Протокол MESI и проблемы синхронизации памяти
Автор: Аванесов Тигран
Источник: Журнал о параллельном программировании «data-race». Статья. 29 октября 2010 г.
Автор: Аванесов Тигран
Источник: Журнал о параллельном программировании «data-race». Статья. 29 октября 2010 г.
Аванесов Тигран Протокол MESI и проблемы синхронизации памяти Что такое барьеры памяти, какие проблемы они решают и почему они свалились на головы программистов? Вкратце – все из-за борьбы за производительность. Для лучшего понимания нужно рассмотреть как работает процессор и как происходит кэширование.
Рассмотрим схему современного многоядерного процессора, построенного на архитектуре SMP (Symmetric Multiprocessing)
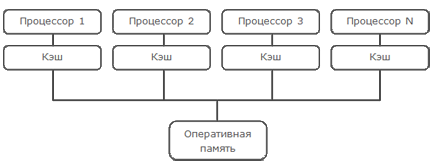
Современные процессоры намного производительнее современных модулей памяти и работа напрямую с памятью значительно снизила бы производительность процессора. Для решения этой проблемы производители процессоров придумали кэширование. Кэш – это высокоскоростной модуль памяти (размерами значительно уступающий оперативной памяти). Все данные прежде чем начать непосредственную работу с ними сперва заносятся в кэш память, логически разделенную на блоки фиксированного размера, называемые кэш-линиями. Размер кэш линии обычно лежит в диапазоне от 16 до 256 байт и является степенью двойки. Кэш обычно реализуют в виде хэш-таблицы, в которой хранится хэш адреса данных (это ключ) и его значение. Когда данные отсутствуют в кэше процессор вынужден загрузить их из памяти и только потом начать непосредственную работу с данными. Естественно кэш не безграничен и через некоторое время возникнет ситуация, когда ячейка, в которую процессор должен загрузить данные уже занята другими данными. Tогда процессор должен будет выгрузить данные из ячейки (предварительно записав их обратно в память, если они изменялись), тем самым освободив место для новых данных. Это дает значительный прирост производительности, но за все приходиться платить. Что случится, если два процессора будут работать с теми же данными?
Для синхронизации между процессорами существуют разнообразные протоколы и для более детального изучения этого процесса мы рассмотрим довольно простой и широко известный протокол MESI. Суть протокола MESI состоит в том, что каждой кэш линии присваивается одно из 4-х состояний
Modified — Состояние указывает на то, что кэш-линия была модифицирована и присутствует только в текущем кэше. Запись данных обратно в память вернет кэш-линию в состояние exclusive.
Exclusive — Состояние указывает на то, что кэш-линия присутствует только в текущем кэше, но пока не была модифицирована. Она может перейти в состояние shared (если другой процессор отправит запрос на чтение) или в состояние modified если текущий процессор модифицирует данные в кэш-линии.
Shared — Состояние указывает на то, что кэш линия может присутствовать и в других кэшах, она не может быть модифицирована, без уведомления остальных процессоров и может перейти в состояние invalid по соответствующему запросу от другого процессора (если другому процессору понадобится изменить данные в кэш-линии).
Invalid — Состояние указывает на то, что кэш-линия пуста.
Рассмотрим простой пример, показывающий алгоритм работы протокола MESI.

Процессору для модификации данных, находящихся в кэше другого процессора необходимо сперва удостовериться, что он обладает эксклюзивными правами на эти данные (отправить остальным процессорам сообщение invalidate (очистить кэш-линию)). Может пройти немало времени, пока процессор ответит на это сообщение и заставлять процессор ждать все это время не имеет смысла. Один из способов избавиться от ненужного ожидания – ввести временный буфер, в который будут записываться изменения до отправки сообщения, а потом (когда прибудет подтверждение от другого процессора) модифицировать данные. Т.е. говоря другими словами – оставить запись “на потом” и продолжить работу. Изменим немного схему процессора и добавим туда некий буфер (store buffer).
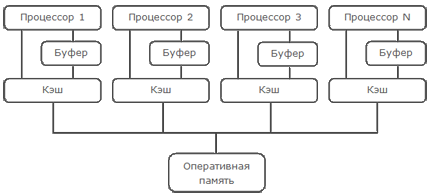
Теперь процессор может провести запись в store buffer и продолжить свою работу, это избавляет процессор от надобности тратить время на ожидание и дает возможность заняться в этом время полезной работой, но все не так просто. Рассмотрим проблемы, связанные с этим на простом примере.
Допустим у нас есть переменные a, b и процессор, который должен выполнить следующие инструкции

по логике assert должен пройти успешно (не должен сработать), но на процессорах с описанной архитектурой он может и не пройти. Рассмотрим такую ситуацию: процессор #1 пытается модифицировать переменную a, находит ее у себя в кэше и отправляет запрос, для получения эксклюзивного доступа к a, записывает данные в store buffer и не ожидая подтверждения переходит к следующей инструкции. Загружает из кэш-линии a (которое имеет значение 0) и присваивает переменной b значение 1. Потом он конечно получает подтверждение и эксклюзивный доступ к a, модифицирует его, но уже поздно, assert провалился. Такое поведение стало бы сущим кошмаром для программистов. К счастью производители процессоров это предусмотрели и все операции совершаются в той последовательности, в которой они написаны с точки зрения текущего процессора, но есть и другая.
Мы поняли, что с точки зрения текущего процессора очередность операций остается неизменной (эту гарантию нам дают производители), но что будет, если посмотреть на эти операции с точки зрения другого процессора? Рассмотрим следующий пример

Есть две глобальные переменные a и b, имеющие изначально значение 0 и есть две функции, которые выполняются в разных потоках и на разных процессорах. Процессор #1 модифицирует переменную a (естественно атомарно), потом переменную b, а процессор #2 в свою очередь читает переменную b до тех пор, пока она не изменит свое значение на 1, а потом проверяет переменную a. По законам логики в тот момент, когда переменная b изменит значение на 1 переменная a уже должна быть модифицирована и также содержать значение 1, но в свете вышеописанной архитектуры тут возможны варианты. Допустим переменная a находится в кэше процессора #2, а переменная b находится в кэше процессора #1. Для выполнения первой операции в функции func_on_cpu1 понадобится отправить запрос второму процессору, для получения эксклюзивного доступа и как уже писалось выше после отправки запроса и записи значения 1 в store buffer процессор #1 перейдет к следующей инструкции и изменит значение b (поскольку b находится только в его кэше), а в то время процессор #2 получит значение b == 1 и выполнит assert (который провалится). Процессор #1 получит в конце концов подтверждение, модифицирует значение переменной a, но будет поздно. Т.е. мы имеем гарантию, что процессор будет наблюдать очередность своих операций с памятью в том порядке, в котором они совершались, но на остальные процессоры эта гарантия не распространяется.
Производители процессоров не в силах тут помочь, так как они не знают о связи этих переменных (а связывать все переменные было бы слишком затратно). Эту проблему решают барьеры памяти (memory barrier, memory fence). Это специальная процессорная инструкция, которая инструктирует процессор сбросить содержимое store buffer-а, т.е. завершить все незавершенные операции с памятью. В данном конкретном случае барьер памяти между 3 и 4 строкой должен решить проблему. Теперь до того, как перейти к строке 5 процессор должен закончить выполнение 3-ей строки, это навязывает процессору очередность выполнения операций с памятью.

Эта инструкция называется барьер, потому-что она как бы проводит линию между операциями, не позволяя процессору при переупорядочивании ее пересекать, но...
Когда процессор получает сообщение invalidate (очистить кэш-линию), для ответа на него он должен сперва очистить соответствующую кэш-линию и только потом ответить подтверждением, но иногда очистка кэш-линии может занять длительное время, а любая задержка является задержкой другого процессора, это лишено смысла. Чтобы не задерживать остальные процессоры он может записать эту команду в какую нибудь очередь (queue), и незамедлительно ответить подтверждением. Процессор дает обещание, что он очистит эту кэш-линию. Добавим эту очередь в схему процессора
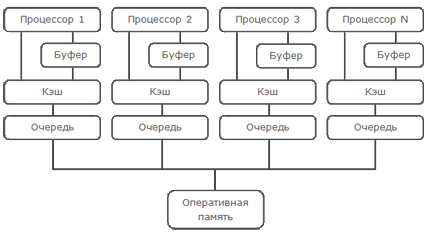
Теперь первому процессору (отправившему запрос на invalidate) не надо долго ждать, пока процессор ответит подтверждением. Он ответит незамедлительно, но это влечет за собой дополнительные проблемы. Рассмотрим их на том же примере
Допустим переменная a опять находится в кэше процессора #2, а переменная b находится в кэше процессора #1. Для выполнения первой операции в функции func_on_cpu1 понадобится отправить запрос второму процессору, для получения эксклюзивного доступа и как уже писалось выше после отправки запроса и записи значения 1 в store buffer процессор #1 перейдет к следующей инструкции и изменит значение b (поскольку b находится только в его кэше). Процессор #2 в то время получает запрос, но не очищает кэш-линию, а оставляет “на потом” (т.е. записывает в очередь), в то время процессор #1 меняет значение b, тем самым давая зеленый свет второму процессору, который перейдет к строке 11 и и выполнит assert (который провалиться), так как переменная a все еще находится в его кэше. Позже процессор #2 очистит кэш-линию, в которой находится a как и обещал, но будет поздно. К счастью барьеры памяти помогают и здесь, надо лишь поставить барьер между 10 и 11-ой строкой, это заставит процессор выполнить выполнить содержимое очереди (т.е. “выполнить все обещания”).

На самом деле многие процессорные архитектуры предоставляют и более “слабые” барьеры. Одни инструктируют процессор очистить store buffer (write memory barrier), другие выполнить содержимое очереди (read memory barrier), третьи делают и то и другое (full memory fence). Оптимальный вариант кода будет выглядеть так

Барьеры памяти — это примитивные объекты синхронизации, которые позволяют навязывать процессору очередность выполнения операций с памятью. Барьеры в основном используются при написании низкоуровневого кода, так как в языках высокого уровня в их явном использовании нет нужды. Например в C# любой lock является полным барьером (full memory fence), Interlocked операции тоже. В новом стандарте C++0x введена поддержка барьеров напрямую, так как создатели C++ хотят плотно занять нишу низкоуровневого программирования.
Memory Barriers: a Hardware View for Software Hackers
Documentation on memory barriers in the Linux kernel
C++ standard