
Реферат за темою випускної роботи
Зміст
- Вступ
- 1 Актуальність теми
- 1.1 Мета і завдання дослідження
- 1.2 Передбачувана наукова новизна
- 1.3 Практична важливість
- 2. Огляд досліджень і розробок
- 3. Методи рішення задач розпізнавання
- 3.1 Метод побудови еталонів
- 3.2 Метод потенційних функцій
- 3.3 Кластерний аналіз
- 4. Огляд методів кластеризації даних
- 4.1 Алгоритм CURE (ClusteringUsing Representatives)
- 4.2 Алгоритм BIRCH (Balanced IterativeReducing and Clustering using Hierarchies)
- 4.3 Алгоритм MST (Algorithm based on Minimum Spanning Trees
- 4.4 Алгоритм k-середніх (k-means)
- Висновки
- Перелік посилань
- Важливе зауваження
Вступ
Проблема розпізнавання образів вже давно привернула увагу психологів, фізіологів, інженерів і математиків. В останні роки інтерес до неї значно зріс, тому що в багатьох областях науки і техніки стала гостро відчуватися необхідність її вирішення. Це пов'язано з розробкою великої кількості різноманітних пристроїв (роботів, систем технічної та медичної діагностики, персональних, мобільних і кишенькових комп'ютерів), автоматична робота яких неможлива без розпізнавання поточного стану об'єктів, процесів, явищ і станів, з якими ці пристрої працюють.
Створення пристроїв, які виконують функції розпізнавання різних об'єктів, у багатьох випадках відкриває можливість заміни людини як елемента складної системи спеціалізованим автоматом. Така заміна дозволяє значно розширити можливості різних систем, що виконують складні інформаційно-логічні завдання. У той же час автомат його замінюючий діє одноманітно і забезпечує завжди однакову якість, якщо він справний.
Більшість сучасних прикладних завдань, що вирішуються шляхом побудови систем розпізнавання, характеризується великим обсягом вихідних даних і можливістю додавання нових даних вже в процесі роботи систем.
1 Актуальність теми
В даний час основним науковим напрямком є дослідження та розробка алгоритмів і методів побудови програмних засобів інтелектуального аналізу даних. Актуальність даної тематики визначається наявністю низки важливих прикладних задач, при вирішенні яких потрібна аналізувати великі обсяги різнорідних сложноорганізованних даних. При цьому обсяг і складність організації таких даних часто не дозволяють ефективно застосовувати традиційні засоби аналізу, засновані на методах статистичного аналізу, інформаційного пошуку та експертних знаннях, що визначає необхідність застосування засобів інтелектуальних аналізу даних, заснованих на методах машинного навчання і штучного інтелекту. Обсяги даних настільки значні, що людині просто не під силу проаналізувати їх самостійно, хоча необхідність проведення такого аналізу цілком очевидна, адже в цих „сирих даних” укладені знання, які можуть бути використані при прийнятті рішень.
Саме тому завдання фільтрації даних є актуальною науково-технічною задачею, що вимагає розробки сучасних підходів до її вирішення.
1.1 Мета і завдання дослідження
Об'єктом дослідження є обробка даних в системах розпізнавання.
Предметом дослідження – алгоритм побудови зважених навчальних вибірок.
Метою випускної роботи магістра є розробка та дослідження алгоритму побудови навчальних вибірок на основі методів кластеризації даних.
У процесі роботи необхідно вирішити наступні задачи:
- дослідження методів вирішення завдань розпізнавання;
- дослідження існуючих алгоритмів побудови вибірок;
- дослідження методів кластеризації даних;
- розробка алгоритму побудови зважених навчальних вибірок на основі обраного методу;
- розробка програмної системи.
1.2 Передбачувана наукова новизна
Науковою новизною даної роботи є розробка алгоритму побудови зважених навчальних вибірок на основі методів кластеризації даних – нового напрямку в передобробці навчальних вибірок великого обсягу.
1.3 Практична важливість
Практична значимість даної роботи полягає в розробці методу фільтрації даних (на основі кластеризації), що дозволяє підвищити якість вихідних даних і, як наслідок, ефективність роботи всієї системи в цілому.
Створення реальної системи побудови зважених навчальних вибірок, тестування і контроль якості їх функціонування.
2. Огляд досліджень і розробок
На глобальному рівні з проблеми розпізнавання проведено значну кількість досліджень, представлене роботами ряду таких фахівців як: Айзерман М.А. [1], Вайнцвайг М.Н. [2] та інші зарубіжні фахівці.
На національному рівні задача побудови автоматичних систем розпізнавання є однією з головних напрямів прикладної математики та інформатики. За останні 50 років було створено значну кількість методів і алгоритмів розпізнавання, класифікацію яких можна знайти в роботах Васильєва В.І. [3], Загогуйко М.Г. [4].
На локальному рівні, в межах ДонНТУ, наукові розробки в цій області ведуть д.т.н., доц. Волченко Є.В. [5-6], а так само магістри 2012 випуску: Кузьменко І.Ю. [7] та Шкарпеткіна Ю.Г. [8]
3. Методи рішення задач розпізнавання
Для побудови вирішальних правил потрібна навчальна вибірка. Навчальна вибірка – це безліч об'єктів, заданих значеннями ознак і приналежність яких до того чи іншого класу достовірно відома „вчителю” і повідомляється вчителем навчальній системі. За навчальною вибіркою система будує вирішальні правила. Якість вирішальних правил оцінюється за контрольною (екзаменаційною) вибіркою, в яку входять об'єкти, задані значеннями ознак, і приналежність яких тому чи іншому способу відома тільки вчителю. Пред'являючи навченою системі для контрольного розпізнавання об'єкти екзаменаційної вибірки, вчитель в змозі дати оцінку ймовірностей помилок розпізнавання, тобто оцінити якість навчання. До навчальної та контрольної вибірках пред'являються певні вимоги. Наприклад, важливо, щоб об'єкти екзаменаційної вибірки не входили в навчальну вибірку (іноді, правда, це вимога порушується, якщо загальний обсяг вибірок малий і збільшити його або неможливо, або надзвичайно складно).
Навчальна та екзаменаційна вибірки повинні достатньо повно представляти генеральну сукупність (гіпотетичне безліч всіх можливих об'єктів кожного образу).
Отже, для побудови вирішальних правил системи пред'являються об'єкти, що входять в навчальну вибірку.
3.1 Метод побудови еталонів
Для кожного класу по навчальній вибірці будується еталон, який має значення ознак:
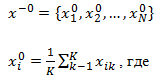
k – кількість об'єктів даного образу в навчальній вибірці,
i – номер ознаки.
По суті, еталон – це усереднений по навчальній вибірці абстрактний об'єкт (мал. 3.1). Абстрактним ми його називаємо тому, що він може не збігатися не тільки ні з одним об'єктом навчальної вибірки, а й ні з одним об'єктом генеральної сукупності.
Розпізнавання здійснюється наступним чином. На вхід системи надходить об'єкт
 ,
належність якого до того чи іншого образу системі невідома. Від цього об'єкта вимірюються відстані до еталонів всіх образів, і система відносить до того образу, відстань до еталона якого мінімально. Відстань вимірюється в тій метриці, яка введена для вирішення певної задачі розпізнавання.
,
належність якого до того чи іншого образу системі невідома. Від цього об'єкта вимірюються відстані до еталонів всіх образів, і система відносить до того образу, відстань до еталона якого мінімально. Відстань вимірюється в тій метриці, яка введена для вирішення певної задачі розпізнавання.

Малюнок 3.1 – Побудова еталонів
3.2 Метод потенційних функцій
Назва методу в певній мірі пов'язане з наступною аналогією (для простоти будемо вважати, що розпізнається два образу).
Уявімо собі, що об'єкти є точками  деякого простору X. У ці точки будемо розміщати заряди + qj, якщо об'єкт належить образу s1, и – qj, якщо об'єкт належить образу s2 (мал. 3.2).
деякого простору X. У ці точки будемо розміщати заряди + qj, якщо об'єкт належить образу s1, и – qj, якщо об'єкт належить образу s2 (мал. 3.2).

Малюнок 3.2 – Ілюстрація синтезу потенційної функції в процесі навчання
-----------
– потенційна функція, породжувана одиночним об'єктом;
––––––– – умарна потенційна функція, породжена навчальною послідовністю.
Функцію, що описує розподіл електростатичного потенціалу в такому полі, можна використовувати в якості вирішального правила (або для його побудови). Якщо потенціал точки  ,
створюваний одиничним зарядом, які у , дорівнює
,
створюваний одиничним зарядом, які у , дорівнює 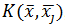 , то загальний потенціал в , створюваний n зарядами, дорівнює
, то загальний потенціал в , створюваний n зарядами, дорівнює
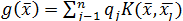
– потенційна функція. Вона, як у фізиці, убуває з ростом евклидової відстані між і . Найчастіше в якості потенційної використовується функція, що має максимум при = і монотонно спадаючий до нуля при 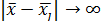 .
.
Розпізнавання може здійснюватися таким способом. У точці , де знаходиться непізнаний об'єкт, обчислюється потенціал g(). Якщо він виявляється позитивним, то об'єкт відносять до образу s1. Якщо негативним – до образу s2.
При великому обсязі навчальної вибірки ці обчислення досить громіздкі, і частіше вигідніше вираховують не g(), а оцінювати поділяючу класи (образи) кордон або апроксимувати потенційне поле.
Вибір виду потенційних функцій – справа непроста. Наприклад, якщо вони дуже швидко зменшуються з зростанням відстані, то можна домогтися безпомилкового поділу навчальних вибірок. Однак при цьому виникають певні неприємності при розпізнаванні непізнаних об'єктів (знижується достовірність прийнятого рішення, зростає зона невизначеності). При занадто „пологих” потенційних функціях може необгрунтовано збільшитися кількість помилок розпізнавання, в тому числі і на навчальних об'єктах.
3.3 Кластерний аналіз
Кластерний аналіз (самонавчання, навчання без вчителя, таксономія) застосовується при автоматичному формуванні переліку образів по навчальній вибірці. Всі об'єкти цієї вибірки пред'являються системі без вказівки, якого образа вони належать. Подібного роду завдання вирішує, наприклад, людина в процесі природно-наукового пізнання навколишнього світу. Цей досвід доцільно використовувати при створенні відповідних алгоритмів.
В основі кластерного аналізу лежить гіпотеза компактності. Передбачається, що навчальна вибірка в просторі ознак складається з набору згустків (подібно галактикам у Всесвіті). Завдання системи – виявити та формалізовано описати ці згустки. Геометрична інтерпретація гіпотези компактності полягає в наступному.
Об'єкти, що відносяться до одного таксону, розташовані близько один до одного в порівнянні з об'єктами, які належать до різних таксонів. „Близькість” можна розуміти ширше, ніж при геометричній інтерпретації. Наприклад, закономірність, що описує взаємозв'язок об'єктів одного таксона, відрізняється від такої в інших таксонах, як це має місце в лінгвістичних методах.
4. Огляд методів кластеризації даних
Кластеризація (або кластерний аналіз) – це завдання розбиття множини об'єктів на групи, названі кластерами. Усередині кожної групи повинні виявитися „схожі” об'єкти, а об'єкти різних груп повинні бути як можна більш відмінні. Головна відмінність кластеризації від класифікації полягає в тому, що перелік груп чітко не заданий і визначається в процесі роботи алгоритму..
Застосування кластерного аналізу в загальному вигляді зводиться до наступних етапів:
– відбір вибірки об'єктів для кластеризації;
– визначення безлічі змінних, за якими будуть оцінюватися об'єкти у вибірці. При необхідності – нормалізація значень змінних;
– обчислення значень міри схожості між об'єктами;
– застосування методу кластерного аналізу для створення груп схожих об'єктів (кластерів);
– представлення результатів аналізу.
Після отримання та аналізу результатів можливе корегування обраної метрики і методу кластеризації до отримання оптимального результату.
4.1 Алгоритм CURE (Clustering Using REpresentatives)
При ієрархічній кластеризації виконується послідовне об'єднання менших кластерів у великі чи поділ великих кластерів на менші [9].
Агломеративного група методів характеризується послідовним об'єднанням вихідних елементів і відповідним зменшенням числа кластерів. На початку роботи алгоритму всі об'єкти є окремими кластерами. На першому кроці найбільш схожі об'єкти об'єднуються в кластер. На наступних кроках об'єднання продовжується до тих пір, поки всі об'єкти не будуть складати один кластер.
Алгоритм CURE виконує ієрархічну кластеризацію з використанням набору визначальних точок для визначення об'єкта в кластер. Призначення: кластеризація дуже великих наборів числових даних. Обмеження: ефективний для даних низької розмірності, працює тільки на числових даних. Переваги: виконує кластеризацію на високому рівні навіть за наявності викидів, виділяє кластери складної форми і різних розмірів, володіє лінійно залежними вимогами до місця зберігання даних і тимчасову складність для даних високої розмірності. Недоліки: є необхідність у завданні порогових значень і кількості кластерів.
Опис алгоритму [11]:
Крок 1. Побудова дерева кластерів, що складається з кожного рядка вхідного набору даних.
Крок 2. Формування „купи” в оперативній пам'яті, розрахунок відстані до найближчого кластера (рядки даних) для кожного кластеру. При формуванні купи кластери сортуються за зростанням дистанції від кластера до найближчого кластера. Відстань між кластерами визначається за двома найближчим елементам з сусідніх кластерів. Для визначення відстані між кластерами використовуються „манхеттенськая”, „евкілдова” метрики або схожі на них функції.
Крок 3. Злиття ближніх кластерів в один кластер. Новий кластер отримує всі крапки вхідних даних, які до нього входять. Розрахунок відстані до інших кластерів для новоствореного кластеру. Для розрахунку відстані кластери діляться на дві групи: перша група – кластери, у яких найближчими кластерами вважаються кластери, що входять до новоствореного кластеру, решта кластери – друга група. І при цьому для кластерів з першої групи, якщо відстань до новоствореного кластеру менше ніж до попереднього найближчого кластера, то найближчий кластер змінюється на новостворений кластер. В іншому випадку шукається новий найближчий кластер, але при цьому не беруться кластери, відстані до яких більше, ніж до новоствореного кластеру. Для кластерів другої групи виконується наступне: якщо відстань до новоствореного кластеру ближче, ніж попередній найближчий кластер, то найближчий кластер змінюється. В іншому випадку нічого не відбувається.
Крок 4. Перехід на крок 3, якщо не отримано необхідну кількість кластерів.
4.2 Алгоритм BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
Дівізімная група методів характеризується послідовним поділом вихідного кластера, що складається з усіх об'єктів, і відповідним збільшенням числа кластерів. На початку роботи алгоритму всі об'єкти належать одному кластеру, який на наступних кроках ділиться на менші кластери, в результаті утворюється послідовність розщеплюють груп.
У цьому алгоритмі передбачено двоетапний процес кластеризації.
Призначення: кластеризація дуже великих наборів числових даних. Обмеження: робота тільки з числовими даними. Переваги: двоступнева кластеризація, кластеризація великих обсягів даних, працює на обмеженому обсязі пам'яті, є локальним алгоритмом, може працювати при одному скануванні вхідного набору даних, використовує той факт, що дані неоднаково розподілені по простору, і обробляє області з великою щільністю як єдиний кластер. Недоліки: робота тільки з числовими даними, добре виділяє тільки кластери сферичної форми, є необхідність в завданні порогових значень.
Опис алгоритму [12]:
Фаза 1. Завантаження даних в пам'ять.
Побудова початкового кластерного дерева (CF Tree) за даними (перше сканування набору даних) у пам'яті.
Підфази основної фази відбуваються швидко, точно, практично нечутливі до порядку.
Алгоритм побудови кластерного дерева (CF Tree):
Кластерний елемент представляє з себе трійку чисел (N, LS, SS), де N – кількість елементів вхідних даних, що входять в кластер, LS – сума елементів вхідних даних, SS – сума квадратів елементів вхідних даних.
Кластерне дерево – це виважено збалансоване дерево з двома параметрами: B – коефіцієнт розгалуження, T – порогова величина. Кожен нелістьевой вузол дерева має не більше ніж B входжень вузлів наступної форми: [CFi, Childi], де i = 1, 2, …, B; Childi – показник на i-й дочірній вузол.
Кожен листовий вузол має посилання на два сусідніх вузла. Кластер складається з елементів листьєва вузла повинен задовольняти наступній умові: діаметр або радіус отриманого кластера повинен бути не більше порогової величини T.
Фаза 2 (необов'язкова). Стиснення (ущільнення) даних.
Стиснення даних до прийнятних розмірів за допомогою перестроювання і зменшення кластерного дерева з збільшенням порогової величини T.
Фаза 3. Глобальна кластеризація.
Застосовується вибраний алгоритм кластеризації на Лістьєва компонентах кластерного дерева.
Фаза 4 (необов'язкова). Поліпшення кластерів.
Використовує центри тяжкості кластерів, отримані у фазі 3, як основи.
Перерозподіляє дані між „близькими” кластерами. Дана фаза гарантує попадання однакових даних в один кластер.
4.3 Алгоритм MST (Algorithm based on Minimum Spanning Trees)
Призначення: кластеризація великих наборів довільних даних.
Переваги: виділяє кластери довільної форми, окремо кластери опуклою і впуклим форми, вибирає з кількох оптимальних рішень найоптимальніше.
Опис алгоритму [13]
Крок 1. Побудова мінімального остівного дерева:
Зв'язний, неорієнтовані граф з вагами на ребрах G(V, E), в якому V – безліч вершин (контактів), а E – безліч їх можливих попарних з'єднань (ребер), для кожного ребра (u, v) однозначно визначено деякий дійсне число w (u, v) — його вага (довжина або вартість з'єднання).
Алгоритм Борувки:
1. Для кожної вершини графа находиме ребро з мінімальною вагою.
2. Додаємо знайдені ребра до кістяка, за умови їх безпеки.
3. Знаходимо і додаємо безпечні ребра для незв'язаних вершин до остовного дерева.
4. Загальний час роботи алгоритму: O(ELogV).
Алгоритм Крускала:
1. Обхід ребер по зростанню ваг. За умови безпеки ребра додаємо його до основного дереву.
2. Общее час роботи алгоритму: O(ELogE).
Алгоритм Пріма:
1. Вибор кореневої вершини.
2. Начіная з кореня додаємо безпечні ребра до остовного дерева.
Загальний час роботи алгоритму: O(ELogV).
Крок 2. Поділ на кластери. Дуги з найбільшими вагами поділяють кластери. Принцип роботи описаних вище груп методів у вигляді дендрограмми зображений на мал. 4.1
")
Малюнок 4.1 – Дендограмма роботи агломеративного та дівізімних методів (анімація: 10 кадрів, 5 циклів повторення, 106 кілобайт)
4.4 Алгоритм k-середніх (k-means)
Найбільш поширений серед неієрархічних методів алгоритм k-середніх, також званий швидким кластерним аналізом. Повний опис алгоритму можна знайти в роботі Хартігана і Вонга (Hartigan and Wong, 1978). На відміну від ієрархічних методів, що не вимагають попередніх припущень щодо числа кластерів, для можливості використання цього методу необхідно мати гіпотезу про найбільш ймовірного кількості кластерів.
Алгоритм k-середніх будує k кластерів, розташованих на можливо великих відстанях один від одного. Основний тип завдань, які вирішує алгоритм k-середніх – наявність припущень (гіпотез) щодо числа кластерів, при цьому вони повинні бути різні настільки, наскільки це можливо. Вибір числа k може базуватися на результатах попередніх досліджень, теоретичних міркуваннях або інтуїції.
Загальна ідея алгоритму: задане фіксоване число k кластерів спостереження співставляються кластерам так, що середні в кластері (для всіх змінних) максимально можливо відрізняються один від одного.
Опис алгоритму:
1. Початковий розподіл об'єктів по кластерах. Вибирається число k, і на першому кроці ці точки вважаються „центрами” кластерів. Кожному кластеру відповідає один центр.
Вибір початкових центроїдів може здійснюватися таким чином:
– вибір k-спостережень для максимізації початкової відстані;
– випадковий вибір k-спостережень;
– вибір перших k-спостережень.
У результаті кожен об'єкт призначений певному кластеру.
2. Ітератівний процес.
Обчислюються центри кластерів, якими потім і далі вважаються покоординатні середні кластерів. Об'єкти знову перерозподіляються.
Процес обчислення центрів і перерозподілу об'єктів продовжується до тих пір, поки не виконана одна з умов:
– кластерні центри стабілізувалися, тобто всі спостереження належать кластеру, якому належали до поточної ітерації;
– число ітерацій дорівнює максимальному числу ітерацій.
На мал.4.2 наведено приклад роботи алгоритму k-середніх для k, рівного двом.

Малюнок 4.2 – Приклад
роботы алгоритму k-середніх (k=2)
Вибір числа кластерів є складним питанням. Якщо немає припущень щодо цього числа, рекомендують створити 2 кластера, потім 3, 4, 5 і т.д., порівнюючи отримані результати.
Після отримання результатів кластерного аналізу методом k-середніх слід перевірити правильність кластеризації (тобто оцінити, наскільки кластери відрізняються один від одного). Для цього розраховуються середні значення для кожного кластера. При гарній кластеризації повинні бути отримані сильно відрізняються середні для всіх вимірювань або хоча б більшої їх частини.
Переваги алгоритму k-середніх:
– простота використання;
– швидкість використання;
– зрозумілість і прозорість алгоритму.
Недоліки алгоритму k-середніх:
– алгоритм занадто чутливий до викидів, які можуть спотворювати середнє. Можливим вирішенням цієї проблеми є використання модифікації алгоритму – алгоритму k-медіани;
– алгоритм може повільно працювати на великих базах даних. Можливим вирішенням даної проблеми є використання вибірки даних.
Висновки
У ході роботи були розглянуті методи для побудови зважених навчальних вибірок. Були розглянуті основні методи кластеризації даних. Встановлено, що за останні роки були розроблені різні методи предобработки даних. Було відзначено, що за великої кількості вихідних даних, важливе значення відіграє попередня обробка інформації.
За результатами проведеного аналізу в якості об'єкта дослідження обрана задача побудови зважених навчальних вибірок.
Перелік посилань
- Айзерман М.А., Браверман Э.М., Глушков В.М. и др. Теория распознавания образов и обучающих систем. – Изв. АН СССР, Техническая кибернетика № 5, 1963, с. 98-101.
- Вайнцвайг М.Н. Алгоритм обучения распознавания образов «Кора». В сб.: Алгоритмы обучения распознавания образов. – М.: 1972, с. 110-116.
- Васильев В.И. Распознающие системы: Справочник. / В.И. Васильев – К.: Наукова думка, 1983. – 423 с.
- Загоруйко Н.Г. Прикладные методы анализа знаний и данных / Н.Г. Загоруйко. – Новосибирск: Издательство института математики, 1999. – 270 с.
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету «Харківський політехнічний інститут». Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ «ХПІ», 2011. – № 36. – С. 12-22.
- Волченко Е.В. Модифицированный метод потенциальных функций / Е.В. Волченко II Бионика интеллекта. – 2006. – № 1 (64). – С. 86-92.
- Волченко Е. В., Кузьменко И. Ю. Анализ методов нахождения выбросов в обучающих выборках / Харьковский Политехнический Институт // Материалы ХI Международной научно-технической конференции/ Секция «Молодые ученые«. – Харьков, ХПИ – 2011, , с. 12-13.
- Автореферат магистерской работы Шкарпеткина Ю.Г. «Исследование и разработка метода заполнения пропусков в взвешенных обучающих выборках данных» [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2012/iii/shkarpetkina/diss/index.htm
- Чубукова И.А. Data Mining. Учебное пособие. – М.: Интернет-Университет Информационных технологий; БИНОМ. Лаборатория знаний, 2006. – 382 с.: ил., табл. – (Серия «Основы информационных технологий»)
- Паклин Н. «Кластеризация категорийных данных: масштабируемый алгоритм CLOPE». [Электронный ресурс]. – Режим доступа: http://www.basegroup.ru/clusterization/clope.htm
- Sudipto Guha, Rajeev Rastogi, Kyuseok Shim «CURE: An Efficient Clustering Algorithm for Large Databases». Proceedings of the 1998 ACM SIGMOD international conference on Management of data pp.. 73-84
- Tian Zhang, Raghu Ramakrishnan, Miron Livny «BIRCH: An Efficient Data Clustering Method for Very Large Databases». Proceedings of the 1996 ACM SIGMOD international conference on Management of data pp. 103-114
- Daniel Fasulo «An Analysis Of Recent Work on Clustering Algorithms». [Электронный ресурс]. – Режим доступа: http://logic.pdmi.ras.ru/ics/papers/aca.pdf
- Паклин Н. «Алгоритмы кластеризации на службе Data Mining». [Электронный ресурс]. – Режим доступа: http://www.basegroup.ru/clusterization/datamining.htm
Важливе зауваження
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: січень 2013. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.