
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження
- 3. Огляд досліджень та розробка
- 4. Висновки
- Перелік посилань
Вступ
Еволюційні алгоритми (ЕА)[2] – це стохастичний метод пошуку, який застосовуєтся для вирішення безлічі проблем пошуку, оптимізації та машинного навчання. На відміну від більшості інших технологій оптимізації, ЕА містять популяцію пробних рішень, які конкурентно управляються за коштами застосування деяких різних операторів для пошуку достовірного, якщо не глобального, оптимального рішення. Серед поширених підкласів ЕА широко вивчаються генетичні алгоритми (ГА). Генетичні алгоритми[1] итеративно навчають популяцію індивідів, застосовуючи оператор рекомбінації (об'єднуючи двох або більше батьків для отримання одного або більше нащадків) і мутації їх вмісту (випадкове зміна проблемних змінних). Однак якщо дотримуватися законів природної еволюції, не можна керувати однією популяцією, в якій взята особина претендує на схрещування з якими-небудь іншими партнерами в тій же популяції (безладне схрещування). Навпаки, вид розвивається в рамках громад (підгруп), де існує структурна близькість, і схильний до відтворення всередині підгрупи. Серед розширень типів ГА особливо популярні. розподілені ГА (РДА), Розподілені еволюційні алгоритми - це підклас паралельних генетичних алгоритмів, призначених для зниження передчасної збіжності до локального оптимуму, стимуляції різноманітності і пошуку альтернативних рішень тієї ж проблеми. Вони засновані на розбитті популяції на кілька окремих подпопуляцій, кожна з яких буде оброблятися ГА, незалежно від інших. Крім того, різноманітні міграції індивідів породжують обмін генетичним матеріалом серед популяцій, які зазвичай покращують точність і ефективність алгоритму Потужність еволюційних алгоритмів посилюється із застосуванням розподілених обчислень. Тут намагаються промоделювати природну модель взаємодії окремих популяцій, для вирішення наступних завдань:
- зменшення ймовірності передчасної збіжності
- збільшення різноманітності популяції
- збільшення швидкості збіжності до глобального оптимуму або максимально оптимальному вирішенню завдання
Для вирішення двох цих головних завдань існує велика кількість робіт, представлених в літературі.
1. Актуальність теми
Останнім часом активно розвиваються багатоядерні обчислювальні машини[4], що володіють можливістю багатопоточних обчислень. При використанні багатоядерних систем необхідно ефективно використовувати механізми розпаралелювання процесів[5] для найбільш продуктивного використання обчислювальних потужностей, у зв'язку з цим використання паралельного генетичного алгоритму бачиться більш продуктивним, ніж використання класичного генетичного алгоритму[3].
2. Мета і задачі дослідження
Мета роботи полягає в тому, щоб практично реалізувати концепцію паралельного генетичного алгоритму[6] за допомогою фреймверка Java concurrent на багатоядерних системах.
Основні завдання:
- Дослідити методи реалізації паралельного генетичного алгоритму.
- Вибрати метод реалізації паралельного генетичного алгоритму.
- Вивчити літературу з паралельних генетичних алгоритмів.
- Реалізувати вивчені методи в програмному проекті.
3. Огляд досліджень та розробка
У теперішній час виділяють три основні типи паралельних генетичних алгоритмів (ПГА)[8] :
- глобальні однопопуляціонние ПГА, модель «господар-раб» (Master–Slave GAs);
- однопопуляціонние ПГА (Fine–Grained GAs);
- многопопуляціонние ПГА (Coarse–Grained GAs).
МОДЕЛЬ «ГОСПОДАР - РАБ»
Модель «господар – раб» характеризується тим, що в алгоритмах такого типу селекція бере до уваги цілу популяцію, на відміну від двох інших моделей. Також варто відзначити те, що можливо випадкове схрещування, тобто будь-які два індивіда можуть схрещуватися, в інших моделях схрещування обмежується строго певним набором індивідуумів. В алгоритмах другого класу існує головна популяція, але оцінка цільової функції розподілена серед декількох процесорів. Господар зберігає популяцію, виконує операції ГА і розподіляє індивідууми між підлеглими. Вони ж лише оцінюють ЦФ індивідуумів. Однопопуляціонние ГА придатні для масових паралельних комп'ютерів і складаються з однієї популяції. Селекція і схрещування обмежені відносинами близького споріднення. Даний клас ПГА може бути ефективно реалізований на паралельних комп'ютерах. Третій клас – многопопуляціонние ГА більш складна модель, так як вона складається з декількох подпопуляцій, які періодично, за встановленими правилами, обмінюються індивідуумами. Такий обмін індивідуумами називається міграцією і управляється кількома параметрами. Многообщінние ГА дуже популярні, але достатні складні як для розуміння так і для реалізації, тому що наслідки від ефекту міграції, на даний момент, не повністю досліджені. У той же час многообщінние ГА мають схожість з «острівної моделлю» в популяційної генетики, яка розглядає відносно ізольовані громади; тому паралельні ГА в деяких випадках називають «острівними» паралельними ГА.
ОСТРІВНА МОДЕЛЬ
Використання невеликого числа відносно великих подпопуляцій та міграція між ними – є однією з головних характеристик многообщінних ПГА. Можна припустити, що першим систематичним вивченням паралельних ГА з безліччю популяцій була дисертація Р.Б.Гроссо (Grosso). Його метою було імітувати взаємодію паралельних субкомпонентов еволюціонує популяції. При цьому Гроссо імітував диплоїдних особин (використовувалися дві субкомпоненти для кожного «гена»), і популяція була розділена на 5 громад. Кожна громада обмінювалася індивідуумами з усіма іншими громадами при встановленні фіксованих коефіцієнтів міграції. Експериментальним шляхом Гроссо визначив, що поліпшення середньої ЦФ популяції відбувалося швидше при маленьких громадах, ніж при одиночній популяції. Це підтверджує усталений у генетиці популяцій принцип: сприятливі ознаки поширюються швидше, коли громади маленькі, ніж коли вони великі. Проте він також зауважив, що коли громади були ізольовані, стрімке зростання ЦФ зупинився на меншому значенні, ніж при великій популяції. Іншими словами, якість знайденого рішення до збіжності було гірше в ізольованому випадку, ніж в одиночній популяції. При низькому коефіцієнті міграції громади все ще вели себе (працювали) незалежно один від одного і досліджували різні регіони простору пошуку. Мігранти не чинили значного ефекту на поведінку громад, і якість рішень було порівнянним з випадком, коли громади були ізольовані. Однак при середніх коефіцієнтах міграції розділена популяція знайшла рішення, схожі з тими, що знайдені для одиночної популяції. Ці спостереження показують, що мається критичне значення коефіцієнта міграції, нижче якого продуктивність алгоритму утруднюється зважаючи ізоляції громад. Для вищерозміщених значень цього коефіцієнта розділена популяція знаходить вирішення того ж якості, що і звичайна одиночна популяція. Зазвичай дана модель розробляються для кластерних архітектур, які складаються з декількох незалежних робочих станцій зі своєю локальною пам'яттю. На кожній з таких систем виконується своя копія ГА (побудова нових поколінь популяцій). При цьому генетичні параметри роботи цих алгоритмів повинні дещо відрізнятися один від одного. Це дозволить направити пошук на кожному такому «острові» у відмінному від інших напрямку. Через задану кількість ітерацій острова проводять обмін кращими особинами, що дозволяє коригувати напрямок пошуку для менш вдалих островів. Ефективність паралельних ГА, побудованих за такою схемою, визначає саме по взаємодії компонент. Можна виділити основні характеристики такого обміну:
- топологія, яка визначає, які подпопуляціі будуть вважатися сусідніми і, відповідно, між якими островами буде можливий обмін особинами;
- час ізоляції, яке визначає, скільки епох ГА не проводитиметься міграція;
- ступінь міграції, яка визначає кількість особин, що беруть участь в міграції;
- стратегія відбору особин для міграції;
- стратегія видалення особин з подпопуляціі при проведенні міграції;
- стратегія реплікації мігруючих особин.
Зауважимо також, що хоча популяції розвиваються незалежно і рівноправно, в реалі-зациях такого виду алгоритмів виділяється сервер, який ініціалізує роботу і реалізує топологію обміну даними. Більше того, синхронізація роботи копій ГА на островах вимагає способу їх взаємодії. Точна і коректна реалізація такої взаємодії різних копій ГА в моделі островів є складним завданням. Популярність многообщінних паралельних ГА пояснюється тим що:
- Многообщінние ГА виглядають як просте розширення послідовного ГА. Схема очевидна: взяти кілька простих послідовних ГА, запустити їх на вузлі паралельного комп'ютера і в попередньо визначений час обмінюватися кількома особинами.
- Потрібен відносно мало додаткових зусиль для конвертації послідовного ГА в многообщінний ГА. Велика частина програми послідовного ГА зберігає стндартную інформацію та слід додати невелику кількість додаткових підпрограм, щоб реалізувати міграцію.
Узагальнену схему міграційної моделі ГА ви можете побачили на малюнку 1.
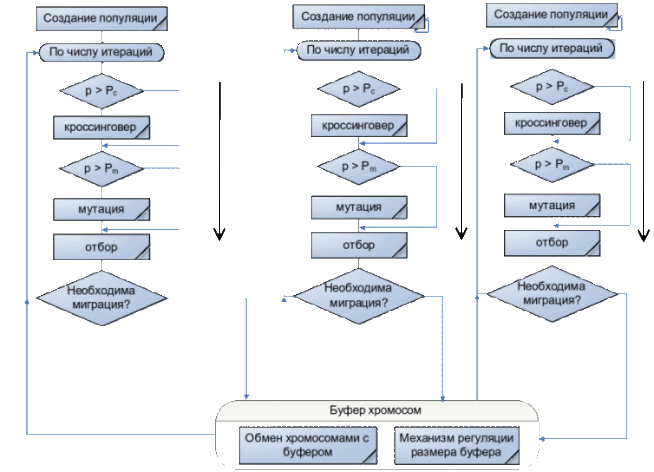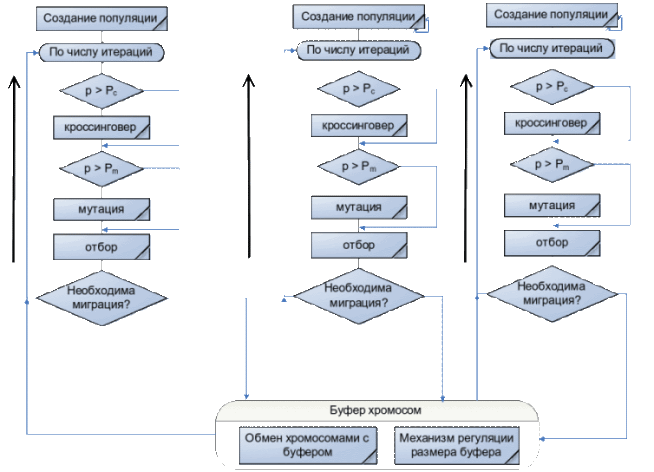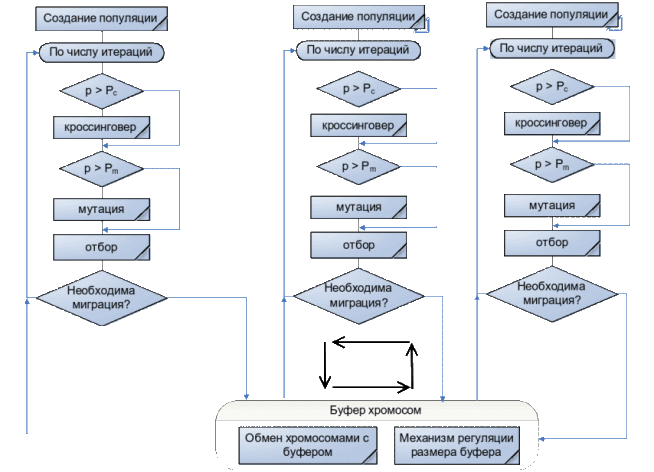
Рисунок 1 – Міграційна модель ГА
(анімація: 4 кадри, постійне повторення, 150 кілобайти)
Побудова ПГА за допомогою Java Concurrent[7]. Фреймверк Java Concurrent[9] містить широкий набір засобів для розпаралелювання та подальшої синхронізації паралельних процесів. Одним з таких наборів є паралельні колекції. Паралельні колекції полегшують розробку багатопотокових програм, надаючи потокобезпечна, вдало зроблені структури даних. Проте в деяких випадках розробнику потрібно зробити ще один крок вперед і подумати про регулювання та / або обмеження виконання потоків. Оскільки пакет java.util.concurrent покликаний спростити багатопоточне програмування, саме тому в нього включені утиліти для синхронізації. Модель міграції представляє популяцію як безліч подпопуляцій. Кожна подпопуляція обробляється окремим потоком (Thread_N). Ці подпопуляціі розвиваються незалежно один від одного протягом однакової кількості поколінь, по закінченню часу ізоляції (час ізоляції буде залежить від параметра - Sleep, який буде викликається на поточному Thread, тобто на поточному подпопуляціі – Thread_N.sleep (час ізоляції)) відбувається обмін особинами між подпопуляціямі. Кількість особин, які зазнали обміну, метод відбору особин для міграції та схема міграції визначає частоту так званого генетичного різноманіття в подпопуляціях та обмін інформацією між подпопуляціямі. Відбір особин для міграції відбувається за допомогою пропорційного відбору. Для міграції беруться найбільш придатні особини. Так при використанні пропорційного відбору в необмеженої міграції спочатку формується колекція з найбільш придатних особин, відібраних за всіма подпопуляціям. Так як в кожному потоці Thread_N обробляється своя подпопуляція, то й особини кожної подпопуляціі міститися в колекції свого потоку виконання. Використовуються колекції типу HashSet[10], в яких міститися шукані подпопуляціі. Нижче наведено фрагмент коду на Java, який показує уявлення подпопуляціі у вигляді колекції типу HashSet:
-
Set
subpopulations_1=new HashSet (); - Set
subpopulations_2=new HashSet (); - Set
subpopulations_3=new HashSet (); - Set
subpopulations_N=new HashSet ();
Генеральна, або «загальна» популяція представлена в тому ж вигляді:
- Set
unionpopulations=new HashSet ();
На основі такого підходу формується «загальна» колекція, яка містить особини з кожної колекції подпопуляцій. Випадковим чином з цієї «загальної» колекції вибирається особина, і нею замінюють найменш придатну в подпопуляціі N. Аналогічні дії проробляємо з рештою подпопуляціямі. При такому підході так само можливо, що якась подпопуляція отримає дублікат своєї «хорошою» особини. Весь цей механізм обміну особинами подпопуляцій реалізований через так званий пул потоків. Пул потоків пропонує рішення і проблеми витрат життєвого циклу потоку, і проблеми пробуксовки ресурсів. При багаторазовому використанні потоків для реалізації нової подпопуляціі, витрати створення потоку поширюються на багато завдань. Як бонус, оскільки потік вже існує, коли прибуває запит, затримка, що відбулася через створення потоку, усувається. Таким чином, запит може бути оброблений негайно, що робить наш додаток більш бистрореагірующій. Нижче представлена схема роботи з пулом потоків:
- public class WorkQueue
- {
- private final int nThreads;
- private final PoolWorker[] threads;
- private final HashSet queue;
- public WorkQueue(int nThreads)
- {
- this.nThreads = nThreads;
- queue = new HashSet();
- threads = new PoolWorker[nThreads];
- for (int i=0; i
- threads[i] = new PoolWorker();
- threads[i].start();
- }
- }
У цьому фрагменті коду представлена чергу потоків. Кожен потік містить свої подпопуляціі особин; пул потоків забезпечує і безпечний обмін особинами, виключаючи взаємні блокування потоків, що в свою чергу забезпечує кращу продуктивність і менший час на виконання операції міграції між подпопуляціямі.
Висновки
Для виконання поставленого завдання - реалізації паралельного генетичного алгоритму була обрана стратегія міграції особин між подпопуляціямі, так само звана «міграційної моделлю». Для практичної реалізації був обраний об'єктно–орієнтована мова Java і фреймверк для розпаралелювання Java Concurrent. Для синхронізації паралельних потів використовується пул потоків, який забезпечує безпечний обмін особинами, виключаючи взаємні блокування потоків, що в свою чергу забезпечує кращу продуктивність і менший час на виконання операції міграції між подпопуляціямі. Було встановлено, що потужність еволюційних алгоритмів посилюється із застосуванням паралельних обчислень. Використання паралельних алгоритмів дає більшу вигоду в продуктивності системи і часу виконання поставленого завдання.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Курейчик В.М., Кныш Д.С. Параллельный генетический алгоритм. Модели и проблемы построения // – С.1 – 3.
- Интернет-ресурс. - Режим доступа:www/ URL: http://www.gotai.net/ – сайт по ИИ.
- Гладков Л.А., Курейчик В.М., Курейчик В.В. Генетические алгоритмы [Текст]/под ред. В.М. Курейчика . – 2-е издн., испр. и доп. – М.:ФИЗМАТЛИТ ,2006 .-320 с.
- Иванов Д.Е., Чебанов П.А. Взаимодействие компонент в распределённых генетических алгоритмах генерации тестов / Д.Е. Иванов, П.А. Чебанов // Наукові праці Донецького національного технічного університету. Серія: “Обчислювальна техніка та автоматизація”. Випуск 16(147).- Донецьк: ДонНТУ.- 2009.- С.121-127.
- Grosso P.B. Computer Simulations of Genetic Adaptation: Parallel Subcomponent Interaction in a Multilocus Model// Unpublished doctoral dissertation, The University of Michigan. (University Microfilms №8520908), 1985.
- Курейчик В.М., Родзин С.И. Эволюционные алгоритмы: генетическое программирование. Обзор // Известия РАН. Теория и системы управления.-2002.-№1.-С.127-137.
- SDN for Java Concurrent / Интернет-ресурс. - Режим доступа: http://docs.oracle.com/javase...
- Mitchell M. An Introduction to Genetic Algorithms [Текст]/M.Mitchell. — Cambridge: MIT Press, 1999 —158 c. — ISBN 0-262-13316-4 (HB), 0-262-63185-7 (PB).
- Java Concurrency in Practice Brian - Goetz, Tim Peierls, Joshua Bloch — Москва: Sun Press, 2012 —983 c. — ISBN 0-262-13316-4 (HB), 63185(P).
- Java 2. Библиотека профессионала. Том 1. Основы - Кей С. Хорстманн, Гари Корнелл. - Москва: Sun Press, 2012 —989 c. — ISBN 0-262-13316-4 (HB), 0-262-63185-7 (PB).