
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження
- 3. Огляд досліджень і розробки
- 4. Висновки
- Перелік посилань
Вступ
Попередня обробка даних є найважливішим етапом, від якості виконання якого, залежить можливість отримання якісних результатів усього процесу аналізу даних. Якщо виникає необхідність використовувати нейромережеві методи для вирішення конкретних завдань, то перше з чим доводиться стикатися – це підготовка даних. Як правило, при описі різних нейроархітектур, типово припускають що дані для навчання вже є і представлені у вигляді, доступному для нейромережі. На практиці ж саме етап попередньої обробки може стати найбільш трудомістким елементом нейромережного аналізу[5]. За деякими оцінками етап попередньої обробки даних може зайняти до 80%[2] всього часу, відведеного на проект. Успіх навчання нейромережі також може вирішальним чином залежати від того, в якому вигляді представлена інформація для її навчання. Власне, попередня обробка даних дозволяє як підвищити якість інтелектуального аналізу даних, так і підвищити якість самих даних.
1. Актуальність теми
Один з прогнозів необхідності, а відповідно і актуальності, збільшення якості даних, зроблений Даффі Брансоном [4] (Duffie Brunson) звучить наступним чином:
Прогноз. Багато компаній стали звертати більше уваги на якість даних, оскільки низька якість даних коштує грошей в тому сенсі, що веде до зниження продуктивності, прийняття неправильних бізнес-рішень і неможливості отримати бажаний результат, а також ускладнює виконання вимог законодавства. Тому компанії дійсно мають намір робити конкретні дії для вирішення проблем якості даних.
.
Реальність. Дана тенденція зберігається, особливо в індустрії фінансових послуг. У першу чергу це відноситься до фірм, які намагається виконувати угоду Basel II. Неякісні дані не можуть використовуватися в системах оцінки ризиків, які застосовуються для установки цін на кредити і обчислення потреб організації в капіталі. Цікаво відзначити, що істотно змінилися погляди на способи вирішення проблеми якості даних. Спочатку менеджери звертали основну увагу на інструменти оцінки якості, вважаючи, що власник
даних повинен вирішувати проблему на рівні джерела, наприклад, очищаючи дані і перенавчитися співробітників. Але зараз їх погляди суттєво змінилися. Поняття якості даних набагато ширше, ніж просто їх акуратне введення в систему на першому етапі. Сьогодні вже багато хто розуміє, що якість даних повинне забезпечуватися процесами вилучення, перетворення і завантаження (extraction, transformation, loading - ETL), а також отримання даних з джерел, які готують дані для аналізу.
2. Мета і задачі дослідження
Мета роботи полягає в тому, щоб програмно реалізувати алгоритм підготовки даних, для подальшого нейромережевого аналізу та прогнозування.
Основні задачі:
- Дослідити методи обробки даних.
- Вибрати комбінацію методів для реалізації алгоритму підготовки даних.
- Вивчити літературу з попередньої підготовки даних.
- Реалізувати вивчені методи підготовки даних в програмному проекті.
3. Огляд досліджень і розробки
3.1 Максимізація ентропії
Інформативність кожного поля/параметра даних, в умовах розв'язуваної задачі, повинна бути максимальною [8]. Отже, можна стверджувати про необхідність максимізації ентропії, для збільшення ймовірності правильного прогнозування та класифікації.
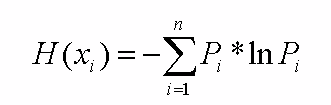
де xi – стан деякого поля/параметра даних, Pi – ймовірність цього стану, n – кількість таких станів.
Така попередня обробка даних призначена для кодування входів-виходів у нейронних мережах, так як вони сприймають тільки числову інформацію [1].
3.2 Нормування даних
Зрозуміло, що результати нейромережевого моделювання не повинні залежати від одиниць вимірювання величин. Значить, можна стверджувати, що для підвищення якості та швидкості навчання нейронної мережі, є необхідність приведення даних до єдиного масштабу шляхом нормування даних. Приведення даних до одиничного масштабу забезпечується нормуваннями кожної змінної на діапазон розкиду її значень. У найпростішому варіанті це - лінійне перетворення:
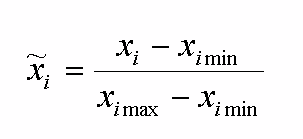
де xi – обраний стан поля/параметра даних, xi max – максимальний стан поля/параметра даних, xi min – мінімальний стан поля/параметра даних.
3.3 Зниження розмірності входів
Існує два типи алгоритмів:
- відбір найбільш інформативних ознак та використання їх у процесі навчання нейронної мережі (в цьому випадку найбільш правильним буде використання генетичного алгоритму отбирающего найбільш інформативні ознаки, проте можливий варіант з оцінкою, по векторів ознак, стохастичного відстані між розподілами ймовірностей);
- кодування вихідних даних меншим числом змінних, але при цьому містять по можливості всю інформацію, закладену у вихідних даних (аналіз головних компонент [7] з використанням нейронної мережі).Був обраний метод аналізу головних компонент, з використанням нейронної мережі, в загальному вигляді виглядає так:
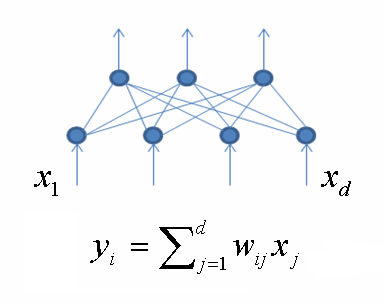
де yi – вихід з i-того нейрона внутрішнього шару, wij – ваги мережі між вхідним і вихідним шарами, xj – компонента входного вектора.
Алгоритм побудови класифікатора на основі нейронних мереж [3]
- Робота з даними
- Скласти базу даних із прикладів, характерних для даної задачі.
- Розбити всю сукупність даних на дві множини: навчальне і тестове (можливо розбивка на 3 безлічі: навчальне, тестове і підтверджуюче).
- Попередня обробка
- Вибрати систему ознак, характерних для даної задачі, і перетворити дані відповідним чином для подачі на вхід мережі (нормування, стандартизація і т.д.). В результаті бажано отримати лінійно відокремлюване простір безлічі зразків.
- Вибрати систему кодування вихідних значень (класичне кодування, 2 на 2 кодування і т.д.).
- Конструювання, навчання та оцінка якості мережі.
- Вибрати топологію мережі: кількість шарів, число нейронів у шарах і т.д.
- Вибрати функцію активації нейронів (наприклад «сигмоїда»).
- Вибрати алгоритм навчання мережі.
- Оцінити якість роботи мережі на основі підтверджує безлічі або іншому критерію, оптимізувати архітектуру (зменшення ваг, проріджування простору ознак).
- Зупиниться на варіанті мережі, який забезпечує найкращу здатність до узагальнення та оцінити якість роботи з тестового безлічі.
- Використання та діагностика
- З'ясувати ступінь впливу різних факторів на прийняте рішення (евристичний підхід).
- Переконається, що мережа дає необхідну точність класифікації (число неправильно розпізнаних прикладів мало).
- При необхідності повернуться на етап 2, змінивши спосіб представлення зразків або змінивши базу даних.
- Практично використовувати мережу для вирішення завдання.

Рисунок 1 - Модель прогнозування/класифікації в загальному вигляді[6]
(анімація: 7 кадрів, 5 циклів повторення, 137 кілобайт)
4. Висновки
Для виконання завдань попередньої обробки даних, що дозволяють швидше і якісніше вирішувати завдання класифікації і прогнозування було обрано такі методи обробки даних: максимізація ентропії, індивідуальна нормировка даних, пониження розмірності входів навченою мережі шляхом методу аналізу головних компонент. Вибрано алгоритм побудови класифікатора на основі використовуваної нейронної мережі.Перелік посилань
- Ежов А.А., Шумский С.А. Нейрокомпьютинг и его применение в экономике и бизнесе – М. 1998г., c. 126-145
- Курс лекций по Data Mining, Чубукова И. А., Соискатель ученой степени кандидата экономических наук в Киевском национальном экономическом университете имени Вадима Гетьмана, кафедра информационных систем в экономике, ведущий инженер-программист в Национальном банке Украины, c. 206-214
- Применение нейронных сетей для задач классификации / Интернет ресурс – Режим доступа: http://www.basegroup.ru
- Десять основных тенденций 2005 года в области Business Intelligence и Хранилищ данных Интернет ресурс – Режим доступа: http://citforum.ru
- Великие раскопки и великие вызовы / Интернет ресурс – Режим доступа: http://www.kdnuggets.com
- Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. - Технологии анализа данных. Data Mining, Visual Mining, Text Mining, OLAP (2-е издание) с. 90-94
- Прикладная статистика: Классификация и снижение размерности: Справ. Изд. / С. А. Айвазян, В. М. Бухштабер, И. С. Енюков, Л. Д. Мешалкин; Под ред. С. А. Айвазяна. – М.: Финансы и статистика, 1989. – 607с.: ил. с. 339
- Технология Data Mining: Интеллектуальный Анализ Данных, Степанов Р. Г. – Казань, 2008. – c. 14