Web Mining: сегодня и завтра
Авторы: Sharma K., Shrivastava G., Kumar V.
Перевод: Арбузова О.В.
Источник: IEEE Xplore. Digital library. [Электронный ресурс]. – Режим доступа:http://ieeexplore...
Аннотация
В данной работе представлены исследования о том, как извлечь полезную информацию из Интернета, а также общие понятия об интеллектуальном анализе данных (Web Mining). Статья описывает настоящее, прошлое и будущее Web Mining. Представлены онлайн-ресурсы для поиска информации в Интернете, то есть для извлечения web-контента (Web Content Mining), и устранения недостатков интеллектуального анализа данных. Кроме того, описано Cloud Mining. Эту технологию можно рассматривать как будущее Web Mining.
Ключевые слова
Web Mining, Web Content Mining, Web Structure Mining, Web Usage Mining, Cloud Mining.
Введение
Широкое внедрение Интернета коренным образом изменило способы, которыми мы общаемся, собираем информацию, ведём бизнес и делаем покупки. Поскольку использование World Wide Web и электронной почты резко выросло, программисты и физики бросились изучать это новое явление. Хотя изначально они были удивлены огромным разнообразием Интернета, вскоре они обнаружили, широко распространенную в нём особенность: есть много мелких элементов, содержащихся в Интернете, и несколько крупных. Некоторые сайты состоят из миллионов страниц, но миллионы сайтов содержат только несколько страниц. Некоторые сайты содержат миллионы ссылок, но многие другие имеют одну или две. Миллионы пользователей стекаются на несколько избранных сайтов, уделяя мало внимания миллионам других.
Распространение Всемирной паутины (Web для краткости) привело к появлению большого объема данных, который теперь находится в общем свободном доступе для пользователей. Различные типы данных должны управляться и организовываться таким образом, чтоб они могли быть эффективно доступны для разных пользователей. Таким образом, применение методов интеллектуального анализа данных в Интернете в настоящее время в центре внимания все большего числа исследователей. Несколько методов Data Mining данных используются для обнаружения скрытой информации в сети Интернет. Тем не менее, Web Mining означает не только применение методов интеллектуального анализа данных. Алгоритмы должны быть изменены так, чтобы они лучше удовлетворяли требованиям Интернета [1], [12]. Должны использоваться новые подходы, которые лучше соответствуют свойствам веб-данных. Кроме того, не только алгоритмы интеллектуального анализа данных, но и искусственного интеллекта, поиска информации и естественных методов обработки языка могут быть эффективно использованы. Таким образом, Web Mining была выделена в автономную область исследований.
Историческая эволюция Web Mining
Методы Web Mining являются результатом длительного процесса исследований и разработки продукции. Эта эволюция началась, когда бизнес-данные стали впервые храниться на компьютерах и в интернете, продолжилась с улучшением доступа к данным и благодаря технологии реального времени, такой что пользователи в WWW (World Wide Web) могут перемещаться по данным.
В процессе эволюции из бизнес-данных к деловой информации каждый новый шаг создан на предыдущем. Например, способность хранить большие базы данных имеет решающее значение для Web Mining. С точки зрения пользователя, пять ступеней перечисленные в таблице 1 были революционными, потому что они позволили ответить точно и быстро на новые вопросы бизнеса.
| Эволюционный шаг | Бизнес-вопрос | Технологии | Поставщики продукта | Характеристики |
| Сбор данных (1960-е годы) |
Каков же был мой общий доход за последние пять лет? |
Компьютер, ленты, диски | IBM, CDC | Ретроспективная, статическая доставка данных |
| Доступ к данным (1980-е годы) |
Каков был объем продаж в Дели в прошлом Марте. |
Реляционная база данных(СУБД), структурированный язык запросов(SQL), ODBC | Oracle, Sybase, Informix, IBM, Microsoft | Ретроспективная, динамическая доставка данных на уровне записи |
| Хранилища данных и поддержка принятия решений (1990-е годы) |
Каков был объем продаж в Дели в прошлом Марте? Детализировать до Мумбаи. |
OLAP, многомерные базы данных, хранилища данных | Pilot, Comshare, Arbor, Congnos, Microstrategy | Ретроспективная, динамическая доставка данных на нескольких уровнях |
| Data Mining (2000-е годы) |
Что, скорее всего, произойдет с продажами в Мумбаи в следующем месяце? Почему? |
Усовершенствованные алгоритмы, многопроцессорные компьютеры, большие базы данных | Pilot, Lockheed, IBM, SGI, numerous startups (nascent industry) | Перспективная, проактивная доставка информации |
| Web Mining (нынешнее время) |
Что, скорее всего, произойдет с продажами в Мумбаи в следующих / предыдущих миллионах месяцев? |
WWW, Интернет, огромные базы данных | RockWare, Apteco Ltd., Simon Fraser University, IBM, Web Trends, SPSS, Flowerfire, Angoss, Net Genesis | Мощный, доступный инструмент для добычи больших объемов данных из реляционных баз данных, быстрое и эффективное использование нескольких функций Web Mining |
Таблица 1 – Этапы в эволюции Web Mining
В основном в Web Mining используется метод интеллектуального анализа данных. Web Mining является расширенной версией Data Mining. Извлечение данных работа Off-Line, в то время как Web Mining работа On-Line. В интеллектуальном анализе данные хранятся в базах данных, а в Web Mining данные хранятся в базе данных сервера и веб-журнале.
Основные компоненты технологии Web Mining были в стадии разработки в течение десятилетий, в области исследований, таких как искусственный интеллект и машинное обучение. Сегодня зрелость этих методов в сочетании с высокой производительностью реляционных баз данных и усилиями по интеграции данных, делает эти технологии практическими для хранения данных [10].
Недостатки существующих подходов
- Время отклика слишком длинное.
- Взрывной рост веб наложил большой спрос на сети.
- Ресурсы и веб-сервера.
- Очевидным решением для того, чтобы улучшить качество веб-служб, будет увеличение пропускной способности, но такой выбор предполагает увеличении экономических издержек.
- Схема веб-кэширования имеет существенный недостаток: если прокси-сервер неправильно обновляется, то пользователь может получить устаревшие данные.
- Очевидными факторами являются ограниченные системные ресурсы серверов. Однако, даже если кэш пространство не ограничено, существуют значительные проблемы.
- Главным недостатком системы, является то, что некоторые предварительно выбранные объекты не могут быть в конечном итоге использованы пользователями. В таком случае, предварительная выборка увеличивает сетевой трафик, а также нагрузки веб-серверов [9].
Web Mining
Web Mining основано на знаниях извлечённых из Интернета. Web Mining как граф, все страницы (узлы) которого соединяются гиперссылками. Web Mining полезен для извлечения информации, изображений, текста, аудио, видео, документов и мультимедиа. С помощью Web Mining легко извлечь всю информацию о мультимедиа, которую до этого было трудно извлечь надлежащим образом из Интернета. Раньше трудно было получить точную информацию из веб, но сейчас легко получить надлежащую информацию о любых вещах [2], [1]. Web Mining основан на технике интеллектуального анализа данных, используя метод интеллектуального анализа данных обнаруживаются скрытые данные в веб. Таким образом, Web Mining, хотя считается конкретным приложением Data Mining, требует отдельной области исследований.
Web Mining можно рассматривать как использование методов интеллектуального анализа данных, чтобы автоматически получать, извлекать и оценивать
информацию для обнаружения знаний из веб-документов. Это включает в себя обобщение
и анализ
.
Категории Web Mining
Web Mining можно разделить на три группы:
- Web Content Mining (извлечение web-контента).
- Web Structure Mining (извлечение web-структур).
- Web Usage Mining (анализ использования web-ресурсов).
Web Content Mining
Web Mining в основном извлекает информацию в Интернет. Какой процесс произойдет для доступа к информации в Сети – это Web Content Mining. Многие страницы открыты для доступа к информации в Интернете. Эти страницы являются содержанием веб. Последний точный результат определяется как результат содержательных страниц извлечения.
Web Structure Mining
Мы можем определить Web Structure Mining с точки зрения графа. Веб-страницы представляют в виде узлов, а гиперссылки представляют рёбра. В основном это показывает отношения между пользователем и веб-сайтом. Мотив Web Structure Mining – генерации структурированных резюме об информации на веб-странице. Показывает, ссылки одной веб-страницы к другой веб-странице.
Web Usage Mining
Это открытие значимых шаблонов из данных, полученных от клиента сервера транзакций на одном или более веб-расположений. Интернет – это коллекция взаимосвязанных файлов на одном или нескольких веб-серверах. Он автоматически генерирует данные, хранящиеся в журналах доступа к серверу, ссылается на логии [3].
Использование Web Mining направлено на использование методов интеллектуального анализа данных. Это техника, чтобы предсказать поведение пользователя, когда он взаимодействует с сетью [11].
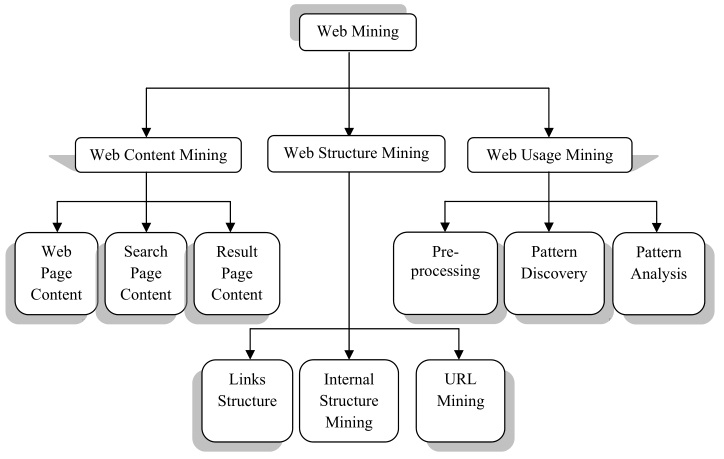
Рисунок 1 – Классификация Web Mining
| Сравнение | Web Mining | Data Mining |
| Шкала | Обработка поиска не большая. | Обработка поиска большая. |
| Доступ | Web Mining предоставляет публичный доступ к данным. Не скрываются данные, к которым осуществляется доступ в веб-базе данных. Но получаетсям разрешение для доступа к данным. | Data Mining предоставляет доступ к данным только в частном порядке и разрешает пользователю доступ к данным в базе данных. |
| Структура | Web Mining получает информацию из структурированных, неструктурированных и полуструктурированных веб-страниц. Web Mining извлечекает информацию из обширной базы данных. | Data Mining получает информацию из явных структур. Data Mining не работает с информацией из обширных баз данных, сравнительно с Web Mining. |
Таблица 2 – Web Mining и Data Mining
Web Mining облачных вычислений
Cloud Computing безусловно является одним из самых соблазнительных технологических областей на сегодняшний день по крайней мере из-за ее
стоимости, эффективности и гибкости. Однако, несмотря на активный рост и заинтересованность, существуют значительные, стойкие проблемы облачных
вычислений, которые в конечном итоге ставят под угрозу видение в облачных вычислениях новую модель закупок IT [8]. Термин
облако
является символом Интернета, абстракция базовой инфраструктуры Интернета, чтобы обозначить точки, в которых ответственность
переходит от пользователей к внешнему поставщику.
В основном Cloud Mining является новым подходом к интерфейсу поиска ваших данных. SaS (программное обеспечение как услуга) используется для снижения затрат Web Mining и старается обеспечить безопасность. На сегодняшний день мы готовы изменить структуру Web Mining на облачные вычисления [6].
Текущие исследования
Многие исследователи искали способ представить будущее Web Mining. Некоторые из них утверждают, что облако является будущим Web Mining. Как мы знаем, Этциони является первым человеком, который ввел термин Web Mining. Эта статья описывает Web Mining: подзадачи и процесс [3]. D. Sravan Кумар и B. Naveena Деви [4] описывают классификацию Web Mining. В этой работе также описывается процесс использования Web Mining.
Заключение
Некоторая путаница между Data Mining и Web Mining растет значительными темпами. Web Mining явлется плодородной областью исследований. Существуют многие успешные приложения. Развивается Cloud Mining, которое менее затратное, чем Web Mining. Таким образом, мы можем сказать, что Cloud Mining может рассматриваться как будущее Web Mining.
Литература
- Virgilio Almeida, Azer Bestavros, Mark Crovella, and Adriana de Oliveira, “Characterizing reference locality in the WWW” , In IEEE International Conference in Parallel and Distributed Information Systems, Miami Beach, Florida, USA, December 1996. http://www.cs.bu.edu/groups/oceans/papers/ Home.html
- Pei J., Han J., Mortazavi B., Zhu H. “Mining Access Patterns efficiently from Web Logs,” Proc. Pacific-Asia Conf. Knowledge discovery and Data Mining (PAKDD’00) 2000.
- Etzioni O. “The World Wide Web: Quagmire or gold mine”, Communication of the ACM, Vol. 39, No. 11, pp. 65-68, 1996.
- Sravan Kumar D. and Naveena Devi B. “Learner’s Centric Approach for Web Mining ” et al. (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 1(2), 2010.
- Magdalini Eirinaki and Michalis Vazirgiannis, “Web Mining for Web Personalization” in ACM Transaction on Internet Technology, Vol. 3, No. 1, Feb. 2003.
- Ajay Ohri “Data mining through Cloud Computing”. http://knol.google.com/k/data-mining... See on Dec. 2010.
- Michael Jennings, “What are the major comparisons or differences between Web mining and data mining?” Information Management Online, June 25, 2002.
- Deyi Li, Kaichang Di, Deren Li and Xuemei Shi, “Mining association rules with linguistic cloud models”, Research and Development in Knowledge Discovery and Data Mining ,Lecture Notes in Computer Science, 1998.
- Faten Khalil, Jiuyong Li and Hua Wang “A Framework of Combining Markov Model with Association Rules for Predicting Web Page Accesses” ,Proc. Fifth Australasian Data Mining Conference (AusDM2006), CRPIT Volume 61, pp. 177-184.
- Raymond Kosala, Hendrik Blockeel, “Web Mining Research: A Survey”, In ACM SIGKDD, July 2000.
- Wu K.L., Yu P.S. Ballman, A. “A Web usage mining and analysis tool”, IBM Systems Journal, 2010.
- Chen M. S, Han J. and Yu P. S. “Data Mining: An overview from a database perspective”, IEEE transaction on knowledge and data engineering, Vol. 08, No. 6, pp. 866-883, 1996.