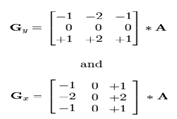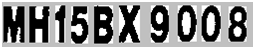Аннотация
В этом исследовании представлен интеллектуальный и простой алгоритм для системы распознавания номерного знака транспортного средства. Предложенный алгоритм состоит из трех главных частей: извлечение области пластины, сегментация символов и распознавание символов пластины. Для извлечения области пластины используются обнаружение границ и морфологические операции. В сегментации используется алгоритм строки развертки. Сегментация символов также представлена для номерных знаков деванагари. Оптическое распознавание символов используется для распознавания символов. Цель состоит в том, чтобы спроектировать эффективную автоматическую санкционированную идентификационную систему транспортного средства при помощи номерной пластины транспортного средства.
Ключевые слова: деванагари, обнаружение границ, распознавание номерного знака, оптическое распознавание символов, сегментация.
1. Введение
Распознавание номерного знака (LPR) является формой автоматической идентификации транспортного средства. Это технология обработки изображения используется, чтобы идентифицировать транспортные средства только по их номерным знакам. В режиме реального времени LPR играет главную роль в автоматическом контроле правил дорожного движения и поддержании правопорядка на общественных дорогах. Существенное преимущество системы LPR состоит в том, что система может вести видеозапись транспортного средства, что полезно для того, чтобы бороться с преступлением и мошенничеством ("изображение стоит тысячи слов"). Ранние системы LPR страдали от низкой скорости распознавания, ниже, чем необходимые практические системы. Внешние эффекты (солнце и фары, плохие пластины, большое число типов пластины), ограниченный уровень программного обеспечения распознавания и аппаратные средства видения привели к низкокачественным системам. Однако недавние улучшения программного и аппаратного обеспечения сделали системы LPR более надежными и широко распространенными.
Здесь мы представляем умный и простой алгоритм для системы распознавания номерного знака транспортного средства для индийских транспортных средств. В этом исследовании предложенный алгоритм основан на извлечении области пластины, сегментации символов пластины и распознавании символов. В Индии встречаются также пластины, имеющие шрифты деванагари (хотя согласно правилам это не разрешено). Символьное извлечение для шрифта деванагари немного отличается по сравнению с английским шрифтом из-за линии заголовка. Мы предлагаем алгоритм символьного извлечения для шрифта Деванагари. Распознанная пластина может сравниваться с базой данных полиции, чтобы идентифицировать украденные транспортные средства.
Статья организована следующим образом: раздел II содержит обзор системы в целом. Извлечение пластины области объясняется в разделе III. Раздел IV показывает сегментацию отдельных символов пластины. Раздел V посвящен распознаванию символов с помощью оптического распознавания символов, основанного на статистическом алгоритме соответствия шаблона, который использует корреляцию. Раздел VI рассматривает проверку пластины в соответствии индийским правилам. Статью завершает раздел VII.
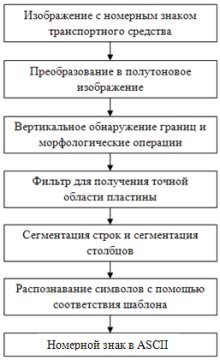
2. Структура LPR системы
Рисунок 1 – Cхема предложенной системы
Алгоритм, предложенный в этой статье, разработан для распознавания номерных знаков транспортных средств автоматически. Входными данными системы является изображение транспортного средства, захваченное камерой. Захваченное изображение, взятое с 3-5 метров сначала преобразуется в полутоновое. Применяем алгоритм вертикального обнаружения границ и морфологическую операцию, открытый и близкий для извлечения пластины. После применения морфологических операций изображение отфильтровывается, чтобы получить точную область пластины. Область пластины подрезана. Сегментация строк отделяет строку в пластине, и разделение столбца отделяет символы из строки. В конце концов распознавание OCR распознает символы, дающие результат как номерной знак в формате ASCII. Результат в формате ASCII может быть проверен на основе соблюдаемых правил в Индии.
3. Извлечение области пластины
Извлечение пластины осуществляется в следующих этапах:
- Преобразование изображения в градациях серого
- Применение вертикального обнаружения границ
- Обнаружение области пластины кандидата:
- морфологически закрытое изображение;
- заполнение отверстий в изображении;
- морфологически открытое изображение;
- Фильтрация не области пластины.
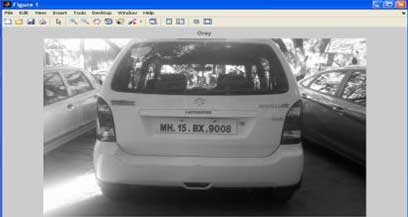
3.1 Преобразование изображения в градациях серого
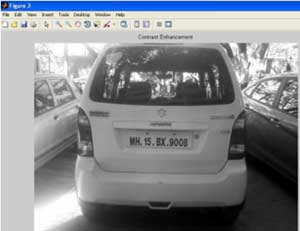
Это этап предварительной обработки для извлечения пластины. Применяем формулу: I(i, j) = 0.114*A( i, j,1) + 0.587*A(i, j, 2) + 0.299* A(i, j,3), где I(i,j) является массивом серого изображения, A(i,j,1), A(i,j,2), A(i,j,3) – R, G, B значения исходного изображения соответственно. Иногда изображение может быть слишком темным, содержать размытие, таким образом, делая задачу извлечения номерного знака трудной. Для того, чтобы распознать номерной знак даже в ночных условиях, улучшение контрастности важно перед дальнейшей обработкой [1].
Рисунок 2 – Исходное изображение
Рисунок 3 – Полутоновое изображение
Рисунок 4 – Полутоновое изображение после улучшения контрастности
3.2 Применение вертикального обнаружения границ
Перед применением обнаружения границ должен быть применен медианный фильтр к изображению для удаления шума. Основная идея медианного фильтра состоит в том, чтобы пробегать через сигнал, вход за входом, заменяя каждый вход медианой соседних входов. Такое шумоподавление является типичным шагом предварительной обработки по улучшению результатов последующей обработки (обнаружения границ) [2].
В порядке возрастания значений: 0, 2, 3, 3, 4, 6, 10, 15, 97. Центральное значение (предварительно 97) заменяется медианой всех девяти значений (4).
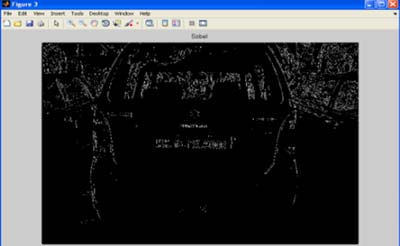
Обнаружения границ осуществляется на данном изображении, направленно на определение точек в цифровом изображении, на котором яркость изображения изменяется резко или, более формально, имеет неоднородности. Существует, главным образом, несколько методов обнаружения границ (фильтры Собеля, Прюитта, Робертса, Кенни). Используем здесь оператор Собеля для вертикального обнаружения границ.
Если мы определяем А в качестве источника изображения и Gx и Gy – два изображения, которые в каждой точке содержат горизонтальные и вертикальные производные приближений, вычисления следующие:
Где * 2D операции свертки.
Рисунок 5 – Вертикальное обнаружение границ Собеля
3.3 Обнаружение области пластины кандидата
Морфологический оператор применяется к изображению для определения местоположения пластины. Строим морфологический оператор, который чувствителен к определенной форме во входном изображении. В нашей системе используется прямоугольник в качестве структурного элемента обнаружения автомобильных пластин. В математической морфологии структурные элементы представлены в качестве матриц. Структурный элемент является характеристикой определенной структуры и функции для измерения формы изображения и используется, чтобы выполнить другие операции по обработке изображений [4]. Типичный прямоугольный структурный элемент показан на рисунке 6.
Рисунок 6 – А 2*5 «прямоугольный» структурный элемент
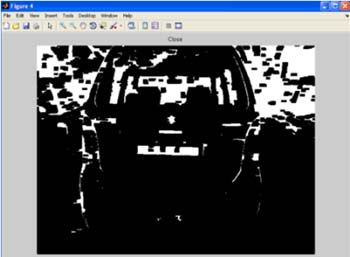
С помощью двух основных операций морфологии (эрозии и расширения), осуществлено размыкание и замыкание изображения. Размыкание А на B является полученное эрозией А на B, а затем расширение полученного изображения В. Замыкание А на B получают расширением А на В, с последующей эрозией полученной структуры B.
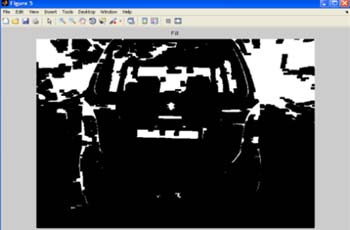
Для замыкания изображения используется 10 * 20 прямоугольный структурный элемент. После замыкания изображения нужно заполнить отверстия на этом изображении. Отверстие – набор фоновых пикселей, что не может быть достигнуто путем заполнения фона от края изображения [3]. Тогда изображение открыто с использованием 5 * 10 прямоугольного структурного элемента. Значения определяются в соответствии с размером изображения. Здесь мы использовали 1280X980 разрешение изображений.
Рисунок 7 – Замкнутое изображение
Рисунок 8 – Заполненное изображение
Рисунок 9 – Разомкнутое изображение
3.4 Фильтрация не области пластины
После определения области интереса (ROI) изображение затем фильтруется с помощью следующих методов фильтрации.
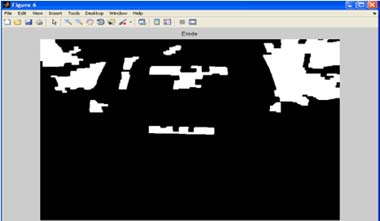
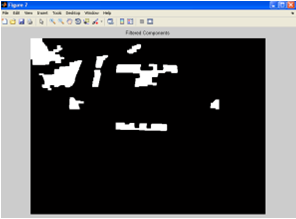
Сначала находим связные компоненты на изображении. Первый метод включает в себя удаление всех белых участков, которые в более или менее, чем пороговое значение. Например, устранены компоненты, имеющие площадь <2000 или> 20000.
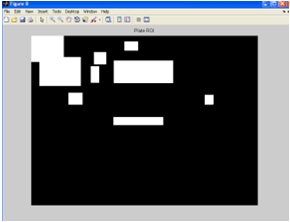
Использование метода ограничивающего прямоугольника, рисование ограничивающего прямоугольника вокруг компонентов и заполнение изображения.
В зависимости от значений высоты, например, только объекты с высотой более Tmin_h и менее Tmax_h сохраняются и исключаются другие объекты. После этого, если значения ширины сохраненных объектов больше Tmin_w и меньше Tmax_w, то объекты удерживаются, в противном случае, объекты будут удалены и так далее.
Где:
Tmin_h: Минимальная высота объекта.
Tmax_h: Максимальная высота объекта.
Tmin_w: Минимальная ширина объекта.
Tmax_w: максимальная ширина объекта [6].
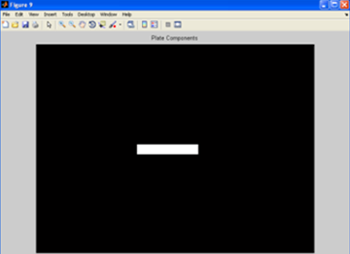
После фильтрации область пластины обрезается с помощью поиска первых и последних белых пикселей, начиная с верхнего левого угла изображения. Пластина, обрезается из исходного изображения после получения координат.
Рисунок 10 – Отфильтрованное изображение на основе области
Рисунок 11 – Ограничивающий прямоугольник и заполненное изображение
Рисунок 12 – Изображение после фильтрации на основе высоты и ширины объектов
Рисунок 13 – После горизонтальной обрезки
Рисунок 14 – После вертикальной обрезки: конечное изображение пластины
Если пластина не прямая, то символы не будут извлечены должным образом. Таким образом, изображение пластины должно быть повернуто, чтобы сделать его прямо. Для коррекции наклона мы используем свойство ориентации связанного компонента. Свойство ориентации возвращает угол, на который пластина повернута в противоположном направлении. Например, если угол возвращает свойство ориентации на 5 градусов, то изображение пластины должно быть повернуто на -5 градусов.
Рисунок 15 – Наклоненная пластина
Рисунок 16 – После коррекции наклона
4. Сегментация символов пластины
Перед применением OCR отдельные линии в тексте разделяются с помощью процесса разделения линии, и отдельные символы разделяются линиями. Шаги для сегментации символов:
- Бинаризация изображения пластины
- Алгоритм строки развертки для сегментации строк
- Вертикальная проекция для сегментации столбцов
4.1 Бинаризация изображения пластины
Бинаризация изображения пластины. Пороговое значение бинаризации должна быть таким, чтобы символы хорошо отображались. Для этого мы берем среднее значение всех значений пикселей в изображении пластины и определяем порог.
Рисунок 17 – Бинаризованное изображение
4.2 Алгоритм строки развертки для сегментации строк
Алгоритм строки развертки основан на особенности, что есть переход от 1 до 0 и 0 до 1 перехода в области символа на бинарном изображении. Таким образом, общее количество переходов в области символа больше, чем общее количество переходов в другой области. Существует, по крайней мере, семь символов на области номерного знака, и каждый символ имеет более, чем два прыжка [7]. Можно выбрать двенадцать в качестве порогового значения. Если общее количество переходов в определенной линии больше двенадцати, эта линия может быть в области символа. В противном случае, это не в области символа.
Алгоритм:
1) пусть Н – высота и W – ширина изображения пластины.
2) для (i=H/2 to 0)
{
не считаем переходов, т.е. от 0 до 1 и от 1 до 0 в cnt;
если cnt<12 получим координату у в ymin и прервем;
}
3) для (i=H/2+1 to H-1)
{
не считаем переходов, т.е. от 0 до 1 и от 1 до 0 в cnt;
если CNT <12 получим координату у в ymax и прервем;
}
4) обрезаем изображение от ymin до ymax.
Таким образом, получаем верхнюю и нижнюю границу пластины. Теперь можем сегментировать символы.
Рисунок 18 – После алгоритма строки развертки
4.4 Вертикальная проекция для сегментации столбцов
Просмотрим обрезанное изображение слева направо по столбцам после точного местоположения верхней и нижней границы и подсчитаем общее количество черных точек в каждом столбце. Пороговое значение установлено в h/10. Определим каждое значение в массиве проекции. Если проекция[i] больше, чем h/10, проекция[i] равна одному. В противном случае, проекция[i] устанавливается в ноль. Где h не модифицирует строки на бинарном изображении после точной локализации верхней и нижней границ [7]. Затем символы обрезаются путем выбора частей, имеющих проекцию[i] = 1.
Перед алгоритмом распознавания символы должны быть уточнены в блок, не содержащий дополнительные пробелы (пиксели) со всех четырех сторон символов.
Рисунок 19 – Сегментация символов для английского шрифта
Рисунок 20 – Символы после удаления лишних пробелов с четырех сторон
Рисунок 21 – Сегментация символов для шрифта деванагари
Как показано на рисунке 21 числа деванагари могут быть разделены с помощью вертикальной проекции, но из-за строки заголовка мы не можем отделить один символ из слова. Таким образом, приведем здесь алгоритм извлечения символа деванагари.
Рисунок 22 – Горизонтальная проекция слова деванагари и ширина заголовка
Рисунок 23 – После удаления строки заголовка
Рисунок 24 – Извлечение символов для шрифта деванагари
Алгоритм:
- Найти строку заголовка, находя горизонтальную проекцию слова, т.е. поиск строк с максимальными черными пикселями.
- Найти ширину заголовка.
- Удалить строку заголовка. После удаления заголовка наше слово делится на три горизонтальные части, известные как верхняя зона, средняя зона и нижняя зона.
- Применить вертикальную проекцию после удаления строки заголовка.
- Извлечь символы как в предыдущем алгоритме.
5. Распознавание символов
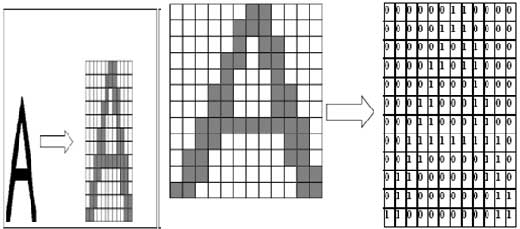
OCR в настоящее время используется для сравнения каждого отдельного символа с полной буквенно-цифровой базой данных, используя соответствие шаблона. Шаблон соответствия является одним из методов оптического распознавания символов [8]. Изображение преобразуется в битовый массив 12x12. Битовый массив представлен 12x12-матрицей или векторами 144 с 0 и 1 координатами.
Рисунок 25 – Битовый массив представлен матрицей 12х12
Изображение символа сравнивается с символами базы данных и находится лучшее сходство. OCR фактически использует метод корреляции, чтобы соответствовать отдельному символу.
Рисунок 26 – База данных символов
Этот процесс включает использование базы данных символов или шаблонов. Существует шаблон для всех возможных входных символов. Для распознавания текущий входной символ сравнивается с каждым шаблоном, чтобы найти или точное соответствие, или шаблон с ближайшим представлением ввода символа. Если I(x, y) является входным символом, Tn(х, у) является шаблоном n, то функция соответствия s(I, Tn) вернет значение, указывающее, насколько хорошо шаблон n соответствует входному символу. Некоторые более общие функции соответствия являются корреляцией на основе следующей формулы:
6. Проверка номерного знака
Таким образом, распознанный номерной знак может быть сохранен в массив и может быть проверен на основе правил, которым следуют в Индии [4]. В случае индийских номерных знаков, длина может быть 8, 9 или 10. Правила, соответствующие длинам номерного знака следующие:
- Если количество сегментированных символов насчитывается до 7, то номерной знак следует сериям 1939, имеющие первые три символа в виде букв и остаток в виде чисел.
- Если количество символов насчитывается до 8, то первые два символа должно быть буквами, а остальные должны быть числами.
- Если количество символов насчитывается до 9, то первый, второй и пятый символы должны быть буквы, а остальные должны быть числами.
- Если число сегментов насчитывается до 10, то первый, второй, пятый и шестой символы будут буквы, а остальные будут числа.
7. Заключение
В этой статье мы представили прикладное программное обеспечение, разработанное для распознавания автомобильных номерных знаков. Во-первых, мы извлекли локализацию пластины, а затем отделили символы пластины отдельно сегментацией и, наконец, применили шаблон согласования с использованием корреляции для распознавания символов пластины. Эта система предназначена для идентификации индийских номерных знаков и она протестирована на небольшом количестве изображений. Предложили алгоритм извлечения символов деванагари. В будущих исследованиях мы предложим алгоритм для сегментации символов и распознавания номерных знаков различных региональных языков.
8. Ссылки
1. Chirag N. Paunwala & Suprava Patnaik,”A Novel Multiple License Plate Extraction Technique for Complex Background in Indian Traffic Conditions”, International Journal of Image Processing (IJIP) Volume (4): Issue (2).
2. Ayesha Butalia, Durgesh Maru, Kuldeep Baheti, Avais Mohammad, Ankit Bagdiya, “Gray Eye Traffic Surveillance”, International Journal of Computer Trends and Technology- May to June Issue 2011.
3. Chetan Sharma1 and Amandeep Kaur ,“Indian Vehicle License Plate Extraction And Segmentation”, International Journal of Computer Science and Communication.
4. Phalgun Pandya, Mandeep Singh, “Morphology Based Approach To Recognize Number Plates in India”, International Journal of Soft Computing and Engineering (IJSCE) ISSN: 2231-2307, Volume-1, Issue-3, July 2011.
5. Muhammad Tahir Qadri, Muhammad Asif, “Automatic Number Plate Recognition System For Vehicle Identification Using Optical Character Recognition”, 2009 International Conference on Education Technology and Computer.
6. Kumar Parasuraman, and P.Vasantha Kumar “An Efficient Method for Indian Vehicle License Plate Extraction and Character Segmentation”, 2010 IEEE International Conference on Computational Intelligence and Computing Research.
7. Ch.Jaya Lakshmi, Dr.A.Jhansi Rani, Dr.K.Sri Ramakrishna, M.KantiKiran, “A Novel Approach for Indian License Plate Recognition System”, International Journal Of Advanced Engineering Sciences And Technologies Vol No. 6, Issue No. 1, 010 – 014.
8. Nadira Muda, Nik Kamariah Nik Ismail, Siti Azami Abu Bakar, Jasni Mohamad ZainFakulti Sistem Komputer & Kejuruteraan Perisian, “Optical Character Recognition By Using Template Matching (Alphabet)”.
9. Raghuraj Singh, C. S. Yadav, Prabhat Verma, Vibhash Yadav, “Optical Character Recognition (OCR) for Printed Devnagari Script Using Artificial Neural Network”, International Journal of Computer Science & Communication, January-June 2010.