A PARALLEL IMPLEMENTATION OF THE INTERSECTION STAGE OF RAY-TRACING ALGORITHM
Author: Khalygov A.A., Ahmed Djamil, Malcheva R.V.
Источник: Информатика і комп’ютерні технології» Збірка праць VIII міжнародної науково-технічної конференції студентів, аспірантів та молодих учених. 18-19 вересня 2012 р. стор. 201-204
Intersection stage
Parameter t for polygonal model has to be calculated as relation of dividend (dev) to devisor (div)
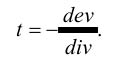
To calculate devisor — scalar product of viewpoint vector to normal vector of a plane:
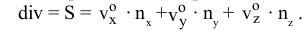
To calculate parameter d for a plane equation
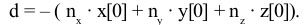
To calculate dividend:
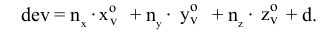
That is why an elementary performing block (EBL) has to realize a multiplication
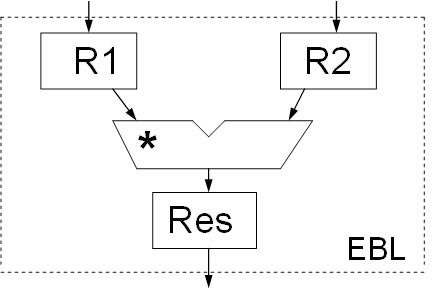
Figure 1. Functional organization of an elementary performing block
Looking to the 1st equation of the system (fig. 1), it needs realization of 3 multiplications and then 3 additions (fig. 2).
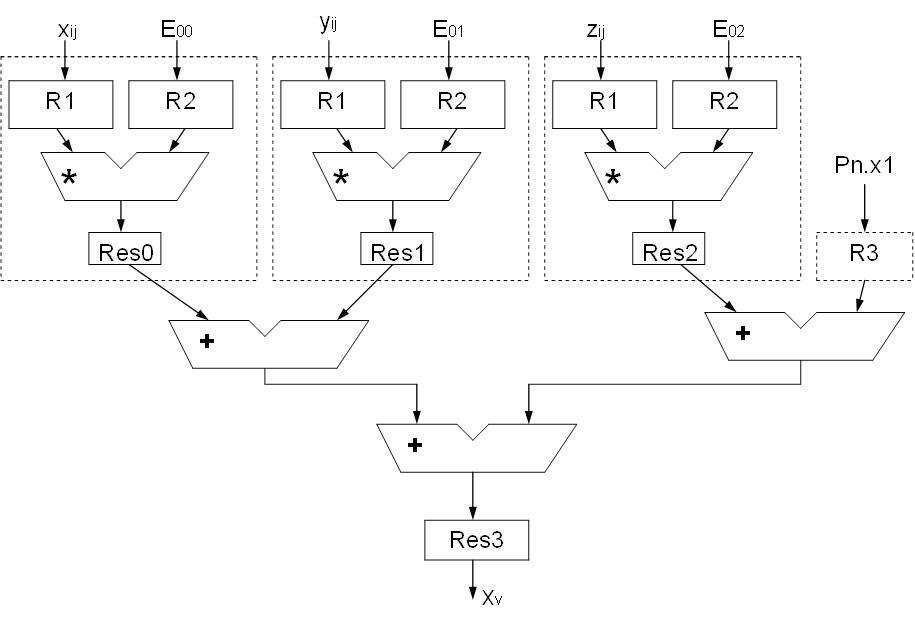
Figure 2. Functional organization of a performing block to calculate X-coordinate of point
Realization of intersection stage by applying of the main performing block.
Looking to the system (fig. 2), we can see that x, y and z coordinates are uncorrelated and can be calculated in parallel (fig. 3).
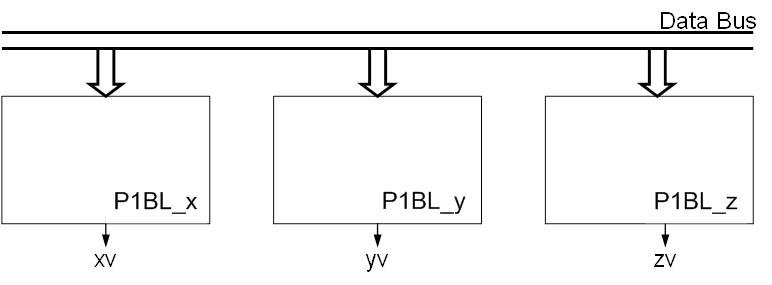
Figure 3. Parallel realization of the system
Application of the main processing block P1BL allows to realize 3 multiplications in parallel. In this case time of 3 multiplications will be equal to 1 tm or 4 processing loops. Application of 3 processing block P1BL in parallel allows to realize 9 multiplications in parallel. In this case time of 9 multiplications will be equal to 1 tm or 4 processing loops. izations.
Table 1. Comparing of processing loops for sequential and parallel realizations
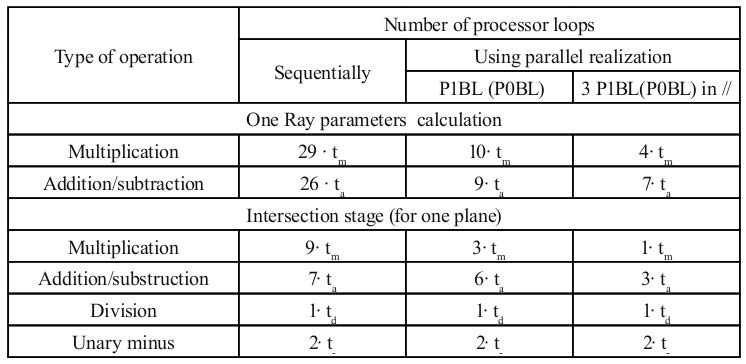
Table 1 shows decreasing of processing loops for parallel realizations for scenes’ complexity from 100 up to 1000 planes. Application of the main processing block P1BL to realize 3 multiplications in parallel reduces processing time by 46,4%.
Application of 3 processing block P1BL in parallel to realize 9 multiplications in parallel reduces processing time by 66,8%.
Table 2. Numbers of processing loops for sequential execution and for parallel realizations for scenes’ complexity from 100 up to 1000 planes
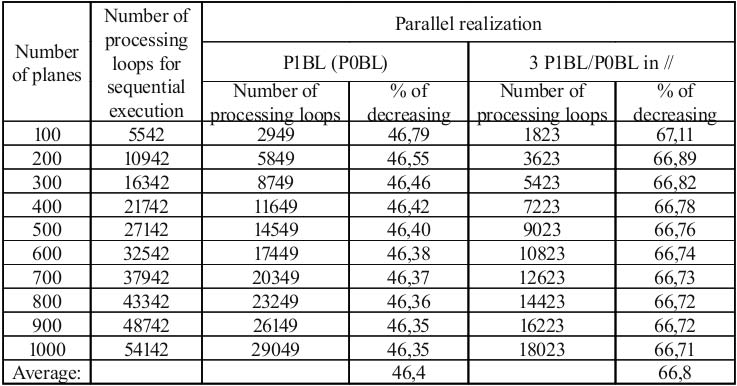
Figure 4 shows diagrams — comparing of processing loops for sequential and parallel realizations.
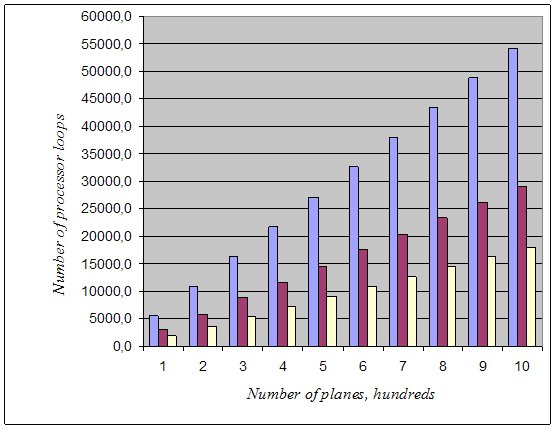
Figure 4. Comparing of processing loops for sequential and parallel realizations
Summaries
To improve system performance the parallel realization of intersection stage is proposed. For this aim structure of an elemental block is used. The main performing block are developed. Implementations of the systems and expressions show that minimum processor unit has to construct 3 parallel performing block P1BL with reconfigurable structure.Application of the main processing block P1BL to realize 3 multiplications in parallel reduces processing time by 46,4%. Application of 3 processing block P1BL in parallel to realize 9 multiplications in parallel reduces processing time by 66,8%.
References
- Foley, James D. Computer Graphics: Principles and Practice. Reading, Mass.: Addison-Wesley, 1990.
- Glassner, Andrew S. An Introduction to Ray-Tracing. San Diego: Academic, 1989.
- Hearn, Donald. Computer Graphics. EngleWood Cliffs, N.J.: Prentice-Hall, 1994.
- Rogers, David. Techniques for Computer Graphics. New York: Springer-Verlag, 1987.
- Watt, Alan. Advanced Animation and Rendering Techniques. New York, N.Y.: ACM Press, 1992.
- Watt, Alan. Fundamentals of Three-Dimensional Computer Graphics. Reading, Mass.: Addison-Wesley, 1989.
- Мальчева Р.В., Мохаммад Юнис. Применение строчной межпиксельной интерполяции для ускорения трассирования лучей // Материалы двенадцатого международного научно-практического семинара «Практика и перспективы развития партнерства в сфере высшей школы».–Донецк: ДонНТУ, 2011.–№12.Кн.2.-C.72-74.
- Мальчева Р.В., Ковалев С.А., Мохаммад Юнис. Применение блочной межпиксельной интерполяции для ускорения трассирования лучей // Материалы ХVIII МНТК «Машиностроение и техносфера ХХI века». – Донецк, 2011. – Т. 2. – С.189-191.
- Мальчева Р.В. Исследование влияния шага трассирования лучей и коэффициента различия в цвете на время выполнения формирования изображения / Р.В. Мальчева, М. Юнис, А. Джамиль // Наукові праці Донецького національного технічного університету. Серія «Інформатика, кібернетика та обчислювальна техніка». – Донецьк: ДонНТУ, 2011. – Вип. 14(188). – C. 195-201.