где Т – транспонирование.
Веса входных / внутренних / выходных соединений образуются в весовых матрицах N x K / N x N / L x (K+N+L). Выходные единицы необязательно должны возвращаться обратно к внутренним единицам с соединениями, веса которых образуются в весовой матрице обратного проецирования N x L.
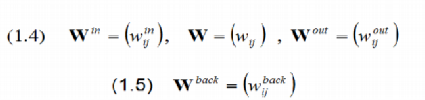
Нулевое значение веса может подразумевать «отсутствие связи». Обратите внимание, что выходные единицы могут иметь связи не только с внутренними единицами, но и также (редко ) с входными единицами и (редко ) с выходными единицами.
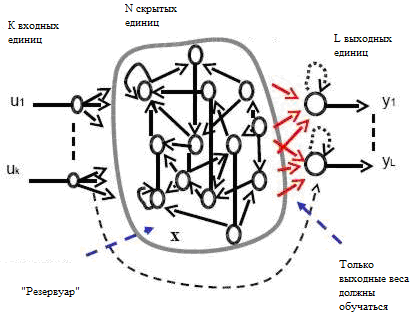
Рисунок 1.2 – Базовая структура нейросети. Штриховые линии означают дополнительные связи. Стрелки красного цвета обозначаю соединения, которые обучаются в подходом ESN ( в других методах все веса обучаются) .
Активация внутренних единиц обновляется в соответствии:
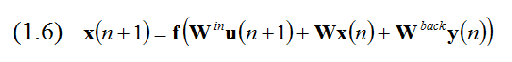
Где u(n+1) является заданным входом и f обозначает покомпонентное приложение передачи функции индивидуального нейрона, f также знакома как функция активации , функция выходного слоя. Будем использовать в основном сигмоидную функцию f = tanh, но иногда также рассмотрим линейные сети с f = 1.
Выход вычисляется по формуле:
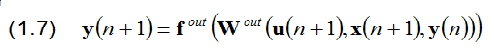
Где (u(n+1),x(n+1),y(n)) означает каскадный вектор, сделанный из входных, скрытых и выходных векторов активации. Мы будем использовать выходную передаточную функцию fout = tanh или fout = 1.
Подход к пониманию обучения ESN – это принцип эхо состояний. Наявность или отсутствие эхо стояний – это особенность нейросети до обучения, то есть свойство матрицы весов Win, W, и (если существует) Wback. Свойство также относительно к типу обучения данных ( training data) : таже не обученая нейросеть может иметь эхо состояния для определённых данных обучения. Поэтому требуется чтобы обучение входных векторов u(n) происходило из интервала U и выходных d(n) – из D. Дадим математическое определение ESN.
Возьмем необученную нейросеть с весами Win, W, и Wback управляемую учителем, входом u(n), и принудительным учителем, учителем выхода d(n), с компактных интервалов U и D. Нейросеть (Win, W, Wback ) имеет эхо состояния в отношении U и D, если для каждой минус бесконечности входных/выходных рядов (u(n), d(n-1)), где n = ..., -2,-1,0, и для всех рядов состояний x(n), x’(n) совместимых с обучающим рядом, т. е. с:
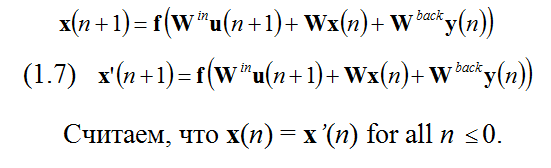
Интуитивно, свойства эхо состояния говорит «если сеть была запущена в течении долгого времени (от минус бесконечности по определению), текущее состояние сети однозначно определяется историей входа и ( обученного принудительным учителем) выхода» . Эквивалентный способ заявить это – сказать, что для каждого внутреннего сигнала xi(n) существует эхо функция ei, которая отображает историю входа/выхода в текущем состоянии:
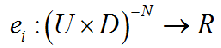
Мы часто говорим, несколько вольно, что (обученная ) сеть (Win, W, Wout, Wback) – это ESN, если её необученное «ядро » (Win, W, Wback) имеет свойство ESN, те вход/выход из любого интервала UxD. Свойство эхо состояния связано с алгебраическими свойствами весовой матрицы W. К сожалению, не известны необходимые и достаточные условия, которые позволят решать ( учитывая (Win, W, Wback)), имеет ли сеть свойства эхо состояний. Для определения эхо состояния в данной сети, можно использовать достаточное условие для отсутствия эхо состояния.
Предложение №1 Предположим, необученная сеть (Win, W, Wback) с эхо состоянием, обновленным в соответствии (1.6 ) и с передаточной функцией tagn. Пусть W имеет спектральные радиус |λ мах| > 1, где |λ мах| - это самая большая абсолютная величина собственного вектора W. Тогда сеть не имеет эхо состояния по отношению к любому входному/выходному интервалу U x D, содержащего нули входа/выхода (0,0). Было замечено, что когда условие, предложенное выше не выполняется, т. е. спектральный радиус матрицы весов меньше единицы, у нас есть эхо состояние.
Гипотеза №1 Пусть δ, ε - это два положительных числа. Тогда есть сеть размером N таковым, чтобы N – размерный динамический резервуар был случайно обазован (1), случайно сгенерируемой матрицей весов W0 , отбором проб весов от равномерного распределения на [-1,1], (2) нормализацию W0 в матрицу W1 с единичным спектральным радиусом, полагая W1 =1/|λ мах| W0, где |λ мах| - это спектральный радиус W0 , (3) масштабирование радиуса, полагая W1 to W2 = (1-δ) W1, посредство чего W2 получает спектральный радиус (1-δ)), тогда сеть (Win, W, Wback) – это ESN с вероятностью 1- ε.
Существует и другая процедура:
Вычисляя L выходных весов wiout для y(n) такую, что выходы данных учителя d(n) аппроксимированы как линейная комбинация внутренних активаций временных рядов xi(n) формулой:
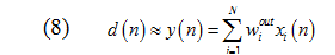
С математической точки зрения, это является линейно регрессивной задачей: вычисление регрессии весов wiout d(n) на состояниях сети xi(n).
1. W. Maass, T. Natschlaeger, and H. Markram. Real-time computing without stable
states: A new framework for neural computation based on perturbations.
Submitted, 2001.
2. H. Jaeger (2001), The "echo state" approach to analysing and training recurrent
neural networks. GMD Report 148, GMD - German National Research Institute
for Computer Science, 2001.
3. H. Jaeger (2001a), Short term memory in echo state networks. GMD Report 152,
GMD - German National Research Institute for Computer Science, 2002.
4. H.Jaeger(2002),A tutorial on training recurrent neural networks, covering BPPT,
RTRL, EKF and the "echo state network" approach, Fraunhofer Institute for
Autonomous Intelligent Systems (AIS), International University Bremen, 2002 .
5. Benjamin Liebald, Exploration of effects of different network topologies on the
ESN signal crosscorrelation matrix spectrum, International University Bremen,
2004 .