Аннотация
F. Jesus Sanchez, Antonio Gonzalez Анализ локальности данных SPECfp95 Эта статья представляет собой подробный анализ локальности, основанный на наборе тестов SPECfp95. Это исследование выполняется с помощью инструмента, который основан на статическом анализе, повышенном за счет простого профилирования. Этот новый подход приводит к быстрым, точным и гибким инструментам анализа локальности данных. Это быстро, потому что расхода времени практически не заметно, имеется замедление 0,05. Кроме того, один запуск тестов может предоставить информацию для различных конфигураций кэша. Инструмент является точным, поскольку информация, которая неизвестна во время компиляции получается путем профилирования. Наконец, инструмент очень гибкий в том смысле, что он может обеспечить различные статистические данные о локальности в программе, также способен оценить различные кэш архитектуры.
Вступление
Штрафы памяти являются одной из основных причин, почему производительность компьютеров довольно ниже пиковой производительности для большинства приложений. Понимание источника проблемы является первым шагом на пути к разработке новой аппаратной организации и / или новых преобразований кода для их преодоления.
Рассмотрим схему современного многоядерного процессора, построенного на архитектуре SMP (Symmetric Multiprocessing)
Пользователь может быть заинтересован в количестве штрафов памяти, но этой информации в большинстве случаев не хватает. Более подробное объяснение различных причин этих штрафов иногда требуется для того, чтобы исследовать соответствующую оптимизацию. Примеры типа информации, в которой пользователь может быть заинтересован перечислены ниже:
- Классификация различных типов кэш-промахов в трех часто используемых категориях (обязательность, емкость, конфликтность) может быть важна в выборе различных типов оптимизации. Емкостные промахи могут быть наилучшим образом ослаблены за счет блокирования [5] [3]; конфликтные промахи за счет заполнения [13]; обязательные промахи с помощью предварительной выборки [2] [11], среди других возможностей.
- Определение частей программы, которые отвечают за большинство штрафов может помочь уменьшить усилия на оптимизацию, сосредоточив внимание на таких случаях.
- Конфликтные промахи являются доминирующим типом промахов для многих численных приложений. Определение того, какие структуры данных несут ответственность за эти конфликты может потребоваться для того, чтобы устранить их с помощью заполнения [13] или копирования [17], наряду с другими возможностями.
- Количество внутреннего повторного использования программы может быть использовано в качестве верхней границы локальности. Это полезная мера для того, чтобы знать, как далеко мы находимся от оптимальной текущей производительности.
- Оценка производительности памяти для различных кэш архитектур для набора приложений может быть интересна для проектирования встроенного процессора с кэш-памятью, оптимизированого для таких программ.
- Компилятор может представлять некоторые намеки на локальность данных в аппаратном отношении, проявляемой каждой инструкцией памяти (включая некоторые биты), становятся обычной практикой. Например, PA7200 имеет немного для того, чтобы определить инструкции памяти только пространственной локальности [4]. PowerPC обеспечивает возможность идентификации инструкций, которые не проявляют много локальности и, таким образом, обходят кэш для таких инструкций [16]. Имея разную кэш память специализируемую на эксплуатации различных типов локальности может быть перспективной альтернативой увеличению производительности кэша [14]. Во всех этих случаях, компилятор отвечает за предоставление информации, которая закреплена в инструкциях памяти, которые будут определять в процессе выполнения соответствующих действий, какой должна быть аппаратура.
В этой статье мы представляем детальную оценку локальности, основанной на наборе тестов SPECfp95, в том числе различные вопросы, перечисленные выше. Для выполнения такой оценки мы разработали SPLAT инструмент [15], который является инновационным инструментом, позволяющий преодолеть ограничения предыдущих, предоставить такого рода информацию, как описано ниже.
Текущие инструменты для анализа локальности программы имеют существенные недостатки, которые ограничивают предоставляемую информацию. Такие инструменты для анализа данных можно разделить на три категории, в зависимости от подхода, используемого для выполнения анализа:
Симуляторы памяти (например, [6] [10]). Адекватный симулятор памяти предоставляет всю информацию, перечисленную выше. Однако, такие инструменты очень медленны, имеют замедление в несколько порядков. Например, в обзоре Улиг и Мадж [19], замедление управляющих трассами симуляторов находятся в диапазоне от 45 до 6245. Кроме того, в большинстве случаев, эти цифры относятся к симуляторам, которые просто сообщают отношения промахов. Эти замедления не являются доступными для некоторых реальных приложений, использующих несколько часов, чтобы работать без каких-либо накладных расходов. Это особенно верно, если анализируется всего лишь один шаг в повторяющемся процессе, который состоит из повторяющегося анализа и оптимизации шагов. Мы считаем, что такой повторяющийся процесс в настоящее время является наиболее подходящим подходом к оптимизации локальности эксплуатации данного приложения, так как полностью автоматический подход все еще не полностью успешен.
Совсем недавно предложенные симуляторы памяти (например [9] [12]), как утверждается, имеют гораздо меньшее замедление. Их подход основан на устранении / уменьшении накладных расходов для ссылок на память, которые попадают в кэш. Таким образом, окончательные накладные расходы зависят от соотношения промахов. Тем не менее, для типичных соотношений промахов результирующие накладные расходы могут оказаться слишком высокими. Значения в диапазоне 2-40, приведены в [19]. Кроме того, эти накладные расходы соответствуют экспериментам, где пользователь заинтересован просто в общем соотношении промахов. Если требуется более полная информация, перечисленная выше, замедление будет гораздо выше. Кроме того, некоторые из сведений, перечисленных выше (например, количество внутреннего повторного использования) может потребовать от инструмента еще и попаданий в кэше, что приведет к замедлению похожему на управляющих трассами симуляторов. Реализация специальных инструкций памяти, чтобы наблюдать за поведением системы памяти обсуждается в [8].
- Инструменты на основе аппаратных счетчиков предоставляют многие текущие микропроцессоры (например, [1]). Эти средства быстродействующие, но они могут обеспечить небольшое количество информации, ограниченную свойствами аппаратных счетчиков, предоставляемых производителем. Например, определение конфликтующих структур данных не может быть сделано полагаясь только на аппаратные счетчики для любого из существующих микропроцессоров. Кроме того, эти инструменты могут только анализировать локальность эксплуатируемой иерархии памяти фактического микропроцессора.
- Инструменты, основанные на статическом анализе локальности (например, [18], [7]). Такой подход очень быстродействующий, поскольку он имеет незначительное замедление. Тем не менее, он может быть неточным для некоторых программ в связи с отсутствием информации во время компиляции. Например, границы циклов, начального адреса структуры данных, размер массива размеров и т.д., могут быть неизвестны на этапе компиляции, что может значительно повлиять на точность анализа.
Краткий обзор инструмента SPLAT
В этом разделе мы представляем обзор SPLAT инструмента, который является инструментом, используемым для извлечения статистических данных, представленных в следующем разделе. Для получения дополнительной информации мы советуем заинтересованного читателя [15].
Инструмент состоит из трех основных шагов. Сначала он выполняет повторное использование анализа на основе подхода, предложенного Вульфом и Ламом [20]. Затем, некоторые данные, неизвестные во время компиляции (например, базовые показатели блока), получаются из профилирования программы. Наконец, анализатор локальности комбинирует информацию от повторного использования и профилирования, чтобы предоставить статистики локальности. Этот инструмент может проанализировать локальность, представленную различными архитектурами кэша, повторяя только последний шаг.
Инструмент быстр и точен. Замедление инструмента составляет около 0,05. Точность инструмента может быть доказана путем сравнения его результатов с такими симуляторами [15]. Основным ограничением является то, что инструмент ориентирован только на численные приложения. Для нечисленных приложений повторный анализ, вероятно, будет довольно неточным в связи с обильным использованием указателей ссылок.
Локальность SPECfp95
В этом разделе представлен количественный анализ локальности программ на SPECfp95. Из-за ограниченности современных платформ компилятора, мы предоставляем статистику семи из десяти показателей. Каждая программа была составлена с полной оптимизацией, и сообщила статистические данные, относящиеся к полному их выполнению.
Внутреннее повторное использование
Внутреннее повторное использование программ может быть использовано в качестве нижней границы пропускной способности памяти, требуемой данной программой. То есть, каждая ссылка, которая не проявляет какой-либо тип повторного использования, безусловно, требует обращения к памяти на следующий уровень иерархии.
Память повторного использования может быть разделена на четыре категории: самостоятельно-временную (ST), самостоятельно-пространственную (SS), группо-временную (GT), и группо-пространственную (GS). Временное внутреннее повторное использование зависит от конкретной архитектуры кэша базового оборудования. С другой стороны, пространственное внутреннее повторное использование зависит от размера строки кэша, в дополнение к программным характеристикам. Что касается группы повторного использования, в настоящее время используемый инструмент может только анализировать внутреннее повторное использование памяти среди ссылок, которые находятся в одном и том же цикле, что может привести к недооценке группы внутреннего повторного использования. Мы сейчас расширяем инструмент для выявления внутреннего повторного использования среди ссылок в различных циклах.
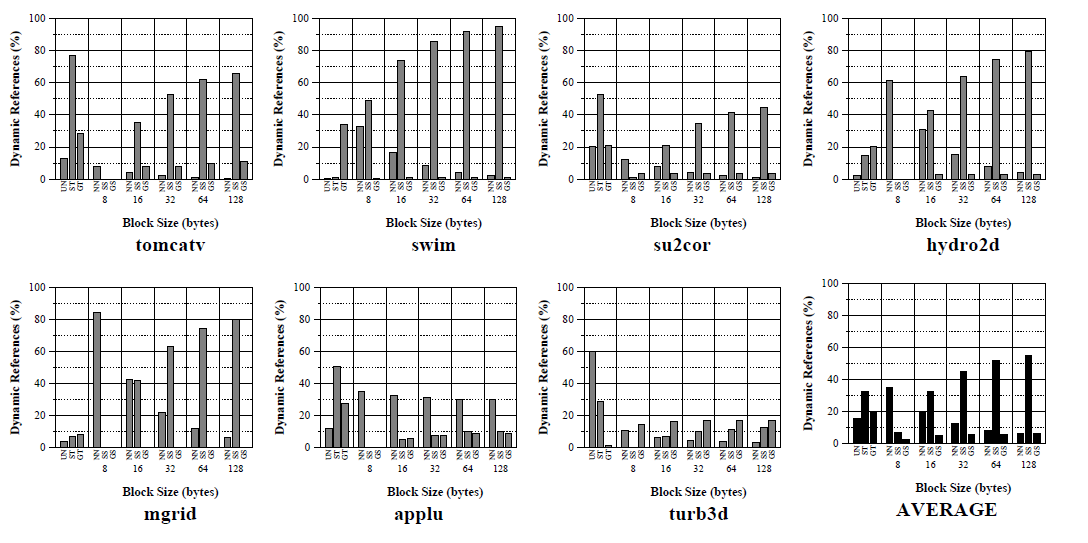
Рисунок 1 — Внутреннее повторное использование
На рисунке 1 приведено количество повторного использования SPECfp95 для некоторых программ в отдельности и в среднем. Внутреннеее повторное использование количественно для размера строки кэша в диапазоне от 8 до 128 байт. В дополнение к ранее упомянутым четырем категориям повторного использования, графики включают в себя пятую категорию, которая соответствует тем ссылкам, которые используются без какого-либо типа повторного использования (NN), и шестую, которая соответствует тем ссылкам, для которых инструмент не смог обнаружить его типа повторного использования (UN). Обратите внимание, что данное обращение может проявлять несколько типов повторного использования и, таким образом, различные бары могут добавляться до более чем 100%.
В среднем для всех программ, можно видеть, что самостоятельно-пространственное повторное использование является наиболее распространенным типом повторного использования (это проявляется на 56% всех ссылок). Самостоятельно-временное повторное использование также значительно (33% обращений). Группо-временное является следующим по значимости (20% обращений) и, наконец, группо-пространственное является наименее распространенным (7% обращений). Отметим также, что группо-пространственное повторное использование стабилизируется при размере строки 32-байта в то время как само-пространственное повторное использование обеспечивает убывающую зависимость для размера строки больше, чем 128 байт.
Результаты для отдельных программ очень разные, и доминирующие типы повторного использования зависят от конкретного теста:
- Tomcatv: доминирующие типы повторного использования: самостоятельно-временные и самостоятельно-пространственные. Группо-временное повторное использование также важно. В общем случае, внутреннее повторное использование для этой программы очень высоко (обратите внимание, что бар NN очень мал, даже для блоков 8 байт).
- Swim: для этой программы доминирующие типы повторного использования: группо-временное и самостоятельно-пространственное. Другие используются очень низко для всех размеров блоков.
- Su2cor: этот тест показал высокую степень временного повторного использования, в основном самостоятельно-временного. Кроме того, программа с высоким внутренним повторным использованием в целом.
- Hydro2d: доминирующий тип внутреннего повторного использования для этой программы - самостоятельно-пространственный, следующими идут временное повторное использование (как и самостоятельно-, так и группо-). Наконец, группо-пространственное повторное использование практически не заметно.
- Mgrid для этой программы временное повторное использования является низким, как для самостоятельно, так и для группо-. Кроме того, группо-пространственное повторное использование почти нулевое. Доминирующим типом внутреннего повторного использования является самостоятельно-пространственное. Следует отметить, что бар отсутствия внутреннего повторного использования очень чувствителен к размеру блока.
- Applu наиболее важным аспектом этой программы относительно ее повторного использования является низкое воздействие размера блока. Обратите внимание, что приращение пространственного повторного использования или декремент отстутствия повторного использования практически не заметно для блоков больше, чем 8 байт. Кроме того, эта программа с самым низким количеством внутреннего повторного использования, как отмечено относительно высоким баром NN.
- Turb3d в целом для этой программы внутреннее повторное использование не заметно, в основном группо-временное и самостоятельно-пространственное повторное использование. Тем не менее, отметим, что процент по неизвестным ссылкам очень высок (около 60%), так что результат может быть не очень точным для программы в целом.
Количество различных типов кэш промахов
Количество различных типов промахов может быть полезно, чтобы решить в частности оптимизацию, которая лучше всего может улучшить производительность программы. Промахи традиционно делятся на три категории: обязательные, емкостные и конфликтные. Каждый тип промахов может быть наилучшим образом ослаблен с различными методами как подчеркивается во введении. В настоящее время инструмент может оценить конфликтные промахи только для прямого отображения кэша хотя расширение для работы с ассоциативным отображением кэша довольно проста.
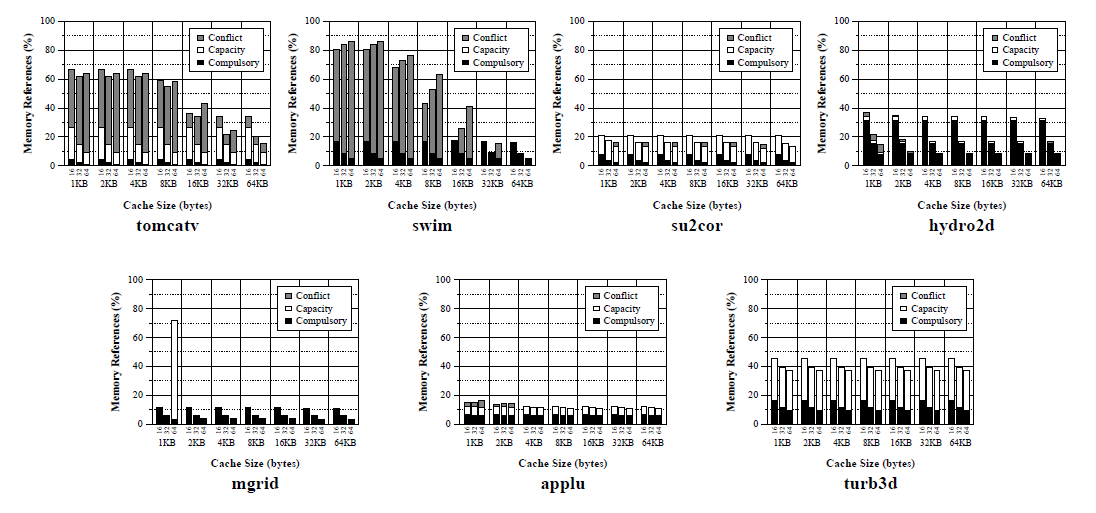
Рисунок 2 — Количество различных кэш промахов
Рисунок 2 показывает соотношение кэш промахов в программах, рассматриваемых в данной работе для кэш размером от 1 КБ до 64 КБ и размером строки 16, 32 и 64 байта. Для каждой конфигурации, общая доля промахов разделена на три различные категории. Ось ординат представляет собой процент от общего количества выполняемых инструкций памяти, чье повторное использование известно (первый столбец каждого графика на рисунке 1 - UN колонка - представляет собой динамический процент ссылок с неизвестным повторным использованием).
Для каждой программы, источник промахов довольно различен:
- Tomcatv: эта программа имеет очень большое количество конфликтных промахов, особенно для кэша меньше, чем 16 КБ. Увеличив размер кэша, сокращаются конфликтные промахи хотя другие методы, например, заполнение может быть более экономически эффективным, как мы покажем в следующем разделе. Емкостные промахи также значительны, и едва ли различаются для рассматриваемого диапазона объемов кэша. Это потому, что рабочий набор этой программы превышает 64 КБ. Наконец, обратите внимание, что наиболее эффективный размер строки зависит от объема кэша. Для очень маленького кэша, размер строки имеет небольшой эффект. Для средних кэшей, маленькая строка ведет себя лучше, так как они значительно уменьшают число конфликтных промахов, в связи с большим числом строк. Для больших кэшей, лучшее исполнение получается крупного размера строки. Это связано с сокращением емкостных промахов. Необходимо заметить, что увеличение размера строки может снизить емкостные промахи, хотя это может показаться нелогичным. Это может произойти, если есть ссылки, которые демонстрируют как пространственное, так и временное повторное использование, но временное повторное использование не может быть использовано в связи с ограниченной пропускной способностью. В этой ситуации увеличение размера строки приведет к лучшему использованию пространственной локальности и, таким образом, количество емкостных промахов будет снижено. Например, предложим следующий код:
do i=1,8
do j=1,1024
... A[j] ...
enddo
enddo
В этом примере ссылка А[j] имеет пространственное повторное использование в цикле j и временное повторное использование в цикле i. Если объем кэша составляет 512 элементов, временное повторное использование не может быть использовано. Таким образом, если размер строки 4 элемента, этот код будет производить 256 (1024/4) обязательных промахов (для первой итерации цикла i) и 1792 ((1024/4) * 7) емкостных промахов (для оставшихся итераций цикла i). Однако, если размер строки 8 элементов, будет 128 (1024/8) обязательных промахов и 896 ((1024/8) * 7) емкостных промахов.
- Swim: основным источником промахов для этой программы являются конфликтные промахи. Для объема кэша меньше, чем 16 Кбайт, промахи связаны с помехами, представленными большинством промахов. Для кэша размером 16 Кбайт, это также доминирующий источник промахов при размере блока 32 и 64 байта. Наконец, для кэша размером 32 или 64 Кбайт, обязательные промахи являются наиболее важным источником промахов. Например, для кэша размером 64 Кбайт, обязательные промахи являются единственным источником промахов. Следует отметить, что для этой программы эффект емкостных промахов почти незначительно.
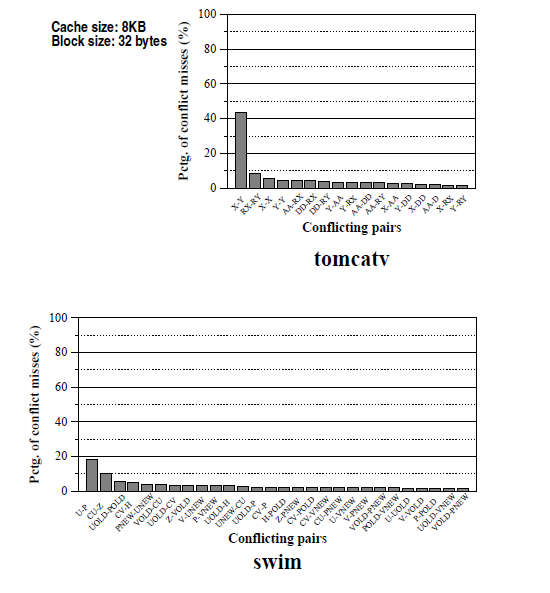
Рисунок 3 — Процент конфликтных промахов между структурами данных
- Su2cor: низкое влияние как размера кэша, так и размера блоков в общем количестве промахов для этой программы является заметным. Поведение всей кэш-памяти практически не меняется и влияние размера блока составляет менее 5%. Можно заметить, что большую часть промахов составляют емкостные промахи, но рабочий набор программы больше, чем 64 Кбайт, так как емкостные промахи до этого размера не уменьшаются.
- Hydro2d: для этой программы все рабочие наборы могут быть сохранены в очень небольшой кэш и, таким образом, увеличивая объем кэша едва ли повышается производительность. Увеличение размера строки способствует эксплуатации пространственной локальности и уменьшает количество обязательных промахов.
- Mgrid: как hydro2d, для этой программы основной причиной промахов являются обязательные промахи. Если кэш имеет только 16 блоков (то есть, размер кэша 1 Кбайт с блоком размером 64 байта), нет места, чтобы сохранить большинство данных в кэше, так что количество емкостных промахов очень высоко.
- Applu: как su2cor, количество промахов в этом тесте почти постоянно для всех конфигураций.
- Turb3d: данная программа показывает высокое количество промахов. Тем не менее, отметим, что результаты представлены ссылками, чье повторное использование изучено, и для этой программы процент неизвестных ссылок составляет почти 60% (см. рисунок 1). По этой причине, результаты этого графа могут не быть репрезентативными для всей программы.
Информация про внутреннее повторное использование вместе с количественным определением различных типов повторного использования может быть использована компилятором, чтобы установить соответствующие попадания, представленные инструкциями памяти в некоторых микропроцессорах. Например, если кэш имеет возможность заполнения, те ссылки, с отсуствием повторного использования, могут быть помечены как некэшируемые. Кроме того, если две различные инструкции памяти часто сталкиваются, одна из них может быть также помечена как некэшируемая. Таким образом, локальность, представленная на другой инструкции, может быть использована, что лучше, чем не использовать обе. Например, как уже сообщалось, что тип анализа, когда применяется ведение селективной политики кэширования, может обеспечивать приблизительно 25%-ое сокращение среднего времени доступа к памяти и 65%-ное снижение пропускной способности памяти следующего уровня [14].
Конфликтующие структуры данных
Для программ с высоким процентом конфликтных промахов, может быть интересно определить, какие структуры данных, ответственны за такие конфликты. Такие методы, как заполнение или копирование может быть применимо на такие структуры данных, чтобы попытаться уменьшить эти конфликты.

Рисунок 4 — Снижение количества конфликтных промахов после заполнения
Например, рисунок 3 показывает процент конфликтов между любой парой структур данных, от большего к меньшему, для tomcatv и swim тестов, для 8 КБ прямого отображения кэша со строкой 32 байта. Для программы tomcatv, можно видеть, что структуры данных, X и Y являются причиной большинства конфликтных промахов. Кроме того, на рисунке 2 мы можем наблюдать, что большинство промахов из-за конфликтов, которые предполагают, что заполнение может быть эффективным методом для снижения штрафов памяти. Например, рисунок 4 показывает результирующее количество конфликтных промахов теста tomcatv после вставки пустых байтов между двумя структурами данных. Видно, что даже с такой наивной схемой заполнения, количество конфликтных промахов значительно снизилось с 39,5% до 27,2%.
Для swim программы, конфликтные промахи более распространены среди большего набора структур данных.
Критические секции кода
Большинство штрафов памяти во многих случаях вызвано малым процентом кода. Выявление этих штрафных секций может помочь программисту / компилятору сосредоточить усилия на таких частях кода.

Рисунок 5 — Кэш промахи на внутренний цикл
Например, рисунок 5 показывает процент промахов кэша (от общего количество промахов), которые вызваны в каждом внутреннем цикле, на примере двух программ. Кроме того, для каждого цикла, соответствующий процент промахов разделен на три различных типа: обязательные, емкостные и конфликтные. 8 КБ, прямого отображения кэша по 32 байта на строку предполагается.
Обратите внимание, что в обоих случаях подавляющее большинство промахов обусловлено малыми секциями кода: три внутренних цикла для swim и шесть внутренних циклов для turb3d. Для swim большинство конфликтных промахов, тогда как в turb3d, значительный вклад состаляют емкостные и обязательные.
Выводы
В этой статье мы представили подробный анализ локальности, представленный на наборе тестов в SPECfp95. Это детальная оценка была выполнена с помощью нового очень быстрого инструмента анализа локальности данных, что позволяет получать данные по всем выполненным реальным программам при различных конфигурациях кэша с незначительным замедлением.
Мы показали, что различные программы обладают очень разными характеристиками локальности. Подробные оценки локальности программ могут быть важны для последующего выбора наилучшего подхода для ее улучшения.
Мы доказали, что полностью автоматизированный инструмент оптимизации пока недостаточен в связи с различными сценариями, с которыми они должны справиться. Также мы считаем, что лучшим подходом на сегодня для оптимизации памяти является итеративный (и интерактивный) процесс, в котором повторяющийся анализ и шаги оптимизации чередуются, пока конечный результат не будет приемлемым. Таким образом, скорость инструмента анализа, а также диапазон информации, которую он может обеспечить являются критическими. Мы показали, что тип анализа, представленный в настоящем документе может быть очень полезный для такого подхода.
Благодарности
Эта работа поддержана Министерством образования Испании по контракту CICYT-TIC 429/95, ESPRIT проектом MHAOTEU (EP24942), а также каталонским Cirit по гранту 1996FI-3083-APDT.
Ссылки
[1] G. Ammons, T. Ball and J.R. Larus, “Exploiting Hardware Performance Counters with Flow and Context Sensitive Pro?ling”, in Procs. on of the 1997 Conf. on Programming Languages Design and Implementation (PLDI-97), 1997
[2] D. Callahan, K. Kennedy and A. Porter?eld, “Software Prefetching”, in Procs. of IV Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS’91), pp. 40-52, April 1991
[3] S. Carr, K.S. McKinley and C-W. Tseng, “Compiler Optimizations for Improving Data Locality”, in Procs. of V Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS’94), pp. 252-262, Oct. 1994
[4] K.K. Chan, C.C. Hay, J.R. Keller, G.P. Kurpanek, F.X. Schumacher and J. Sheng, “Design of the HP PA 7200 CPU”, Hewlett-Packard Journal, Feb. 1996
[5] D. Gannon, W. Jalby and K. Gallivan, “Strategies for Cache and Local Memory Management by Global Program Transformations”, Journal of Parallel and Distributed Computing, 5, pp. 587-616, 1988
[6] J. Gee, M. Hill, D. Pnevmatikatos and A.J. Smith, “Cache Performance of the SPEC92 Benchmark Suite”, IEEE Micro, pp. 17-27, Aug. 1993
[7] S. Ghosh, M. Martonosi and S. Malik, “Cache Miss Equations: an Analytical Representation of Cache Misses”, in Procs. of Int. Conf. on Supercomputing (ICS’97), pp. 317-324, July 1997
[8] M. Horowitz, M. Martonosi, T.C. Mowry and M.D. Smith, “Informing Memory Operations: Providing Memory Performance Feedback in Modern Processors”, in Procs. of Int. Symp. on Computer Architecture (ISCA’96), pp. 260-270, 1996
[9] M. Martonosi, A. Gupta and T. Anderson, “Memspy: Analyzing Memory Performance System Bottlenecks in Programs”, Performance Evaluation Rev., 20(2), June 1992
[10] K. S. McKinley and O. Temam, “A Quantitative Analysis of Loop Nest Locality”, in Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASP-LOS’96), 1996
[11] T.C. Mowry, M.S. Lam and A. Gupta, “Design and Evaluation of a Compiler Algorithm for Prefetching”, in Procs. of V Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS’92), pp. 62-73, Oct. 1992
[12] S. Reinhardt, R. P?le and D. Wood, “The Wisconsin Wind Tunnel: Virtual Prototyping of Parallel Computers”, in ACM Sigmetrics Conf. on Measurement and Modeling of Computer Systems, pp. 48-60, 1993
[13] G. Rivera and C-W. Tseng, “Data Transformations for Eliminating Con?ict Misses” in Procs. of Conf. on Programming Language Design and Implementation (PLDI‘98), 1998
[14] F.J. Sanchez, A. Gonzalez and M.Valero, “Static Locality Analysis for Cache Management”, in Procs. Int. Conf. on Parallel Architectures and Compiler Techniques (PACT’97), 1997
[15] F.J. Sanchez and A.Gonzalez, “Fast, Accurate and Flexible Data Locality Analysis”, Technical Report DAC-UPC-1998-8, UPC-Barcelona, May 1998
[16] J.M. Stone and R.P. Fitzgerald, “Storage in the PowerPC”, IEEE Micro, vol. 15, no. 2, pp. 50-58, April 1995
[17] O. Temam, E.D. Granston, W. Jalby, “To Copy or not to Copy: A Compile-time Technique for Assessing when Data Copying Should be Used to Eliminate Cache Con?icts”, in Proc
[18] O. Temam, C. Fricker and W. Jalby, “Cache Interference Phenomena”, in ACM Sigmetrics Conf. on Measurement and Modeling of Computer Systems, May 1994
[19] R.A. Uhlig and T.N. Mudge, “Trace-driven Memory Simulation: a Survey”, ACM Computing Surveys, 1997
[20] M.E. Wolf and M.S. Lam, “A Data Locality Optimizing Algorithm”, in Procs. of Conf. on Programming Language Design and Implementation (PLDI‘91), pp. 30-44, 1991